因为kafka用到的地方比较多,日志收集、数据同步等,所以咱们来聊聊kafka。
首先先看看kafaka的结构,producer将消息放到一个Topic然后push到broker,然后cosumer从broker中拉取对应Topic的消息。

broker可能大家不太熟悉,这个broker就是构成kafka集群的机器,用于实现将数据持久化并且其他数据从leader broker中进行备份,一旦其中一台 broker出现问题之后将由其他broker直接升级为leader,然后代替原来的broker。
zookeeper的作用是记录当前leader broker的id,并将其发送给producer,并且记录每个consumer的进行的offset。offset就是消息存在的位置,这块与其他消息组件不同的是其他的消息组件消费完了直接就没有了,但是kafka会将消息持久化一段时间,这个时间可以是几天时间,用于消息重新再读取。
接下来咱们再继续看看broker的内部实现:
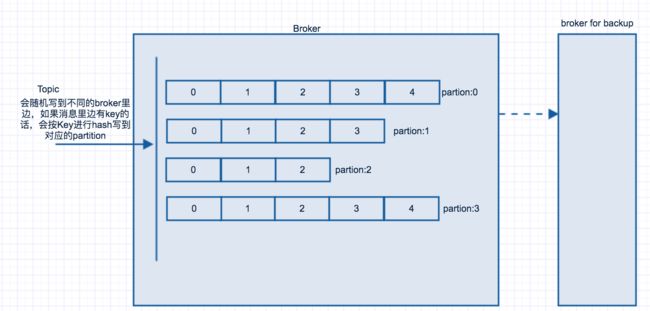
在每一个broker里边有相应的partition,这个partition就是按照Topic将消息分发到不同的partition, 然后consumer再到相应的partition获取对应的消息。如果producer发送消息到某个指定的key上,那么kafka会将这个key进行hash到指定的partition上。在kafka里边可以指定factor,这个factor的作用是备份,对partition的备份。如果指定factor=2,那么一个partion会有2个备份。如下图所示:

下面说一下consumer group, 因为partion设置的数量固定,所以在consumer group中的数量一定是小于等于partition的数量,因为最多每个consumer消息一个,consumer多了就消费不过来了。
consumer group 是拥有相同group id的机器,这些机器是单独的机器,每个机器都可以指定topic、partition进行消费。如下图所示:

这些就是基本的kafka结构了,当然里边还有很多非常详细的内容,这里就不单独说了。kafka的功能非常强大,分布式,可动态扩展,消息复制,高可用低延迟等特点,这就是为什么很多人喜欢使用kafka。kafka单台机器生产消费机器的话,每秒处理70-80万左右的消息。当然消息备份采用异步处理,如果消息采用同步处理的话,一秒可以处理的数据每秒也有30-40万左右。
kafka支持消息持久化,这个持久化的时间可以进行配置,也就是消息可以被consumer多次消费。这个是其他消息队列所没有的。
kafka支持consumer进行assign(分配)topic,也就是单独消费某一个消息,在consumer group里边只有一台机器消费此topic。也支持Pub-Sub模式,所有订阅指定Topic的consumer会收到消息。同时支持取消订阅功能。
kafka还支持connector(连接器),可以进行数据库连接,连上数据库后可以将数据库的记录读取到,按照自增列id或者timestamp(时间戳)进行读取,然后将消息写入到需要的地方,比如写到数据分析的地方。
kafka支持stream(流),可以将消息写入到stream,并将消息以流的形式从一个topic写入到另一个topic中,这个功能其他队列也没有。
kafka一般用于消息队列,日志收集,网站行为记录等,当然它也有区别,比如不能topic不能使用通配符,connector的支持的语言不是特别多。
好了,关于kafka咱们先聊到这里,还有很多地方没有说到,有觉得那些写的不好的地方还望同学不吝赐教。