* HBase框架基础(三)
本节我们继续讨论HBase的一些开发常识,以及HBase与其他框架协调使用的方式。在开始之前,为了框架之间更好的适配,以及复习之前HBase的配置操作,请使用cdh版本的HBase开启动相关服务,记得,配置HMaster的HA。
为了方便,cdh版本hbase下载传送门:
链接:http://pan.baidu.com/s/1dFsyakT 密码:xji7,相关配置请参考HBase框架基础(一)
* HBase的数据迁移
原因:我们需要问一个问题,何时,HBase的数据需要被迁移?例如:集群架构变更,服务器硬件,或者软件升级等等。
方案:
1、将整个HBase目录迁移到另一个集群
distcp方式:
尖叫提示:以下NameNode为两个独立的物理集群,不是HA
$ bin/hadoop distcp hdfs://NameNode1:8020/hbase hdfs://NameNode2:8020/hbase
hftp方式:
$ bin/hadoop distcp -i hftp://sourceFS:50070/hbase hdfs://dstFS:8020/hbase
当完成了整个迁移后,可以使用hbck来恢复一下hbase的元数据,因为元数据也有可能在迁移的过程中出现问题。
hbck修复:
$ bin/hbase hbck -fixMeta
2、自定义MapReduce程序
这种方式主要是自己写一个MapReduce程序,自行的读取集群中的某一个HBase表中的数据,然后写入到另一个集群的HBase的表中。稍后我们做一个实现。
* BulkLoad加载文件到HBase表
功能:将本地文件数据导入到HBase当中
原理:BulkLoad会将tsv/csv格式的文件编程hfile文件,然后再进行数据的导入,这样可以避免大量数据导入时造成的集群写入压力过大。
作用:
1、减小HBase集群插入数据的压力
2、提高了Job运行速度,降低Job执行时间
BulkLoad举例测试:
Step1、配置临时环境变量,与上一节一样
$ export HBASE_HOME=/opt/modules/cdh/hbase-0.98.6-cdh5.3.6
$ export HADOOP_HOME=/opt/modules/cdh/hadoop-2.5.0-cdh5.3.6
$ export HADOOP_CLASSPATH=`${HBASE_HOME}/bin/hbase mapredcp`
Step2、创建一个新的HBase表
$ bin/hbase shell
hbase(main):001:0> create 'fruit_bulkload','info'
Step3、将tsv/csv文件转化为HFile (别忘了要确保你的fruit格式的文件fruit.txt在input目录下)
$ /opt/modules/cdh/hadoop-2.5.0-cdh5.3.6/bin/yarn jar \
/opt/modules/cdh/hbase-0.98.6-cdh5.3.6/lib/hbase-server-0.98.6-cdh5.3.6.jar importtsv \
-Dimporttsv.bulk.output=/output_file \
-Dimporttsv.columns=HBASE_ROW_KEY,info:name,info:color \
fruit hdfs://mycluster/input
完成之后,你会发现在HDFS的根目录下出现了一个output_file文件夹,里面存放的就是HFile文件
Step4、把HFile导入到HBase表fruit_bulkload
$ /opt/modules/cdh/hadoop-2.5.0-cdh5.3.6/bin/yarn jar \
/opt/modules/cdh/hbase-0.98.6-cdh5.3.6/lib/hbase-server-0.98.6-cdh5.3.6.jar \
completebulkload /output_file fruit_bulkload
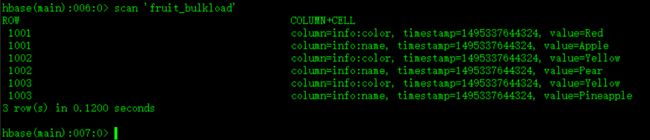
Step5、查看使用bulkLoad方式导入的数据,如图:
* HBase中的自定义MapReduce
在Hadoop的学习阶段,我们了解了如何编写MapReduce代码,那么HBase中自定义MapReduce也是大同小异。接下来我们就看看应该如何操作,实现将文件中的数据或HBase表中的数据通过自定义MapReduce导入到HBase。
案例一:HBase表数据到表数据的导入
Hadoop中:
我们分别继承了Mapper和Reducer两个类,然后编写mapreduce代码
而HTable(HBase)中:
我们要继承的是TableMapper和TableReducer从而编写mapreduce代码
我们依照Hadoop中WordCount的示例,分为3个步骤走:
目标:将fruit表中的一部分数据,通过MapReduce迁入到fruit_mr表中(fruit_mr表是个新的空的表)
Step1、自行建立项目,以来不再赘述请参考上一节内容
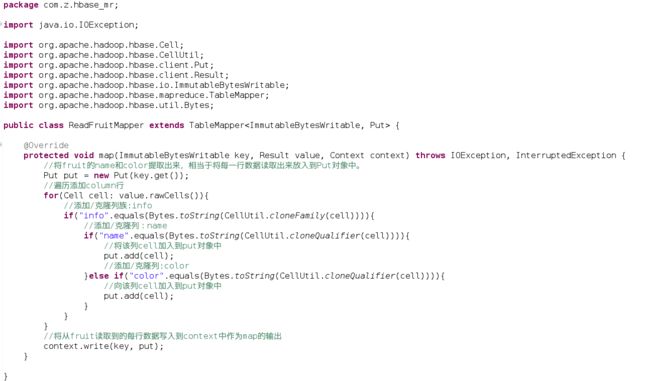
Step2、构建ReadFruitMapper类,用于读取fruit表中的数据
Step3、构建WriteFruitMRReducer类,用于将读取到的fruit表中的数据写入到fruit_mr表中

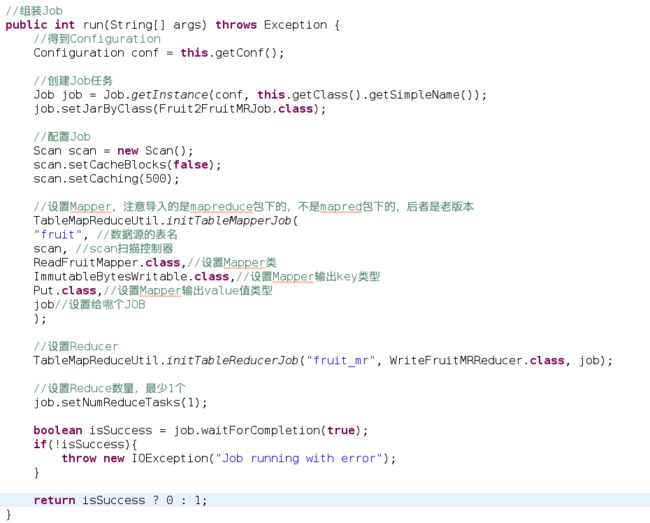
Step4、构建Fruit2FruitMRJob类,用于组装运行Job任务
Step5、主函数中调用运行该Job任务

尖叫提示:导入数据前请确保fruit_mr表是存在的,运行后如图:

案例二:文件数据到HBase表数据的导入
与案例一不同的是,本次是将数据从源文件读取出来,解析后,写入到HBase的某张表中。而此时Mapper不再继承自TableMapper,而是直接继承自Mapper了。
目标:将文件中的数据导入到fruit_mr_from_txt表中
Step1、自行建立项目,以来不再赘述请参考案例一的内容(不新建项目也可以,这个阶段你应该已经懂得怎么弄)
Step2、构建ReadFruitFromHDFSMapper类,用于读取tsv格式的fruit.txt文件中的数据

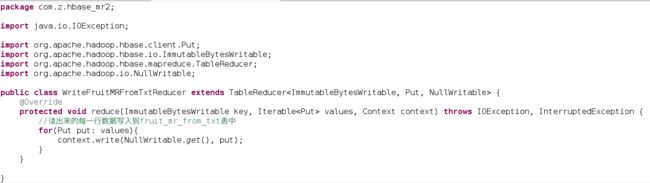
Step3、构建WriteFruitMRFromTxtReducer类
Step4、组装Job

Step5、运行测试

尖叫提示:测试前确保fruit_mr_from_txt表已经创建,测试后scan一下这个表如图:

* 总结
Congratulations!你已经掌握了如何使用MapReduce来操作HBase,这将有助于你在工作中更加灵活的操作数据。
IT全栈公众号:

QQ大数据技术交流群(广告勿入):476966007

下一节:HBase框架基础(四)