前言
食用本文前,需要有对BERT模型基础知识的掌握,因为ERNIE就是在BERT的基础上做的提升与改进。如果你对BERT毫无了解,可以参考我之前的博文《大名鼎鼎的BERT模型》。废话不多说,让我们开始吧!
介绍
BERT模型提出后,可谓是横扫了许多NLP数据榜单,大家也开始纷纷学习这个新型的语义表征模型,并尝试在他的基础上进行改进。ERNIE就是在这个背景下诞生的,ERNIE(Enhanced Representation from kNowledge IntEgration)模型由百度在2019年提出,同时百度发布了基于飞浆 PaddlePaddle 的开源代码与模型,在语言推断、语义相似度、命名实体识别、情感分析、问答匹配等自然语言处理(NLP)各类中文任务上的验证显示,模型效果全面超越 BERT。目前ERNIE已经有1.0和2.0两个版本,本文将基于对应的两篇论文进行阐述。
ps. ERNIE也是芝麻街的人物哦,而且是BERT的朋友
ERNIE1.0
下面主要介绍一下,ERNIE1.0相比于BERT的改进部分。
模型上的改进
我们知道,BERT是对token-level进行建模,这样并没有学到语义单元的完整含义,ERNIE模型中加入了entity-level和phrase-level,用来学习命名实体和语义单元的知识。举个栗子,在Masked LM过程中,“哈[MASK]滨是黑[MASK]江的省会。”这句话中,BERT可以预测出“尔”和“龙”,但是他学习不到“哈尔滨”与“黑龙江”之间的关系,而在ERNIE中通过对entity-level的建模,关于location的信息会被完整的学习到。再来看一个栗子,“[MASK]引起高血糖”这句话,BERT会预测出“糖糖内”,而ERNIE就能预测出“胰岛素”,因为ERNIE在训练中学习到了“胰岛素”和“糖尿病”的关系。
引入对话语料库
为了能够在对话和语义表达上有更好的效果,ERNIE引入了对话语料库,从而构建了一个Dialogue LM(DLM)。训练中,通过生成一些假的Question-Response(QR)对,让模型来判断多轮对话是否真实,其中多伦对话可以表示成 [CLS] tok1 ... tokn [SEP] tok1 ... tokm [SEP] tok1 ... tokl [SEP]。
实验部分
实验大致是在下面五个任务上进行的,结果都比BERT好了约一个百分点。
- Natural Language Inference (XNLI)
- Semantic Similarity (LCQMC)
- Name Entity Recognition(NER)
- Sentiment Analysis(ChnSentiCorp)
- Retrieval Question Answering(Dbqa)
ERNIE2.0
下面讲一下2.0版本相比较于1.0版本有什么改进之处。
引入七大任务
在ERNIE2.0中,预训练过程使用了一个持续学习continual learning的形式引入了七大任务(如下图所示),其实就是依次加入7个任务,后面我们来具体讲一下每个任务在做什么。
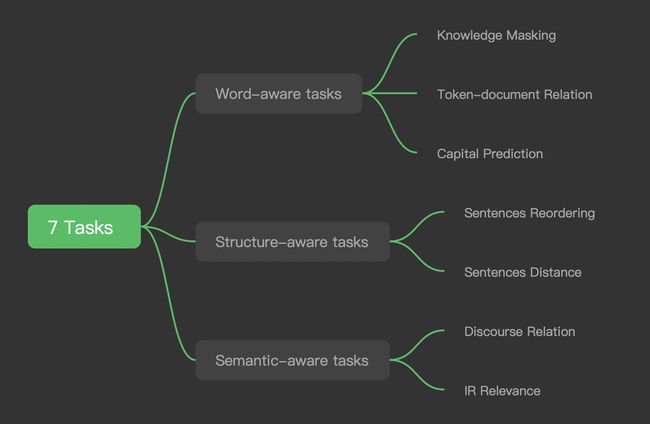
1. Knowledge Masking
这个任务与之前的MLM类似,在训练中mask短语(比如,a series of)或是命名实体(比如,地点LOC,机构ORG,人物PER等)。
2. Token-Document Relation
这个任务用于预测一个token是否出现在原始文档的其他字段中,可用于寻找关键词key words。
3. Capital Prediction
这个任务就很简单了,预测首字母的大小写。因为有些单词大小写不同就会有不同的含义,例如Apple和apple,大写多指苹果公司,小写多指苹果这种水果。
4. Sentence Reordering
这个任务用于学习句子间的关系,训练中会把段落分成n个片段,然后重新组合,做一个k分类问题的预测。
5. Sentence Distance
这个任务归类到一个三分类的问题,用0表示两个句子同文档且相邻,1表示两个句子同文档但不相邻,2表示两个句子不在同一文档中。
6. Discourse Relation
这个任务用于学习句子之间的语义关系。
7. IR Relevance
这个任务用于学习文本在信息检索中的相关性。可以作为一个三分类的问题,来预测query和title之间的关系。0表示强相关,1表示弱相关,2表示不相关。
训练损失
注意在ERNIE2.0中,总的损失是这样计算的:\(Loss = Loss_sequence-level + Loss_word-level\)
实验
实验部分于之前的类似,结果是在中文任务中比BERT模型有了很大的提高。
后续发展
百度研究团队表示,此次技术突破将被应用于多种产品和场景,进一步提升用户体验。未来百度将在基于知识融合的预训练模型上进一步深入研究。例如使用句法分析或利用其他任务的弱监督信号进行建模。此外,百度也会将该思路推广到其他语言,在其他语言上进一步验证。
Reference
- Sun, Y., Wang, S., Li, Y., Feng, S., Chen, X., Zhang, H., ... & Wu, H. (2019). ERNIE: Enhanced Representation through Knowledge Integration. arXiv preprint arXiv:1904.09223.
- Sun, Y., Wang, S., Li, Y., Feng, S., Tian, H., Wu, H., & Wang, H. (2019). Ernie 2.0: A continual pre-training framework for language understanding. arXiv preprint arXiv:1907.12412.