本着“三百六十行,行行转生信”的崇高宗旨,基础科研、生物学出身的小编在今年成功进入生信圈,入坑的时候才发现贵圈真的是太乱了,不仅要敲的了代码,跑的了数据,而且跨行不太成功的我还要怒扛鱼饲料、单刀斩鲤鱼。忽然想起了那天在夕阳下拉网的我,那是我逝去的青春(本人海洋生物专业的偶)。
入坑了就要坚持下去啊有没有?不然毕不了业谁会对我负责呢。于是小编收起了不学无术的泪水。毕竟搞生信也是高薪行业永不失业,学好了生信就可以升职加薪,出任CEO,迎娶白富美,走上人生巅峰。
于是小编开始了当代研究生的一贯学习套路“看文献”,果然是一脸懵逼啊有没有?因为有轻伤不下火线的战斗精神,小编一口气看了20多篇文献,几乎每一篇文献里都有利用illumina双端测序后得到多少条reads,所以小编搜集各方资料,头悬梁、锥刺股,对illuemina二代测序技术原理做了一个总结,希望对刚入生信圈的小伙伴们有所帮助。闲言少叙,书归正文。
有些同学就比较好奇,既然叫做二代测序,那就是还有一代测序喽?当然了,接下来我就一代测序与二代测序原理的差别简单梳理一下,这样你就知道长江后浪推前浪,一代更比一代强。
一代测序
第一代测序是由生物化学家桑格(Frederick Sanger)发明的,因此被称为桑格法测序,也被称为“双脱氧测序”。为什么称为“双脱氧测序”呢,这主要是基于它的测序原理。在DNA链的合成过程中加入ddNTP(双脱氧核苷酸),由于ddNTP的2’和3’都不含羟基,其在DNA的合成过程中不能形成磷酸二酯键,因此可以用来中断DNA合成反应,在4个DNA合成反应体系中分别加入一定比例带有放射性同位素标记的ddNTP(分为:ddATP,ddCTP,ddGTP和ddTTP),通过凝胶电泳和放射自显影后可以根据电泳带的位置确定待测分子的DNA序列。
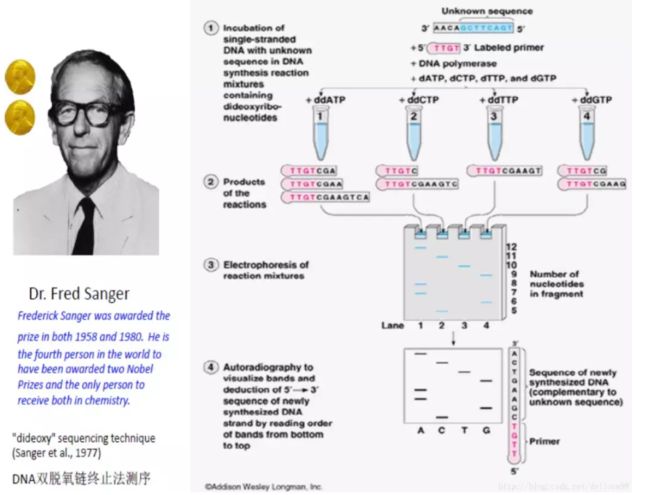
测序过程如图所示:玻璃毛细管中的丙烯酰胺溶液在紫外线的电离作用下发生聚合反应,变成聚丙烯酰胺凝胶,在电场条件下由于不同长度的DNA片段在聚丙烯酰胺凝胶中的游动速度不同,而且是从负极游向正极,因此可以分离出不同长度的DNA片段。
在毛细管正极一端用激光进行照射,并用分光的光学传感器把不同颜色的荧光强度记录下来。越先到达毛细管正极的DNA片段越短,它聚合的终止位置离聚合起始位置越近,因此它的颜色就反映了离3’末端最近的碱基的种类。然后我们就会得到峰值图,图的横轴代表电泳时间,纵轴代表荧光强度,然后我们可以根据峰的颜色判断出依次是哪种碱基。峰越高越尖说明这个碱基的判读越准确。
二代测序
第二代高通量测序也称为下一代测序技术,相比于第一代测序通量更高、速度更快、成本更低,主要有样本制备、文库构建、测序反应等过程。由于原理和技术的不同,二代测序有诸多的测序平台,我们主要为大家介绍illumina 二代测序原理和过程。

00 常用概念
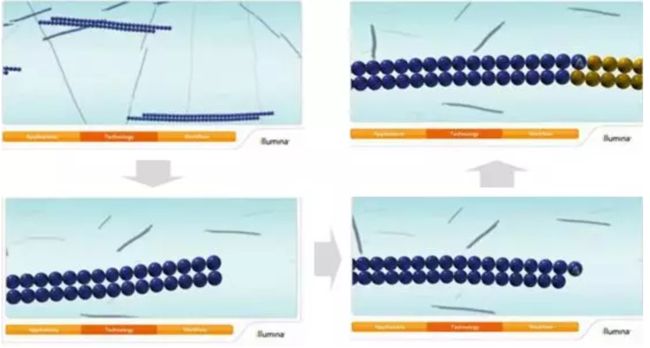
首先大家请看下图,这是一个flowcell,大家可以叫它“泳池”,测序反应就发生在它上面。同时它上面有8条lane,大家可以叫它“泳道”。

每一条“泳道”的内表面做了专门的化学修饰,主要是两种DNA引物,如下图所示,(也就是图二中的绿色和黄色这两种)。
这两种DNA引物的序列和接下来要测序的DNA文库的接头序列是互补的。这两种DNA引物是种植在“泳道”内表面的,大家就要问了:它是如何种植在泳道内表面的,为什么要将它种植在内表面呢?它是通过共价键连接到内表面的,之所以要将它连接在内表面是因为在后面的测序过程中会有大量的液体要流过这个“泳池”,如果不将它连接在上面的话,这些液体就会将它冲走,够直白了吧。下面正式开始介绍测序反应。
01 建库
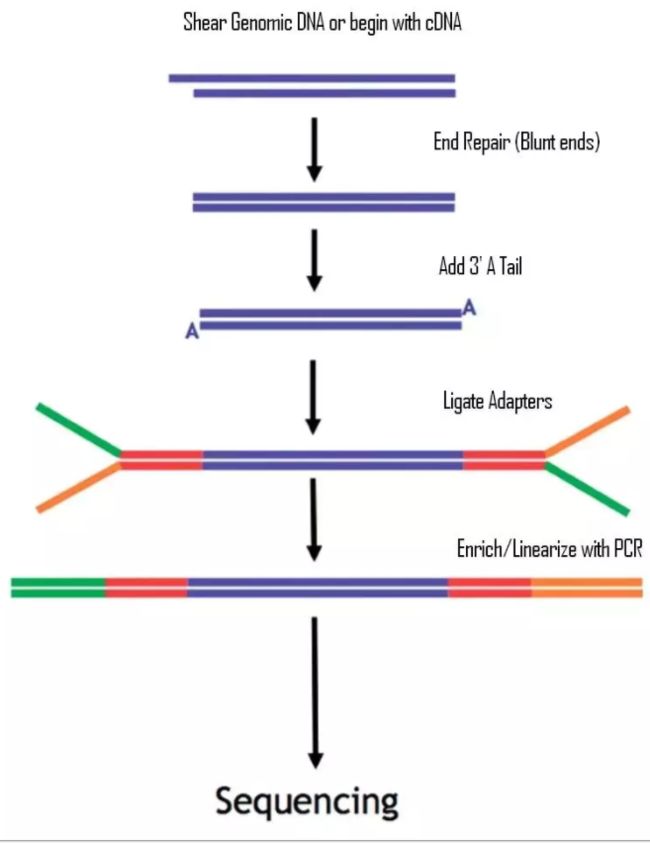
首先给大家说一下什么是DNA文库,所谓的DNA文库就是许多两头接上了特定接头的DNA片段混合物。为什么是特定接头?因为它是人为特地加上去的已知序列。和上面种植在“泳池内表面的引物序列是互补的”。
下面正式开始建库:
1、 首先把基因组DNA用超声波打断;
2、 打断之后会出现末端不平整的情况,所以我们先要将它补齐成平末端;
3、 补平之后要在3’端使用klenow酶加上一个特异性碱基A;
4、 加上A之后就可以用连接酶加上特异性接头;
5、 连好了接头的DNA混合物我们就称为DNA文库;
6、 然后进行PCR扩增,以保证我们的DNA样品浓度能够达到上机的要求。
02 桥式PCR
什么是桥式PCR?桥式PCR是把DNA文库种植到flowcell上去,然后进行PCR扩增的过程。因为文库DNA片段两头的特异性接头和种植在芯片上的引物是互补的,所以会产生互补杂交。
桥式PCR流程如下:
1、 首先把文库加入到flowcell上,等文库和flowcell上的引物杂交完之后加入dNTP和聚合酶,就会以文库为模板合成一条新的互补链。
2、 在flowcell中加入NaOH碱溶液使DNA双链解链,然后文库那条链会被冲走,新合成的链由于与种植在lane内表面的引物连接,所以会被保留。
3、 在flowcell中加入中性液体中和碱液,使环境变为中性。这时DNA链上的另外一端会弯曲下来与另一个引物发生互补杂交。加入聚合酶和dNTP,聚合酶沿着第二个引物,合成出一条新的链。
4、 再加入碱液,使两条链解开,然后再加入中和液,两条DNA单链会和新的引物杂交互补,再加酶和dNTP,又从新的引物合成新的链。
5、 连续重复第四步,DNA链的数量就会以指数方式增长。

桥式PCR完成之后,要把合成的双链变成可以测序的单链,可以通过化学反应把一个引物上的一个特定基团切掉,然后加入碱溶液使双链解链,切断了的那根DNA链就会被冲走,这样就得到单链。再加入中性溶液,中性溶液中加入测序引物就可以开始测序了。
读取Read1
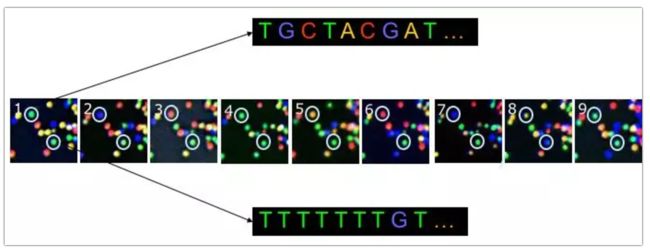
测序时需要加入带荧光标记的dNTP和聚合酶,在聚合酶作用下dNTP会根据碱基互补的原则与模板链互补生成一条新链。但是,dNTP的一个特点就是它的3’末端是被一个叠氮基团堵住的,所以它一个循环只能延长一个碱基。延长一个碱基之后就用水把多余的dNTP和聚合酶洗掉,然后进行激光扫描,根据发出来的颜色判断加入的是哪种碱基。加入的4种dNTP所标的荧光素都不一样,根据红黄蓝绿判断加入的是哪种碱基,然后得出与它互补的DNA链上的碱基,这就完成了一个循环。
一个循环结束之后就加入一些化学试剂把叠氮基团和标记的荧光基团切掉,使3’端的羟基暴露出来,再加入新的dNTP和聚合酶开始第二轮循环。不断重复这个过程,就可以将文库DNA片段一端的序列读取出来,称为“reads1”。
读取Index
什么是index?因为illumina 的测序通量很大,一个样本用不了太多的DNA。因此在文库的接头上做了一些标记,每一个样本都有一个特定的接头,每一个接头里面有特定的序列叫做index。
如何读取index的序列?要读取index的序列,先用碱把测完“read1”序列的链解链掉,然后加入中性液,再加入“read2”的测序引物,“read2”引物的结合位点刚好在index序列的旁边,然后开始进行第二轮测序,一般读特异接头的6-8个碱基,然后就可以知道这一段DNA来自哪个样本。

双端测序
双端测序是illumina的核心技术,简单来说就是将一条DNA链的一端测序得到“read1”,然后再测出互补链的与“read1”互补的这段的序列,得到“read2”。图九是双端测序概念图。Read1的测序过程已经在文章中交代过。测“read2”需要倒链。倒链的过程是先让测“read1”的DNA合成双链,有了互补链之后,用化学试剂将原来的模板链从根部切断。然后从互补链上开始进行“read2”的测序,测序原理同“read1”测序原理相同。
小结
总而言之,第一代测序的优点是读长较长,准确性高;缺点是通量低,成本较高;而二代测序不仅准确性高、通量高,而且成本低,只是相对于一代测序读长较短。
读完这篇帖子之后相信大家对于一代测序和二代测序技术有了更深的认识。小编搜集各方资料再结合自己对测序技术的理解码出这篇帖子。希望对刚接触分子生物和生物信息的小伙伴有所帮助。
图片来源于网络,侵权请联系删除。
更多信息,关注“科研猫”公众号
胖雨小姐姐
or
折耳猫小姐姐

- 往期热门干货 -
科研绘图
立即学习>
数据挖掘
立即学习>
精通R语言
立即学习>
网络分析
发现更多>
生存分析
发现更多>
功能富集
发现更多>
更多科研新鲜资讯、文献精读和生物信息技能
请关注科研猫公众号

未经许可请勿随意转载,
版权事宜由上海辰明律师事务所提供法务支持