前言
好几个月都没写点东西,更新博客了。果然,懒惰是人类的天性啊!趁着记忆清晰,对前些日子部门内部的建模比赛进行知识梳理,总结经验与心得,加深印象,以备不时之需。
本文博客位置
评价风控(模型)的标准
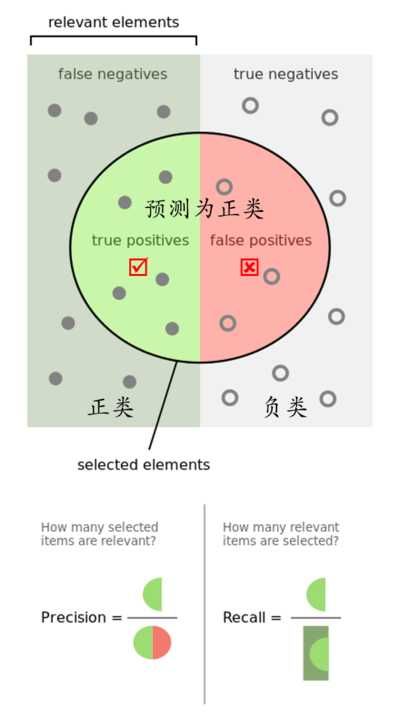
【混淆矩阵】
本次建模是关于风控反欺诈,对非金交易客户进行预测,判断是否为欺诈客户。这里暂先撇开风控建模相关的事宜,我们来谈谈评判风控的标准是什么。
最好的风控效果其实是在所有客户中能100%鉴别出欺诈客户,然而现实是:这样的判断力太难实现了。在我们认定欺诈的客户中必然会误杀部分“好”客户;而在认定的非欺诈客户中同样也存在漏网之鱼(欺诈客户)。
因此,这里我们需要引进混淆矩阵这个概念。
| (预测) 1 | (预测) 0 | |
|---|---|---|
| (真实) 1 | TP | FN |
| (真实) 0 | FP | TN |
这里的0、1与网上关于混淆矩阵的介绍正好相反。大部分的资料都会把好客户作为把目标客户1,而我们的目标是要预测欺诈客户,所以欺诈客户为1,非欺诈客户为0。通过预测与真实的差异,得到以下4个指标:
- TP:本身就是欺诈客户,同时也被判断为欺诈客户(True Positive)
- TN:本身是好客户,同时被判断为好客户(True Negative)
- FN:欺诈客户被认为是好客户,即漏网之鱼(False Negative)
- FP:好客户却被判为欺诈客户,即误杀掉的(False Positive)
为了方便记忆这四个单词,可采取如下方法:Positive/Negative指的是预测的结果,如果预测准确,前面加上一个True(真);预测错了的话就是False(假)。此外,由混淆矩阵又引出了以下两个概念(之后会有用到):
- 召回率:简称为TPR,计算公式为
TPR=TP/(TP+FN)——所有真实的“1”中,有多少被模型成功选出 - 误报率:简称为FPR,计算公式为
FPR=FP/(FP+TN)——所有真实的“0”中,有多少被模型误判成1
假设现在我们已经有了一个预测模型,得到的是每个客户会发生欺诈的概率,同时画出一个关于欺诈概率的频数分布图,如下:
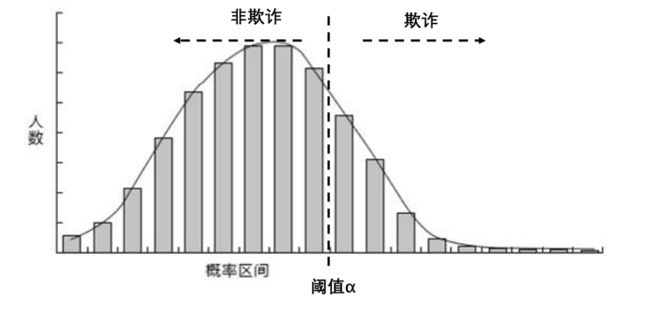
我们需要一个阈值,来划分欺诈与非欺诈用户。如果为50%,那么概率大于50%的都认为是欺诈用户(再次注意,这里的概率指的是欺诈的概率);如果阈值调整至70%,原本概率为60%的欺诈客户“张三”,将会被判定为非欺诈。因此,阈值的选取至关重要!
我们可以把原样本的欺诈/非欺诈客户分开,单独画频数分布图。对于欺诈客户的概率分布,我们给定一个评判的标准(阈值),则左侧灰色部分为FN(欺诈用户漏网了,认为是好人),右侧阴影部分为TP(本身为欺诈,认定为欺诈)。
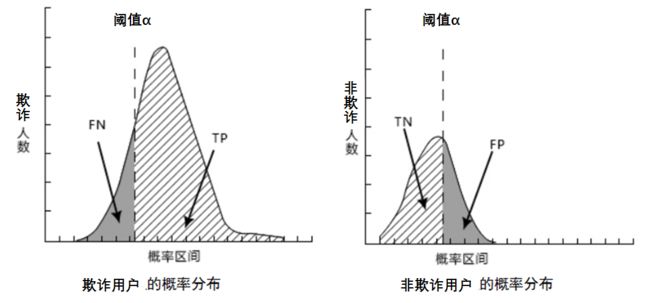
我们发现,无论阈值标准线往左往右移动,势必会导致TP(被正确判断的欺诈用户)与TN(被正确判断的非欺诈用户)一方增大与一方减小。这样也正解释了风控力度的大小。阈值标准线越往左,风险控制越苛刻,漏网之鱼(FN)就越小,但与此同时非欺诈客户量(TN)也越小,原本正常的客户被误判为欺诈(FP)的也越多。
【ROC与AUC】
那么阈值究竟这么取比较好呢?这其实是个很有考量的技术活。还记得我们之前提及的召回率(TPR)与误报率(FPR)么。在给定TPR的情况下,FPR越小,说明误判的“好人”越少;同理,在给定FPR(能接受一定好人误判的)的情况下,如果TPR越大,说明抓出来的“坏人”也越多。
假如阈值取0.6,我们把大于0.6的标记为1(违约),小于0.6的标记为0(正常),同时可以计算出TPR与FPR。同理,如果阈值换成了0.5,我们又得到一组(TPR2,FPR2)。于是,我们以FPR为横坐标,TPR为纵坐标,把不同的点连成一条曲线,就是ROC曲线。
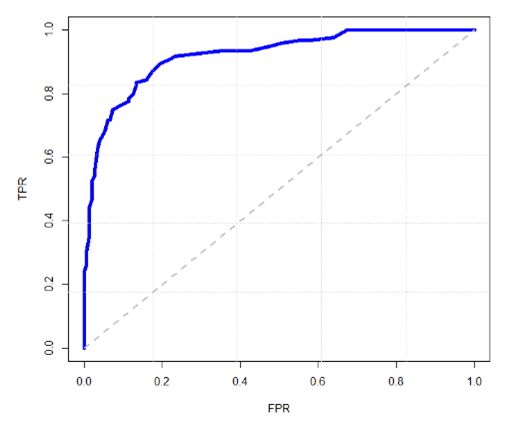
其实TPR与FPR是正相关的,也就是说:正确判断出“1”的数量增加,必然会付出代价(误判为“1”的FP也会增加),ROC曲线上也能反映出这种变化趋势,从△TPR>△FPR到△TPR<△FPR。所以这里就回答了我们之前提出的问题:理想的阈值应该取△TPR=△FPR时所对应的阈值。
当我们有2个模型,画出了两条ROC曲线时,可以利用ROC曲线下的面积,即AUC或者C-统计量,来判断模型的效果。AUC越高,说明模型的分辨效果越好。
【提升图与洛伦兹曲线】
除了ROC曲线与AUC指标,常用的模型评价还有K-S曲线,而K-S曲线又是由洛伦兹曲线变换之后得到,所以这里我们结合《信用风险评分卡》书中的例子来介绍相关概念。
假设10000笔借款,实际发生了700笔坏账。如果我们把10000笔随机分成10等分,那么每等分的坏账应该为70笔。
再假设我们有一个模型。通过这个模型,我们能给出每笔借款可能发生坏账的概率,将概率从高到低排序。排名越靠前的,发生坏账的可能性越大。我们对排好序的序列也分成10等分。那么应该是,越靠前的等份里,包含的坏人应该越多,越靠后的等份里,包含的坏人要更少(好人更多)。一个理想的模型,应该是这个排序与真实的排序是一样的,即,从一个分割点开始,靠前的都是坏人,靠后的都是好人。
理想是美好的,然而现实是残酷的,我们总会误杀好人,也会漏掉坏人,能做的是把更多的坏人排到越前面。回到“提升图”相关内容,我们对之前排好序且10等份的数据计算各自等份内的违约数、占比与累计占比,如图:
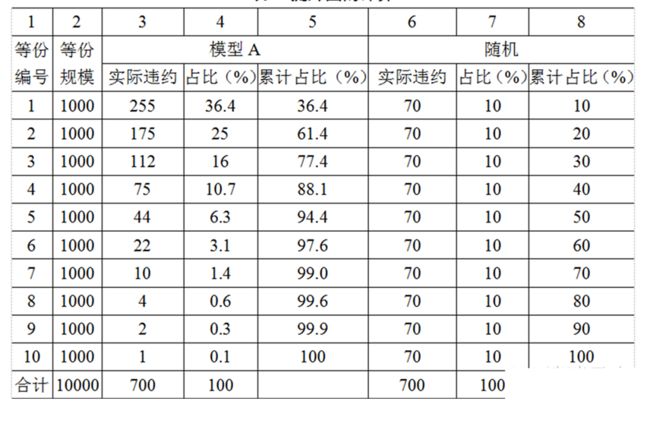
把每份违约占比(实际与随机即第4与第7列)放到一张柱形图上,即提升图。
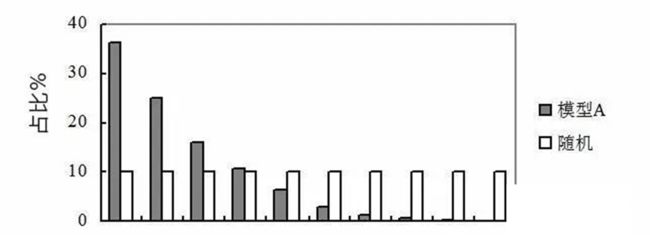
也可以将累计占比(实际与随机即第5与第8列)放到一张曲线上,即洛伦兹曲线。
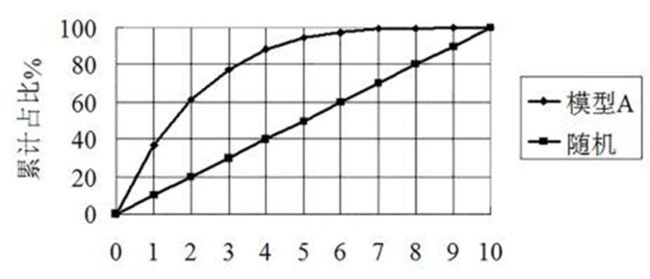
有了洛伦兹曲线,我们就可以直观的比较两个模型的优劣了。我们在一张图上画上两个模型的洛伦兹曲线A与B,假定用户群体中真实的欺诈率是40%(即理想的模型中所有的违约用户全部集中在前4个等份)。我们可以看到,模型A识别出88%的违约用户,而B模型只能分离出78%的用户,所以模型A要比模型B效果好。所以以后我们只要看哪个模型越往“左上角鼓”,效果就越好。
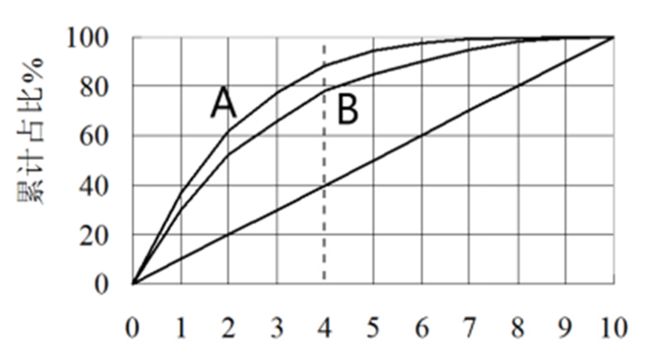
【K-S曲线】
现在我们对“好人”,“坏人”分别画洛伦兹曲线,这两条曲线的差值,就是K-S曲线。如下图所示,假定我们选取阈值为20%(即认定概率大于20%的用户为违约用户),则该模型可以挑选出60%的违约用户,但同时会误判8%的“好人”。那么K-S曲线在违约率上的值就是60%-8%=52%。
K-S曲线主要是验证模型的区分能力,曲线中的最大值就是K-S统计量。K-S统计量越大,就越能把“好”“坏”区分开来,模型效果也就越好。
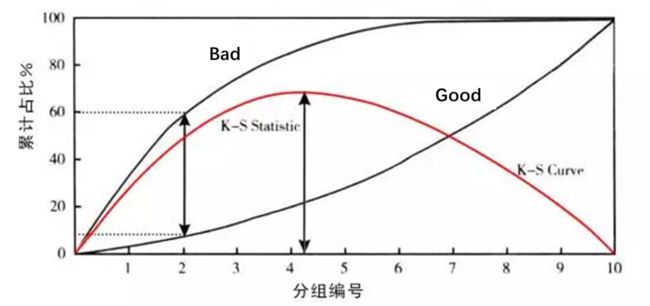
我们再深入一层,针对60%与8%这两个数字细想一下:这60%不正是在设定20%阈值情况下,TPR的定义么。同理,8%对应着FPR。所以K-S曲线实际上就是以10%的倍数为横坐标,分别以TPR与FPR的值为纵坐标画出的两条曲线的差值。而KS=max(TPR-FPR)即两条曲线的最大差值,当KS最大时,也就是△TPR=△FPR,这不就是我们之前在ROC曲线上找到的最优阈值么?所以无论是ROC曲线还是K-S曲线,其本质上是一样的。