3.1 超参调试的简单介绍
1. DNN的常见超参
(1)学习率 ☆☆☆☆☆非常重要;
(2)训练参数Mini_batch_size ☆☆☆比较重要;
(3)与优化算法相关的参数:比如momentum的(默认0.9)参数,Adam的(默认0.9)、(默认0.999)、参数(默认10^-8),最后一个无关紧要,前三个一般重要,但基本上使用默认值(括号内)就可以了;
(4)学习率衰减参数及衰减方式:一般重要;
(5)网络结构参数:如隐藏层层数、各层神经元个数
2. 寻找合适的超参的正确姿势
1)不要用网格搜索,而用随机的一些组合
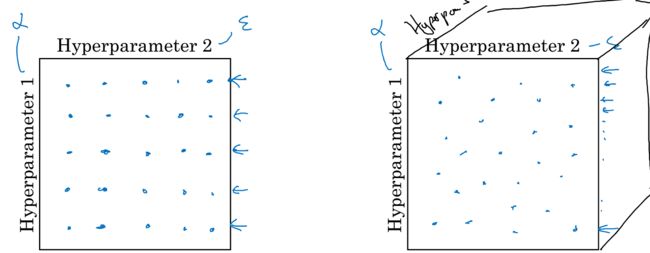
如上图所示,左侧为网格搜索。对于DNN而言,由于不同的参数的重要程度不一样(比如和),使用网格搜索时,设定了固定的,而去尝试了若干的,是没有太多意义的。右侧为随机设定25组参数组合,这样能够尝试更多的
2)参数搜索应遵循从粗糙到精细的步骤
当已经初步试验出某个区域内的超参效果最好,则锁定这片区域进行更精细的搜索。如下图所示

3.2 为超参选择设定合适的尺度
标题解释:尺度(scale)的翻译并不算准确。举个栗子来说:有一个参数的选取范围是1~1000,假设我们按照1,2,3,4,5,6,7,8,...,1000的方式来寻找参数,就叫叫线性尺度;而假设我们的寻找方式是1,10,100,1000,这就叫指数尺度。本节是在简单描述不同的参数所对应的合适的尺度。
隐藏层层数、隐藏层神经元数等超参,一般都使用线性尺度进行搜索
学习率、等参数,一般用指数尺度进行搜索。
3.3 超参数调试的两种方式
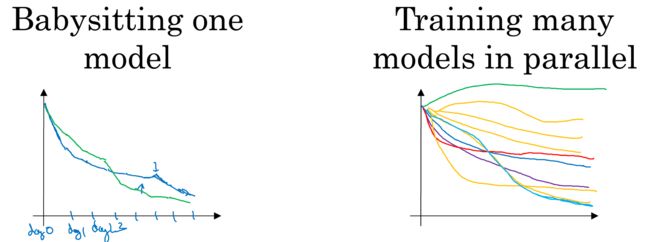
第一种方式:边训练边调试。比方今天开始训练,一天结束了收敛趋势还不错,那么此时尝试加大一下学习率。这种方式像是在精细地培养一个模型,在计算资源有限的时候可以这样干。
这与之前的调参经验不同,在使用GBDT算法建模的时候,通常是设定好一组超参,然后pia训出一个模型,观察该模型的过拟合欠拟合情况,再重新设定一组超参,看看效果会不会更好。私以为这种区别主要是由算法本身的特性导致的,GBDT系的算法通常训练是非常快的,一般就几分钟,但DNN可能要到天级。
第二种方式:同时训练很多模型,每个模型设定不同的超参,最后取效果最好的那个。就像鱼产卵,大家野蛮生长好了。适用于不缺计算资源的时候。
两种方式如下图所示:
3.4 ~ 3.7 Batch Normalization
1. Batch Normalization是什么操作?
简单来说,Batch Normalization就是基于batch把神经网络的隐藏层值也进行标准化,从而达到更好的训练效果。从前向传播角度来看,不带Batch Normalization的FP就是“加权求和 → 激活函数”的循环往复,而带batch normalization的FP则是“加权求和 → 标准化 → 尺度缩放 →激活函数”的循环往复。
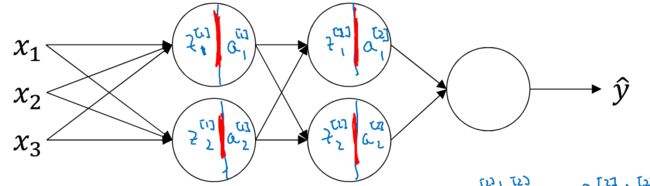
以上图为例,从第一个隐藏层向第二个隐藏层进行前向传播时,本来的FP步骤如下:
i. 加权求和
ii. 激活函数
加上batch normalization的FP步骤如下:
i. 加权求和 注意去掉了偏执项。
ii. 基于batch或当前的mini_batch求出的均值和标准差,且
iii. 尺度缩放(rescale)
iv. 激活函数
关于上述步骤,有以下基点需要注意:
① 第ii步中,求解均值和方差的reduce运算是针对batch或mini_batch的,对本身而言则是point-wise的;
② 第iii步的rescale也是针对z的每个元素单独进行缩放,所以和都是个vector,且元素数等于第二个隐藏层的神经元数;
③ 是像一样的待学习的参数,在使用BP进行梯度下降时,这些参数都是要迭代的。
2. Batch Normalization的作用?
1)应对分布发生变化的问题(没有太看懂,略)
2)有一定的正则化作用(没有太看懂,略)。
3. 预测/测试时的Batch Normalization
如第1部分所言,中间有一步是进行标准化,那么需要基于batch或mini_batch求解均值和方差。而用模型进行预测或测试时,有可能是针对单个样本的,此时所谓的均值和方差怎么来?很艰难,提前存的。有可能是① 训练完模型后,使用整个训练集求出各个输入层及各个隐藏层值的均值和标准差,存好备用;② 在训练过程中使用类似“指数加权平均”的方式动态地存储这些值。总之就是一句话,提前存好,预测/测试时直接调用即可。
3.8 ~ 3.9 SoftMax激活函数
1. 什么是SoftMax激活函数
sigmoid、tanh、ReLU等激活函数都是对单个值做一个非线性变换,而SoftMax则是vector2vector,可以文字描述为:加权求和后,point-wise的求指数(x → e^x),再缩放成和为1的形式。如下图:

2. SoftMax可解决的问题
(只描述,知其然不知其所以然)
从softmax的输出形式上看,其特别像是给出了一个多分类问题中,该样本属于各个类别的概率值所构成的向量,其实际含义也确实如此。
如果说逻辑回归给定阈值后,就相当于在特征空间中划定了一个超平面,用于划分成两个类别,那么softmax就是在特征空间划定了多个超平面边界,区分了多个类别。如下图示意
3. SoftMax所用的损失函数
从前文中可知,SoftMax多用于最后一层(输出层),可以理解为,softmax的结果就是预测值了,那么这个预测值和真实值(一个one-hot向量)之间的差异用什么损失函数衡量?答案是softmax_cross_entropy(softmax所用的交叉熵),形式如下:(与LR的交叉熵本质是一回事)
1)针对单个样本,模型预测值(softmax输出值为),那么损失为;C是类别数。
2)针对整个数据集的损失则为
4. 有没有HardMax?
把一个向量中的最大值位置设为1,其它位置设为0,这就是HardMax。
→
3.10 ~ 深度学习框架
略