概括:上一节学习了pyspider框架,这一节我们来看一下Scrapy的强大之处。他应该是目前python使用的最广泛的爬虫框架。
一、简单实例,了解基本。
1、安装Scrapy框架
这里如果直接pip3 install scrapy可能会出错。
所以你可以先安装lxml:pip3 install lxml(已安装请忽略)。
安装pyOpenSSL:在官网下载wheel文件。
安装Twisted:在官网下载wheel文件。
安装PyWin32:在官网下载wheel文件。
下载地址:https://www.lfd.uci.edu/~gohlke/pythonlibs/
配置环境变量:将scrapy所在目录添加到系统环境变量即可。
ctrl+f搜索即可。
最后安装scrapy,pip3 install scrapy
2、创建一个scrapy项目
新创建一个目录,按住shift-右键-在此处打开命令窗口
输入:scrapy startproject tutorial即可创建一个tutorial文件夹
文件夹目录如下:
|-tutorial
|-scrapy.cfg
|-__init__.py
|-items.py
|-middlewares.py
|-pipelines.py
|-settings.py
|-spiders
|-__init__.py
文件的功能:
scrapy.cfg:配置文件
spiders:存放你Spider文件,也就是你爬取的py文件
items.py:相当于一个容器,和字典较像
middlewares.py:定义Downloader Middlewares(下载器中间件)和Spider Middlewares(蜘蛛中间件)的实现
pipelines.py:定义Item Pipeline的实现,实现数据的清洗,储存,验证。
settings.py:全局配置
3、创建一个spider(自己定义的爬虫文件)
例如以爬取猫眼热映口碑榜为例子来了解一下:
在spiders文件夹下创建一个maoyan.py文件,你也可以按住shift-右键-在此处打开命令窗口,输入:scrapy genspider 文件名 要爬取的网址。
自己创建的需要自己写,使用命令创建的包含最基本的东西。
我们来看一下使用命令创建的有什么。

介绍一下这些是干嘛的:
name:是项目的名字
allowed_domains:是允许爬取的域名,比如一些网站有相关链接,域名就和本网站不同,这些就会忽略。
atart_urls:是Spider爬取的网站,定义初始的请求url,可以多个。
parse方法:是Spider的一个方法,在请求start_url后,之后的方法,这个方法是对网页的解析,与提取自己想要的东西。
response参数:是请求网页后返回的内容,也就是你需要解析的网页。
还有其他参数有兴趣可以去查查。
4、定义Item
item是保存爬取数据的容器,使用的方法和字典差不多。
我们打开items.py,之后我们想要提取的信息有:
index(排名)、title(电影名)、star(主演)、releasetime(上映时间)、score(评分)
于是我们将items.py文件修改成这样。
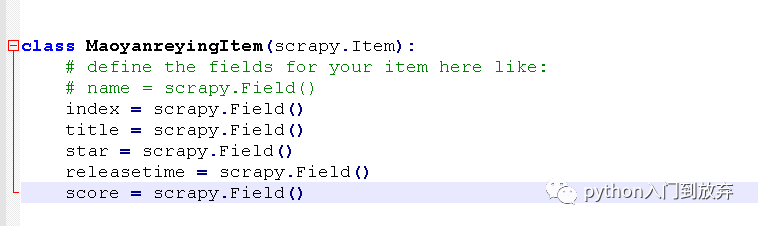
即可。
5、再次打开spider来提取我们想要的信息
修改成这样:
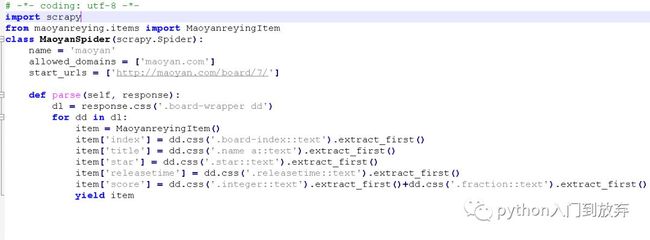
好了,一个简单的爬虫就写完了。
6、运行
在该文件夹下,按住shift-右键-在此处打开命令窗口,输入:scrapy crawl maoyan(项目的名字)
即可看到:
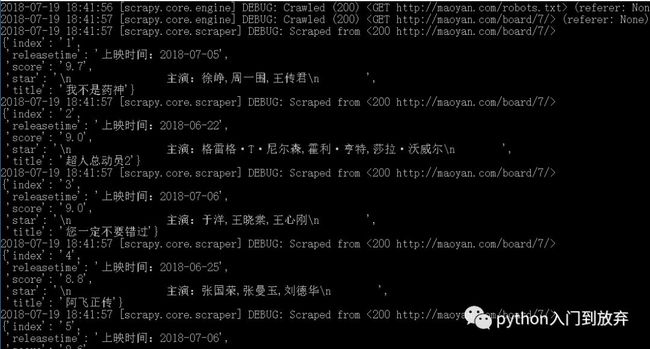
7、保存
我们只运行了代码,看看有没有报错,并没有保存。
如果我们想保存为csv、xml、json格式,可以直接使用命令:
在该文件夹下,按住shift-右键-在此处打开命令窗口,输入:
scrapy crawl maoyan -o maoyan.csv
scrapy crawl maoyan -o maoyan.xml
scrapy crawl maoyan -o maoyan.json
选择其中一个即可。当然如果想要保存为其他格式也是可以的,这里只说常见的。这里选择json格式,运行后会发现,在文件夹下多出来一个maoyan.json的文件。打开之后发现,中文都是一串乱码,这里需要修改编码方式,当然也可以在配置里修改
(在settings.py文件中添加FEED_EXPORT_ENCODING='UTF8'即可),
如果想直接在命令行中修改:
scrapy crawl maoyan -o maoyan.json -s FEED_EXPORT_ENCODING=UTF8
即可。
这里自己试试效果吧。
当然我们保存也可以在运行的时候自动保存,不需要自己写命令。后面介绍(我们还有还多文件没有用到呦)。
二、scrapy如何解析?
之前写过一篇文章:三大解析库的使用
但是scrapy也提供了自己的解析方式(Selector),和上面的也很相似,我们来看一下:
1、css
首先需要导入模块:from scrapy import Selector
例如有这样一段html代码:
html='
1.1、首先需要构建一个Selector对象
sel = Selector(html)
text = sel.css('.cla::text').extract_first()
.cla表示选中上面的div节点,::text表示获取文本,这里和以前的有所不同。
extract_first()表示返回第一个元素,因为上述 sel.css('.cla::text')返回的是一个列表,你也可以写成sel.css('.cla::text')[0]来获取第一个元素,但是如果为空,就会报出超出最大索引的错误,不建议这样写,而使用extract_first()就不会报错,同时如果写成extract_first('123')这样,如果为空就返回123
1.2、有了选取第一个,就有选取所有:extract()表示选取所有,如果返回的是多个值,就可以是这样写。
1.3、获取属性就是sel.css('.cla::sttr('class')').extract_first()表示获取class
1.4、获取指定属性的文本:sel.css('div[class="cla"]::text')
1.5、其他写法和css的写法如出一辙。
1.6、在scrapy中为我们提供了一个简便的写法,在上述的简单实例中,我们知道了response为请求网页的返回值。
我们可以直接写成:response.css()来解析,提取我们想要的信息。同样,下面要说的XPath也可以直接写成:
response.xpath()来解析。
2、Xpath
Xpath的使用可以看上面的文章:三大解析库的使用
注意:获取的还是列表,所以还是要加上extract_first()或者extract()
3、正则匹配(这里用response操作)
例如:response.css('a::text').re('写正则')
这里如果response.css('a::text')匹配的是多个对象,那么加上正则也是匹配符合要求的多个对象。
这里如果想要匹配第一个对象,可以把re()修改成re_first()即可。
注意:response不可以直接调用re(),response.xpath('.').re()可以相当于达到直接使用正则的效果。
正则的使用:万能的正则表达式
三、Dowmloader Middleware的使用
本身scrapy就提供了很多Dowmloader Middleware,但是有时候我们要修改,
比如修改User-Agent,使用代理ip等。
以修改User-Agent为例(设置代理ip大同小异):
第一种方法,可以在settings.py中直接添加USER-AGENT='xxx'
但是我们想要添加多个User-Agent,每次随机获取一个可以利用Dowmloader Middleware来设置。
第一步将settings中的USER-AGENT='xxx'修改成USER-AGENT=["xxx","xxxxx","xxxxxxx"]
第二步在middlewares.py中添加:

from_crawler():通过参数crawler可以拿到配置的信息,我们的User-Agent在配置文件里,所以我们需要获取到。
方法名不可以修改。
第三步在settings.py中添加:

将scrapy自带的UserAgentmiddleware的键值设置为None,
自定义的设置为400,这个键值越小表示优先调用的意思。
四、Item Pipeline的使用。
1、进行数据的清洗
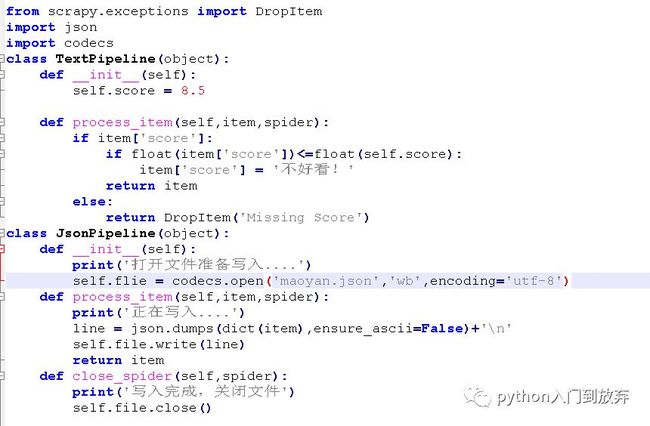
在一的实例中我们把评分小于等于8.5分的score修改为(不好看!),我们认为是不好看的电影,我们将pipeline.py修改成这样:

在setting.py中添加:

我们执行一下:
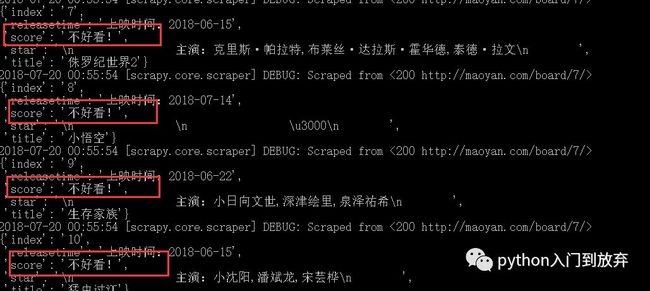
2、储存
2.1储存为json格式
我们将pipeline.py修改成这样:
在setting.py中添加:

表示先执行TextPipeline方法,再执行JsonPipeline方法,先清洗,再储存。
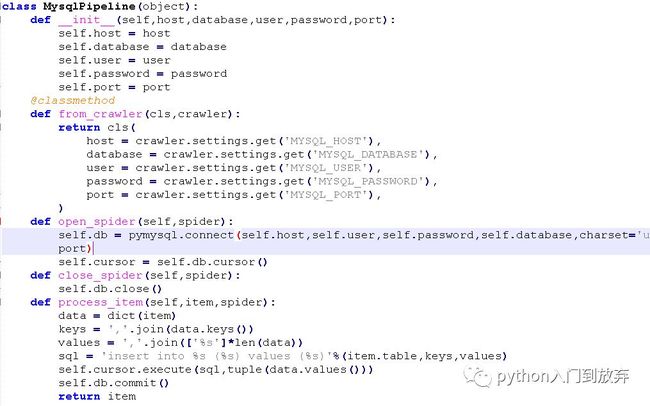
2.2储存在mysql数据库
首先在mysql数据库中创建一个数据库maoyanreying,创建一个表maoyan。
我们将pipeline.py修改成这样:
在setting.py中添加:
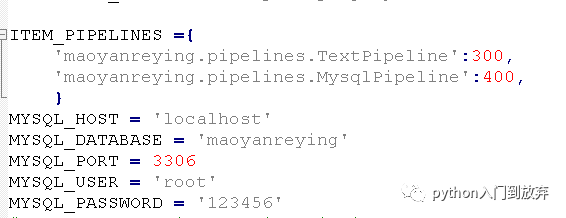
即可
完。