说明一下,本次源码是基于jdk1.8的。
我在了解,学习一个东西的时候,首先要了解清楚跟它有关的都有哪些东西,这些东西之间有着怎样的关联、结构。所以,我会首先选择从大处着眼,理清整个集合的层次关系,以及ArrayList它在整个集合的位置。
从ArrayList这个类开始,一层一层向上找,终于经过一番不太愉快的努力之后,终于做出了一副图(我就先将就着看吧)
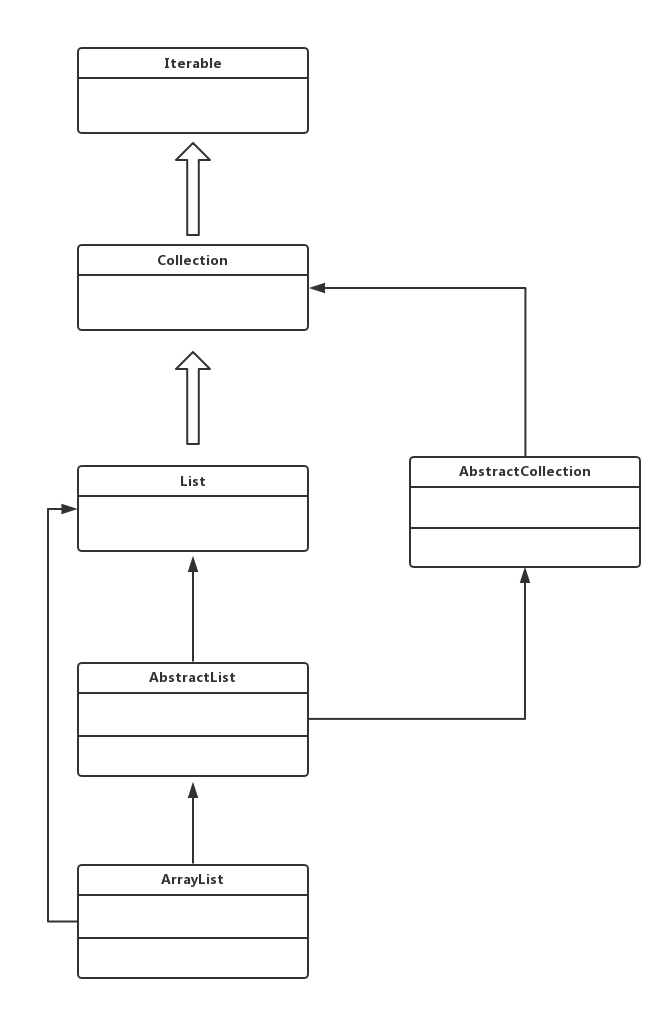
从这幅奇丑无比的图中,我们可以忍着痛暂时看出ArrayList集合在Collection这个框架中的一个层次。
接下来我要开始庖丁解牛了,虽然刀法不怎么样。
ArrayList的声明:
public class ArrayList extends AbstractList
implements List, RandomAccess, Cloneable, java.io.Serializable
从声明中,可以看到有泛型的存在。泛型有一种较为正式的称呼“参数化类型”,从“参数化”这个字面上去联想,就比较容易理解这个概念了。一个函数声明了它的调用参数之后,只要还没有对这个函数进行调用,那么它的参数的值也就没有确定下来,只有当调用了该函数,传递了相应的参数,其值才确定下来。以此类比,只有当E的具体数据类型给定了,这个泛型的类型才是真正确定了。
看到泛型,我突然想到了在JVM中有一种叫“语法糖”的东西了。它不是糖,而且无色无味无实物,好吧其实就是一种语法。当在java语言中使用了这种糖,在编译期,会伴随有类型擦除的动作,即JVM会把当初传递的类型参数给擦除掉,再次变成Object(噢~,Object大法好!),而在C++语言中则不会发生擦除动作。所以相比来说,Java中的这种“语法糖”算是比较奇葩的。
不过话说回来了,既然最后还要把类型给擦除掉,可这种糖有什么用呢?肯定有用啊!那就是喂你吃,让你开心呀!什么意思?当我们传入了一个特定的参数类型后,那么我们便可以放心地去向这个集合里面添加我们所需的元素,即使失误,添加了不对应的类型,编译器也会及时提醒我去做更改。反之,如果不传入一个特定的类型参数,那么当我们在编程开发的时候,什么时候脑子一热,心里一兴奋,就把一个Integer,或者一个自定义类型的数据给放入进去了。那么当我们在遍历该集合,进行类型转换的时候,肯定是要出错的呀!同学们,这个送分题可不能错啊!(严肃脸)
好,回归正题。接下来看一下ArrayList的属性有哪些
private static final long serialVersionUID = 8683452581122892189L;
每一个可序列化的对象都要有这么一个serialVersionUID属性值的。
private static final int DEFAULT_CAPACITY = 10;
ArrayList默认的容量大小为10!同学们,记住是10,又一道送分题!
private static final Object[] EMPTY_ELEMENTDATA = {};
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
transient Object[] elementData;
private int size;
接下来找一找ArrayList的构造函数有哪些
//将elementData初始化为一个空的Object[]
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
空构造函数,ArrayList默认容量为10;
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
//如果initialCapacity大于0,则对Object[]类型的elementData进行初始化
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
//如果initialCapacity等于0,则默认初始化一个空的Object[]
this.elementData = EMPTY_ELEMENTDATA;
} else {
//否则抛错
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}
指定ArrayList容量:initialCapacity
public ArrayList(Collection c) {
//将Collection数组转化为Object[]
elementData = c.toArray();
if ((size = elementData.length) != 0) {
// c.toArray might (incorrectly) not return Object[](see 6260652)
if (elementData.getClass() != Object[].class)
//如果转化的对象数组不是Object[]类型的,就利用Arryas工具类的copyOf方法来进行一个强制转化
elementData = Arrays.copyOf(elementData, size, Object[].class);
} else {
// replace with empty array.
this.elementData = EMPTY_ELEMENTDATA;
}
}
传入的参数为Collection类型,相当于直接将Collection集合中的一部分数据直接copy到了刚刚实例化的ArrayList集合中。注意工具类:Arrays的使用。
读完了构造函数,接下来再来看普通方法(遵循增删改查的顺序)
接下来说一下ArrayList的添加对象方法
添加对象:
public boolean add(E e)
public void add(int index, E element)
public boolean addAll(Collection c)
public boolean addAll(int index, Collection c)
1.添加一个对象
public boolean add(E e) {
// Increments modCount!!
ensureCapacityInternal(size + 1);
elementData[size++] = e;
return true;
}
该方法就是向ArrayList集合的末尾添加一个对象,即调用elementData[size++] = e,ArrayList的增删改差实际就是通过内部的这个Object类型的数组来实现的,没错就是这么简单。不过在增加之前还要再进行一次容量的判断,即判断增加之后的数组大小和原来的数组大小,如果原来数组大小偏小了,则要进行动态扩充,扩充的原则则是,oldSize *3/2,即oldSize的3/2
public void add(int index, E element) {
rangeCheckForAdd(index);
// Increments modCount!!
ensureCapacityInternal(size + 1);
System.arraycopy(elementData, index, elementData, index + 1, size - index);
elementData[index] = element;
size++;
}
这个方法同样也是增加一个对象,不过这个在指定位置出增加一个对象,所以该位置后面的所有对象都需要向后移动一个位置,那么怎样才能做到呢?那就需要System.arraycopy()来帮忙啦。
public static native void arraycopy(Object src, int srcPos,
Object dest, int destPos,
int length);
通过查看System类的源码可对该方法有一个初步的了解了。arraycopy为一个native方法,所谓native方法是指首先该方法不是由Java来实现的,而是由其他偏底层的语言来实现的(比如C),这样通过调用这个方法,相比于非native方法来说,这类方法往往具有更高的效率。
这里有一篇英文文章来讲解如何一步步来实现一个native method的
看完了native,再来看一下五个参数。这个方法应该是我到目前为止见到过参数最多的一个了。通过参数的名字也不难理解它们各自的含义了,所以总的来说这个方法的作用就是根据给定的一个数组和起始位置还有复制的长度,来生成一个从指定位置复制后得到的对象。
另外再补充一个作用比较类似的方法:Arrays.copyof(T[] original, int newLength)
public static T[] copyOf(T[] original, int newLength) {
return (T[]) copyOf(original, newLength, original.getClass());
}
给定一个对象数组和长度,将返回一个复制过的相应长度的对象数组
所以接着回上边的add方法,经过容量的检测,然后调用arraycopy方法来将原来index位置及其以后的元素全部增加一位重新复制到原来的数组中,最后在index位置处插入要增加的对象。
public boolean addAll(Collection c) {
Object[] a = c.toArray();
int numNew = a.length;
// Increments modCount
ensureCapacityInternal(size + numNew);
System.arraycopy(a, 0, elementData, size, numNew);
size += numNew;
return numNew != 0;
}
该addAll()方法将一个Collection类型的集合直接添加到ArrayList的后边。
其中要涉及判断容量是否需要扩充,复制扩充原来的数组。
public boolean addAll(int index, Collection c) {
rangeCheckForAdd(index);
Object[] a = c.toArray();
int numNew = a.length;
// Increments modCount
ensureCapacityInternal(size + numNew);
int numMoved = size - index;
if (numMoved > 0)
System.arraycopy(elementData, index, elementData, index + numNew,numMoved);
System.arraycopy(a, 0, elementData, index, numNew);
size += numNew;
return numNew != 0;
}
该方法的作用是,在指定的位置处将一个Collection集合直接给插进去。所以,既然有index索引位置参数,所以要首先检查是否访问越界,检测完正常之后,再去判断是否要发生集合的扩充,所以调用了ensureCapacityInternal()方法,最后再根据相应的插入点位置来调用System.arraycopy方法来进行一个数组的复制,即为插入之后的数组。
接下来说一下ArrayList的删除方法
删除方法:
public E remove(int index)
public boolean remove(Object o)
private void fastRemove(int index)
public void clear()
第一个remove(int index)方法
public E remove(int index) {
rangeCheck(index);
modCount++;
E oldValue = elementData(index);
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--size] = null; // clear to let GC do its work
return oldValue;
}
经过了上面对arraycopy方法的分析,发现这个remove(int index)突然变得如此的简单,只需要注意这个rangeCheck(index)边界检查的方法。
不过,还需要注意变量modCount的变化,每当有删除操作时,该值就会+1,那么有什么用呢?这个在fail-fast机制中起到了一个提醒危险的作用,至于具体是什么作用呢?我也不会,可是我当然会去搞懂它呢!
private void rangeCheck(int index) {
if (index >= size)
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
如果index >= size,就会抛异常:IndexOutOfBoundsException
第二个remove(Object o)方法
public boolean remove(Object o) {
if (o == null) {
for (int index = 0; index < size; index++)
if (elementData[index] == null) {
fastRemove(index);
return true;
}
} else {
for (int index = 0; index < size; index++)
if (o.equals(elementData[index])) {
fastRemove(index);
return true;
}
}
return false;
}
通过对集合进行遍历,找到符合删除对象的索引,然后调用fastRemove(int index)方法来快速删除该对象。
private void fastRemove(int index) {
modCount++;
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--size] = null; // clear to let GC do its work
}
之所以叫做fastRemove,就是因为当他决定开始删除对象的时候,就不用再进行randCheck了,因为在外边的方法中已经保证了index一定小于size。
public boolean removeAll(Collection c) {
Objects.requireNonNull(c);
return batchRemove(c, false);
}
该方法的作用为删除一个指定集合。不过在删除之前首先会判断该集合是否为空,即调用了为 final类型的Objects.requireNonNull(T obj),其源码如下:
public static T requireNonNull(T obj) {
if (obj == null)
throw new NullPointerException();
return obj;
}
很简单的一段源码,如果为空,则抛NullPointerException()异常。接着再调用batchRemove方法,其源码如下:
private boolean batchRemove(Collection c, boolean complement) {
final Object[] elementData = this.elementData;
int r = 0, w = 0;
boolean modified = false;
try {
for (; r < size; r++)
if (c.contains(elementData[r]) == complement)
elementData[w++] = elementData[r];
} finally {
// Preserve behavioral compatibility with AbstractCollection,
// even if c.contains() throws.
if (r != size) {
System.arraycopy(elementData, r,
elementData, w,
size - r);
w += size - r;
}
if (w != size) {
// clear to let GC do its work
for (int i = w; i < size; i++)
elementData[i] = null;
modCount += size - w;
size = w;
modified = true;
}
}
return modified;
}
这段代码的作用就是批量删除一个Collection集合对象。(好吧,我承认没怎么看懂)
public void clear() {
modCount++;
// clear to let GC do its work
for (int i = 0; i < size; i++)
elementData[i] = null;
size = 0;
}
调用clear()方法,简单粗暴地来清空整个集合。
接下来说一下ArrayList的修改方法
修改方法:
public E set(int index, E element)
public void replaceAll(UnaryOperator
operator)
public E set(int index, E element) {
rangeCheck(index);
E oldValue = elementData(index);
elementData[index] = element;
return oldValue;
}
该set()方法首先也会检查index是否越界,如果没有越界,直接将index位置的对象替换即可,最后返回值为原来位置的那个对象。
public void replaceAll(UnaryOperator operator) {
Objects.requireNonNull(operator);
final int expectedModCount = modCount;
final int size = this.size;
for (int i=0; modCount == expectedModCount && i < size; i++) {
elementData[i] = operator.apply((E) elementData[i]);
}
if (modCount != expectedModCount) {
throw new ConcurrentModificationException();
}
modCount++;
}
接下来说一下ArrayList的查询方法
修改方法:
public E get(int index)
public int indexOf(Object o)
public int lastIndexOf(Object o)
该方法的作用是替换一部分的对象,至于 UnaryOperator 该类型之前没有见过,没有搞懂,所以这段代码的分析暂时先搁置,随后就来,随后就来
public E get(int index) {
rangeCheck(index);
return elementData(index);
}
该方法传入一个位置索引参数,返回相应的类型。不过,在return之前,还需要调用两个方法rangeCheck(index)和elementData(index),
看一下和elementData()方法,这是一个私有方法,所以肯定是在该类内部进行服务的,从源码里可以很容易看出,就是检查一下索引位置是否越界。
@SuppressWarnings("unchecked")
E elementData(int index) {
return (E) elementData[index];
}
从源码上很容易看出是获得相应索引值的对象,而且由于前边由于已经对边界进行检查过了,所以此处可以加一个注解@SuppressWarnings来提示JVM忽略该方法可能所产生的警告。
public int indexOf(Object o) {
if (o == null) {
for (int i = 0; i < size; i++)
if (elementData[i]==null)
return i;
} else {
for (int i = 0; i < size; i++)
if (o.equals(elementData[i]))
return i;
}
return -1;
}
该方法的作用同样是查,不过这次返回的是指定对象的索引值,其实内部的原理很简单,就是对该集合进行一个遍历,如果找到了指定的Object对象,就返回该索引的值。
public int lastIndexOf(Object o) {
if (o == null) {
for (int i = size-1; i >= 0; i--)
if (elementData[i]==null)
return i;
} else {
for (int i = size-1; i >= 0; i--)
if (o.equals(elementData[i]))
return i;
}
return -1;
}
同上面方法的原理几乎一样,这次是倒序查找。
一些其他常见适用方法
public boolean contains(Object o) {
return indexOf(o) >= 0;
}
查询是否包含指定对象
public boolean isEmpty() {
return size == 0;
}
该集合是否为空
public int size() {
return size;
}
返回该集合的大小
public Object[] toArray() {
return Arrays.copyOf(elementData, size);
}
将一个arrayList对象转换成Object对象数组
至此,我想已经将ArrayList的内部实现的一些基本原理给写明白了。希望这篇文章能够帮到一些人,同时也十分欢迎就一些疑问或者想法直接留言进行交流!