有了美丽的封面, 写的兴致又来了。 我们在“深度学习名校课程大全”里面介绍了深度学习的课程。 在“人工智能深度学习人物关系[全]”里面介绍了部分深度学习的人物。 这里简要概述下下部分图像目标检测深度学习模型。
前言
有一些图像分割的背景知识也很有意思,简单列下, 概述下来,主要是五大任务, 六大数据集, 七大牛人组,一个效果评估。
五大图像处理任务
1. 图像分类

2. 分类和定位

3. 目标物体检测

4. 语义分割
一下子从框的世界进入了像素点的世界。

5. 实例分割

六大图像数据库
1.PASCAL Visual Object Classes (VOC) 挑战
人、车、自行车、公交车、飞机、羊、牛、桌等20大类

2.MS COCO: Microsoft Common Object in Context
80大类, 多目标

3.ImageNet Object Detection: ILSVRC DET 任务
200类别,578,482 图片

4.Oxford-IIIT Pet Dataset
37 类别,每个类别 200 图片

5.Cityscapes Dataset
30 类别,25,000 + 真实开车场景图片

6.ADE20K Dataset
150+ 类别,22,000 + 普通场景图片

七大牛人组
1.Navneet Dalal 和 Bill Triggs (INRIA)
两人提出了Histogram of Gradient (HOG)获得2015年的 Longuet-Higgins Prize大奖

2.Pedro Felipe Felzenszwalb
和学生Ross Girshick一起发明了DPM,深化了HOG.

3.Ross Girshick
Felzenszwalb的高徒,RBG大神、发明了R-CNN、Mask R-CNN。Ross目前在Facebook人工智能研究院 FAIR。

4.Koen van de Sande
提出Selective Search的大神。

5.Jitendra Malik
去噪模型Perona-Malik扩散和聚类分割里面的归一化分割Normalized Cut的发明人,RBG大神的博士后导师,鼓励RBG引入CNN做目标检测,R-CNN发明人之一。

6. Pietro Perona去噪模型Perona-Malik扩散的发明人, 李飞飞的博士导师, 2013获得Longuet-Higgins Prize。 和高徒Piotr Dollar一起提出Fast Feature Pyramids的神器。他的另外一个高徒Stefano Soatto搞出了 Structure From Motion SFM,视觉运动信息的多幅二维图像序列估计三维结构的技术。 他弟子Piotr Dollar目前在FAIR。

7.何凯明
ResNet,SPP, Mask-CNN发明人,目前在FAIR。

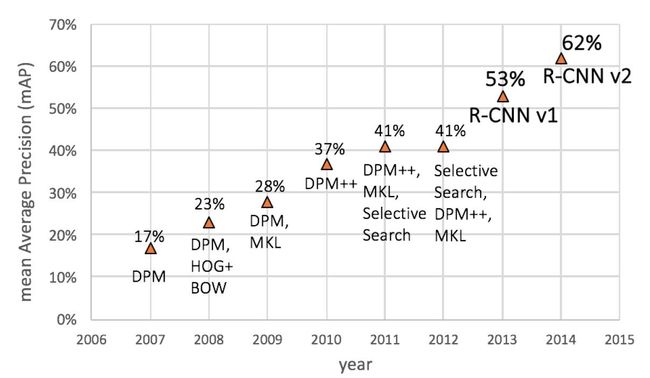
一个效果评估mAP(mean average precision)借用了文档检索里面的标准, 假设目标物体的预测在所有的图像中都进行预测, 在每个图像上计算准确和召回。 但是最后计算每个目标物体的AP的时候, 仅仅选用相关的图像,进行平均average, 最后计算mAP的时候再求平均mean。 是一个奇怪的名字,却是一个蛮直观的评价!

R-CNN系列
R-CNN的横空出世, 随后经过一系列改进, 走到了Mask R-CNN和Mask^X R-CNN的神奇境界。

CNN结构上从AlexNet过渡到ResNet, 中间也受到Overfeat和SPPNet的影响深远!
一, R-CNN的前世
2013年之前, 基本由RBG和他导师的DPM主导, 当然离不开SS和SVM的应用,和后续Box Regression的修正。
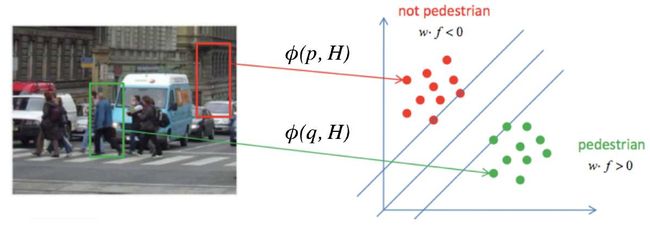
1. Histogram of Gradient (HOG) 特征
8x8像素框内计算方向梯度直方图

2. HOG Pyramid
特征金字塔,对于不同大小的物体进行适应。

3. HOG特征 -> SVM分类
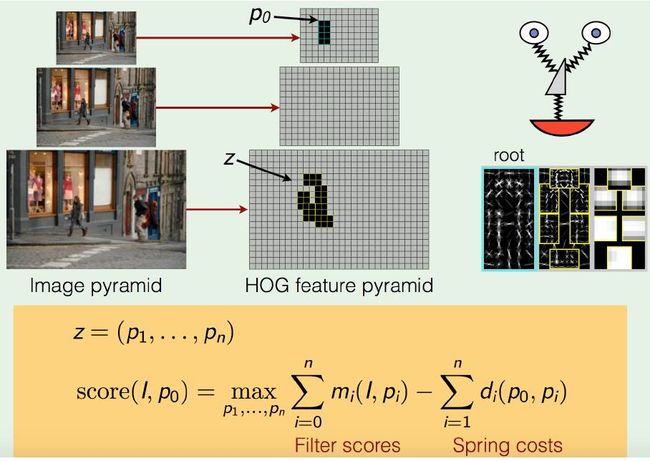
4. DPM模型 Deformable Part Model
加组件组合的HOG特征,组件间计算弹性得分,优化可变形参数。
如果没有弹性距离,就是BoW (Bag of Word)模型,问题很大, 位置全部丢失:

n个组件的DPM计算流程

5. Selective Search 思想
首先, 过分割后基于颜色纹理等相似度合并,

然后,过分割、分层合并、建议区域排序
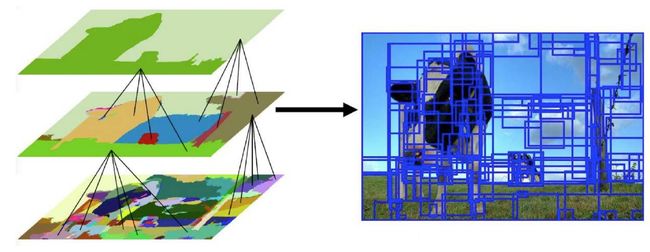
6. 基于Selective Search + DPM/HoG + SVM的物体识别

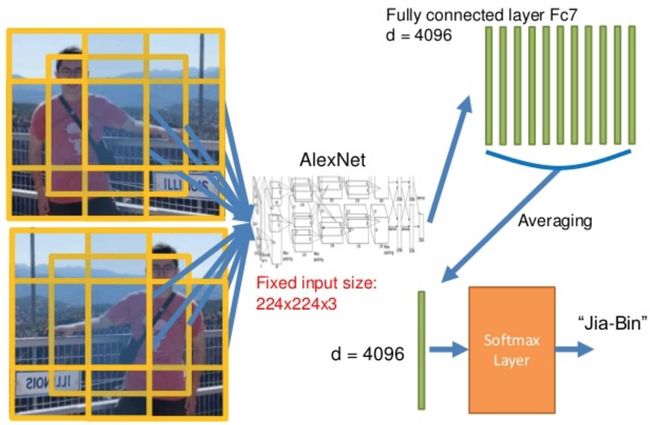
7. AlexNet的图像分类
2012年AlexNet赢得LSVRC的ImageNet分类竞赛。深度CNN结构用来图像特征提取。

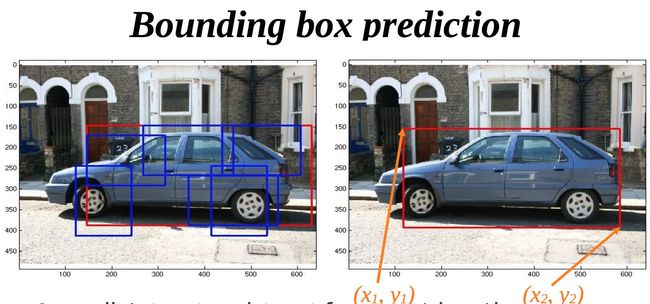
8. bounding-box regression 框回归
BBR 在DPM时代就和SVM分类结合,一般直接使用线性回归,或者和SVR结合。
二, R-CNN的出世
这个工作是RBG在Malik那里读博士后的产出。 这个工作的影响巨大!
1.1 R-CNN的本质, 用深度CNN网络取代了HoG/DPM的特征提取!
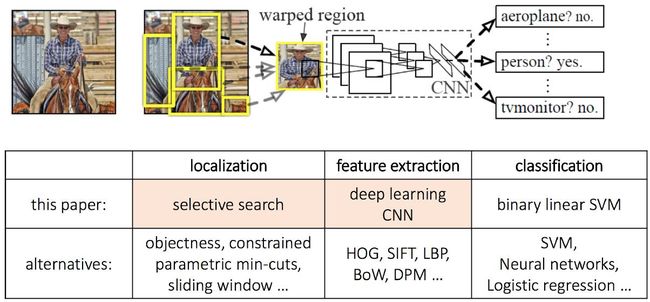
1.2 R-CNN依赖分类预训练的特征
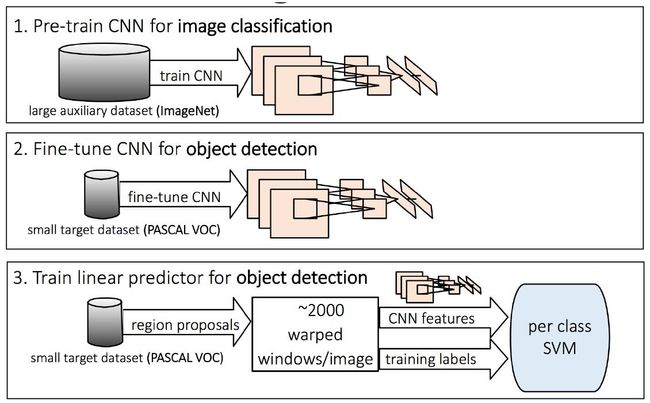
1.3 通过bounding-box regression改进效果,对于SS推荐的, 经过SVM分类的结果进行修正。

这样,我们就得到了最后RNN的框架,我们看到区域推荐、SVM和Bound Box Regression都是成熟的技术的整合:
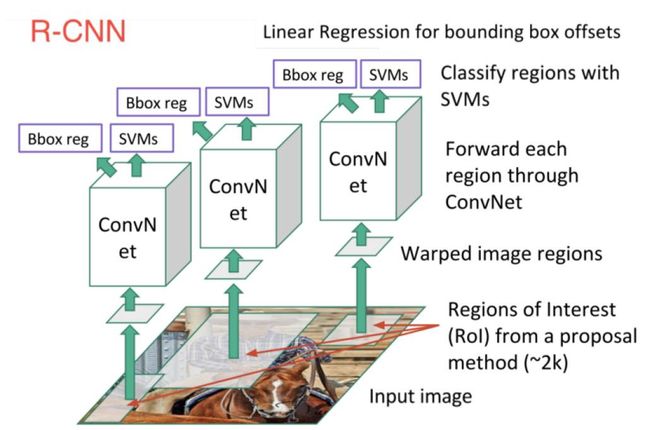
R-CNN优点:
1. 效果比DPM方法大幅度提高
2. 开启了CNN网络的目标检测应用
3. 引入了BBR和分类结合的思想
4. 定义了RoI, 基于推荐区域的思想
R-CNN问题:
不是端到端的模型,依赖SS和SVM!
计算速度相当慢!
对于过大过小的东西,效果很不好。
譬如,对于长凳, 或者眼镜等等。

三,MR-CNN的改进
Multi-Region的提出, 开始对Box进一步做文章, 相当于对Box进一步做增强,希望改进增强后的效果,主要改善了部分重叠交叉的情况。

但是特征拼接后使得空间变大,再使用SVM处理, 效果和R-CNN基本类似。

MR-CNN改进有限!
四, Overfeat的改进
LeCun的Overfeat是个端到端的模型,直接抛弃了SVM,并且把BBR整合一起使用FCN(Fully-Connected Net)搞定, 解决了后面一端的问题(取代了SVM和BBR)。
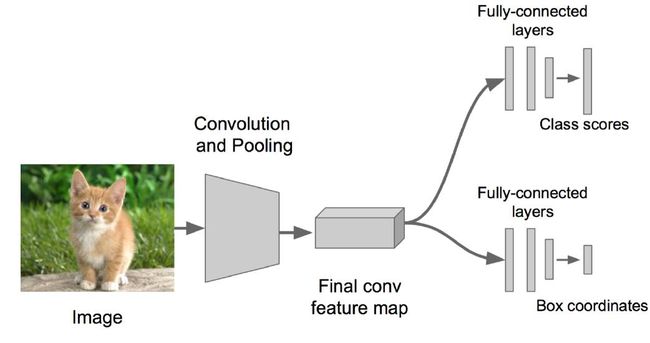
另外, 也直接抛弃了SS,采用CNN上滑动窗口来进行框推荐,搞定前面一端。

然后直接根据滑动窗口的不准确的判断, 进行Box 回归(BR)来进行准确定位。

并且在计算上做了三大优化: 第一, 先进行CNN再滑动窗口, 而不是先滑动窗口再进行CNN计算。 把窗口滑动放到CNN之后进行。 避免重复的特征计算。


第二, 多类别并行计算框架, 进一步减少CNN特征计算因为没有找到特定类别而浪费。

第三, 把FCN直接用CNN网络取代, 计算量大大减少。怎么做到的呢? 结合上面两点, 利用每个类别实现一个0-1的CNN网络, 然后所有类别并行处理。

还做了一大改进, 考虑了多尺度衍生:

Overfeat优点:
1. 端到端的模型
2. 回归和分类结合的计算模型
3. 首次将区域计算后移, 极大节省计算量, 优化速度
4. 有多尺度考量,试图优化极大极小目标问题
Overfeat问题:
1. 取消区域推荐, 依赖窗口滑动和BR效果后的推荐效果一般。
2. 定位准确, 但是对于重叠目标物体的情况,效果很差。
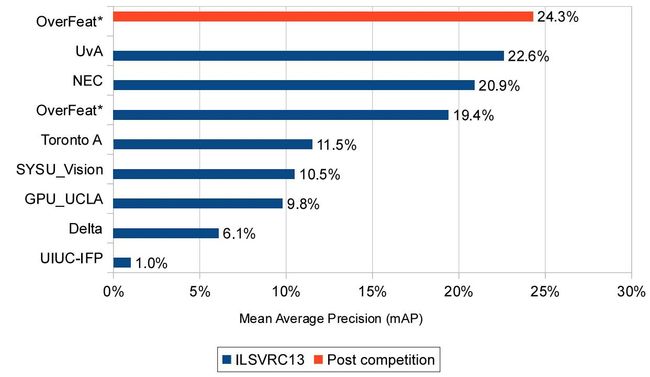

五, SPPNet的改进
这个工作是何凯明在孙剑指导下, 微软的工作。 后来孙剑去了旷视科技, 而何凯明去了Facebook人工智能实验室FAIR。 前面, 我们提到R-CNN和Overfeat都存在部分多尺度,重叠效果的问题。 某种意义上, 应对了HoG特征, 这样对于物体来说类似BoW模型, 我们知道DPM里面,是带有组件空间分布的弹性得分的, 另外也有HoG Pyramid的思想。 如何把Pyramid思想和空间限制得分加入改善多尺度和重叠的效果呢? MR-CNN里面尝试了区域增强, Overfeat里面尝试了多尺度输入。 但是效果都一般。 这里我们介绍另外一个技术Spatial Pyramid Matching, SPM。把空间和Pyramid结合的思想。
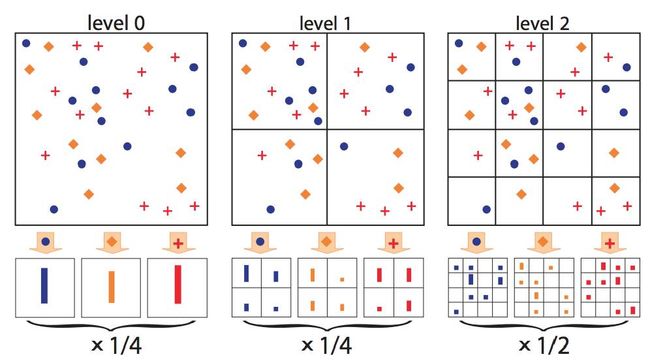
1. SPM
把BoW修改金字塔Pyramid方式进行空间限制,做特征提取。
2. SPM用在CNN特征之后,R-CNN里面 SVM分类之前。
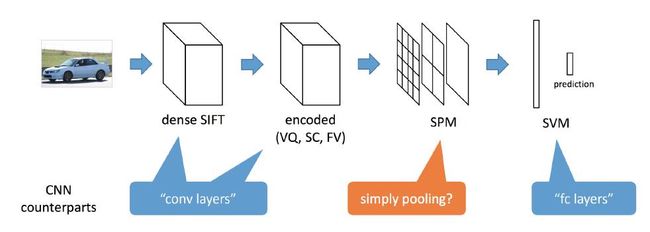
3. 基于CNN的Pooling技术来实现SPM, 通过不同尺度的Pooling技术很容易就实现了CNN特征的SPM特征。

4. 先特征后区域的处理, 某种意义上取代了多尺度输入,或者特征增强。

和R-CNN相比做到了先特征后区域, 和Overfeat相比自带Multi-Scale。
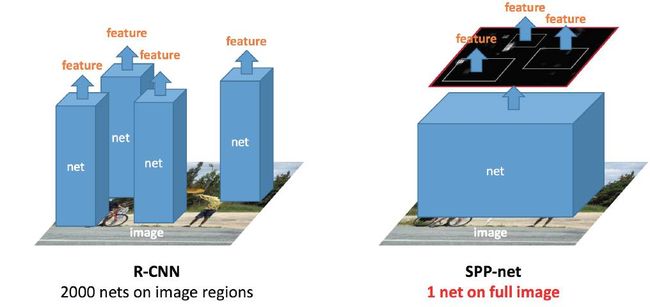
于是SPPNet(Spatial Pyramid Pooling Net)很空出世!
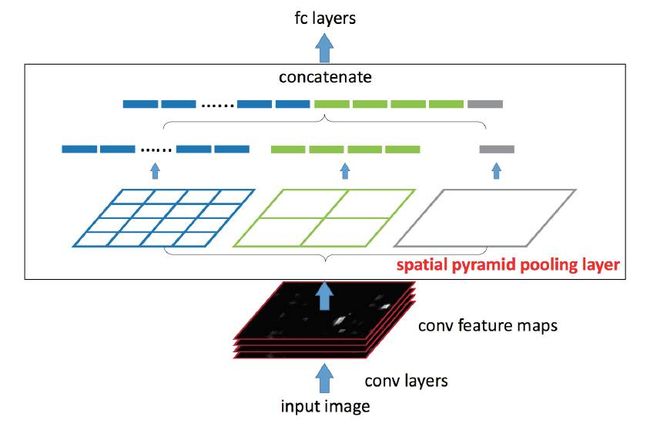
SPPNet优点:
1. 提取SPP的概念, 把CNN的Pooling用的出神入化, 取代了HoG Pyramid的改进。 对于大小尺度的物体识别有改进。
2. 进一步强调了CNN特征计算前移, 区域处理后移的思想, 极大节省计算量。
SPPNet缺点:
1. 依然不是端到端的模型
2. 过于注重CNN特征的分离, CNN特征提取没有联动调参数!

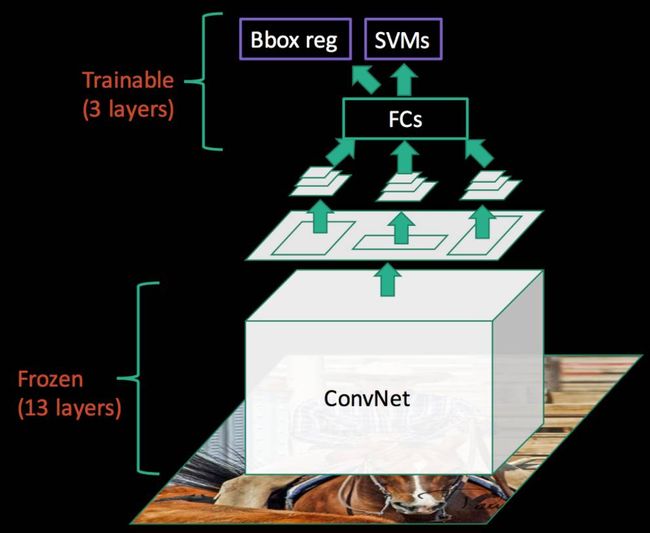
Fast R-CNN的改进
RBG从后来去了微软,在微软了解了何凯明的SPPNet工作。 所以Fast R-CNN 基本和SPPNet类似, 但是进一步联动改进!全部打通区域推荐之后到目标识别后一端!而且效果较好!
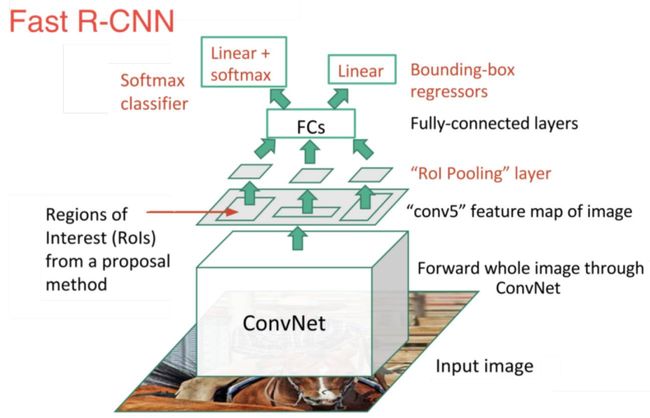
基于SPPNet, Fast R-CNN做了两大改进:
一, 简化SPP成为RoI Pooling, 只用了最细分的SPPNet。 把RoI区域变成了RoI Pooling, 这就是RoI Pooling的思想的来源。 Pyramid上层更粗的特征, 可以依赖FCN进行整合学习。

二, CNN特征网络联动调参数!

这样, Softmax分类误差和线性回归误差叠加的误差, 可以反传通过FCN, ROI Pooling和ConvNet层。
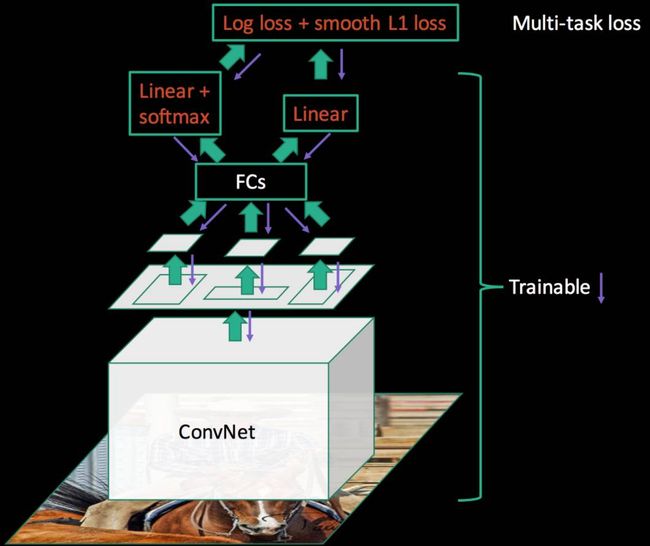
Fast R-CNN优点:
1. 吸收了SPPNet和R-CNN的精华,极大的打通并且改进了从区域推荐到目标检测一端。
2. RoI Pooling技术横空出世, 极大的发挥了区域计算后移的优势, 加快了训练速度。
3. Log 损失和Smooth L1的损失下的FCN、RoI Pooling、ConvNet三层联动调参数成熟, 并且带来效果上的提升。
4. 并且应用VGG16,取代AlexNet作为CNN网络模型
Fast R-CNN缺点:
1. 依然没有实现端到端的模型,对SS区域推荐依赖严重。
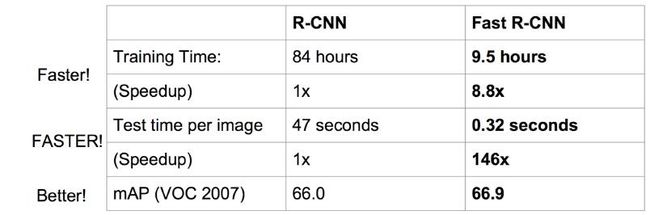

Faster R-CNN的改进
SPPNet和Fast R-CNN都面临着并非端到端模型的困惑, 那么RBG、何凯明和孙剑, 微软的3位牛人合作开启了端到端模型的开发。
提出RPN(Region Proposal Net)取代了SS区域推荐。 RPN有点类似Overfeat的ConvNet的滑动窗口, 但是加入了Anchor Box的设计。
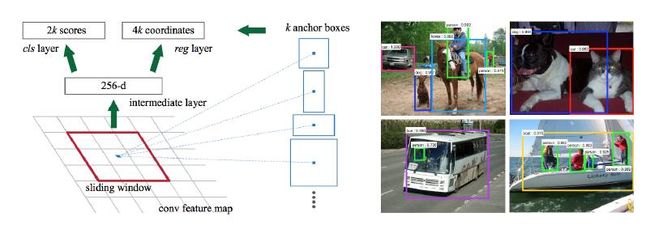
在Overfeat的ConvNet上的滑动窗口, 加上Multi-Scale的图像输入设计, 编程了带Anchor Box推荐的区域Pyramid。 这种机制, 某种意义上是带了先验的Attention机制。
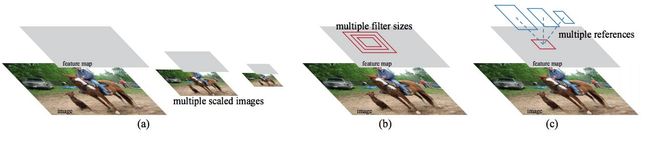
这样 RPN的Anchor和Pyramid和定位都可以是参数学习, 例如:9 anchors x 2 scores x width x height。
如果在考虑ROI Pooling对推荐区域的修正作为新的RPN,就会带来ROI Pooling的迭代:

所以最初, RPN的损失是单独计算进行参数学习的。
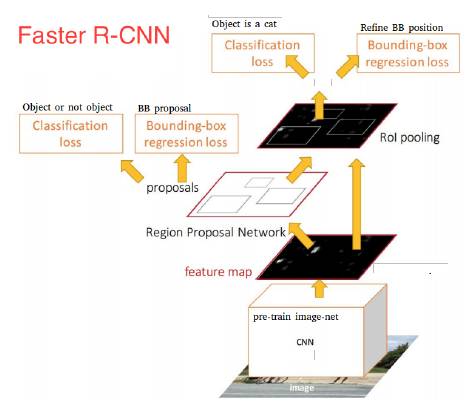
但是后来, RPN的误差也全部整合处理了, 一个端到端的模型诞生,并且具有较好的区域推荐、特征Pyramid,和Box回归的效果保证。

Faster R-CNN优点:
1. 和Overfeat一样是一个端到端的模型, 但是集成了以前图像处理里面的思想: 区域推荐, 特征Pyramid和Box回归。
2. 较好的ConvNet特征共享, 效率更高
3. 提出了RPN网络,并且整合后的效果和Fast R-CNN一样
Faster R-CNN缺点:
1. 依然难以做到实时高效
2. 功能上没有进入实例分割阶段。

小结
我们发现, 单纯的端到端ConvNet模型的Overfeat很难达到较好的效果。 如何融合图像处理经典思想里面的区域推荐, 特征金字塔, 和框回归,还是非常有必要。 而Faster R-CNN做到了这些。 这个过程中一直伴随着性能的提升, 其中重要一步就是如何让特征计算不要重复,做到一次计算。 如何进一步提高速度, 和增强功能, 是后续网络的要改进的地方。 例如, 我们发现ConvNet的计算在Faster R-CNN已经达到很高的共享, 但是ROI之后依然有ConvNet的计算, 如何进一步共享这部分计算呢? 请看下期。


