1. 背景介绍
在艺术绘画的创作过程中,人们通过将一张图片的内容和风格构成复杂的相互作用来产生独特的视觉体验。然而,所谓的艺术风格是一种抽象的难以定义的概念。因此,如何将一个图像的风格转换成另一个图像的风格更是一个复杂抽象的问题。尤其是对于机器程序而言,解决一个定义模糊不清的问题是几乎不可行的。在神经网络之前,图像风格迁移的程序采用的思路是:分析一种风格的图像,为这种风格建立一个数学统计模型;再改变要做迁移的图像使它的风格符合建立的模型。该种方法可以取得不同的效果,但是有一个较大的缺陷:一个模型只能够实现一种图像风格的迁移。因此,基于传统方法的风格迁移的模型应用十分有限。随着神经网络的发展,机器在某些视觉感知的关键领域,比如物体和人脸识别等有着接近于人类甚至超越人类的的表现。这里我们要介绍一种基于深度神经网络的机器学习模型——卷积神经网络,它可以分离并结合任意图片的风格和内容,生成具有高感知品质的艺术图片。本文介绍一篇在2015年由 Gatys 等人发表的一篇文章_ A Neural Algorithm of Artistic Style_,该文章介绍了一种利用卷积神经网络进行图像风格迁移的算法。相比于传统的风格迁移的方法,该方法具有更好的普适性。
2. 概述
2.1 内容表示
处理图像任务最有效的一种深度神经网络就是卷积神经网络。卷积神经网络由多个网络层组成的前馈神经网络,每个网络层包含了许多用于处理视觉信息的计算单元(神经元)。每一层的计算单元可以被理解为一个图片过滤器的集合,每一层都可以提取图片的不同的特定特征。我们把给定层的输出称为特征图谱(Feature Map)——输入图像的不同过滤版本。当卷积神经网络用于物体识别时,随着网络的层次越来越深,网络层产生的物体特征信息越来越清晰。这意味着,沿着网络的层级结构,每一个网络层的输出越来越关注于输入图片的实际内容而不是它具体的像素值。通过重构每个网络层的特征图谱,我们我可以可视化每一层所表达的关于输入图片的信息。从中可以看出,位于更高层的网络层能够根据物体及其在输入图像中的排列来捕获输入图像的高级内容而不包含具体的像素值信息。因此,我们参考网络模型的高层结构作为图片的内容表示。
2.2 风格表示
为了获取输入图片的风格表示,我们使用一个被用来获取纹理特征的特征空间。该特征空间包含了特征图谱空间范围内不同滤波器响应之间的相关性。通过多个层的特征相关性,我们获得输入图像的静态多尺度表示,它能够捕获图片的纹理信息却不包含全局排列。
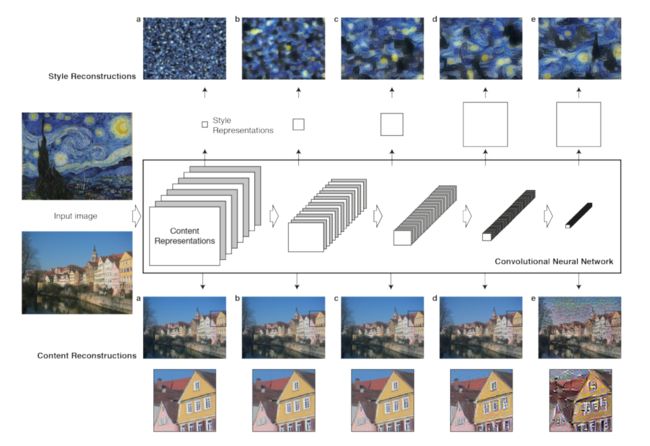
2.3 内容和风格的分离
本文的一个关键点是图片的内容表示和风格表示在卷积神经网络中是可分离的。也就是说,我们可以独立地操纵这两种表示来产生新的有感知意义上的图片。为了证明这一观点,该论文展示了一些由不同内容和风格的图片混合生成的合成图片,如图 2 所示。这些图片是通过寻找一个同时匹配照片内容和对应的艺术风格的图片的方法而生成的。这些合成图片在保留原始照片的全局布置的同时,继承了各种艺术图片的不同艺术风格。风格表示是一个多层次的表达,包括了神经网络结构的多个层次。当风格表示只包含了少量的低层结构,风格的就变得更加局部化,产生不同的视觉效果。当风格表示由网络的高层结构表示时,图像的结构会在更大的范围内和这种风格匹配(图 2 最后一行),产生更加流畅持续的视觉体验。

2.4 图片的合成
实际上,图片的内容和风格是不能够被完全分离的。当我们合成图片时,我们通常找不出一张能够匹配某个图片内容和另一种图片风格的图片。在我们合成图片的过程中,我们需要最小化的损失函数包含内容和风格,但它们是分开的。因此,我们需要平滑地调整内容和风格的权重比例(图 3 的行坐标)。当损失函数分配在内容和风格的权重不同时,合成产生的图片效果也完全不一样。我们需要适当地调整内容表示和风格表示的权重比来产生具有视觉感染力的图片。是否能够找到合适的权重比是能否产生令人满意的图片的关键因素。

3. 实验
该论文中的实验结果,是以 VGG 网络为基础产生的。该实验使用的是由 16 个卷积层和 5 个池化层(VGG 19)组成的特征空间。由于该实验不要进行分类,我们不需要使用全连接层。该模型是公开可用的,我们可以在 Caffe 框架和 Keras 框架找到。该文作者实验发现使用平均池化比使用最大池化更容易得到令人满意的实验结果。
3.1 实验准备
在这里我们参考后续的文章,使用 VGG 16 网络模型进行实验。该模型能够在不丢失图片精度的条件下,尽可能地加快训练速度。同时,为了保留原始图片的结构细节(且让合成图片符合大多数人的审美),在这里我们使用 'block2_conv2' 的输出作为图片的内容表示(原文采用的是'block4_conv2' )。而风格表示方面,我们依旧采用论文中所述的纹理特征作为风格表示。
3.2 内容损失
在卷积神经网络(CNN)中,一般认为较低层的描述了图像的具体视觉特征(即纹理、颜色等),较高层的特征是较为抽象的图像内容描述。当要比较两幅图像的内容相似性的时候,我们比较两幅图片在 CNN 网络中高层特征的相似性即可。本次实验中,我们使用内容图片和合成图片对应网络层的特征图谱的欧氏距离来表示内容损失。内容损失的计算公式:

,其中
和
分别表示合成图片和原始图片在第l 层的第i个滤波器在位置 j上的激活值。
参考代码:
def content_loss(content, combination):
return backend.sum(backend.square(combination - content))
layer_features = layers['block2_conv2']
content_image_features = layer_features[0, :, :, :]
combination_features = layer_features[2, :, :, :]
loss += content_weight * content_loss(content_image_features,
combination_features)
3.3 风格损失
要比较两张图片的风格相似性,我们需要比较它们在 CNN 网络中较低层特征的相似性。与内容损失不同的是,我们不能仅仅使用欧式距离来定义风格损失。CNN 的底层特征虽然在一定程度上包含了图像的风格特点,但是由于特征图谱的空间信息过于明显,直接计算欧氏距离会产生较大的误差。因此,我们需要在保留低层的视觉特征的同时消除空间信息,Gatys 提出了一个非常神奇的矩阵——Gram 矩阵。Gram 矩阵:
,
表示第l层中两个向量化特征矩阵的内积。单个网络层的风格损失:

,其中

,
表示每一层的损失权重。参考代码:
# 定义 Gram 矩阵
def gram_matrix(x):
features = backend.batch_flatten(backend.permute_dimensions(x, (2, 0, 1)))
gram = backend.dot(features, backend.transpose(features))
return gram
# 计算总的风格损失
def style_loss(style, combination):
S = gram_matrix(style)
C = gram_matrix(combination)
channels = 3
size = height * width
return backend.sum(backend.square(S - C)) / (4. * (channels ** 2) * (size ** 2))
feature_layers = ['block1_conv2', 'block2_conv2',
'block3_conv3', 'block4_conv3',
'block5_conv3']
for layer_name in feature_layers:
layer_features = layers[layer_name]
style_features = layer_features[1, :, :, :]
combination_features = layer_features[2, :, :, :]
sl = style_loss(style_features, combination_features)
loss += (style_weight / len(feature_layers)) * sl
3.4 总损失
为了得到令人满意的合成图片,我们需要最小化上面定义的内容损失和风格损失。这里我们定义了一个总损失函数,分别用
表示提供内容的照片和风格的艺术作品,
表示合成图片。总损失函数:
表示内容损失和风格损失的权重。参考代码:
def total_variation_loss(x):
a = backend.square(x[:, :height-1, :width-1, :] - x[:, 1:, :width-1, :])
b = backend.square(x[:, :height-1, :width-1, :] - x[:, :height-1, 1:, :])
return backend.sum(backend.pow(a + b, 1.25))
loss += total_variation_weight * total_variation_loss(combination_image)
,其余网络层的权重为 0。总损失中的权重比
需要我们自己调整,来合成令我们满意的图片。本实验采用的内容损失权重和风格损失权重为 0.025 和 5.0,能够得到一个较为令人满意的结果,如图 4 所示。
3.5 优化问题
在本实验中,我们使用 L-BFGS 算法来优化总损失函数。由于我们使用的是梯度下降算法,我们引入一个Evaluator 类——通过两个独立的函数 loss 和 grads,来计算损失和梯度。参考代码:
# 定义梯度
grads = backend.gradients(loss, combination_image)
# 定义类
outputs = [loss],outputs += grads
f_outputs = backend.function([combination_image], outputs)
def eval_loss_and_grads(x):
x = x.reshape((1, height, width, 3))
outs = f_outputs([x]),loss_value = outs[0]
grad_values = outs[1].flatten().astype('float64')
return loss_value, grad_values
class Evaluator(object):
def __init__(self):
self.loss_value = None,self.grads_values = None
def loss(self, x):
assert self.loss_value is None
loss_value, grad_values = eval_loss_and_grads(x)
self.loss_value = loss_value,self.grad_values = grad_values
return self.loss_value
def grads(self, x):
assert self.loss_value is not None
grad_values = np.copy(self.grad_values)
self.loss_value = None,self.grad_values = None
return grad_values
evaluator = Evaluator()
对于合成图片,我们将其初始化为一个随机有效的像素的集合。最后通过 L-BFGS 算法来最小化损失函数。从实验结果可以看出,当迭代进行至 10 次后,损失就不再显著减少。参考代码:
x = np.random.uniform(0, 255, (1, height, width, 3)) - 128.
iterations = 10
for i in range(iterations):
print('Start of iteration', i)
start_time = time.time()
x, min_val, info = fmin_l_bfgs_b(evaluator.loss, x.flatten(),
fprime=evaluator.grads, maxfun=20)
print('Current loss value:', min_val)
end_time = time.time()
print('Iteration %d completed in %ds' % (i, end_time - start_time))
最终我们合成的图片效果展示如下:



图 4:最左边的是内容图片,中间的是风格图片,最右边的是合成的效果图
4.总结和展望
本论文首次提出了运用神经网络模型来实现风格迁移:使用卷积神经网络将一张图片中的内容和风格进行了分离和提取;并且定义了如何来计算图片内容相似性和风格相似性,通过最小化内容损失和风格损失来得到令人满意的结果。相比传统的风格迁移模型,利用卷积神经网络来提取图片的内容和风格具有重大的意义 ,它使得模型具有更加广泛的通用性,而不需要为每一种风格的图片建立一个数学模型。但是该方法也有一些不足之处:内容损失使用特征图谱的欧氏距离来表示的效果并不是十分的理想,比如一个张图片经过一小段平移之后在视觉效果上与原图几乎没有差别,而此时使用像素点间的差值来计算损失会产生较大的误差;同时该模型优化的是合成图片
,每生成一张合成图片都需要进行一次训练,速度较慢,而且输入
是随机生成的,初始值的好坏会对最终结果产生一定影响。因此,2016 年 Johnson 等人提出了一种更为快速的风格迁移的方法 Perceptual losses for real-time style transfer and super- resolution。该方法使用的模型在 Mo 平台上有实现,大家可以在 应用中心中找到 Style Transfer 这个应用 。****项目源码地址: https://momodel.cn/explore/5bfb634e1afd943c623dd9cf?type=app&tab=1
5.参考资料
- 论文:A Neural Algorithm of Artistic Style
- 论文:Texture Synthesis Using Convolutional Neural Networks
- 论文:Very Deep Convolutional Networks for Large-Scale Image Recognition
- 论文:Perceptual losses for real-time style transfer and super- resolution
- 代码:https://github.com/erilyth/DeepLearning-Challenges/tree/master/Art_Generation
- 博客:一个艺术风格化的神经网络算法
- 博客:CNN 实现艺术风格转移
- 博客:深度学习之风格迁移简介
- 博客:快速风格转移
- 博客:风格迁移
- 新闻资讯:风格迁移简史
关于我们
Mo(网址:momodel.cn)是一个支持 Python 的人工智能在线建模平台,能帮助你快速开发、训练并部署模型。
Mo 人工智能俱乐部 是由网站的研发与产品设计团队发起、致力于降低人工智能开发与使用门槛的俱乐部。团队具备大数据处理分析、可视化与数据建模经验,已承担多领域智能项目,具备从底层到前端的全线设计开发能力。主要研究方向为大数据管理分析与人工智能技术,并以此来促进数据驱动的科学研究。
目前俱乐部每周六在杭州举办以机器学习为主题的线下技术沙龙活动,不定期进行论文分享与学术交流。希望能汇聚来自各行各业对人工智能感兴趣的朋友,不断交流共同成长,推动人工智能民主化、应用普及化。