目前大部分 Python 的 HTTP 服务都是用 uWSGI 托管 Python 多进程的 Django 或者 Flask 框架的 App。而多进程模型就会有进程间通信的问题,对此 uWSGI 提供了 spooler 功能用于让不同 worker 进程把数据通过共享内存传给单独进程以集中进行处理的功能。但是 uWSGI 的 Python C 扩展实现有 bug,对 Python tuple 对象的引用计数处理是错误的,会在多线程环境下有小概率导致进程崩溃,从而造成线上 HTTP 请求返回 502 错误。
分享之前我还是要推荐下我自己建的Python开发学习群:628979297,群里都是学Python开发的,如果你正在学习Python ,小编欢迎你加入,今天分享的这个案例已经上传到群文件,大家都是软件开发党,不定期分享干货(只有Python软件开发相关的),包括我自己整理的一份2018最新的Python进阶资料和高级开发教程,欢迎进阶中和进想深入Python的小伙伴。
经过几天的分析排查和复现,最终修复了导致对象引用计数出错的代码。整个过程涉及到 uWSGI 和 Python 虚拟机中内置类型的实现、对象引用计数和对象池、GC、多线程 GIL、内存管理及 GDB 使用等。本文记录了主要的排查过程,并在涉及到虚拟机实现的地方介绍对应的细节。
uWSGI和Python并发模型
首先简单介绍一下 Python 与其它语言在并发处理上的不同。熟悉 Python 的同学知道,Python 2.x 的官方实现版本是有一个 GIL 的,即全局解释锁。在 Python 代码执行的大部分时间里,线程都会持有这个锁,这样不能简单通过开多线程的方式充分利用多核的优势。有人尝试把 GIL 改成更细粒度的锁,但是发现在单线程场景下运行效率有明显下降。
为了解决 Python 并发的问题,有人实现了其它方案,比如 gevent,tornado 等,不过用起来多少都有些别扭,或者容易掉坑里。
所以对于 Python 2 建议的用法是多进程模型。小计算量的 IO 操作可以开在另外一个线程里边。
而多进程模型就需要在进程管理上做一些处理。整体上来说 uWSGI 是一个宿主,用来承载其它服务。uWSGI 会先启动一个 master 进程,然后再启动各个 worker 进程和单独的 spooler 进程,并监控这些进程的运行状态。不过通常我们主要用 uWSGI 作为 Web Server,管理 Python 写的 Web Application。而不会使用 uWSGI 的 LB 之类的功能。
而由 uWSGI 管理多进程,同时进程内有不止一个线程的情况下,由于 C 扩展部分的实现有 bug,会导致 uWSGI 进程有小概率在请求处理过程中崩溃。
初步查看
少量uWSGI日志
线上报 502 之后,先查看 uWSGI 日志,发现会有少量 worker 崩溃的情况。平时业务出现问题,一般是 Python 层面逻辑不对,比如出现 Exception,请求超时之类的,比较少有进程直接挂掉的情况。而且我印象里 RPC Server 不太会有这种崩溃的情况,以前简单看过一眼 uWSGI 的 C 扩展部分,不过没有看细节,当时就觉得这些对对象引用计数的处理部分挺容易出错的,其它逻辑倒还好。所以我的第一直觉是 C 扩展部分写的有问题,而且很可能是 Python 对象引用计数错误导致的。
而具体到 log 能直接看到的内容并不多,大概是这样几行:
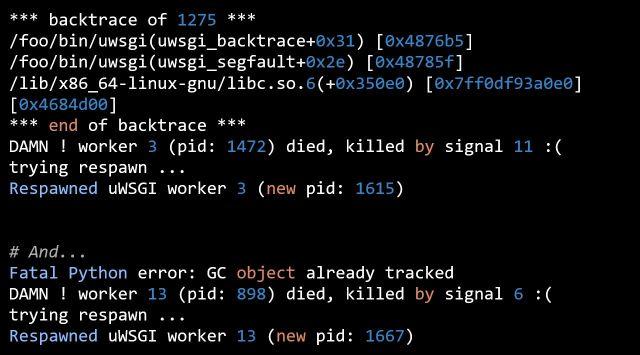
这里除了能知道是 master 进程发现 worker 进程挂了,然后又拉起来一个,其它重要信息就是 signal 11 和 signal 6 了。
一般来说出现 Segmentation Fault(signal 11)这种情况是比较麻烦的,出事的地方往往不是第一现场,有可能是另外的代码已经把内存状态跑错了。
而 Abort(signal 6)就好一点了,可能是程序主动为之。而且 GC object already tracked 这条信息非常关键,应该是 Python 虚拟机发现状态异常主动抛出来的。
于是翻出 Python 源码:

从这个宏中可以看出来,是在向 Python 虚拟机申请一个对象的时候,发现其引用计数不是 PyGCREFS_UNTRACKED。
直觉
GC_TRACK 这个宏是把对象加入 GC 链里边,是申请对象的时候的操作。看起来似乎不是减少引用计数释放内存的时候出现的问题啊。
其实也不一定,因为既然需要在使用前对对象进行 check,那大概说明这个对象的类在内部实现是有对象池的(之前只看了 int 对象池细节,但是知道很多内置类型有对象池),而对象在被放回对象池的时候有问题,当时没有发现,而再拿出来用的时候出错了也合理。
而收到 signal 11 时内存越界错误不一定跟这个有关,可能是另外的问题,也可能是相同的原因。反正内存被乱写,谁知道会发生啥呢。这个方向不好直接查。
找到一个有问题的点
可以说干猜大概只能猜到这里了。下面得用工具具体调试一下出现问题的现场了。
从线上看,单台机器上 10 分钟左右会出现一次崩溃,于是在一台机器上打开 core dump 文件配置(ulimit 和/proc/sys/kernel/core_pattern),重新编译 Python,加上–with-pydebug 选项,放到线上去跑。
而用这个版本在线上跑的时候,出现了另外一种情况:每次出错的接口请求打进来,worker 就挂了。
之前是偶尔挂掉,现在是每次请求都崩溃,难道是编译的有问题?
不过仔细看另外获得的 has negative ref count 日志发现,错误出现同在一个地方。

这个代码的意思是,虚拟机在对一个对象减少引用计数的时候,如果正好减到了 0,那么就该回收这个对象了。而在打开 PyREFDEBUG 的情况下,会检查是不是已经把引用计数减成负的了,减成负数说明虚拟机内部状态不正常。这个选项是在打开–with-pydebug 才有的。
也就是说调用到这里的代码有问题。到底是不是引起崩溃的主要原因不好确定。
从 gdb 查看崩溃时候的调用栈,可以找到对应的 C 代码如下:
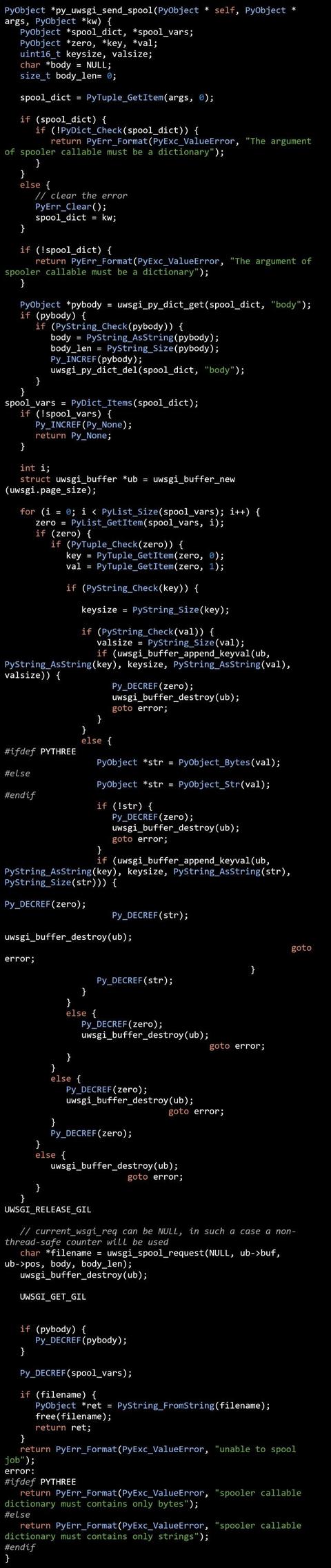
这里把整个函数全放上来,是因为这段代码非常关键。
先简单解释一下这里在处理什么逻辑:
这个函数是 uWSGI 的 C 扩展,绑定到 Python 层的 uwsgi.spool 函数,现在我们在 uWSGI 里面用 spooler 功能的时候,是在 Python 逻辑处理函数上面套一层 decorator,本进程做的事情是把参数还有函数名等封装成一个 dict 整体扔到共享内存里边,然后由 uWSGI 另外启的 spooler 进程拿到数据,再调用被修饰的函数体。
回头看上面的 C 扩展的大概流程
先做一些检查,比如 spool_dict 这个是不是从 Python 层面以 dict 形式传进来的,dict 中有没有超长的 value 以”body”为 key 传进来
把 dict 转换成 list,每个元素是原始 dict 的 (key, value) 组成的 tuple。类似于调用了一次 dict.items() 函数
把这个 list 扫描一遍,确保 tuple 的两个元素 key value 都是 str 类型,并且把内容塞到 buffer 里边
释放 GIL
把 buffer 里的内容和可能传进来的 body 塞到共享内存并且释放 buffer
重新获取 GIL
对刚才转换出来的 list 释放一次引用 PyDECREF(spoolvars);
其中在第 3 步扫描每个 tuple 的过程中(pyuwsgisend_spool 2018 行),错误的多减少了一次引用计数:

因为在 1969 行这一步的时候,并没有给 zero 增加引用计数。
到这里可以简单提一下 Python 中对象管理的方式了。跟大部分 GC 实现不一样,Python 主要用了引用计数的方式来自动回收内存,即在把一个对象赋值给一个变量、被另外一个容器引用、作为参数传递等的时候引用计数加 1,离开作用域(即不再被变量指向)、不被容器引用等时候减少引用计数。用 Mark And Sweep 解决循环引用的问题,同时用了分代等优化手段。这样实现的 GC 代码在实际运行起来比通常的方式会慢一点,不过对象大部分时间会第一时间被释放(当然可能只是释放后回到对象池)。
回到对 tuple 引用计数部分,在上面这个函数最后执行 PyDECREF(spoolvars) 的时候,其实是对其所有的引用对象又释放了一遍的。
但是平时为什么不会每次调用都出现崩溃的问题呢。这里涉及到了 Python 多线程的问题。前面提到 Python 为了保证单线程场景下执行效率还有 C 扩展编写容易,一直保持了 GIL 即全局解释锁的实现,Python 大部分线程代码在执行的时候,都是持有这个锁的,也就是通常一个进程内只有一个线程在执行。有几种情况会释放掉这个锁,比如显式释放、IO 调用,连续执行 byte code 到达一定数量(默认 100 条)。
由于有 GIL 锁的限制,上面这段代码只在非常短的时间窗口内会跟其它线程出现交替执行的情况。就是上面提到的第 5 步。而另外一个线程是 10s 才去请求一次 Consul 获取下游服务地址列表的,其它时间在 sleep。所以线上不会太频繁的出错。
平时大部分时间执行都挺好的,而在打开 REF 检查的时候才出错,大概可以猜测如果这里没有这个小的时候窗口让线程切换,就算多减了一次引用计数也不会有问题。具体可以参考最上面的宏实现,Python 代码在把一个对象引用计数减到 0 的时候会主动对其释放,再减成负的也不会额外作处理。
直觉
虽然之前没有直接看过 tuple 对象池的代码,但是看过 int 对象池的实现,对于 Python 的对象管理和内存管理有一定理解,加上看到有 GIL 释放的处理,还有
这条非常关键的 log 提示,我又大胆进行了一次猜测,出现 core dump 的地方很可能是这样一个顺序
1. spooler 执行到的地方即 uWSGI worker 线程在循环执行的过程中把 tuple 放回了对象池
2. 释放 GIL
3. 另外一个线程需要使用 tuple,于是从对象池中拿出了这个对象
4. 使用 spooler 的线程又把这个 tuple 的引用计数减了 1,又放回了对象池
5. 另外那个线程继续用这个 tuple,增加了其引用计数
6. 另外那个线程本身或者再切到第三个线程,需要用 tuple 对象,尝试从对象池里面取
7. 检查到 PyGCHeadREFS(g) != PyGCREFS_UNTRACKED 条件不满足,崩溃
其实如果没有 uWSGI log 里面那条额外的提示,我猜测的最后几步顺序可能不是这样,而是稍微简单一点,比如第 4 步把对象放回对象池之后,接着 GC 把对象池清空了,然后第 5 步继续使用这个 tuple 就已经足够让程序崩溃了。当然这样收到的信号最可能是 signal 11。
GDB 展示调用栈
有了一个大概的猜想,下面就是拿工具和代码来验证实际是不是这样一个场景了。
从某 core 文件里面可以看到这样一个栈信息
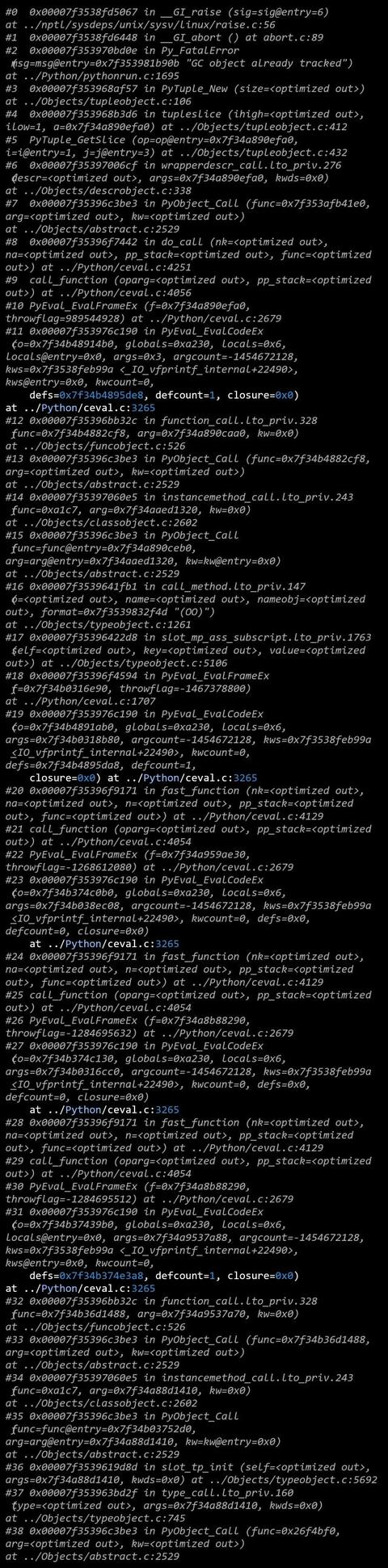
从调用栈大概可以看出,出现问题的地方是一个 Python 虚拟机在解释 byte code 的过程当中,一个 callable object(大概可能是实现了 call 的对象)被调用,想要使用一个 tuple,然后调用了 PyTupleNew,但是遇到了上面提到过的 PyObjectGCTRACK 这个宏不满足条件,主动调用了 abort()。
不过由于上面只是猜想,而且过程需要绕几个弯才能真正在线上出现问题,概率很低,还需要一些手段来验证当时的场景是不是这样。
uWSGI C 扩展修复
既然已经找到了一个 bug,而且看起来进程崩溃跟这个很可能有关,那就先改一下好了。
整体上改动并不是很多。既然代码中错误的多减少了 zero 的引用计数,那把相应的几行去掉就好了。这样就不会在主动释放 spool_vars 的时候再减一次了 。
不过需要注意的一点是后面有个 error 的 label,在这个后面需要再对 spool_vars 处理一下,防止内存泄漏。
把修改过的二进制版本放到一台机器上去测试,一整天都没有出现 core dump。难道 bug 就这样修复了?会不会还有其它隐藏的 bug 呢。程序内部到底是什么样一个过程导致线上崩溃呢。毕竟上面出现崩溃的过程只是一个猜想,实际上并不一定完全是这样。
复现
现在就需要在线下稳定复现这个问题了。实际上复现的过程比找到问题还要麻烦一些。
搭建线下环境
于是我用业务 HTTP 代码改了一下,只留一个接口,并且在接口内部处理的时候尽量精简,大概只是调用了 spooler 一次,然后随便折腾用了几个 tuple,看看随意的多样的使用这些 tuple 对象会不会把崩溃的概率提高一些。
由于之前分析过,这个 bug 跟 Python 多线程有关,所以要想复现这个问题,要尽量把多线程相关的操作贴近线上环境,否则折腾半天复现不出来,都不好说哪里的问题。
业务方自己并没有使用多线程,唯一用到的地方就是框架中另启了一个线程去轮询 consul 以获取下游的地址列表。所以我把这个 API 的下游全 dump 出来,在接口的入口处先主动调用了一下对应函数,把列表加到缓存里边让线程开始轮询。这里没有直接放在初始化的地方,是想让进程启动的时候尽量少做事情,让虚拟机内部状态简单可控一些。
尝试主动清空对象池
在尝试复现这个问题的过程中,我也走了一些弯路。
我在想既然是主 worker 线程把对象放回对象池后其它线程会出现问题,那如果在刚刚把对象放回对象池之后,就把对象池清空,是不是至少不会出现在 GC untrack 的时候出错进而调用 abort() 呢(当然既然真的多减引用计数了,所以内存使用错误 signal 11 还是有可能收到的)。
于是我在 C 代码中加入了对 PyTuple_ClearFreeList 的调用,把这个函数绑定到 Python 层面进行调用,在 worker 线程 Python 代码中主动调用 gc.collect()。几种组合操作,都没有明显效果,还是两种 signal 带来的崩溃都有。
之后分析,才发现这样尝试是有问题的。这个涉及到了 Python 中对于内置类型的对象管理和内存管理这两层之间的关系。实际上对 tuple 对象的错误操作渗透到了底层内存第一层对象池 block 去了,即清理了 tuple 的对象池放回 block,然后需要生成 tuple 对象的时候由于 tuple 对象池己空所以又从 block 中拿出来一块内存用作 tuple 对象。而此时虚拟机对这块地址的错误引用问题依然存在,还是会非法修改其引用计数。实际上清理对象池之后,崩溃的时机不止在于对 tuple 的使用,因为也可能有其它类型需要从 block 池中拿相同大小的一块内存。不过这种情况概率并不高,测试的时候没有太注意。
打印被 spooler 使用的 tuple 对象 id
吃饭的时候想到一点,其实我首先可以简单的把对象 id 打印出来,看看在 uWSGI 里面被污染的 tuple 是否包含了跟出现 core dump 的时候最后用到的 tuple 对象。万一哪次不用,其实也就说明之前的猜想是有问题的。
于是我把 pyuwsgisend_spool 函数用到的所有 tuple 的内存地址都打了出来,再用 gdb 打开 core 文件,跟栈顶(不是最顶)最后一次用到的 tuple 的地址对比。
手动出现的四个 core 文件中,三个都是 pyuwsgisend_spool 函数最后放回对象池的对象跟栈顶对象一致,另外一个不是,不过也出现过。感觉安心了一点。
增加被 spooler 函数错误使用的 tuple 对象数量
突然想到,打印出来的对象 id 都是三个一组,每次 request 进来被污染的对象其实并不多。这时才想起来上面提到的那个 decorator。仔细一看,原来每次扔进 C 函数的 dict 都是确定的三个 key,一个 fucntion name,另外两个是 args 和 kwargs 被 pickle 之后的 str。
于是,我非常暴力的加了个循环:在 dict 里面另外加了 50 个 key value(当然最后精准复现问题的时候是不需要这样额外加的)。
于是,测试进程频繁出 core。复现过程终于有一些进展了。
另写线程折腾 tuple 大致复现问题
上面复现的过程是在线下把对接口请求的响应做到尽量精简,并且增加被 spooler 用错的 tuple 对象数来方便复现问题。但是另外一个线程跑的还是框架里面的轮询 consul 的代码,有不少代码逻辑并且有网络调用,这样中间过程哪些是对复现问题有用的,哪些没有用并不清楚。
我先在 spooler 的 C 代码中释放 GIL 之后加了一行 sleep(2),让另外一个线程比较方便的执行一些操作。而在另外这个线程中把之前请求 consul 的代码去掉,只留线程的壳子,改成一段简单的 Python 代码,大概按照顺序做这样几件事情:
1. sleep 一下,等待手工打入一条请求,触发写 spooler 操作
2. 生成五六个 tuple
3. sleep 2s 切回 spooler 进程
4. 用两个对象引用这五六个 tuple
5. 再生成几个 tuple
这样请求打进来几次,程序就崩溃了。比之间复现频率高了非常多。
但是,之前的猜想是在第 5 步再从对象池申请使用 tuple 的时候就该崩溃了啊,为啥程序还在继续跑,而处理过几次请求之后才崩溃呢?
精准复现
这个问题实在猜不出来为啥了,这时候回头想上面那行关键的提示:
GC object already tracked
然后回头去看代码,才发现原来自己以前对 Python 对象在内存中的布局理解一直有点偏差,那就是记录一个对象是不是 Tracked 的状态的标记是放在对象所在内存的前面,而 refcnt 是在对象的头部,即所有 Python 对象都有的 PyObject 头。
对象放回对象池的时候,是 Tracked 标记的位置改成 UNTRACKED,这时候如果 GC 开始,那就会被回收掉(我之前还尝试手动 GC 来回收的,不过忘了标记位在这里)。而我把对象从对象池拿出来,然后切换线程去减掉其引用计数,再在 Python 代码里面增加引用计数等操作,对引起崩溃都不是最直接的做法。
直接跟 GC object already tracked 相关的问题在于一个对象从对象池里被拿出来被标记为 Tracked 之后,又被拿出来一次才会被检查到不正常。也就是说,我需要把一个 tuple 对象在两个线程里边交叉两次获取却三次放回对象池,然后连续尝试两次拿出来才会出现 uWSGI log 里面的错误提示。
最后写出这样一段代码:
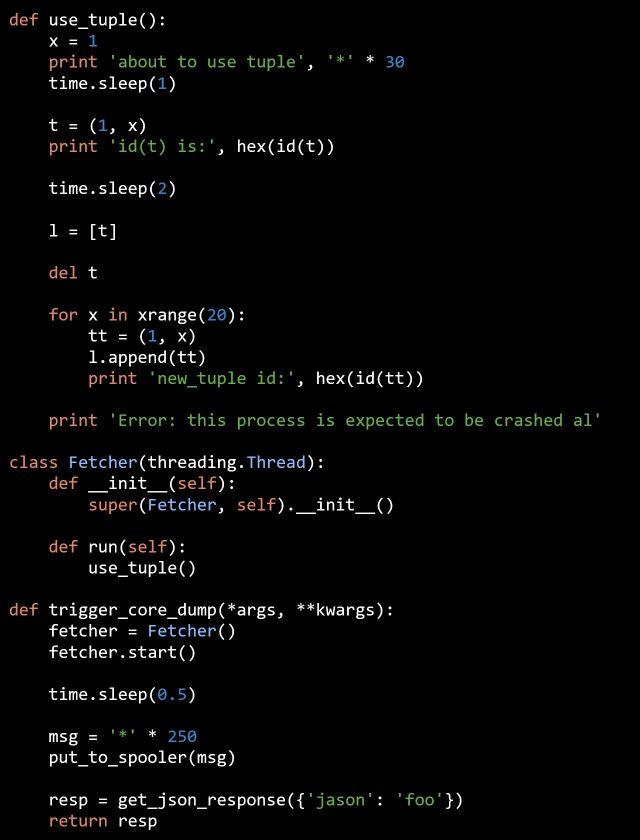
终于,每次手动打进来一个请求,worker 就会崩溃。
这段看似挺正常而没什么作用的 Python 代码,其实每一行的操作和前后顺序都非常重要。尤其 11 和 13 两行代码就是在 spooler 线程已经把 t 放回对象池之后,又把其引用计数加一再减一,又一次放回对象池。那么在最后连续申请 tuple 对象的时候就出错了。
两个线程的交替时序可以用下图展示:

问题复现到这里,想出现另外一种 Segmentation Fault 的崩溃现象也是比较简单的。不让程序连接申请 tuple 对象立即出上面的错误,再跑一会儿就挂了。让多减一次引用计数这个操作影响到 tuple 相关内存以外的代码就行。
总结
整体上来说问题出现的原因在于 uWSGI 的 C 扩展存在 bug 导致 Python 虚拟机中 tuple 对象被不正常的重复放回对象池而引起其引用计数错误。其中大部分崩溃的情况是程序试图把对象从 tuple 对象池中重新拿出来使用的时候虚拟机检查到 GC 状态不正常,主动调用了 abort(),小部分情况是被放回 tuple 对象池的内存回到内存池后被其它代码使用过程中被异常修改内容,导致程序在执行过程中不确定的位置逻辑异常,最终导致内存越界。
而复现的时候需要控制两个线程的执行顺序,线程交叉两次获取 tuple 对象却三次放回对象池,然后再连续尝试两次拿出来使用,才可以稳定让程序崩溃。
整体上查找修复并复现这个问题,除了基本工具的使用,对各种细节的理解,另外还需要一些猜想和尝试。这种没有固定 Pattern 可寻只能从有限的信息中找到线索,猜想出错原因再去构建一种复杂执行顺序验证的过程还是比较锻炼思维的。