感觉芯片分析很多原理不是很懂,2002年的这篇文献介绍标准化思想在RNA-seq和芯片分析中都得到了广泛应用,其中并不涉及复杂的统计学公式,读完后有豁然开朗的感觉,原来最初的标准化原理不过如此
文章地址为:
https://www.stat.berkeley.edu/~terry/zarray/Html/normspie.html
https://www.ncbi.nlm.nih.gov/pubmed/11842121
文章为2002年发表在Nucleic Acids Research上的文章,介绍了一种对芯片数据进行标准化的方法,标准化处理之后,使得不同组别之间具有可比性
1. 简介
芯片试验的系统误差很多因素都可以造成,包括不同荧光(绿色的Cy3和红色的Cy5)标记的效率、实验组与对照组用于杂交核酸总量的差异、扫描参数造成的差。传统的做法是使用Global normalization的方法是引入一个校正常数k,使log-ratios(M)的中位数为0,但是由于这种方法没有考虑到不同芯片荧光密度和探针的不同位置(即不同点样针点样)所引起的误差(print-tip effects 点样针效应)。该文提出了对于芯片实验中荧光密度依赖和位置依赖误差的标准化方法。
2. 背景
芯片的标准化目的为平衡同一芯片上的绿色(Cy3)和红色(Cy5)荧光强度,并且对不同芯片的荧光值进行处理,使不同芯片之间也具有可比性。【包括within slide和multiple slide的标准化】。不同荧光造成的偏差可以由以下实验证明:同一mRNA样本用不同荧光标记,并且与同一芯片上的探针杂交,通常绿色的信号强度比红色的信号强度高,造成该偏差的原因可能是由于荧光素的物理性质包括热、光敏感度以及它们的半衰期,荧光标记的效率,探针的制备过程,扫描参数的设定有关。仅仅用Global标准化方法不能有效消除这些误差,并且重复组数据之间可能有不同的spread,需要进行scale校正以防止一个较极端的实验的结果对其他重复组的结果有太大的干扰。
标准化包括(1)同一芯片内荧光强度的标准化(2)多个不同芯片之间的标准化(3)dye-swap(荧光交换)芯片的标准化【dye-swap实验为配对的芯片,如一个芯片中实验组用绿色,对照组用红色荧光标记,而另一个芯片中实验组用红色,对照组用绿色标记】
3 用于标准化的基因的选择
3.1 所有基因用于标准化
前提条件:(1)不同组别之间仅仅有少量基因表达发生显著变化(2)上调和下调的基因数目几乎相同,即对称性
一般实验中,对照组和实验组仅仅有少量的基因差异表达,因此大多可以适用
3.2 表达恒定的基因用于标准化(管家基因)
一般认为管家基因在很多条件下表达都是恒定的,如β actin,通常很难找到在任何情况下表达量都恒定的基因,但是可以找到在某个实验条件下的“temporary” 管家基因。
使用管家基因的限制是它们往往表达量比较高,对于全部的基因来说不具有代表性。
3.3 设置特殊对照用于标准化
合成不存在于实验组和对照组中的核酸序列探针,并在实验组和对照组mRNA中加入等量该核酸,由该特殊探针产生的荧光值进行标准化。
4 标准化
标准化的目的是为了是不同组别之间的数据具有可比性,如前所述,一般实验中,对照组和实验组仅仅有少量的基因差异表达,因此大多数基因的log-ratio【即log(组1)-log(组2)】值都应该在零左右,并且正负值大致相当。
MAplot就是衡量标准化是否成功的一个方法,以M为纵坐标
A为横坐标
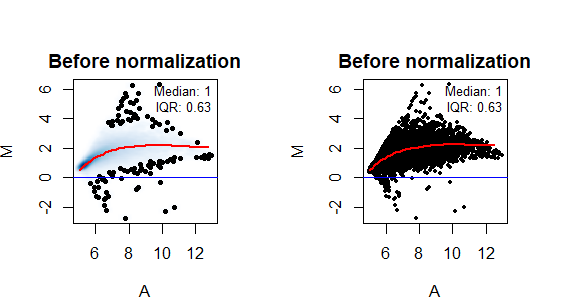
因此M代表不同组别之间的基因的表达差异,A代表基因表达的平均水平(即芯片的荧光信号强度),当差异值是随着表达水平而变化时,MAplot可以很好的鉴别出这种系统偏差,如下图:可以很清楚地看出M不是以y=0这条线为中心的(中位数不是0),说明存在系统偏差,需要进行校正。
## 原载入实例始数据
load(url("https://github.com/x2yline/Rdata/raw/master/normlization/LSH_KO_GSE29392_raw_matrix.rdata"))
M <- log2(matrix_LSH[, 1]) - log2(matrix_LSH[, 2])
A <- (log2(matrix_LSH[, 1]) + log2(matrix_LSH[, 2]))/2
plot(A, M, pch=20, main="Raw data", cex=0.75)
lines(lowess(M~A, f=0.2), lwd=2, col="red")

也可以使用
affy包做MAplot
par(mfrow = c(1, 2), pty = "s", mar=c(2,1,2,1) , pin=c(1.5,1.5))
library(affy)
ma.plot(A, M, show.statistics=T,
span=0.2,plot.method="smoothScatter",
lwd=2, pch=20, cex=0.8,
main="Before normalization")
ma.plot(A, M, show.statistics=T,
span=0.2,plot.method="normal",
lwd=2, pch=20, cex=0.8,
main="Before normalization")
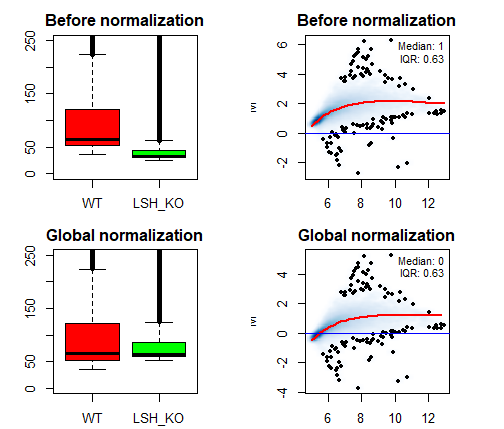
4.1 全局标准化
c为标准化常数,引入c后时M的中位数为0,即c=median(M)
R语言实现如下:
可以看出确实通过标准后后,M的中位数变成了0,两样本的表达量中位数也相同了,但是由表达量而变化而产生的偏差并没有完全消除,即lowess拟合的曲线并没有很好地接近直线y=0
c <- median(M)
par(mfrow = c(2, 2), pty = "s", mar=c(2,1,2,1) , pin=c(1.5,1.5))
boxplot(matrix_LSH[, 1], matrix_LSH[, 2],
ylim=c(0, 250), col=c("red", "green"),
main="Before normalization",
names=colnames(matrix_LSH))
ma.plot(A, M, show.statistics=T,
span=0.2,plot.method="smoothScatter",
lwd=2, pch=20, cex=0.8,
main="Before normalization")
boxplot(matrix_LSH[, 1], matrix_LSH[, 2]*2^c,
ylim=c(0, 250), col=c("red", "green"),
main="Global normalization",
names=colnames(matrix_LSH))
ma.plot(A, M-c, show.statistics=T,
span=0.2,plot.method="smoothScatter",
lwd=2, pch=20, cex=0.8, main="Global normalization")
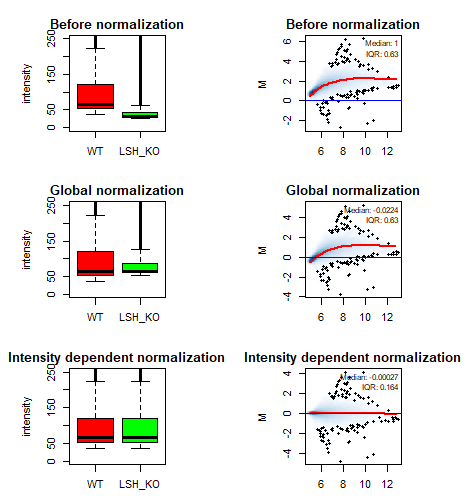
4.2 表达量(A值)依赖的标准化
由于不同的表达量(A值)对应的M偏离0的距离不同,因此这次使用c(A),即c是A的一个函数,而不再是常数来进行标准化。
R语言实现如下:
可以看出经过标准化后,M的分布基本上是以0为中位数,并且上调和下调的基因数目几乎相等
lowess.model <- lowess(A, M, f=0.1)
# create a functional version of the lowess fit
# https://stats.stackexchange.com/questions/126699/residuals-from-lowess-curve
lfun <- approxfun(lowess.model)
par(mfrow = c(3, 2), pty = "s", mar=c(2,1,2,1) , pin=c(1, 1))
boxplot(matrix_LSH[, 1], matrix_LSH[, 2],
ylim=c(0, 250), col=c("red", "green"),
main="Before normalization",
names=colnames(matrix_LSH), ylab="intensity")
ma.plot(A, M, show.statistics=T,
span=0.2,plot.method="smoothScatter",
lwd=2, pch=20, cex=0.8,
main="Before normalization")
boxplot(matrix_LSH[, 1], matrix_LSH[, 2]*2^c,
ylim=c(0, 250), col=c("red", "green"),
main="Global normalization",
names=colnames(matrix_LSH), ylab="intensity")
ma.plot(A, M-c, show.statistics=T,
span=0.2,plot.method="smoothScatter",
lwd=2, pch=20, cex=0.8, main="Global normalization")
boxplot(matrix_LSH[, 1], matrix_LSH[, 2]*2^(lfun(A)),
ylim=c(0, 250), col=c("red", "green"),
main="Intensity dependent normalization",
names=colnames(matrix_LSH), ylab="intensity")
ma.plot(A, M-lfun(A), show.statistics=T,
span=0.2,plot.method="smoothScatter",
lwd=2, pch=20, cex=0.8, main="Intensity dependent normalization")
4.4 Scale缩放【使不同样本spread相同,但可能会造成更大误差,因此通常不使用】
如果在做完以上标准化之后,各样本的M分布大致相当时,可以不用做scale缩放,以免引入更多的混杂因素
由于该示例数据只有两个样本,,本来是需要在不同样本中缩放M,使M的spread大致相同,由于只有两个样本,因此该实例用表达量代替M作scale变换
par(mfrow = c(1, 1), pty = "s", mar=c(1,1,1,1) , pin=c(1, 1))
boxplot(matrix_LSH[, 1], matrix_LSH[, 2],
ylim=c(0, 250), col=c("red", "green"),
main="Before normalization",
names=colnames(matrix_LSH), ylab="intensity")

可以看出这两个样本表达量的spread(变异程度)不一致,需要标准化为相同spread,直接使用标准差进行缩放受极端值影响较大,该文提出使用mad(Median_absolute_deviation中位数绝对偏差)的方法进行缩放,可以达到较好的效果
原理为,不同样本分别除以一个缩放因子,使其方差由原来的αi^{2} * σ2都变为σ2,使各样本的方差均为 σ^2 即都相等
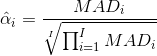
i为样本编号,共由I个样本,MAD为中位数绝对偏差,如果没有极端值的影响MAD可以用标准差替代
R语言实现:
scale_factor1 <-mad(matrix_LSH[, 1])/ (mad(matrix_LSH[, 2])*mad(matrix_LSH[, 1]))^(0.5)
scale_factor2 <- mad(matrix_LSH[, 2])/(mad(matrix_LSH[, 2])*mad(matrix_LSH[, 1]))^(0.5)
par(mfrow = c(1, 2), mar=c(2,1,2,1))
boxplot(matrix_LSH[, 1], matrix_LSH[, 2],
ylim=c(0, 250), col=c("red", "green"),
main="Before adjustment",
names=colnames(matrix_LSH), ylab="intensity")
boxplot(matrix_LSH[, 1]/scale_factor1, matrix_LSH[, 2]/scale_factor2,
ylim=c(0, 150), col=c("red", "green"),
main="Scale adjusted normalization",
names=colnames(matrix_LSH), ylab="intensity")
