在软件行业里面,关于是否需要重复造轮子,一直是一个讨论的问题?我个人是一个喜欢重复造轮子的人,并不是我不相信开源项目里的“轮子”,而是我想学习一下别人的思想是什么?关于“轮子”我们一直是使用者,也是学习造轮子的技术的学习者。一直被别人讨论为闭门造轮子,但是我一直都不认为我是一个闭门造轮子的人。一直都在借鉴别人和学习别人。
JDK1.8从发布到现在已经有二年多时间了!但是对于我们而言,我们一直使用JDK1.6,JDK1.7,其实不是我们不想使用JDK1.8。而是我们的开发人员对于1.8的特性了解不是很多。即使1.7的特使我们都没有使用多少新特性,别说1.8了。即使使用1.8,但是我们还在使用1.7的特性,那么和1.7其实没有多大的必要。
聊聊1.8的新特性吧!
1:接口改善
2:函数式接口
3:Lambdas
4:java.util.function
5:java.util.stream
6:泛型接口改进
7:java.time
8:集合API附件
9:增加并发API
10:IO/NIO API的新增内容
11:反射和annotation的改动
12:Nashorn JavaScript 引擎
对于一个Java开发人员而言,其实每一次JDK发布新的标准的时候,我往往是欣喜若狂,因为不同的标准出现,你就会发现,你将为之少付出很多时间去实现一个以前需要花很长时间的功能了。但是其实我个人思考的是,其实随着各种规范出现,是否我们都要去实现,我个人其实不是很喜欢,我只喜欢根据这些规范我准备实现什么,我准备为这些规范如何在哪些模块准备以一种什么样的方式实现它。
说说正题吧!
众所周知Java8中加入了lambda语法,这一特性也帮助Java开发者极大的简化了开发。相对于Java世界的ORM框架的话,我们有JPA,Hibernate,Mybatis等等一些被认可的很好的ORM框架。但是当Jdk1.8出现,lambda和stream是否可以组合成一个新的ORM架构呢?现在市面上已经有了Speedment框架就是使用lambda表达式操作数据库的框架。当我想做这个的时候,Speedment版本不知道迭代了多少版本!我不认为我做的有Speedment那么好,但是我肯定可以通过这个可以更加方便理解lambda和stream。
先来一个简单的数据集存储在List里面,然后从List中搜索想要的数据吧!
一开始没法做的那么复杂,只能通过简单List先理解lambda和stream。因为我个人认为只有这样才能进一步的了解和编写想要的。
List
List test = list.stream().
filter(module -> module.equals("1")).
filter(module -> module.equals("2")).
collect(Collectors.toList());
对于我个人而言其实第一步就是如何集成Stram接口和重写里面的方法。因为我认为filter其实就是我们的查询条件。但是对于数据库我们有Join等等一些列SQL的写法。
在这个开发过程中对于Stream理解是一个很大的挑战,我们来看看IBM上面对于Stream介绍吧!
为什么需要 Stream
Stream 作为 Java 8 的一大亮点,它与 java.io 包里的 InputStream 和 OutputStream 是完全不同的概念。它也不同于 StAX 对 XML 解析的 Stream,也不是 Amazon Kinesis 对大数据实时处理的 Stream。Java 8 中的 Stream 是对集合(Collection)对象功能的增强,它专注于对集合对象进行各种非常便利、高效的聚合操作(aggregate operation),或者大批量数据操作 (bulk data operation)。Stream API 借助于同样新出现的 Lambda 表达式,极大的提高编程效率和程序可读性。同时它提供串行和并行两种模式进行汇聚操作,并发模式能够充分利用多核处理器的优势,使用 fork/join 并行方式来拆分任务和加速处理过程。通常编写并行代码很难而且容易出错, 但使用 Stream API 无需编写一行多线程的代码,就可以很方便地写出高性能的并发程序。所以说,Java 8 中首次出现的 java.util.stream 是一个函数式语言+多核时代综合影响的产物。
什么是聚合操作
在传统的 J2EE 应用中,Java 代码经常不得不依赖于关系型数据库的聚合操作来完成诸如:
1:客户每月平均消费金额
2:最昂贵的在售商品
3:本周完成的有效订单(排除了无效的)
4:取十个数据样本作为首页推荐
这类的操作。
但在当今这个数据大爆炸的时代,在数据来源多样化、数据海量化的今天,很多时候不得不脱离 RDBMS,或者以底层返回的数据为基础进行更上层的数据统计。而 Java 的集合 API 中,仅仅有极少量的辅助型方法,更多的时候是程序员需要用 Iterator 来遍历集合,完成相关的聚合应用逻辑。这是一种远不够高效、笨拙的方法。在 Java 7 中,如果要发现 type 为 grocery 的所有交易,然后返回以交易值降序排序好的交易 ID 集合,我们需要这样写:
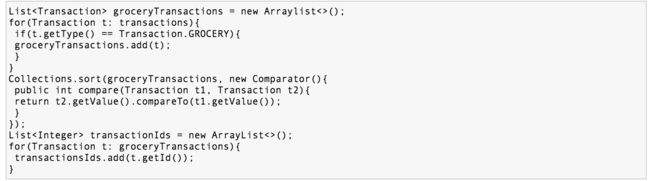

Java 8 使用 Stream,代码更加简洁易读;而且使用并发模式,程序执行速度更快。
Stream 总览
什么是流
Stream 不是集合元素,它不是数据结构并不保存数据,它是有关算法和计算的,它更像一个高级版本的 Iterator。原始版本的 Iterator,用户只能显式地一个一个遍历元素并对其执行某些操作;高级版本的 Stream,用户只要给出需要对其包含的元素执行什么操作,比如 “过滤掉长度大于 10 的字符串”、“获取每个字符串的首字母”等,Stream 会隐式地在内部进行遍历,做出相应的数据转换。
Stream 就如同一个迭代器(Iterator),单向,不可往复,数据只能遍历一次,遍历过一次后即用尽了,就好比流水从面前流过,一去不复返。
而和迭代器又不同的是,Stream 可以并行化操作,迭代器只能命令式地、串行化操作。顾名思义,当使用串行方式去遍历时,每个 item 读完后再读下一个 item。而使用并行去遍历时,数据会被分成多个段,其中每一个都在不同的线程中处理,然后将结果一起输出。Stream 的并行操作依赖于 Java7 中引入的 Fork/Join 框架(JSR166y)来拆分任务和加速处理过程。Java 的并行 API 演变历程基本如下:
1:1.0-1.4 中的 java.lang.Thread
2:5.0 中的 java.util.concurrent
3:6.0 中的 Phasers 等
4:7.0 中的 Fork/Join 框架
5:8.0 中的 Lambda
Stream 的另外一大特点是,数据源本身可以是无限的。
流的构成
当我们使用一个流的时候,通常包括三个基本步骤:
获取一个数据源(source)→ 数据转换→执行操作获取想要的结果,每次转换原有 Stream 对象不改变,返回一个新的 Stream 对象(可以有多次转换),这就允许对其操作可以像链条一样排列,变成一个管道。

看看JDK1.8中Stream的API,你会发现一些你看的很熟悉的"东东"
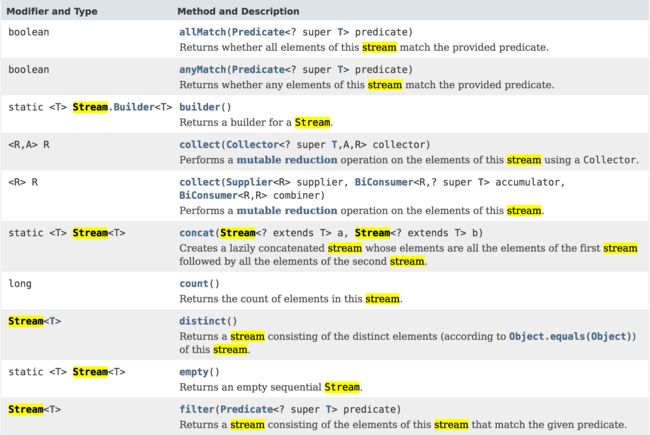

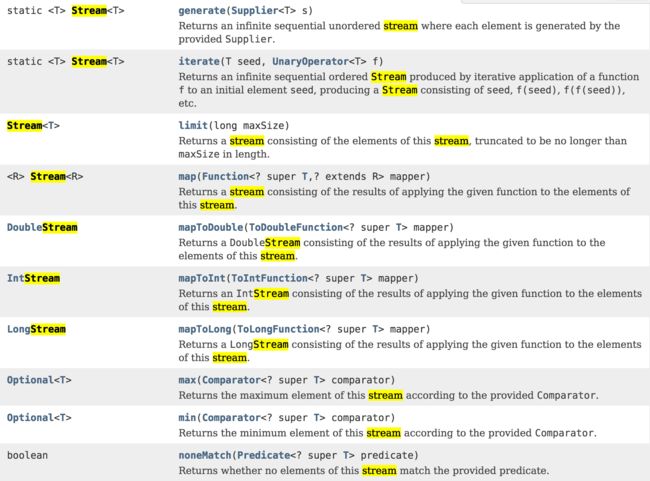
具体很多请参考http://docs.oracle.com/javase/8/docs/api/index.html的介绍。
发现了什么?
夜已深,准备开始新的挑战,根据这些简单的介绍,相信大家知道我准备怎么干了。即使这么做很傻。但是我还是这么做。