目录
- 10.1 异常增加复杂性的原因
- 10.2 例外情况太多
- 10.3 定义不存在的错误
- 10.4 示例:在Windows中删除文件
- 10.5 示例:Java子字符串方法
- 10.6 屏蔽异常
- 10.7 异常聚合
- 10.8 事故?
- 10.9 设计不存在的特殊情况
- 10.10 做过了头
- 10.11 结论
异常处理是软件系统中最糟糕的复杂性来源之一。处理特殊情况的代码天生就比处理正常情况的代码更难编写,而且开发人员经常在定义异常时没有考虑如何处理它们。本章讨论了异常对复杂性的不成比例的贡献,然后展示了如何简化异常处理。本章的主要教训是减少必须处理异常的地方;在许多情况下,可以修改操作的语义,使正常行为可以处理所有情况,并且不需要报告任何异常情况(这就是本章的标题)。
10.1 异常增加复杂性的原因
我使用术语异常来指改变程序中正常控制流的任何不寻常的情况。许多编程语言都包含一个正式的异常机制,该机制允许底层代码抛出异常并通过封装代码捕获异常。但是,即使不使用正式的异常报告机制,也可能发生异常,例如当一个方法返回一个特殊值,表明它没有完成正常行为。所有这些形式的异常都增加了复杂性。
一段特定的代码可能会遇到几种不同的异常:
- 调用者可能提供错误的参数或配置信息。
- 被调用的方法可能无法完成请求的操作。例如,I/O操作可能失败,或者所需的资源可能不可用。
- 在分布式系统中,网络数据包可能丢失或延迟,服务器可能无法及时响应,或者对等节点可能以无法预料的方式通信。
- 代码可能会检测出bug、内部不一致或无法处理的情况。
大型系统必须处理许多异常情况,特别是当它们是分布式的或者需要容错的时候。异常处理占系统中所有代码的很大一部分。
异常处理代码天生就比正常情况下的代码更难写。异常中断了正常的代码流;它通常意味着某事没有像预期的那样工作。当异常发生时,程序员可以用两种方法处理它,每种方法都很复杂。第一种方法是向前推进并完成正在进行的工作,尽管存在例外。例如,如果一个网络数据包丢失,它可以被重发;如果数据损坏了,也许可以从冗余副本中恢复。第二种方法是中止正在进行的操作,向上报告异常。但是,中止可能很复杂,因为异常可能发生在系统状态不一致的地方(数据结构可能已经部分初始化);异常处理代码必须恢复一致性,例如通过撤销发生异常之前所做的任何更改。
此外,异常处理代码为更多的异常创造了机会。考虑重新发送丢失的网络包的情况。也许包裹实际上并没有丢失,只是被耽搁了。在这种情况下,重新发送数据包将导致重复的数据包到达对等点;这引入了一个新的异常条件,对等方必须处理。或者,考虑从冗余副本中恢复丢失的数据的情况:如果冗余副本也丢失了怎么办?在恢复期间发生的次要异常通常比主要异常更微妙和复杂。如果通过中止正在进行的操作来处理异常,则必须将此异常作为另一个异常报告给调用者。为了防止异常的无休止级联,开发人员最终必须找到一种方法来处理异常,而不引入更多的异常。
对异常的语言支持往往冗长而笨拙,这使得异常处理代码难以阅读。例如,考虑以下代码,它使用Java对对象序列化和反序列化的支持从文件中读取tweet集合:
try (
FileInputStream fileStream =new FileInputStream(fileName);
BufferedInputStream bufferedStream =new BufferedInputStream(fileStream);
ObjectInputStream objectStream =new ObjectInputStream(bufferedStream);
)
{
for (int i = 0; i < tweetsPerFile; i++) {
tweets.add((Tweet) objectStream.readObject());
}
}
catch (FileNotFoundException e) {
...
}
catch (ClassNotFoundException e) {
...
}
catch (EOFException e) {
// Not a problem: not all tweet files have full
// set of tweets.
}
catch (IOException e) {
...
}
catch (ClassCastException e) {
...
}但是,基本的try-catch样板代码比正常情况下的操作代码行数更多,甚至不考虑实际处理异常的代码。很难将异常处理代码与正常情况代码联系起来:例如,在哪里生成每个异常并不明显。另一种方法是把代码分成许多不同的try块;在极端情况下,可以尝试生成异常的每一行代码。这将使异常发生的地方变得清晰,但是try块本身会破坏代码流,使其更难读取;此外,一些异常处理代码可能会在多个try块中重复。
很难确保异常处理代码真正有效。有些异常,比如I/O错误,在测试环境中很难生成,因此很难测试处理它们的代码。异常在运行的系统中不经常发生,所以很少执行异常处理代码。bug可能很长一段时间都无法检测到,当最终需要异常处理代码时,它很可能无法工作(我最喜欢的说法之一是:“未执行的代码无法工作”)。最近的一项研究发现,在分布式数据密集型系统中,超过90%的灾难性故障是由错误处理引起的。当异常处理代码失败时,很难调试问题,因为它发生的频率很低。
10.2 例外情况太多
程序员通过定义不必要的异常而加剧了与异常处理相关的问题。大多数程序员都被告知检测和报告错误很重要;他们通常将其解释为“检测到的错误越多越好”。这导致了一种过度防御的风格,任何看起来有点可疑的东西都会被异常拒绝,这导致了不必要的异常的扩散,增加了系统的复杂性。
在设计Tcl脚本语言时,我自己也犯了这个错误。Tcl包含一个未设置的命令,可用于删除变量。我定义了unset以便在变量不存在时抛出错误。当时我认为,如果有人试图删除一个不存在的变量,那么它一定是一个bug,所以Tcl应该报告它。然而,unset最常见的用途之一是清理以前操作创建的临时状态。通常很难准确地预测创建了什么状态,特别是在操作中途中止的情况下。因此,最简单的方法是删除可能已经创建的所有变量。unset的定义使得这种情况很尴尬:开发人员最终会在catch语句中封装对unset的调用,以捕获并忽略unset抛出的错误。回顾过去,unset命令的定义是我在Tcl设计中犯下的最大错误之一。
使用异常来避免处理困难的情况是很有诱惑力的:与其找出一个干净的方法来处理它,不如抛出一个异常并把问题推给调用者。有些人可能会认为这种方法赋予了调用者权力,因为它允许每个调用者以不同的方式处理异常。然而,如果你在特定情况下不知道该怎么做,很有可能打电话的人也不知道该怎么做。在这种情况下生成异常只会将问题传递给其他人,并增加系统的复杂性。
类抛出的异常是其接口的一部分;具有大量异常的类具有复杂的接口,并且它们比具有较少异常的类要浅。异常是接口中特别复杂的元素。它可以在被捕获之前向上传播几个堆栈级别,因此它不仅影响方法的调用者,还可能影响更高级别的调用者(及其接口)。
抛出异常很容易,处理它们很困难。因此,异常的复杂性来自于异常处理代码。减少异常处理造成的复杂性损害的最佳方法是减少必须处理异常的地方的数量。 本章的其余部分将讨论减少异常处理程序数量的四种技术。
10.3 定义不存在的错误
消除异常处理复杂性的最佳方法是定义api,这样就没有异常需要处理:定义不存在的错误。 这可能看起来有些亵渎,但在实践中却非常有效。考虑前面讨论的Tcl unset命令。当unset被要求删除一个未知变量时,它应该简单地返回,而不是抛出一个错误。我应该稍微修改一下unset的定义:unset应该确保一个变量不再存在,而不是删除一个变量。对于第一个定义,如果变量不存在,unset就无法执行其任务,因此生成异常是有意义的。对于第二个定义,使用不存在的变量的名称来调用unset是非常自然的。在这种情况下,它的工作已经完成,所以它可以简单地返回。不再需要报告错误情况。
10.4 示例:在Windows中删除文件
文件删除提供了另一个如何定义错误的例子。如果文件在进程中打开,Windows操作系统不允许删除该文件。对于开发人员和用户来说,这是一个持续的沮丧之源。为了删除正在使用的文件,用户必须在系统中搜索,找到打开该文件的进程,然后杀死该进程。有时用户会放弃并重新启动他们的系统,只是为了删除一个文件。
Unix操作系统更优雅地定义了文件删除。在Unix中,如果文件在删除时打开,Unix不会立即删除该文件。
它将文件标记为删除,然后删除操作成功返回。该文件名已从其目录中删除,因此其他进程无法打开旧文件,并且可以创建具有相同名称的新文件,但现有的文件数据将持续存在。已经打开文件的进程可以继续正常地读取和写入文件。一旦文件被所有访问进程关闭,它的数据就会被释放。
Unix方法定义了两种不同的错误。首先,删除操作不再返回一个错误,如果文件当前正在使用;删除成功,文件最终将被删除。其次,删除正在使用的文件不会为使用该文件的进程创建异常。解决这个问题的一种可能的方法是立即删除文件,并标记所有打开的文件来禁用它们;其他进程读取或写入删除文件的任何尝试都将失败。但是,这种方法会为那些要处理的进程创建新的错误。相反,Unix允许它们继续正常地访问文件;延迟文件删除定义了不存在的错误。
Unix允许进程继续读写一个命中注定的文件,这似乎有些奇怪,但我从未遇到过这种情况,它会导致严重的问题。对于开发人员和用户来说,Unix下的文件删除定义要比Windows下的定义简单得多。
10.5 示例:Java子字符串方法
最后一个例子是Java String类及其子String方法。给定一个字符串中的两个索引,substring返回从第一个索引给出的字符开始并以第二个索引之前的字符结束的子字符串。但是,如果其中一个索引超出了字符串的范围,则子字符串将抛出IndexOutOfBoundsException。此异常是不必要的,并使此方法的使用复杂化。我经常遇到这样的情况,其中一个或两个索引可能在字符串的范围之外,我希望提取字符串中与指定范围重叠的所有字符。不幸的是,这需要我检查每一个指标,把它们四舍五入到0或到字符串的末尾;一个单行的方法调用现在变成了5-10行代码。
如果Java子字符串方法自动执行此调整,那么它将更容易使用,以便实现以下API:“返回索引大于或等于beginIndex而小于endIndex的字符串字符(如果有的话)。这是一个简单而自然的API,它定义了IndexOutOfBoundsException异常。即使一个或两个索引是负的,或者beginIndex大于endIndex,该方法的行为也已经定义好了。这种方法简化了方法的API,同时增加了它的功能,因此使方法更加深入。许多其他语言都采用了无错误的方法;例如,Python为超出范围的列表片返回一个空结果。
当我主张定义不存在的错误时,人们有时反驳说抛出错误会捕获bug;如果错误被定义为不存在,那么这是否会导致bug生成?也许这就是为什么Java开发人员决定子字符串应该抛出异常的原因。这种错误的方法可能会捕获一些bug,但也会增加复杂性,从而导致其他bug。在错误的方法中,开发人员必须编写额外的代码来避免或忽略错误,这增加了错误的可能性;或者,他们可能忘记编写额外的代码,在这种情况下,可能会在运行时抛出意外的错误。相反,定义不存在的错误简化了api,并减少了必须编写的代码量。
总的来说,减少错误的最好方法是使软件更简单。
10.6 屏蔽异常
减少必须处理异常的位置数量的第二种技术是异常屏蔽。 使用这种方法,可以在系统的较低级别上检测和处理异常情况,这样较高级别的软件就不必知道该情况。异常屏蔽在分布式系统中特别常见。例如,在网络传输协议(如TCP)中,可以由于各种原因(如损坏和拥塞)丢弃数据包。TCP通过在其实现中重新发送丢失的包来掩盖包丢失,因此所有数据最终都能通过,而客户端并不知道丢失的包。
NFS网络文件系统中出现了一个更具争议性的屏蔽示例。如果NFS文件服务器崩溃或由于任何原因没有响应,客户端会不断地向服务器重新发出请求,直到问题最终得到解决。客户机上的低级文件系统代码不向调用应用程序报告任何异常。正在进行的操作(以及应用程序)只是挂起,直到操作成功完成。如果挂起持续的时间较长,那么NFS客户机将在用户的控制台打印“NFS服务器xyzzy没有响应,仍然在尝试”的消息。
NFS用户经常抱怨他们的应用程序在等待NFS服务器恢复正常操作时挂起。许多人建议,NFS应该在异常情况下中止操作,而不是挂起。然而,报告异常只会使事情变得更糟,而不是更好。如果一个应用程序失去了对其文件的访问权,那么它就无能为力了。一种可能性是应用程序重试文件操作,但这仍将把应用程序,并且更容易执行重试在NFS层在一个地方,而不是在每个文件系统调用在每个应用程序(编译器不应该担心这个)。另一种方法是应用程序中止并将错误返回给调用者。调用方也不太可能知道该做什么,所以它们也会中止,从而导致用户的工作环境崩溃。当文件服务器关闭时,用户仍然无法完成任何工作,而且一旦文件服务器恢复正常,他们将不得不重新启动所有应用程序。
因此,最佳的替代方案是NFS屏蔽错误并挂起应用程序。使用这种方法,应用程序不需要任何代码来处理服务器问题,一旦服务器恢复正常,它们就可以无缝地恢复。如果用户厌倦了等待,他们总是可以手动中止应用程序。
异常屏蔽并非在所有情况下都有效,但在它有效的情况下,它是一个强大的工具。它会产生更深层的类,因为它减少了类的接口(减少了用户需要注意的异常),并以代码的形式增加了掩盖异常的功能。异常屏蔽是降低复杂性的一个例子。
10.7 异常聚合
第三种减少异常复杂性的技术是异常聚合。异常聚合背后的思想是用一段代码处理许多异常;与其为许多单独的异常编写不同的处理程序,不如使用单个处理程序在一个地方处理它们。
考虑如何处理Web服务器中丢失的参数。Web服务器实现一个url集合。当服务器接收到传入的URL时,它将发送到特定于URL的服务方法来处理该URL并生成响应。URL包含用于生成响应的各种参数。每个服务方法将调用一个较低级别的方法(让我们将其称为getParameter)来从URL中提取所需的参数。如果URL不包含所需的参数,则getParameter抛出异常。
当软件设计类的学生实现这样一个服务器时,他们中的许多人将每个不同的getParameter调用包装在一个单独的异常处理程序中,以捕获NoSuchParameter异常,如图10.1所示。这导致了大量的处理程序,所有的处理程序本质上都做相同的事情(生成错误响应)。
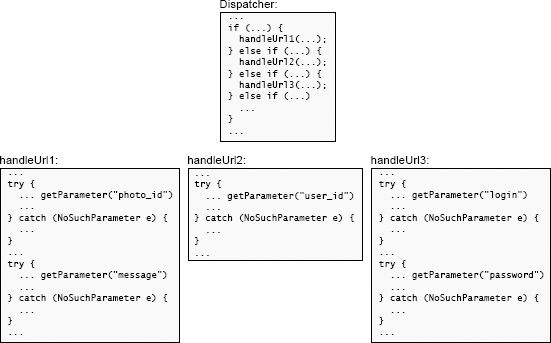
图10.1:顶部的代码分派给Web服务器中的几个方法中的一个,每个方法处理一个特定的URL。每个方法(底部)都使用来自传入HTTP请求的参数。在这个图中,每个对getParameter的调用都有一个单独的异常处理程序;这会导致重复的代码。
更好的方法是聚合异常。不捕获各个服务方法中的异常,而是让它们向上传播到Web服务器的顶级分派方法,如图10.2所示。此方法中的单个处理程序可以捕获所有异常并为丢失的参数生成适当的错误响应。
聚合方法可以在Web示例中更进一步。除了在处理Web页面时可能出现的参数丢失之外,还有许多其他错误;例如,参数可能没有正确的语法(服务方法期望的是一个整数,但是值是“xyz”),或者用户可能没有请求操作的权限。在每种情况下,错误应该导致错误响应;错误只在响应中包含的错误消息中有所不同(“URL中不存在参数‘quantity’”或“quantity”参数的“bad value’xyz”;必须是正整数”)。因此,导致错误响应的所有条件都可以使用一个顶级异常处理程序来处理。可以在抛出异常时生成错误消息,并将其作为变量包含在异常记录中;例如,getParameter将生成“URL中不存在参数‘quantity’”消息。顶级处理程序从异常中提取消息并将其合并到错误响应中。

图10.2:这段代码在功能上与图10.1相同,但是异常处理已经聚合:dispatcher中的一个异常处理程序从所有url特定的方法捕获所有NoSuchParameter异常。
从封装和信息隐藏的角度来看,上述聚合具有良好的特性。顶级异常处理程序封装了关于如何生成错误响应的知识,但它对特定的错误一无所知;它只使用异常中提供的错误消息。getParameter方法封装了有关如何从URL提取参数的知识,并且还知道如何以人类可读的形式描述提取错误。这两条信息是密切相关的,所以把它们放在一起是有道理的。但是,getParameter对HTTP错误响应的语法一无所知。随着新功能被添加到Web服务器,像getParameter这样的新方法可能会创建它们自己的错误。如果新方法以与getParameter相同的方式抛出异常(通过生成从相同超类继承的异常,并在每个异常中包含一条错误消息),它们可以插入到现有的系统中,而不需要进行其他更改:顶级处理程序将自动为它们生成错误响应。
此示例演示了用于异常处理的通用设计模式。如果系统处理了一系列请求,那么定义一个异常来中止当前请求、清理系统状态并继续下一个请求是很有用的。异常捕获在系统请求处理循环顶部附近的单个位置。此异常可在处理请求的任何时刻抛出,以中止请求;可以为不同的条件定义异常的不同子类。这种类型的异常应该与对整个系统致命的异常明确区分开来。
如果异常在处理之前在堆栈上向上传播了几个级别,则异常聚合工作得最好;这允许在同一个地方处理来自更多方法的更多异常。这与异常掩蔽相反:掩蔽通常在用低级方法处理异常时工作得最好。对于掩蔽,低级方法通常是许多其他方法使用的库方法,因此允许异常传播将增加处理它的位置的数量。屏蔽和聚合的相似之处在于,这两种方法都将异常处理程序放置在能够捕获最多异常的位置,从而消除了许多需要创建的处理程序。
另一个异常聚合的例子发生在用于崩溃恢复的RAMCloud存储系统中。RAMCloud系统由一组存储服务器组成,这些服务器保存每个对象的多个副本,因此系统可以从各种故障中恢复。例如,如果服务器崩溃并丢失了所有数据,RAMCloud将使用存储在其他服务器上的副本来重新构建丢失的数据。错误也可能在较小的范围内发生;例如,服务器可能发现某个对象已损坏。
对于每种不同类型的错误,RAMCloud没有单独的恢复机制。相反,RAMCloud将许多较小的错误“提升”为较大的错误。原则上,RAMCloud可以通过从备份副本中恢复一个损坏的对象来处理这个损坏的对象。然而,它并不这样做。相反,如果它发现一个损坏的对象,它会使包含该对象的服务器崩溃。RAMCloud使用这种方法是因为崩溃恢复非常复杂,而且这种方法最小化了必须创建的不同恢复机制的数量。为崩溃的服务器创建恢复机制是不可避免的,因此RAMCloud对其他类型的恢复也使用相同的机制。这减少了必须编写的代码量,而且这还意味着服务器崩溃恢复将更频繁地被调用。因此,恢复中的bug更有可能被发现和修复。
将损坏的对象升级到服务器崩溃的一个缺点是,它大大增加了恢复的成本。这在RAMCloud中不是问题,因为对象损坏非常罕见。然而,错误提升对于频繁发生的错误可能没有意义。举个例子,当一个服务器的网络数据包丢失时,它不可能崩溃。
考虑异常聚合的一种方法是,它用一种能够处理多种情况的通用机制替代了几个专门用于特定情况的机制。这又一次说明了通用机制的好处。
10.8 事故?
降低异常处理复杂性的第四种技术是使应用程序崩溃。 在大多数应用程序中都会有一些不值得处理的错误。通常,这些错误很难或不可能处理,而且不经常发生。为响应这些错误,最简单的方法是打印诊断信息,然后中止应用程序。
一个例子是在存储分配期间发生的“内存不足”错误。考虑C中的malloc函数,如果它不能分配所需的内存块,它将返回NULL。这是一种不幸的行为,因为它假设malloc的每个调用者都将检查返回值,并在没有内存时采取适当的操作。应用程序包含大量对malloc的调用,因此在每次调用后检查结果会增加很大的复杂性。如果程序员忘记了检查(这是很有可能的),那么如果内存耗尽,应用程序将取消对空指针的引用,从而导致掩盖真正问题的崩溃。
此外,当应用程序发现内存耗尽时,它也无能为力。原则上,应用程序可以寻找不需要的内存来释放,但是如果应用程序有不需要的内存,它可能已经释放了内存,这将在一开始就防止内存不足的错误。今天的系统有如此多的内存,以至于内存几乎永远不会用完;如果是,通常表示应用程序中有bug。因此,尝试处理内存不足的错误很少有意义;这造成了太多的复杂性,而得到的好处却太少。
更好的方法是定义一个新的方法ckalloc,它调用malloc,检查结果,如果内存耗尽,则用错误消息中止应用程序。应用程序从不直接调用malloc;它总是调用ckalloc。
在较新的语言(如c++和Java)中,如果内存耗尽,新的操作符会抛出异常。捕获这个异常没有多大意义,因为异常处理程序很可能也会尝试分配内存,这也会失败。动态分配内存是任何现代应用程序的基本元素,如果内存耗尽,应用程序继续运行是没有意义的;一旦检测到错误,最好立即崩溃。
还有许多其他的错误示例,崩溃应用程序是有意义的。对于大多数程序,如果在读取或写入打开的文件时发生I/O错误(例如磁盘硬错误),或者无法打开网络套接字,应用程序无法进行太多的恢复,因此使用明确的错误消息中止是一种明智的方法。这些错误并不常见,因此不太可能影响应用程序的整体可用性。如果应用程序遇到内部错误(如不一致的数据结构),也可以使用错误消息中止。这样的条件可能表明程序中存在bug。
崩溃是否可以接受取决于应用程序。对于复制的存储系统,由于I/O错误而中止是不合适的。相反,系统必须使用复制的数据来恢复丢失的任何信息。恢复机制将为程序增加相当大的复杂性,但是恢复丢失的数据是系统向用户提供的价值的重要组成部分。
10.9 设计不存在的特殊情况
定义错误使其不存在是有意义的,同样,定义其他特殊情况使其不存在也是有意义的。特殊情况会导致代码中充斥着if语句,这使得代码难以理解并导致bug。因此,应尽可能消除特殊情况。实现这一点的最佳方法是,以一种无需任何额外代码就能自动处理特殊情况的方式来设计正常情况。
在第6章描述的文本编辑器项目中,学生必须实现一种选择文本和复制或删除选择的机制。大多数学生在他们的选择实现中引入了一个状态变量来表示选择是否存在。他们之所以选择这种方法,可能是因为有时在屏幕上看不到选择,所以在实现中表示这种概念似乎是很自然的。然而,这种方法导致了大量的检查来检测“无选择”条件,并对其进行特殊处理。
通过消除“没有选择”的特殊情况,可以简化选择处理代码,使选择始终存在。当在屏幕上没有可见的选择时,可以用一个空的选择在内部表示它,它的起始位置和结束位置是相同的。使用这种方法,可以编写选择管理代码,而不需要检查“没有选择”。复制选择时,如果选择为空,则将在新位置插入0字节(如果实现正确,则不需要作为特殊情况检查0字节)。类似地,应该可以设计用于删除选择的代码,以便在不进行任何特殊情况检查的情况下处理空的情况。考虑在单行上进行选择。要删除所选内容,请提取所选内容之前的行部分,并将其与所选内容之后的行部分连接起来,以形成新行。如果选择为空,则此方法将重新生成原始行。
这个例子也说明了第7章中“不同的层,不同的抽象”的思想。“无选择”的概念对于用户如何考虑应用程序的接口是有意义的,但这并不意味着它必须在应用程序内部显式地表示。有一个总是存在的选择,但有时是空的,因此是不可见的,结果是一个更简单的实现。
10.10 做过了头
定义异常或在模块内部屏蔽异常,只有在模块外部不需要异常信息时才有意义。本章中的示例也是如此,比如cl unset命令和Java子字符串方法;在调用者关心由异常检测到的特殊情况的罕见情况下,可以通过其他方式获取此信息。
然而,这种想法可能会走得太远。在一个用于网络通信的模块中,一个学生团队屏蔽了所有的网络异常:如果发生了网络错误,模块捕获它,丢弃它,然后继续处理,就好像没有问题一样。这意味着使用该模块的应用程序无法查明消息是否丢失或对等服务器是否故障;没有这些信息,就不可能构建健壮的应用程序。在这种情况下,即使异常增加了模块接口的复杂性,模块也必须公开异常。
与软件设计中的许多其他领域一样,对于例外,您必须确定什么是重要的,什么是不重要的。不重要的事情应该隐藏起来,越多越好。但当某件事很重要时,它必须被曝光。
10.11 结论
任何形式的特殊情况都会使代码更难理解,并增加bug的可能性。 本章重点讨论异常,它是特殊情况代码最重要的来源之一,并讨论了如何减少必须处理异常的地方。最好的方法是重新定义语义来消除错误条件。对于无法定义的异常,您应该寻找机会在较低的层次上屏蔽它们,这样它们的影响就有限了,或者将几个特殊情况处理程序聚合到一个更通用的处理程序中。总之,这些技术可以对整个系统的复杂性产生重大影响。