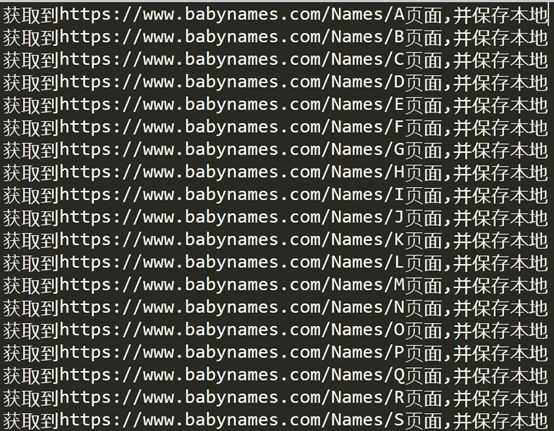
一.爬取目标
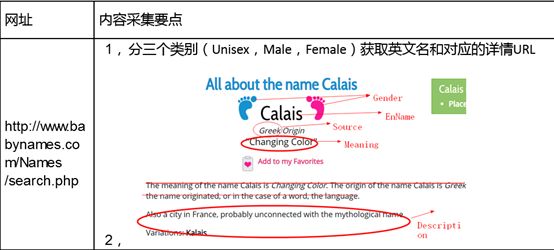
网址:http://www.babynames.com/Names/search.php
任务:分三个类别(Unisex,Male,Female)获取英文名的详情信息(Gender,EnName,Souce,Meaning,Description及详情URL)
二.爬取思路
1.首先在主页获取A-Z的html并保存到本地
2.然后创建三个文件夹,把Unisex,Male,Female的婴儿名区分开
3.再获取每个英文名的详情url
4.获取信息详情
5.根据性别不同存到不同的文件里
三. 运用的技术:
1:requests 模块请求,加headers
2:re 正则模块 基本只是用了简单的 .*?
3:bs4 中的BeautifulSoup 运用了其中的类选择器
4:lxml 中的 etree方法
5:os 模块中的 判断文件是否存在方法
6:csv 模块的存入和读取
四.代码
import requests import re from bs4 import BeautifulSoup from lxml import etree import csv import os """ 思路: 第一步 先获取A-Z 的链接 并将html文件保存到html文件夹中, 第二步 获取各个页面name的详情页链接,并请求,再去get_info中依次解析 第三步 在详情页进行分析,提取数据 注 代码运行 中间有一个warning 警告 并无妨 运用的技术: 1:requests 模块请求,加headers 2:re 正则模块 基本只是用了简单的 .*? 3:bs4 中的BeautifulSoup 运用了其中的类选择器 4:lxml 中的 etree方法 5:os 模块中的 判断文件是否存在方法 6:csv 模块的存入和读取 """ # 头部 headers = { "User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36"} #获取 A-Z列表 并保存下来 def get_liebiao(): url = "https://www.babynames.com/Names/A" # 请求 response1 = requests.get(url=url, headers=headers).content.decode("utf-8") # 写入 with open('html/babynames.html', "w", encoding="utf-8") as f: f.write(response1) # 解析 用的bs4 soup = BeautifulSoup(open("html/babynames.html"), "lxml",exclude_encodings="utf-8") # print(soup.prettify()) #打印这个页面 # 通过标签和类属性查找到A-Z所对应的 ul 框 ul = soup.find_all("ul", class_="browsebyletter")[0] # 通过正则表达式解析出里面所对应的全部li 标签 就是想要的A-Z.... li_pattern = re.compile(r'.*? ') li_list = li_pattern.findall(str(ul)) # 此时获取到的是每个英文首字母对应的链接列表,但是他不是全的,所以需要拼接 A_Z_list = [] for li in li_list: wenjianming = li.replace('/Names/','')+".html" A_Z_list.append(wenjianming) url = 'https://www.babynames.com' + li # 请求A-Z分类的详情页 response2 = requests.get(url = url, headers=headers).content.decode("utf-8") # 保存对应格式的html文件 with open('html/{}'.format(wenjianming), "w", encoding="utf-8") as f: f.write(response2) print("获取到{}页面,并保存本地".format(url)) return A_Z_list def get_info(wenjianming): print("{},开始解析".format(wenjianming)) #判断文件是否存在 分三个文件存储 if not os.path.exists('2017111030453赵金辉_Unisex.csv'): # 如果不存在 先写入2017111030453赵金辉_Unisex.csv with open("2017111030453赵金辉_Unisex.csv", "a",encoding="utf-8") as csvfile: writer = csv.writer(csvfile) # 先写入2017111030453赵金辉_Unisex.csv writer.writerow(["EnName", "Gender", "Source","Meaning",'url_info','Description']) print("文件不存在,同时创建新的文件") if not os.path.exists('2017111030453赵金辉_Male.csv'): # 如果不存在 2017111030453赵金辉_Male.csv with open("201711501234张三_Male.csv", "a",encoding="utf-8") as csvfile: writer = csv.writer(csvfile) # 先写入201711501234张三_Male.csv writer.writerow(["EnName", "Gender", "Source","Meaning",'url_info','Description']) print("文件不存在,同时创建新的文件") if not os.path.exists('2017111030453赵金辉_Female.csv'): # 如果不存在 先写入2017111030453赵金辉_Female.csv with open("2017111030453赵金辉_Female.csv", "a",encoding="utf-8") as csvfile: writer = csv.writer(csvfile) # 先写入2017111030453赵金辉_Female.csv writer.writerow(["EnName", "Gender", "Source","Meaning",'url_info','Description']) print("文件不存在,同时创建新的文件") soup = BeautifulSoup(open("html/{}".format(wenjianming)), "lxml") div_info = soup.find_all("div", class_="namesindex")[0] li_info_pattern = re.compile(r'.*? ') li_info_list = li_info_pattern.findall(str(div_info)) for li_info in li_info_list: data_list = [] url_info = 'https://www.babynames.com' + li_info #请求详情页 response3 = requests.get(url=url_info,headers=headers).content.decode("utf-8") tree = etree.HTML(response3) soup = BeautifulSoup(response3, "html") ###### EnName EnName = soup.find_all("h1", class_="baby-name")[0] #定义正则去匹配baby-name pattern = re.compile('(.*?)
') EnName = pattern.findall(str(EnName))[0] ###### Gender Gender = soup.find_all("a", class_="logopink") #此处匹配分三种情况 因为分为男女 还有中性的 if Gender : pattern = re.compile('(.*?)') Gender = pattern.findall(str(Gender[0]))[0] elif soup.find_all("a", class_="logoblue"): Gender = soup.find_all("a", class_="logoblue") pattern = re.compile('(.*?)') Gender = pattern.findall(str(Gender[0]))[0] else: Gender = soup.find_all("a", class_="logogreen") pattern = re.compile('(.*?)') Gender = pattern.findall(str(Gender[0]))[0] Source = tree.xpath('//div[@class="name-meaning"]/a/text()')[0] Meaning = tree.xpath('//div[@class="name-meaning"]/strong/text()')[0] Description = tree.xpath('//div[@class="nameitem"]/p//text()') Description = "".join(Description).replace('\n','').replace("\t",'').replace('"',"") # 存入csv文件 data_list_info = [] data_list_info.append(EnName) data_list_info.append(Gender) data_list_info.append(Source) data_list_info.append(Meaning) data_list_info.append(url_info) data_list_info.append(Description) data_list.append(data_list_info) print(Gender) if Gender=="Unisex": #每次读取到一个 name 就存进去 with open("2017111030453赵金辉_Unisex.csv", "a",encoding="utf-8") as csvfile: writer = csv.writer(csvfile) # 写入多行用writerows writer.writerows(data_list) print("{},保存完毕!!!".format(EnName)) elif Gender=="Male": #每次读取到一个 name 就存进去 with open("2017111030453赵金辉_Male.csv", "a",encoding="utf-8") as csvfile: writer = csv.writer(csvfile) # 写入多行用writerows writer.writerows(data_list) print("{},保存完毕!!!".format(EnName)) elif Gender=="Female": #每次读取到一个 name 就存进去 with open("2017111030453赵金辉_Female.csv", "a",encoding="utf-8") as csvfile: writer = csv.writer(csvfile) # 写入多行用writerows writer.writerows(data_list) print("{},保存完毕!!!".format(EnName)) print("{},解析完毕".format(wenjianming)) if __name__ == '__main__': A_Z_list = get_liebiao() #获取到每个 文件名 传递给下面的函数 for wenjianming in A_Z_list: try: get_info(wenjianming) except Exception as e: print(e)
五.调试过程遇到的问题
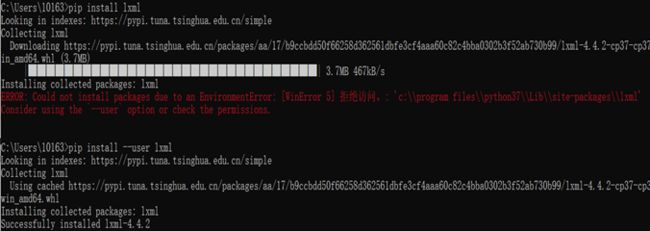
(1)No module named 'lxml',用pip install lxml无法下载
解决方案: 换成pip install --user lxml
(2)爬取个人信息性别的时候一直提示错误
原因:每个个人信息性别的属性是不一样的


所以这个时候需要一个判断语句来获取性别
Gender = soup.find_all("a", class_="logopink") #此处匹配分三种情况 因为分为男女 还有中性的 if Gender : pattern = re.compile('(.*?)') Gender = pattern.findall(str(Gender[0]))[0] elif soup.find_all("a", class_="logoblue"): Gender = soup.find_all("a", class_="logoblue") pattern = re.compile('(.*?)') Gender = pattern.findall(str(Gender[0]))[0] else: Gender = soup.find_all("a", class_="logogreen") pattern = re.compile('(.*?)') Gender = pattern.findall(str(Gender[0]))[0]
六.运行结果及csv文件