一、引言
Codis是一个分布式 Redis 解决方案,可以管理数量巨大的Redis节点。个推作为专业的第三方推送服务商,多年来专注于为开发者提供高效稳定的消息推送服务。每天通过个推平台下发的消息数量可达百亿级别。基于个推推送业务对数据量、并发量以及速度的要求非常高,实践发现,单个Redis节点性能容易出现瓶颈,综合考虑各方面因素后,我们选择了Codis来更好地管理和使用Redis。
二、选择Codis的原因
随着公司业务规模的快速增长,我们对数据量的存储需求也越来越大,实践表明,在单个Redis的节点实例下,高并发、海量的存储数据很容易使内存出现暴涨。
此外,每一个Redis的节点,其内存也是受限的,主要有以下两个原因:
一是内存过大,在进行数据同步时,全量同步的方式会导致时间过长,从而增加同步失败的风险;
二是越来越多的redis节点将导致后期巨大的维护成本。
因此,我们对Twemproxy、Codis和Redis Cluster 三种主流redis节点管理的解决方案进行了深入调研。
推特开源的Twemproxy最大的缺点是无法平滑的扩缩容。而Redis Cluster要求客户端必须支持cluster协议,使用Redis Cluster需要升级客户端,这对很多存量业务是很大的成本。此外,Redis Cluster的p2p方式增加了通信成本,且难以获知集群的当前状态,这无疑增加了运维的工作难度。
而豌豆荚开源的Codis不仅可以解决Twemproxy扩缩容的问题,而且兼容了Twemproxy,且在Redis Cluster(Redis官方集群方案)漏洞频出的时候率先成熟稳定下来,所以最后我们使用了Codis这套集群解决方案来管理数量巨大的redis节点。
目前个推在推送业务上综合使用Redis和Codis,小业务线使用Redis,数据量大、节点个数众多的业务线使用Codis。
我们要清晰地理解Codis内部是如何工作的,这样才能更好地保证Codis集群的稳定运行。下面我们将从Codis源码的角度来分析Codis的Dashboard和Proxy是如何工作的。
三、Codis介绍
Codis是一个代理中间件,用GO语言开发而成。Codis 在系统的位置如下图所示 :
Codis是一个分布式Redis解决方案,对于上层应用来说,连接Codis Proxy和连接原生的Redis Server没有明显的区别,有部分命令不支持;
Codis底层会处理请求的转发、不停机的数据迁移等工作,对于前面的客户端来说,Codis是透明的,可以简单地认为客户端(client)连接的是一个内存无限大的Redis服务。
Codis分为四个部分,分别是:
Codis Proxy (codis-proxy)
Codis Dashboard
Codis Redis (codis-server)
ZooKeeper/Etcd
Codis架构 
四、Dashboard的内部工作原理
Dashboard介绍
Dashboard是Codis的集群管理工具,所有对集群的操作包括proxy和server的添加、删除、数据迁移等都必须通过dashboard来完成。Dashboard的启动过程是对一些必要的数据结构以及对集群的操作的初始化。
Dashboard启动过程
Dashboard启动过程,主要分为New()和Start()两步。
New()阶段
⭕ 启动时,首先读取配置文件,填充config信息。coordinator的值如果是"zookeeper"或者是"etcd",则创建一个zk或者etcd的客户端。根据config创建一个Topom{}对象。Topom{}十分重要,该对象里面存储了集群中某一时刻所有的节点信息(slot,group,server等),而New()方法会给Topom{}对象赋值。
⭕ 随后启动18080端口,监听、处理对应的api请求。
⭕ 最后启动一个后台线程,每隔一分钟清理pool中无效client。
下图是dashboard在New()时内存中对应的数据结构。
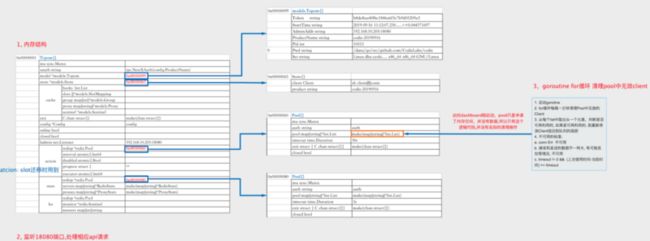
Start()阶段
⭕ Start()阶段,将内存中model.Topom{}写入zk,路径是/codis3/codis-demo/topom。
⭕ 设置topom.online=true。
⭕ 随后通过Topom.store从zk中重新获取最新的slotMapping、group、proxy等数据填充到topom.cache中(topom.cache,这个缓存结构,如果为空就通过store从zk中取出slotMapping、proxy、group等信息并填充cache。不是只有第一次启动的时候cache会为空,如果集群中的元素(server、slot等等)发生变化,都会调用dirtyCache,将cache中的信息置为nil,这样下一次就会通过Topom.store从zk中重新获取最新的数据填充。)
⭕ 最后启动4个goroutine for循环来处理相应的动作 。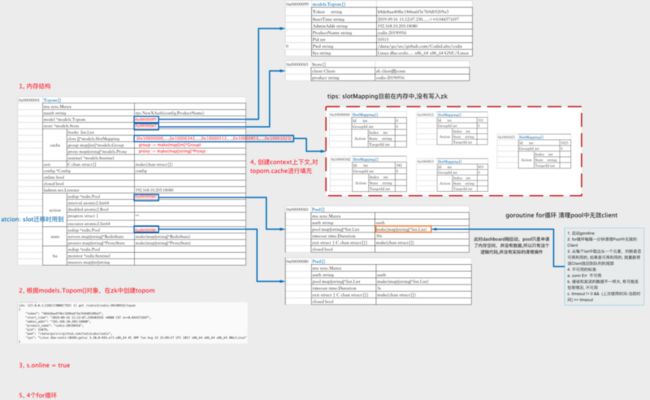
创建group过程
创建分组的过程很简单。
⭕ 首先,我们通过Topom.store从zk中重新拉取最新的slotMapping、group、proxy等数据填充到topom.cache中。
⭕ 然后根据内存中的最新数据来做校验:校验group的id是否已存在以及该id是否在1~9999这个范围内。
⭕ 接着在内存中创建group{}对象,调用zkClient创建路径/codis3/codis-demo/group/group-0001。
初始,这个group下面是空的。
{
"id": 1,
"servers": [],
"promoting": {},
"out_of_sync": false}
添加codis server
⭕接下来,向group中添加codis server。Dashboard首先会去连接后端codis server,判断节点是否正常。
⭕ 接着在codis server上执行slotsinfo命令,如果命令执行失败则会导致cordis server添加进程的终结。
⭕ 之后,通过Topom.store从zk中重新拉取最新的slotMapping、group、proxy等数据填充到topom.cache中,根据内存中的最新数据来做校验,判断当前group是否在做主从切换,如果是,则退出;然后检查group server在zk中是否已经存在。
⭕ 最后,创建一个groupServer{}对象,写入zk。
当codis server添加成功后,就像我们上面说的,Topom{}在Start时,有4个goroutine for循环,其中RefreshRedisStats()就可以将codis server的连接放进topom.stats.redisp.pool中

tips
⭕ Topom{}在Start时,有4个goroutine for循环,其中RefreshRedisStats执行过程中会将codis server的连接放进topom.stats.redisp.pool中;
⭕ RefreshRedisStats()每秒执行一次,里面的逻辑是从topom.cache中获取所有的codis server,然后根据codis server的addr 去topom.stats.redisp.Pool.pool 里面获取client。如果能取到,则执行info命令;如果不能取到,则新建一个client,放进pool中,然后再使用client执行info命令,并将info命令执行的结果放进topom.stats.servers中。
Codis Server主从同步
当一个group添加完成2个节点后,要点击主从同步按钮,将第二个节点变成第一个的slave节点。
⭕ 首先,第一步还是刷新topom.cache。我们通过Topom.store从zk中重新获取最新的slotMapping、group、proxy等数据并把它们填充到topom.cache中。
⭕然后根据最新的数据进行判断:group.Promoting.State != models.ActionNothing,说明当前group的Promoting不为空,即 group里面的两个cordis server在做主从切换,主从同步失败;
group.Servers[index].Action.State == models.ActionPending,说明当前作为salve角色的节点,其状态为pending,主从同步失败;
⭕ 判断通过后,获取所有codis server状态为ActionPending的最大的action.index的值+1,赋值给当前的codis server,然后设置当前作为slave角色的节点的状态为:g.Servers[index].Action.State = models.ActionPending。将这些信息写进zk。
⭕ Topom{}在Start时,有4个goroutine for循环,其中一个用于具体处理主从同步问题。
⭕ 页面上点击主从同步按钮后,内存中对应的数据结构会发生相应的变化: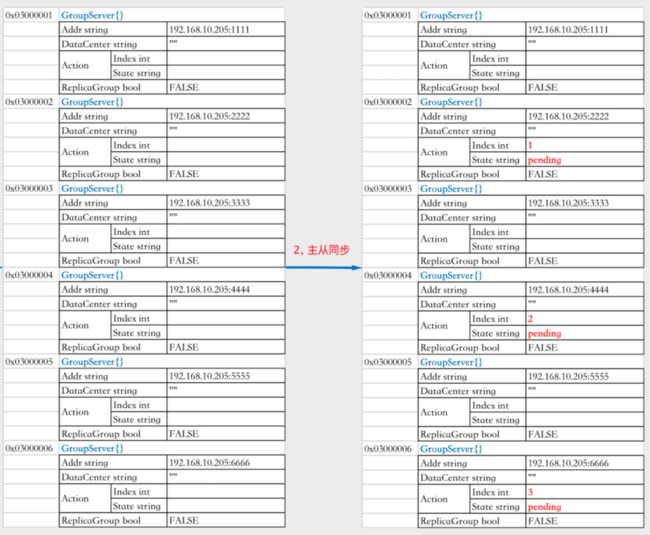
⭕ 写进zk中的group信息:

tips
Topom{}在Start时,有4个goroutine for循环,其中一个便用于具体来处理主从同步。具体怎么做呢?
首先,通过Topom.store从zk中重新获取最新的slotMapping、group、proxy等数据填充到topom.cache中,待得到最新的cache数据后,获取需要做主从同步的group server,修改group.Servers[index].Action.State == models.ActionSyncing,写入zk中。
其次,dashboard连接到作为salve角色的节点上,开启一个redis事务,执行主从同步命令:
c.Send(“MULTI”) —> 开启事务
c.Send(“config”, “set”, “masterauth”, c.Auth)
c.Send(“slaveof”, host, port)
c.Send(“config”, “rewrite")
c.Send(“client”, “kill”, “type”, “normal")
c.Do(“exec”) —> 事物执行
⭕ 主从同步命令执行完成后,修改group.Servers[index].Action.State == “synced”并将其写入zk中。至此,整个主从同步过程已经全部完成。
codis server在做主从同步的过程中,从开始到完成一共会经历5种状态:
""(ActionNothing) --> 新添加的codis,没有主从关系的时候,状态为空
pending(ActionPending) --> 页面点击主从同步之后写入zk中
syncing(ActionSyncing) --> 后台goroutine for循环处理主从同步时,写入zk的中间状态
synced --> goroutine for循环处理主从同步成功后,写入zk中的状态
synced_failed --> goroutine for循环处理主从同步失败后,写入zk中的状态
slot分配
上文给Codis集群添加了codis server,做了主从同步,接下来我们把1024个slot分配给每个codis server。Codis给使用者提供了多种方式,它可以将指定序号的slot移到某个指定group,也可以将某个group中的多个slot移动到另一个group。不过,最方便的方式是自动rebalance。
通过Topom.store我们首先从zk中重新获取最新的slotMapping、group、proxy等数据填充到topom.cache中,再根据cache中最新的slotMapping和group信息,生成slots分配计划 plans = {0:1, 1:1, … , 342:3, …, 512:2, …, 853:2, …, 1023:3},其中key 为 slot id, value 为 group id。接着,我们按照slots分配计划,更新slotMapping信息:Action.State = ActionPending和Action.TargetId = slot分配到的目标group id,并将更新的信息写回zk中。
Topom{}在Start时,有4个goroutine for循环,其中一个用于处理slot分配。
SlotMapping:
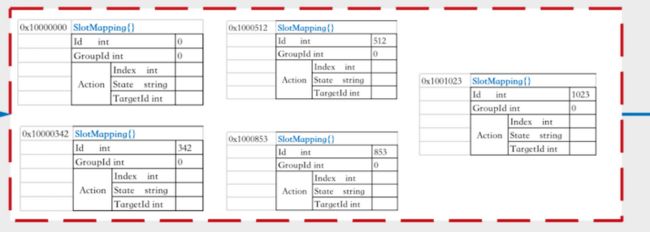
tips
● Topom{}在Start时,有4个goroutine for循环,其中ProcessSlotAction执行过程中就将codis server的连接放进topom.action.redisp.pool中了。
● ProcessSlotAction()每秒执行一次,待里面的一系列处理逻辑执行之后,它会从topom{}.action.redisp.Pool.pool中获取client,随后在redis上执行SLOTSMGRTTAGSLOT命令。如果client能取到,则dashboard会在redis上执行迁移命令;如果不能取到,则新建一个client,放进pool中,然后再使用client执行迁移命令。
SlotMapping中action对应的7种状态: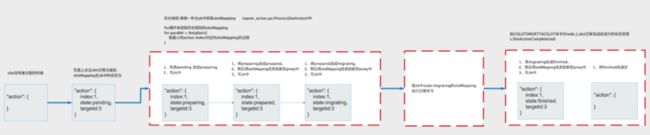
我们知道Codis是由ZooKeeper来管理的,当Codis的Codis Dashbord改变槽位信息时,其他的Codis Proxy节点会监听到ZooKeeper的槽位变化,并及时同步槽位信息。

总结一下,启动dashboard过程中,需要连接zk、创建Topom这个struct,并通过18080这个端口与集群进行交互,然后将该端口收到的信息进行转发。此外,还需要启动四个goroutine、刷新集群中的redis和proxy的状态,以及处理slot和同步操作。
五、Proxy的内部工作原理
proxy启动过程
proxy启动过程,主要分为New()、Online()、reinitProxy()和接收客户端请求()等4个环节。
New()阶段
⭕ 首先,在内存中新建一个Proxy{}结构体对象,并进行各种赋值。
⭕ 其次,启动11080端口和19000端口。
⭕ 然后启动3个goroutine后台线程,处理对应的操作:
●Proxy启动一个goroutine后台线程,并对11080端口的请求进行处理;
●Proxy启动一个goroutine后台线程,并对19000端口的请求进行处理;
●Proxy启动一个goroutine后台线程,通过ping codis server对后端bc予以维护 。

Online()阶段
⭕ 首先对model.Proxy{}的id进行赋值,Id = ctx.maxProxyId() + 1。若添加第一个proxy时, ctx.maxProxyId() = 0,则第一个proxy的id 为 0 + 1。
⭕ 其次,在zk中创建proxy目录。
⭕之后,对proxy内存数据进行刷新reinitProxy(ctx, p, c)。
⭕ 第四,设置如下代码:
online = true
proxy.online = true
router.online = true
jodis.online = true
⭕ 第五,zk中创建jodis目录。

reinitProxy()
⭕Dashboard从zk[m1] 中重新获取最新的slotMapping、group、proxy等数据填充到topom.cache中。根据cache中的slotMapping和group数据,Proxy可以得到model.Slot{},其里面包含了每个slot对应后端的ip与port。建立每个codis server的连接,然后将连接放进router中。
⭕ Redis请求是由sharedBackendConn中取出的一个BackendConn进行处理的。Proxy.Router中存储了集群中所有sharedBackendConnPool和slot的对应关系,用于将redis的请求转发给相应的slot进行处理,而Router里面的sharedBackendConnPool和slot则是通过reinitProxy()来保持最新的值。
总结一下proxy启动过程中的流程。首先读取配置文件,获取Config对象。其次,根据Config新建Proxy,并填充Proxy的各个属性。这里面比较重要的是填充models.Proxy(详细信息可以在zk中查看),以及与zk连接、注册相关路径。
随后,启动goroutine监听11080端口的codis集群发过来的请求并进行转发,以及监听发到19000端口的redis请求并进行相关处理。紧接着,刷新zk中数据到内存中,根据models.SlotMapping和group在Proxy.router中创建1024个models.Slot。此过程中Router为每个Slot都分配了对应的backendConn,用于将redis请求转发给相应的slot进行处理。
六、Codis内部原理补充说明
Codis中key的分配算法是先把key进行CRC32,得到一个32位的数字,然后再hash%1024后得到一个余数。这个值就是这个key对应着的槽,这槽后面对应着的就是redis的实例。 
slot共有七种状态:nothing(用空字符串表示)、pending、preparing、prepared、migrating、finished。
如何保证slots在迁移过程中不影响客户端的业务?
⭕ client端把命令发送到proxy, proxy会算出key对应哪个slot,比如30,然后去proxy的router里拿到Slot{},内含backend.bc和migrate.bc。如果migrate.bc有值,说明slot目前在做迁移操作,系统会取出migrate.bc.conn(后端codis-server连接),并在codis server上强制将这个key迁移到目标group,随后取出backend.bc.conn,访问对应的后端codis server,并进行相应操作。
七、Codis的不足与个推使用上的改进
Codis的不足
⭕ 欠缺安全考虑,codis fe页面没有登录验证功能;
⭕ 缺乏自带的多租户方案;
⭕ 缺乏集群缩容方案。
个推使用上的改进
⭕ 采用squid代理的方式来简单限制fe页面的访问,后期基于fe进行二次开发来控制登录;
⭕ 小业务通过在key前缀增加业务标识,复用相同集群;大业务使用独立集群,独立机器;
⭕ 采用手动迁移数据、腾空节点、下线节点的方法来缩容。
八、全文总结
Codis作为个推消息推送一项重要的基础服务,性能的好坏至关重要。个推将Redis节点迁移到Codis后,有效地解决了扩充容量和运维管理的难题。未来,个推还将继续关注Codis,与大家共同探讨如何在生产环境中更好地对其进行使用。
