在elasticsearch中es支持对存储文档进行复杂的统计.简称聚合。
ES中的聚合被分为两大类。
1、Metrics, Metrics 是简单的对过滤出来的数据集进行avg,max等操作,是一个单一的数值。
2、ucket, Bucket 你则可以理解为将过滤出来的数据集按条件分成多个小数据集,然后Metrics会分别作用在这些小数据集上。
聚合在ELK里面是一个非常重要的概念,虽然我们在ELK stack里面用于过多的去了解es的实现过程,但是简单的了解es的查询过程,可以有效的帮助我们快速的入门Kibana,通过kibana鼠标点击的方式生成聚合数据。
1、git先下载数据导入:
git [email protected]:xiaoluoge11/longguo-devops.git
执行脚本:
[root@controller longguo-devops]# ./car.sh
#备注:我们会建立一个也许对汽车交易商有所用处的聚合。数据是关于汽车交易的:汽车型号,制造商,销售价格,销售时间以及一些其他的相关数据
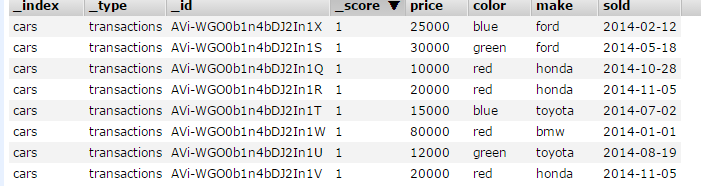
Bucket:
1、按时间统计(可以是一个时间区间的柱形图date_histogram:kibana这样展示):
[root@controller .ssh]# curl -XGET '192.168.63.235:9200/cars/transactions/_search?pretty' -d '
{
"aggs" : {
"articles_over_time" : {
"date_histogram" : {
"field" : "sold",
"interval": "month" ##区间可以为:data.hour,munite,year等
}
}
}
}'
返回结果:
"aggregations" : {
"articles_over_time" : {
"buckets" : [
{
"key_as_string" : "2014-01-01T00:00:00.000Z",
"key" : 1388534400000,
"doc_count" : 1
},
{
"key_as_string" : "2014-02-01T00:00:00.000Z",
"key" : 1391212800000,
"doc_count" : 1
},
#####也可以这样指定:
"field" : "sold",
"interval" : "mount",
"format" : "yyyy-MM-dd" ###指定相应的时间格式
"offset": "+6h" ###区间间隔
####或者按照时间区间来查询:
"aggs": {
"range": {
"date_range": {
"field": "date",
"time_zone": "CET",
"ranges": [
{ "to": "2016-02-15/d" },
{ "from": "2016-02-15/d", "to" : "now/d" },
{ "from": "now/d" },
2、返回价格区间柱形图(Histogram Aggregation):
[root@controller .ssh]# curl -XGET '192.168.63.235:9200/cars/transactions/_search?pretty' -d '
{
"aggs" : {
"prices" : {
"histogram" : {
"field" : "price",
"interval" : 5000
}
}
}
}'
###Histogram做等间距划分,统计区间的price值,看他落在那个区间,数据间隔是5000:
返回结果:
"aggregations" : {
"prices" : {
"buckets" : [
{
"key" : 10000.0,
"doc_count" : 2
},
{
"key" : 15000.0,
"doc_count" : 1
},
3、查看每种颜色的销量:
[root@controller .ssh]# curl -XGET '192.168.63.235:9200/cars/transactions/_search?pretty' -d '
{
"aggs" : {
"genres" : {
"terms" : { "field" : "color" }
}
}
}'
###注意可能会报如下错:
"reason" : "Fielddata is disabled on text fields by default. Set fielddata=true on [color] in order to load fielddata in memory by uninverting the inverted index. Note that this can however use significant memory."
提示我们数据类型不对,我们修改一下mapping映射:
[root@controller .ssh]# curl -XPUT '192.168.63.235:9200/cars/_mapping/transactions' -d '
> {
> "properties": {
> "color": {
> "type": "text",
> "fielddata": true
> }
> }
> }'
{"acknowledged":true}
再查下就会看到统计分布的结果:
"buckets" : [
{
"key" : "red",
"doc_count" : 4
},
{
"key" : "blue",
"doc_count" : 2
},
{
"key" : "green",
"doc_count" : 2
}
4、添加一个指标(Metric):
[root@controller .ssh]# curl -XGET '192.168.63.235:9200/cars/transactions/_search?pretty' -d '
{
"aggs" : {
"genres" : {
"terms" : { "field" : "color" }
,
"aggs": {
"avg_price": {
"avg": {
"field": "price"
}
}
}
}
}
}'
####avg可以换成max,min,sum等。用stats就表示所有。
5、用stats找出Metric的所有值。
curl -XGET '192.168.63.235:9200/cars/transactions/_search?pretty' -d '
{
"aggs" : {
"genres" : {
"terms" : { "field" : "color" }
,
"aggs": {
"avg_price": {
"stats": {
"field": "price"
}
}
}
}
}
}'
####返回结果:
"buckets" : [
{
"key" : "red",
"doc_count" : 4,
"avg_price" : {
"count" : 4,
"min" : 10000.0,
"max" : 80000.0,
"avg" : 32500.0,
"sum" : 130000.0
}
}
本文内容出自:日志分析之 ELK stack 实战课程学习笔记