hadoop是处理大数据的得力帮手,它主要分为三种模式:
单机模式;
伪分布式模式;
完全分布式模式;
在这篇文章中,主要来看看在CentOS7中进行hadoop的单机和伪分布式的环境搭建。(在Ubuntu下安装也一样。)
因为自己设备的条件,就先在虚拟机里搭建伪分布式的环境来进行hadoop的学习。
以下的环境是需要java环境才能进行,我的电脑中的java是:

单机模式
先来看看单机模式,单机模式比较简单。
首先在官网下载hadoop,网站地址为:http://hadoop.apache.org/releases.html
我这里用的是hadoop2.6.5的版本。
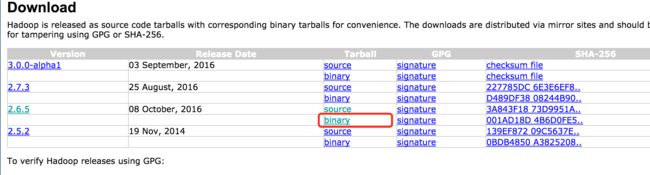
点击binary下载即可。
下载完毕后,将下载下来的包放在/usr/local目录下:

然后解压压缩包:
# 如果遇上权限不够,就加sudo,或用root用户进行
tar -xvf hadoop-2.6.5.tar.gz
# 将减压出来的hadoop-2.6.5改名为hadoop(改不改随便)
mv hadoop-2.6.5 hadoop
完成后我们就可以进入hadoop文件夹看看了:

这时候进入etc/hadoop目录,那个目录里面装的东西关于hadoop的一些配置文件,进去后可以看一看:
其中我们先来配置关于环境的东西:
vim hadoop-env.sh
可以看到里面的内容:
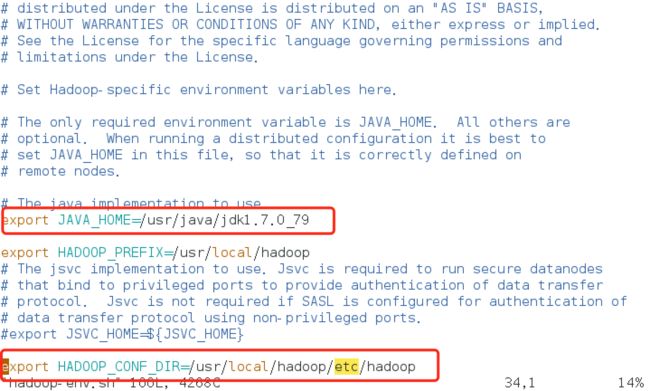
我们需要看的就是JAVA_HOME那个变量,如果不是我们系统中java的路径就把它改成java的路径。下面那个HADOOP_CONF_DIR也可以改为自己电脑hadoop文件夹中etc/hadoop那个路径。
然后在终端中source一下:
source hadoop-env.sh
接着进入前面的bin目录下看看
cd ../../bin

运行hadoop试试看:
./hadoop version

输出如上信息,就说明hadoop的单机模式成了。
再来运行个hadoop给的例子程序跑跑。
为了测试,先新建一个目录Input:
mkdir Input
在里面放上一个txt文件,随便写一些英文在里面吧,比如说我的乱写了几个:
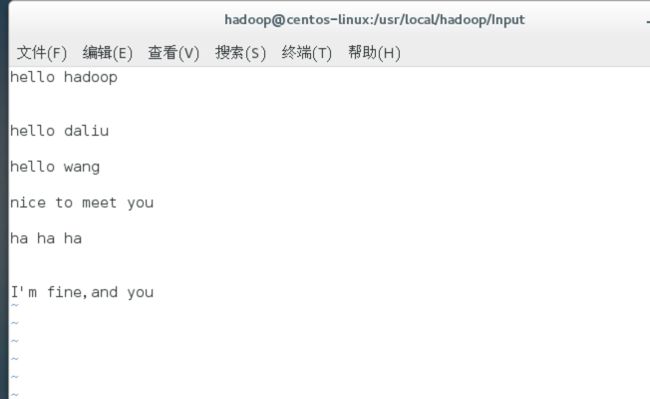
然后在shell中执行:
执行完毕后,到hadoop文件夹内,会看到出现了Output目录,打印出里面的东西来看看:

可以看到,英文单词的个数被统计了出来。
伪分布式模式
我们单机的环境中,比较常用的是伪分布式。那么接下来就来看看伪分布式的做法,其实也就是接着上面来。
要进行伪分布式,就是配置几个文件和改改环境变量。
上面说了,配置文件都在etc那个目录下,因此需要进入那个目录,然后修改里面的core-site.xml、hdfs-site.xml两个文件。
可以先看看官方文档上是怎么修改的:
http://hadoop.apache.org/docs/r2.6.5/hadoop-project-dist/hadoop-common/SingleCluster.html#Pseudo-Distributed_Operation
里面的Pseudo-Distributed Operation介绍了需要修改的文件:
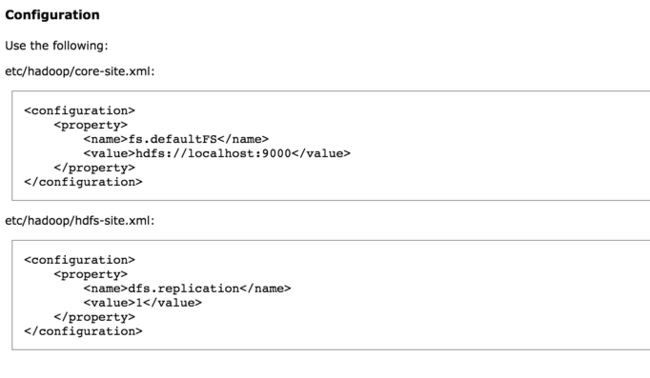
那么我们就安装它的这个配置,不过再稍微增加一些东西。先打开core-site.xml,配置如下:

这里比官方的多了一个配置,这样做可以把tmp目录指定在自己设置的位置,而tmp是用来存放零时文件,比例运行过程中的文件等。如果不指定,系统会利用linux自己的/tmp目录来存放,这样在重启后就不在了。
hdfs-site.xml的配置如下:

比官方多了两个东西,一个是namenode,一个是datanode。namenode和datanode文件夹默认是放在tmp里面的,这2个文件夹用来存储hdfs里的内容。 这里配置指定了那两个目录的位置。
然后在相应的目录中创建namenode和datanode的目录:
mkdir dfs
mkdir dfs/name
mkdir dfs/data
配置完成后,跟着官方走,下一步是设置无密码登陆的ssh。
如果没有安装ssh,那就用yum安装就是了。安装完毕后,生成密钥对:
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
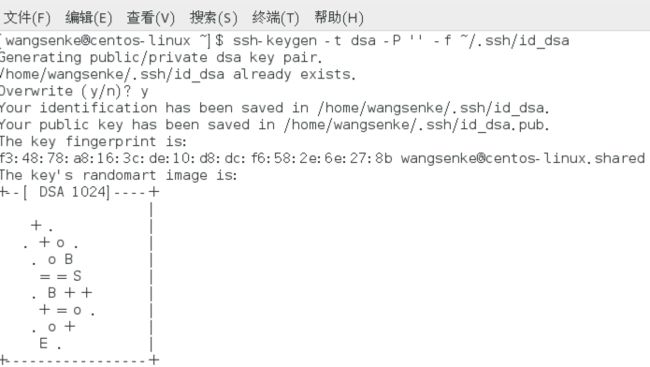
然后用cat命令追加公钥:
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
这就是一个读写过程。
然后就应该可以进行ssh无密码登录了:
ssh localhost
登录本机之后,可以开始正式开启hadoop了。首先我们可以把hdfs看成和普通新的硬盘一样,刚买来的新硬盘需要进行格式化,同样的,我们先进行hdfs的格式化:
bin/hdfs namenode -format
接下来我们就来开启hdfs文件系统吧:
sbin/start-dfs.sh
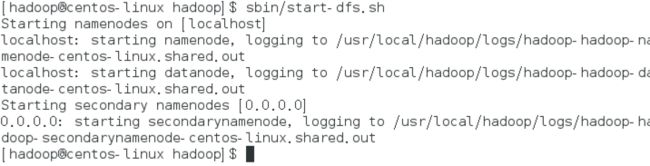
然后通过jps命令查看一下:

可以看到,服务启动了哦。
用网页查看就是以下状态,输入localhost:50070:
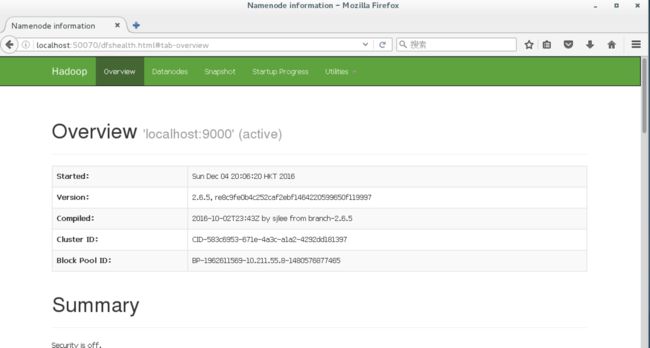
以上内容就完成了hdfs的伪分布式。本来官网后面还有yarn的配置,就放在介绍yarn的时候吧。这样子已经能够进行hdfs的一些编程操作了。
下一节介绍要进行hadoop开发的eclipse环境搭建。