心情不够振奋,学个新技术吧!
翻译来源:
https://www.youtube.com/watch?v=hBedCdzCoWM
发现了一个特逗儿的小伙儿,有一些5分钟系列的视频,介绍一些人工智能的技术,有兴趣的可以去他的youtube频道。
今天要讲的是自动驾驶车是怎样工作的,然后在一个模拟的环境中应用我们自己的自动驾驶车。
自动驾驶车再也不是只能在科幻小说里面才能看到的东西了,很多大的公司比如说谷歌,优步,丰田和福特都在研发甚至上路了。
在不久的将来,我们将会看到有越来越多的消费者可以购买自动驾驶车。
自动驾驶车是怎样工作的呢?

当我们人类坐在车上的时候,我们需要观察周围的环境,同时操作我们的车,作出决定该向哪个方向转动方向盘。

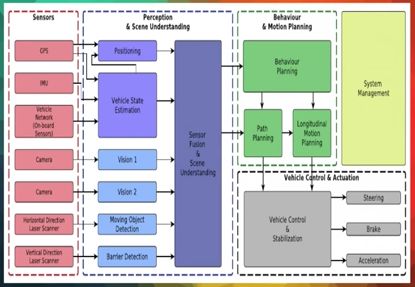
这个可以被建模成一个机器学习问题,SLAM,simutaneous localization and mapping,这就是自动驾驶车要做的事情。
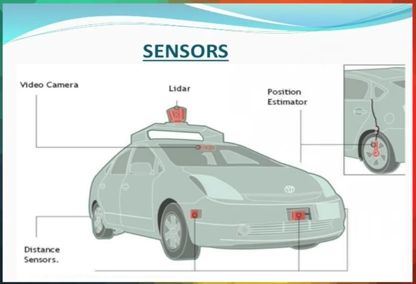
无人驾驶车,会装备GPS,一个惯性导航系统,一些传感器。然后用GPS传过来的地理数据来定位自己,用传感器传过来的数据来构造它所在环境的内部地图,

在自己构建的这个内部地图中找到自己的位置之后,就会寻找一个从此位置到目标地点的优化路径,并且避免任何一个障碍物。
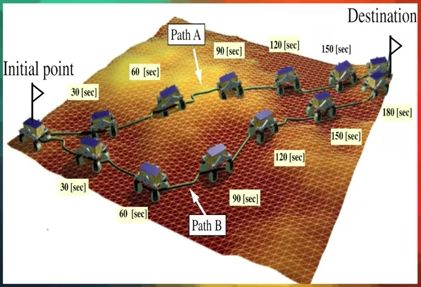
当它已经确定了这个最优路径之后,就会把它分解成一系列的电机命令,这些命令会被送到汽车的致动器。
但是在实际的开车的过程中有很多问题,不仅仅是躲避障碍物,还有不同的天气条件下如何控制速度,不同类型的道路,比如说弯路,还有遇到不同的道路标志时采取什么样的行动。
最近有一篇论文叫 Long term Planning for Short Term 。

文中介绍了一个规划的算法。这个算法可以使无人驾驶车在优化一个长期的目标时,做出一个即时的反应

一个应用场景实例就是在环岛时,当一个汽车想要进入这个环岛时,它需要做出一个是加速还是减速的决定,这个决定的长期效果就是是否成功进入环岛。

通常来讲,一个无人驾驶车的规划问题,是一个强化学习问题。一个汽车是通过很多次的尝试和犯错,不断的纠正错误,来强化它的驾驶能力的。
一个汽车观察到周围环境的一个状态 s,经过判断某个行为是好还是坏后采取行动 a,然后它会收到一个反馈,如果这个行为是对的就会奖励它,然后重复上面这个过程。
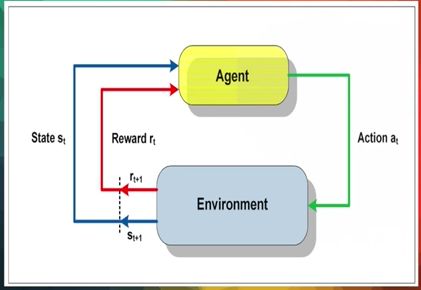
这个过程是想要最大化这个奖励,它依赖于将状态映射到行动的规则,这个函数被称作 Q,用这个函数来找到最优的规则。
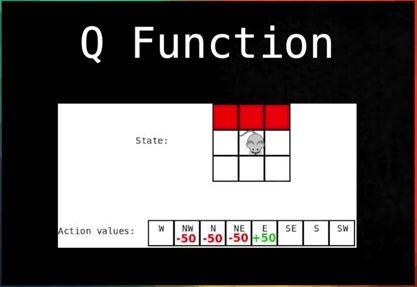

但是在实际的道路上,状况是非常复杂的,有很多车,而且这个状态是动态的,这就不仅需要要预测自己的车的行为,还要能够预测其他车辆的行为。
为了能够学习出这个函数,论文的作者们构建了一个深度神经网络。
向这个神经网络中投入的数据包括,可预测的部分-车的速度和不可预测的部分-其他车的速度,这样就同时学习这两个部分。
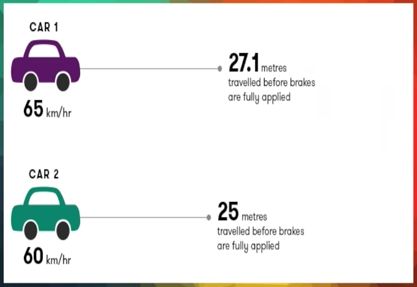
模型里只有两个特征,一个是 Adaptive Cruise Control,一个是 Merging Roundabouts。

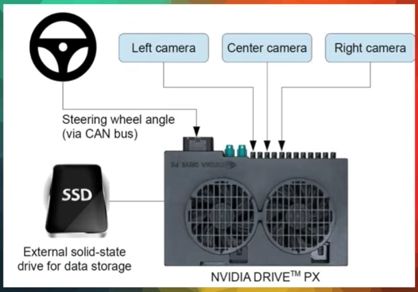
有一个术语叫 End to End Learning for Self-Driving Cars,三个月前Nvidia的一个团队发了一篇新的论文。他们在挡风玻璃上装了三个摄像头来获取数据,把这些数据投入到一个卷积神经网络中,然后自动学习特征。

用这个模型,并不需要把不同的场景明确的分解成不同的子问题。模型里的卷积神经网络,将把从输入数据看到的东西直接映射成转向命令。

它会先在一个提前录制的虚拟模拟环境中训练,然后再由一个司机去驾驶它。他们得到一个非常好的结果,但是这个作者觉得很难区分这个神经网络的特征提取部分和控制部分,也就很难去检验它们。
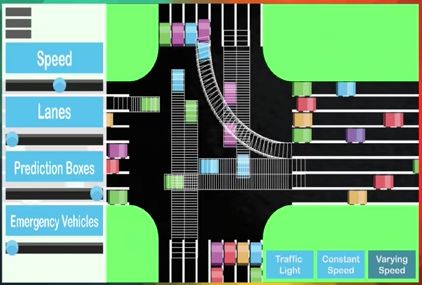
一个叫 George Hotz 在他的车库里构建了自己的无人驾驶车,只用了一对手机相机,成本只有1000美元。

接下来让我们训练一下自己的无人驾驶车
让它通过 Q Learning 来自动驾驶而不会碰到其它的障碍物。
篇幅有限,只贴上主要代码一部分,逻辑请看代码注释的汉语部分,完整repo请看文末资源列表。

from flat_game import carmunk
import numpy as np
import random
import csv
from nn import neural_net, LossHistory
import os.path
import timeit
NUM_INPUT = 3
GAMMA = 0.9 # Forgetting.
TUNING = False # If False, just use arbitrary, pre-selected params.
# 训练一个神经网络,有一些hyper parameters
def train_net(model, params):
filename = params_to_filename(params)
# 定义变量:观察数据
observe = 1000 # Number of frames to observe before training.
epsilon = 1
train_frames = 1000000 # Number of frames to play.
batchSize = params['batchSize']
buffer = params['buffer']
# 定义变量:位置
# Just stuff used below.
max_car_distance = 0
car_distance = 0
t = 0
data_collect = []
replay = [] # stores tuples of (S, A, R, S').
loss_log = []
# 创建一个新的游戏实例
# Create a new game instance.
game_state = carmunk.GameState()
# 得到这个实例的第一个状态
# Get initial state by doing nothing and getting the state.
_, state = game_state.frame_step((2))
# 用一个timer来追踪
# Let's time it.
start_time = timeit.default_timer()
# 当我们开始建立experience replay时
# Run the frames.
while t < train_frames:
t += 1
car_distance += 1
# 我们会更新位置变量,然后依据状态随机选择行为
# Choose an action.
if random.random() < epsilon or t < observe:
action = np.random.randint(0, 3) # random
else:
# 如果这个随机变量在我们的限制条件之外,我们会得到每个行为的Q值,
# 来帮我们找到最优的决策
# Get Q values for each action.
qval = model.predict(state, batch_size=1)
action = (np.argmax(qval)) # best
# 如果它是有效的,我们会得到一个reward
# Take action, observe new state and get our treat.
reward, new_state = game_state.frame_step(action)
# Experience replay storage.
replay.append((state, action, reward, new_state))
# 当它结束观察游戏和建立经验回放时,会开始训练采样记忆experience replaying,得到训练值
# If we're done observing, start training.
if t > observe:
# If we've stored enough in our buffer, pop the oldest.
if len(replay) > buffer:
replay.pop(0)
# Randomly sample our experience replay memory
minibatch = random.sample(replay, batchSize)
# Get training values.
X_train, y_train = process_minibatch(minibatch, model)
# 然后训练神经网络模型
# Train the model on this batch.
history = LossHistory()
model.fit(
X_train, y_train, batch_size=batchSize,
nb_epoch=1, verbose=0, callbacks=[history]
)
loss_log.append(history.losses)
# 然后更新状态
# Update the starting state with S'.
state = new_state
# Decrement epsilon over time.
if epsilon > 0.1 and t > observe:
epsilon -= (1/train_frames)
# 当car dies,
# We died, so update stuff.
if reward == -500:
# Log the car's distance at this T.
data_collect.append([t, car_distance])
# Update max.
if car_distance > max_car_distance:
max_car_distance = car_distance
# Time it.
tot_time = timeit.default_timer() - start_time
fps = car_distance / tot_time
# Output some stuff so we can watch.
print("Max: %d at %d\tepsilon %f\t(%d)\t%f fps" %
(max_car_distance, t, epsilon, car_distance, fps))
# 记录距离,重启
# Reset.
car_distance = 0
start_time = timeit.default_timer()
# 每25000 frames保存一下模型和weights
# Save the model every 25,000 frames.
if t % 25000 == 0:
model.save_weights('saved-models/' + filename + '-' +
str(t) + '.h5',
overwrite=True)
print("Saving model %s - %d" % (filename, t))
# Log results after we're done all frames.
log_results(filename, data_collect, loss_log)
下面是训练的结果,然后看一下在模拟环境中是如何work的,可以看到它可以通过强化学习和神经网络,不断地躲避障碍物:
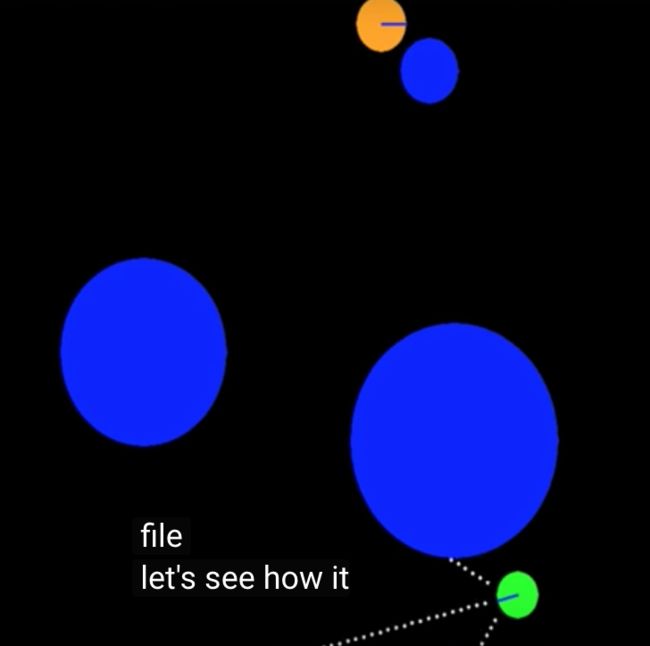
来,把你的小汽车放回宇宙吧

其他资源:
The code in the video is here:
https://github.com/llSourcell/Self-Dr...
Paper 1: Long term Planning for Short Term Prediction
[http://arxiv.org/pdf/1602.01580v1.pdf(http://arxiv.org/pdf/1602.01580v1.pdf)
Paper 2: End-to-End Learning for Self-Driving Cars
[https://arxiv.org/pdf/1604.07316v1.pdf(https://arxiv.org/pdf/1604.07316v1.pdf)
More on Reinforcement Learning:
http://www2.hawaii.edu/~chenx/ics699r...
https://www.quora.com/Artificial-Inte...
http://www2.econ.iastate.edu/tesfatsi...
我是 不会停的蜗牛 Alice
85后全职主妇
喜欢人工智能,行动派
创造力,思考力,学习力提升修炼进行中
欢迎您的喜欢,关注和评论!