概述
市场营销和客户管理的经验表明,开发一个新客户的成本远远大于维护一个老客户的成本,而一个老客户所能贡献的利润也远远大于一个新客户贡献的利润。经典的二八定律在日常的业务实践中时刻发挥着它的作用,20%的老客户带来80%的利润,而80%的新客户,其复购率和所贡献的利润却总是维持在较低的水平。
那么,在激烈的市场竞争和不断变化的市场需求面前,如何最大程度的降低客户的流失率,维护好老客户,挽留住新客户,以创造更大的利润,就成为摆在我们面前的问题。而要解决这个问题的前提,是我们必须要能够识别潜在的有流失倾向的用户,从而才能有的放矢的推出一些用户挽留的措施。
本文尝试使用商业活动中用户的历史行为数据,通过机器学习的手段,对用户的流失倾向做出预测,希望为客户管理给出一些帮助,同时探讨通过技术的手段对用户行为进行预测的可行性。
准备数据
对用户流失进行预测,这是个二分类问题,要么流失,要么不流失。如果使用有监督学习算法,那么需要事先对样本数据进行分类标记,考虑到用户数据有多年的积累,为了省去人工标记数据的麻烦,我们按照如下思路准备数据。
- 根据业务领域知识,定义一批可能影响用户流失的特征,这些特征包括用户基本信息和各类用户消费行为统计指标
- 采样一批一年前的用户,收集这些用户的特征数据
- 定义一条严格的规则,使用规则对同一批用户近一年的数据进行判断,得出用户是否流失的标签,我们使用这个标签代替人为标记的标签,认为它就是事实上的流失情况
- 合并特征数据和标签数据,得到一份已标记的数据集
以上步骤的大体思路是收集一年以前的用户数据,这些用户在最近一年有没有流失已经成为事实,使用这些事实对一年以前的用户进行打标签,从而得到综合了历史数据及其真实标签的数据集。
后面的工作中将把这个数据集切分为训练集和测试集,用训练集训练模型,用测试集验证和评估模型质量,在此基础上持续改进,得到一个能满足需求的模型,并使用模型对后面的用户行为进行预测。
import os
work_dir = 'D:/ml/cr-user-churn'
assert os.path.exists(work_dir), '工作目录不存在'
data_dir = os.path.join(work_dir, 'data')
assert os.path.exists(data_dir), '数据目录不存在'
model_dir = os.path.join(work_dir, 'model')
if not os.path.exists(model_dir):
os.mkdir(model_dir)
output_dir = os.path.join(work_dir, 'output')
if not os.path.exists(output_dir):
os.mkdir(output_dir)
os.chdir(work_dir)
import numpy as np
import pandas as pd
data_file_name = 'member_before_2017.csv'
data_file_path = os.path.join(data_dir, data_file_name)
df = pd.read_csv(data_file_path, low_memory=False)
df.head()
| 会员编号 | 会员性别 | 会员生日 | 首次入会日期 | 会员状态 | 会员年龄 | 婚姻状态 | 教育程度 | 接受信件 | 接受电话 | ... | 生日距离现在月份数(一年前) | 入会距离现在月份数(一年前) | 累计金额(一年前) | 是否流失 | 是否关注公众号 | 参加活动次数(一年前) | 停车次数(一年前) | 停车时长H(一年前) | 车辆数量 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | QY1-4157-49542 | 女 | 1990-07-27 | 2013-11-06 | 正常 | 28.0 | NaN | NaN | N | N | ... | 323.0 | 39.0 | 7793.0 | Y | N | NaN | 1.0 | 0.733333 | 1.0 |
| 1 | QY1-4169-46659 | 女 | 1972-05-13 | 2014-09-25 | 正常 | 46.0 | NaN | 小学 | N | N | ... | 544.0 | 28.0 | 106696.3 | N | Y | 5.0 | 11.0 | 43.900000 | 8.0 |
| 2 | QY1-4161-11780 | 男 | 1985-05-26 | 2012-09-08 | 正常 | 33.0 | NaN | NaN | N | N | ... | 386.0 | 53.0 | 24002.6 | Y | N | NaN | NaN | NaN | NaN |
| 3 | QY1-4196872436 | 男 | 1984-04-04 | 2016-12-30 | 正常 | 34.0 | NaN | NaN | N | N | ... | 399.0 | 1.0 | 2110.0 | Y | N | NaN | 1.0 | 1.083333 | 2.0 |
| 4 | QY1-4153-150631 | 女 | 1988-07-14 | 2013-04-02 | 正常 | 30.0 | NaN | NaN | N | N | ... | 347.0 | 46.0 | 165844.0 | N | Y | 1.0 | 38.0 | 81.283333 | 5.0 |
数据预处理
数据的清洗工作非常重要,没有高质量的输入数据,后面的工作无从谈起。
只选取对预测有价值的特征,无关特征或数据严重缺失的无效特征不处理
处理缺失值、异常值、重复分类、日期值。把缺失值和异常值填充为默认值,把重复分类进行合并处理,如合并“沈阳”和“沈阳市”等,把日期值处理为距离今天的天数或月数等
# 查看哪些字段存在缺失值
# print(df.isnull().any())
df.rename(columns={'会员性别':'性别'}, inplace = True)
df.rename(columns={'会员年龄':'年龄'}, inplace = True)
df.rename(columns={'省/(直辖)市':'省份'}, inplace = True)
fields = ['会员编号', '性别', '会员状态', '年龄', '教育程度', '接受电话', '接受短信', '会员类别', '省份', '城市', '是否有车',
'可用积分', '累计积分',
# 以下是一年前消费行为指标
'总消费频次(一年前)', '最近消费距现在天数(一年前)', '近一年消费频次(一年前)', '近一年消费金额(一年前)',
'生日距离现在月份数(一年前)', '入会距离现在月份数(一年前)', '累计金额(一年前)',
'是否关注公众号', '参加活动次数(一年前)', '停车次数(一年前)', '停车时长H(一年前)', '车辆数量',
# 标签值
'是否流失']
df = df.loc[:, fields]
df['性别'].fillna('保密', inplace=True)
df['年龄'].fillna('0', inplace=True)
df['累计积分'].fillna('0', inplace=True)
df['省份'].fillna('其他', inplace=True)
df['城市'].fillna('其他', inplace=True)
df['教育程度'].fillna('其他', inplace=True)
df['参加活动次数(一年前)'].fillna('0', inplace=True)
df['停车次数(一年前)'].fillna('0', inplace=True)
df['停车时长H(一年前)'].fillna('0', inplace=True)
df['车辆数量'].fillna('0', inplace=True)
df.replace({'性别':'null'},'保密', inplace=True)
df.replace({'年龄':'null'},'0', inplace=True)
df.replace({'累计积分':'null'},'0', inplace=True)
df.replace({'省份':'null'},'其他', inplace=True)
df.replace({'城市':'null'},'其他', inplace=True)
df.replace({'教育程度':'null'},'其他', inplace=True)
df.replace({'教育程度':'其它'},'其他', inplace=True)
df.replace({'教育程度':'高中(中专)'},'中专', inplace=True)
df.replace({'教育程度':'中等专科'},'中专', inplace=True)
df.replace({'教育程度':'大学专科'},'大专', inplace=True)
df.replace({'教育程度':'大学本科'},'本科', inplace=True)
df.replace({'教育程度':'硕士研究生'},'硕士', inplace=True)
经过简单预处理之后,来看看各个重要特征的值分布,根据特征值的内容,对于一些人为可以判断的无效特征,可以事先做一些精简。
有些特征方差实在很小,整列数据几乎只有一个取值,可以去掉这些特征,以免在后面训练中造成影响
有些特征之间有极强的相关性,像“城市”和“省份”,属于某城市一定属于某省份,对于这类特征,根据实际情况只保留一个有效特征即可
在后面的特征处理中虽然也会做移除低方差特征和主成分分析这个工作,但我们最好在源头就能保证数据的质量,既然人为能判断,就不要留到后面再做,人拿不准的判断,才留给技术处理。
数据清理越靠近源头越好,这就是我们的原则。
import matplotlib.pyplot as plt
import matplotlib.pylab as pylab
# 设置画图参数
params = {
'axes.titlesize': '18',
'axes.labelsize': '13',
'xtick.labelsize': '13',
'ytick.labelsize': '13',
'lines.linewidth': '2',
'legend.fontsize': '13',
'figure.figsize': '6, 5',
# 'figure.facecolor': 'white',
'figure.facecolor': 'snow',
# 正常显示中文
'font.sans-serif': 'SimHei',
# 正常显示负号
'axes.unicode_minus': False
}
pylab.rcParams.update(params)
def plot_groupby(df, fields):
for i in range(0, len(fields)):
assert len(fields) != 0, '数据集不能为空'
plt.subplot(len(fields), 3, i+1)
# df[fields[i]].groupby(df[fields[i]]).count().plot(kind='pie', startangle=270, shadow=True)
df[fields[i]].value_counts().sort_index().plot(kind='pie', startangle=270, shadow=True)
fig = plt.gcf()
fig.set_size_inches(14, 5 * len(fields))
fig.autofmt_xdate()
# plt.legend(loc='best')
plt.show()
plot_groupby(df, ['性别', '会员状态', '教育程度', '会员类别', '是否有车', '接受电话', '接受短信', '是否关注公众号', '省份', '城市'])
为了对样本数据有一个直观感受,先选择两个有代表性的特征,采样一小部分数据,把它们画在坐标系上,看看是否具备初步分类的特征。需要注意的是,实际上我们使用了数据的二十几个特征来进行训练,而这里由于要在二维坐标系上显示数据,我们只能选择两个特征,这两个特征远远不能代表全貌,只是提供一个初步的直观感受,实际上我们也可以看到只有两个特征的情况下,数据并没有显著的互相区分开来。
def show_sample(df):
# 选择两个有代表性的特征,采样50条数据
X_plt_Y = df[df['是否流失'] == 'Y'].sample(n=50).loc[:, ['总消费频次(一年前)', '最近消费距现在天数(一年前)']].values
X_plt_N = df[df['是否流失'] == 'N'].sample(n=50).loc[:, ['总消费频次(一年前)', '最近消费距现在天数(一年前)']].values
plt.scatter(X_plt_Y[:50, 0], X_plt_Y[:50, 1], color='red', marker='o', label='已流失')
plt.scatter(X_plt_N[:50, 0], X_plt_N[:50, 1], color='blue', marker='x', label='未流失')
plt.xlabel('总消费频次')
plt.ylabel('最近消费距现在天数')
plt.legend(loc='best')
plt.grid(True)
plt.show()
show_sample(df)
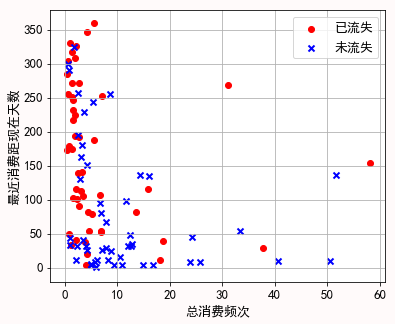
可以看到在只考虑两个有代表性特征的情况下,数据被粗略的分成两类。接下来我们尝试加入更多特征,并对特征做进一步处理,看看能不能做更精细的分类。
构建数据分类标签
数据的分类标签也就是事先给数据划分好的分类。对于训练数据来说,正是这个分类标签告诉算法该数据的正确分类是什么,对于测试数据来说,分类标签用来对模型输出的分类进行测试验证。
from sklearn.preprocessing import LabelEncoder
y = df.是否流失.values
y = LabelEncoder().fit_transform(y)
print(y)
[1 0 1 ..., 0 1 1]
特征处理
为了将数据输入到算法进行计算,需要对特征数据做各种有利于提升预测效果的变换,并将数据切分为训练集和测试集。
对特征做预处理,主要有如下几个处理过程。
把枚举型的数据全部转变为数字,这类数据只能在固定的集合中取值,像“性别”只能取值“男”、“女”或“保密”,那么它的值应该被处理成0、1或2。
对数据做标准化处理。由于各个特征的取值范围不一样,比如“累计积分”的取值范围要比“性别”的取值范围大很多,如果不做标准化处理,各个特征之间的方差差距非常大,这会影响模型训练的性能和效果。
移除低方差的特征,这样的特征对模型训练没什么帮助
对特征做降维处理,某些特征之间可能存在某种关联关系,通过降维处理,相关联的多个特征将被处理成多个正交的方差较大的特征向量,从而达到压缩特征向量的目的,这对提高计算效率和模型的效果有很大的意义。这里采用主成分分析PCA来做降维。
from sklearn.model_selection import train_test_split
def preprocess_features(X, y, test_size = 0.2):
# 标签类数据数值化
X.性别 = LabelEncoder().fit_transform(X.性别)
X.会员状态= LabelEncoder().fit_transform(X.会员状态)
X.教育程度= LabelEncoder().fit_transform(X.教育程度)
X.会员类别= LabelEncoder().fit_transform(X.会员类别)
X.省份= LabelEncoder().fit_transform(X.省份)
X.城市= LabelEncoder().fit_transform(X.城市)
X.是否有车= LabelEncoder().fit_transform(X.是否有车)
X.接受电话= LabelEncoder().fit_transform(X.接受电话)
X.接受短信= LabelEncoder().fit_transform(X.接受短信)
X.是否关注公众号= LabelEncoder().fit_transform(X.是否关注公众号)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = test_size, random_state = 0)
df_X_test = X_test
df_y_test = y_test
# onehotencoder = OneHotEncoder(categorical_features = [1])
# X_train = onehotencoder.fit_transform(X_train).toarray()
# X_train = np.delete(X_train, [0], 1)
# X_test = onehotencoder.fit_transform(X_test).toarray()
# X_test = np.delete(X_test, [0], 1)
# 移除低方差的特征,移除那些超过80%的数据都相同的特征
from sklearn.feature_selection import VarianceThreshold
vt = VarianceThreshold(threshold=(0.8 * (1 - 0.8)))
X_train = vt.fit_transform(X_train)
X_test = vt.fit_transform(X_test)
# 标准化处理,将特征值减去均值,除以标准差
# 变换后各维特征有0均值,单位方差
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.fit_transform(X_test)
# 归一化,将特征值映射到[0,1]区间
from sklearn.preprocessing import Normalizer
normalizer = Normalizer(norm='l2')
X_train = normalizer.fit_transform(X_train)
X_test = normalizer.fit_transform(X_test)
# # 利用主成分分析对数据进行降维处理
# from sklearn import decomposition
# # pca = decomposition.PCA(n_components=0.99)
# # pca = decomposition.PCA(n_components=6)
# pca = decomposition.PCA()
# X_train = pca.fit_transform(X_train)
# X_test = pca.fit_transform(X_test)
return X_train, X_test, y_train, y_test, df_X_test, df_y_test
X = df.iloc[:, 1 : -1]
X_train, X_test, y_train, y_test, df_X_test, df_y_test = preprocess_features(X, y, test_size = 0.2)
训练模型
使用逻辑回归算法训练模型,并对测试数据进行预测。
# 逻辑回归
from sklearn.linear_model import LogisticRegression
clf = LogisticRegression()
# from sklearn.ensemble import GradientBoostingClassifier
# clf= GradientBoostingClassifier(random_state=10)
# from sklearn.ensemble import RandomForestClassifier
# clf= RandomForestClassifier()
# K近邻
# from sklearn.neighbors import KNeighborsClassifier
# clf= KNeighborsClassifier()
# 决策树
# from sklearn.tree import DecisionTreeClassifier
# clf = DecisionTreeClassifier(max_depth=8)
clf.fit(X_train, y_train)
print('模型拟合得到的各个特征的权重向量')
print(clf.coef_)
# 使用模型对测试集进行预测
y_pred = clf.predict(X_test)
y_proba = clf.predict_proba(X_test)
print('测试集中每个数据属于各个分类的概率')
print(y_proba)
模型拟合得到的各个特征的权重向量
[[ 0.45191254 -0.14106264 0.71485707 -0.58603324 -1.45001049
0.10248359 -1.36833823 -32.94555061 -2.80966691 1.40884882
1.23937541 -4.90103402 2.43933976 0.46002433 -0.51806657
0.71911302 -0.28188146 0.78763868 -0.97428886 1.87561118
-1.2210612 ]]
测试集中每个数据属于各个分类的概率
[[ 0.12312803 0.87687197]
[ 0.17757516 0.82242484]
[ 0.22376395 0.77623605]
...,
[ 0.51354312 0.48645688]
[ 0.39261335 0.60738665]
[ 0.61063578 0.38936422]]
评估模型指标
根据模型预测结果,与测试数据目标结果进行对比,计算准确率(precision),召回率(recall)和F1 Score,画出ROC曲线,计算曲线下方面积AUC的值。
预测值为正例,记为P(Positive)
预测值为反例,记为N(Negative)
预测值与真实值相同,记为T(True)
预测值与真实值相反,记为F(False)
TP:预测类别是P,真实类别也是P
FP:预测类别是P,真实类别是N
TN:预测类别是N,真实类别也是N
FN:预测类别是N,真实类别是P
准确率(Precision):预测正确的正例数据占预测为正例数据的比例
召回率(Recall):预测为正例的数据占实际为正例数据的比例
Fβ值(Fβ score):Fβ值是准确率和召回率的调和均值,是准确率和召回率的综合评价指标。当有些情况下,我们认为准确率更重要些,那就调整β的值小于1,如果我们认为召回率更重要些,那就调整β的值大于1
F1值(F1 score):Fβ当取β=1时的值,相当于认为准确率和召回率一样重要,当F1较高时说明模型质量较好
Accuracy:预测正确的(包括预测正确的正例数据和预测正确的反例数据)占整个数据的比例
TPR(True Positive Rate):真实的正例中被预测正确的比例
FPR(False Positive Rate):真实的反例中被预测正确的比例
ROC曲线(Receiver Operating Characteristic,受试者工作特征曲线):得到一组(TPR,FPR),然后由点(TPR,FPR)组成的曲线,是多个混淆矩阵的结果组合
AUC(Area Under Curve):ROC曲线下方的面积,越接近1说明模型质量越好
import sklearn.metrics as metrics
def model_metrics(y_test, y_pred, y_proba):
fbeta = metrics.fbeta_score(y_test, y_pred, beta=4)
print('F4-Score: %.2f' % fbeta, end='\n\n')
print('分类报告\n' + metrics.classification_report(y_test, y_pred), end='\n')
print('混淆矩阵')
print(metrics.confusion_matrix(y_test, y_pred))
accuracy = metrics.accuracy_score(y_test, y_pred)
fpr, tpr, thresholds = metrics.roc_curve(y_test, y_proba[:, 1])
auc = metrics.auc(fpr, tpr)
#中文字体显示
plt.rc('font', family='SimHei', size=13)
#画图,只需要plt.plot(fpr,tpr)
plt.plot(fpr, tpr, lw=2, label='ROC Curve(AUC=%0.2f, accuracy=%0.2f)' % (auc, accuracy))
#画对角线
plt.plot([0, 1], [0, 1], '--', color=(0.6, 0.6, 0.6), label='随机预测')
plt.xlim([-0.05, 1.05])
plt.ylim([-0.05, 1.05])
plt.xlabel('FPR(False Positive Rate)')
plt.ylabel('TPR(True Positive Rate)')
plt.title('ROC curve(Receiver operating characteristic)')
plt.legend(loc='best')
plt.grid(True)
plt.show()
model_metrics(y_test, y_pred, y_proba)
F4-Score: 0.85
分类报告
precision recall f1-score support
0 0.91 0.66 0.76 8852
1 0.57 0.88 0.69 4595
avg / total 0.80 0.73 0.74 13447
混淆矩阵
[[5822 3030]
[ 562 4033]]

评价模型质量
基于上面的模型评估指标,我们如何来评价这个模型的质量?
通常我们使用准确率(Precision)和召回率(Recall)来评估模型的质量,前面介绍了准确率和召回率的计算公式,虽然从计算公式来看,两者并没有什么必然的关系,但是在大规模数据集合中,这两个指标往往是相互制约的。理想情况下做到两个指标都高当然最好,但一般情况下,准确率高,召回率就低,召回率高,准确率就低。所以在实践中常常需要根据具体情况做出取舍,例如常见的搜索引擎,需要在保证准确率的条件下,尽量提升召回率。而像癌症检测、地震检测、金融欺诈等,则在保证召回率的条件下,尽量提升准确率。
嫌疑人定罪,基于不错怪一个好人的原则,对于嫌疑人的定罪我们希望是非常准确的,要求准确率非常高,甚至必要的时候牺牲召回率,即使有些罪犯没有被正确预测(放过了一些罪犯),也是值得的。
地震预测,我们希望的是召回率非常高,也就是说每次地震我们都希望预测出来,不要漏报。这个时候我们可以牺牲准确率,情愿发出1000次警报,把10次地震都预测正确了,也不要预测100次,对了8次漏了两次。
在我们这个业务场景中,为了提高用户挽留的价值,我们的逻辑是这样的:
- 如果用户没有流失的倾向,而我们预测为将流失,那关系不大,我们的挽留用户列表中包含了这个用户,对忠实用户再做一次触达,没有什么坏处。就是说本来不流失而预测为流失,即预测的准确率不高,也没什么影响
- 如果用户有流失的倾向,而我们预测为不流失,我们的挽留用户列表中不包含这个用户,没有触达到该用户,将造成这个用户的真正流失。就是说本来要流失而没有被找出来,即预测的召回率不高,将造成真正的流失
换一种说法就是我们很关注召回率(Recall),不太关注准确率(Precision),更具体的说,我们很关注用户流失的召回率,对没有流失用户的召回率也不太关注。
在这个模型中,准确率是0.80,召回率是0.73,对于预测结果为流失(分类为1)的召回率达到了0.88。
而总体来看,通常我们使用F1-Score来综合评估召回率和准确率的值,在这个模型中F1-Score的值是0.74。F1-Score代表召回率和准确率同等重要,如果我们认为召回率比准确率更加重要,比如我们计算F4-Score的值,我们得到这个模型的F4-Score的值是0.85。
基于多个混淆矩阵我们画出了ROC曲线,通常我们使用ROC曲线下方的面积,也就是AUC的值来衡量模型的质量,在这个模型中AUC的值是0.84。
交叉验证
不失一般性,为防止单次训练对模型评估造成偶然性的偏差,我们对模型再做一个K折交叉验证,把数据集分成K份,轮流使用一份作为测试集,其余数据作为训练集进行验证,观察其AUC的值是否均匀,评估模型表现是否稳定。
from sklearn.cross_validation import cross_val_score
K = 10
scores = cross_val_score(clf, X, y, cv=K, scoring='roc_auc')
print('%d-Fold交叉验证结果: ' % K)
print(scores, end='\n\n')
print('%d-Fold交叉验证结果均值: %.2f' % (K, scores.mean()))
C:\ProgramData\Anaconda3\lib\site-packages\sklearn\cross_validation.py:44: DeprecationWarning: This module was deprecated in version 0.18 in favor of the model_selection module into which all the refactored classes and functions are moved. Also note that the interface of the new CV iterators are different from that of this module. This module will be removed in 0.20.
"This module will be removed in 0.20.", DeprecationWarning)
10-Fold交叉验证结果:
[ 0.90673967 0.90748945 0.9015688 0.9019813 0.90312298 0.90263653
0.90368534 0.91210915 0.9045497 0.88542386]
10-Fold交叉验证结果均值: 0.90
输出预测结果
合并用户数据和预测值,输出结果,保存为文件,方便从业务上人为评估模型准确性。
# 生成预测结果
from pandas import DataFrame
def output(df, df_test, y_pred, y_proba):
pred = DataFrame({'预测结果':y_pred})
proba = DataFrame(y_proba)
# 合并预测结果
X_test_index = df_X_test.reset_index()
X_test_pred = pd.concat([pred, proba, X_test_index], axis=1)
X_test_pred.rename(columns={1:'流失概率'}, inplace = True)
# 恢复原始index
X_test_pred = X_test_pred.loc[:,['index', '预测结果', '流失概率']].set_index('index')
# 与原始数据合并
user_churn = pd.concat([X_test_pred, df], axis=1, join='inner')
# 只过滤可能流失的用户
user_churn = user_churn[user_churn['预测结果'] == 1].reset_index()
# 1和0替换为Y和N
user_churn['预测结果'] = np.where(user_churn.预测结果 == 1, 'Y', 'N')
# 组织字段
label = user_churn['是否流失']
user_churn = user_churn.drop(['index', '是否流失'], axis=1)
user_churn.insert(0, '是否流失', label)
X_plt_Y = user_churn[(user_churn['是否流失'] == user_churn['预测结果'])]
# 输出文件
output_file_name = '预测结果.xlsx'
output_path = os.path.join(output_dir, output_file_name)
# user_churn.to_csv(file_name, encoding='gbk')
user_churn.to_excel(output_path, encoding='gbk', sheet_name='预测结果')
print('预测结果保存为:' + output_path)
output(df, df_X_test, y_pred, y_proba)
预测结果保存为:D:/ml/cr-user-churn\output\预测结果.xlsx
保存模型
将模型持久化,下次对当前用户流失进行预测时直接加载模型即可,而不需要每次都重新训练模型。
# 保存模型
from sklearn.externals import joblib
# 全量历史用户
model_file_name_all = 'cr-user-churn-all.model'
# 金卡以上用户
model_file_name_adv = 'cr-user-churn-adv.model'
model_path = os.path.join(model_dir, model_file_name_all)
joblib.dump(clf, model_path)
print('模型保存为:' + model_path)
模型保存为:D:/ml/cr-user-churn\model\cr-user-churn-all.model