上一篇笔记在这里:《机器学习》西瓜书学习笔记(二)
第四章 决策树
4.1 基本流程

决策树的生成是一个递归过程,有3种条件退出递归:
- 当前结点包含的样本同类。(3:)
- 当前属性值为空,或是所有样本在所在属性上取值相同。(6:)
- 当前结点包含的样本集合为空,不能划分。(12:)
4.2 划分选择
决策树生成的算法的关键是如何选择最优化分属性。

假定离散属性a有V个可能的取值{a1,a2,...,aV},若使用a来对样本集D进行划分,则有V个分支结点,其中第v个分支分支结点包含了D中所有在属性a上取值为av的样本,记为Dv。各个分支的权重是|Dv|/|D|。于是可以计算信息增益:

信息增益越大,则a划分获得的“纯度提升”越大,所以要求a*:

此外,数据集D的纯度可用基尼值表示,基尼值越小,数据集D的纯度越高。

属性a的基尼指数定义为:

要求的是:
4.3 剪枝处理
剪枝处理是用来解决“过拟合”问题的。
- 预剪枝:先算划分前后的验证集精度。
- 后剪枝:后算划分前后的验证集精度。
4.4 连续与缺失值
4.4.1 连续值处理
给定样本集D和连续属性a,假定a在D上出现了n个不同的取值,将这些值从小到大进行排序,记为{a1,a2,...,an},有划分点集合:
将式(4.2)改造:

4.4.2 缺失值处理
给定训练集D和属性a,令D表示D中在属性a上没有确实值的样本子集,令Dv表示~D中属性a上取值为av的样本子集。假定我们为每个样本x赋予一个权值wx,并定义:
可以得到推广的信息增益的计算式:


4.5 多变量决策树
如果单次处理多变量的话决策树会很复杂,可以找到一个多元函数来做决策。

第五章 神经网络
5.1 神经元模型

这里的f(x)是 激活函数。最理想的函数是阶跃函数,但是不连续不光滑,所以用Sigmoid函数。
5.2 感知机与多层网络


给定数据集,权重wi以及阈值θ通过学习得到,其中theta看成w
n+1,其中n+1输入固定为-1.0。对训练样例(x,y),若输出为^y,则感知机权重这样调整:
5.3 误差多传播(BP)算法
欲训练多层网络,上一节的学习规则就不够了,需要更强大的算法,逆误差算法就是其中之一。
BP算法:
给定训练集D={(x1,y1),(x2,y2),...,(xm,ym)},xi∈Rd,yi∈Rl,即输入示例有d个属性,输出l维实值向量。
下图给出了一个拥有d个输入神经元、l个输出神经元、q个隐层神经元的多层前馈网络结构:

其中输出层第j个神经元的阈值用θ j表示,隐层第h个神经元的阈值用γ h表示,输入层第i个神经元与输出层第j个神经元之间的链接权为v ih,隐层第h个神经元与输出层第j个神经元之间的链接权为v hj。假设隐层和输出层神经元都使用Sigmoid函数。
对训练例( x k, y k),假定神经网络的输出为 ^y k。
则网络在( x k, y k)上的均方误差为

图5.7的网络中有(d+l+1)q+l个参数需要确定:输入层到隐层的dq个权值、隐层到输出层的ql个权值、q个隐层神经元的阈值、l个输出层神经元的阈值。
BP算法基于梯度下降,对于误差Ek,给定学习率η,有:
对于Sigmoid函数,有:
于是记gj为:
代入得,
类似可得,
其中,


误差逆传播算法大致如下,

注意,BP算法的目标是要最小化训练集D上的累积误差,但是上面所介绍的“标准BP算法”每次仅针对一个训练样例更新连接权和阈值,如果推导出基于累积误差最小化的更新规则,就是累积误差逆转传播算法。
为了达到同样的累积误差极小点,标准BP算法需要更多的迭代,而累计BP算法直接针对累积误差最小化,它在读取整个训练集D一遍后才对参数进行更新。但是很多任务中,累计误差下降到一定程度后下降的特别慢,这是标准BP更快。
BP算法表示能力十分强大,所以会遇到“过拟合”情况,策略有二:
- 第一种是“早停”:将数据分为训练集和验证集,若训练集误差降低而验证集误差升高,则停止训练。
- 第二种是“正则化”:
其中λ∈(0,1)用于对经验误差与网络复杂度取折中。
5.4 全局最小和局部极小
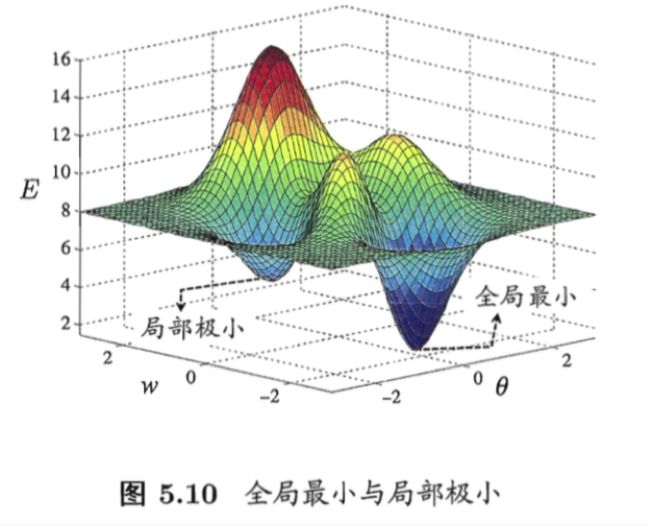
如果有多个局部极小,就不能保证找到的解是全局最小。
有以下办法来“跳出”局部极小:
- 多组不同参数值。
- “模拟退火”:每一步以一定概率接受比当前解更差的结果。
- 使用随机梯度下降。
5.5 其他常见神经网络
5.5.1 RBF网络
RBF(Radial Basis Function,径向基函数)网络是一种单隐层前馈神经网络,它使用径向基函数作为隐层神经元激活函数,而输出层则是对隐层神经元输出的线性组合。假定输入为d维向量x,输出为实值,则RBF函数可表示为:
q为隐层神经元个数,ci和wi分别是第i个隐层神经元所对应的中心和权重,ρ(x,ci)为径向基函数(顾名思义是关于径向距离的函数)。常用的高斯径向量基函数形如:
通常采用两步来训练RBF网络:
- 确定神经元中心ci(随机采样、聚类等)
- 利用BP算法等来确定参数wi和βi
5.5.2 ART网络
竞争型学习:每一时刻只有一个神经元被激活。
ART(Adaptive Resonance Theory,自适应谐振理论)网络是竞争型学习的重要代表,由比较层、识别层、识别阈值和重置模块构成:
- 比较层:接受输入样本并将其传送给识别层神经元。
- 识别层:接收信号后相互竞争以产生获胜神经元。(竞争的简单方式:比较与模式代表向量的距离,距离最小者胜)
- 若输入向量与获胜神经元所对应的代表向量之间的相似度大于识别阈值,则归类并更新网络连接权;否则增设一个新的神经元,其代表向量就设置为当前输入向量。
5.5.3 SOM网络
SOM(Self-Organizing Map,自组织映射)网络是一种竞争学习型的无监督神经网络,将高位输入数据映射到低维空间。

SOM的训练过程:在接收到一个训练样本后,每个输出层神经元会计算该样本与自身携带的权向量之间的距离,距离最近的神经元成为竞争获胜者,称为最佳匹配单元(best matching unit)。然后,最佳匹配单元及其邻近神经元的权向量将被调整,以使得这些权向量与当前输入样本的距离缩小,不断迭代至收敛。
5.5.4 级联相关网络

5.5.5 Elman网络
“递归神经网络”(recurrent neural network):允许网络中出现环形结构。
Elman网络就是常用的递归神经网络之一。

5.5.6 Boltzmann机
神经网络中有一类模型是为网络状态定义一个“能量”,能量最小化时网络达到理想状态,而网络的训练就是在最小化这个能量函数。Boltzmann机就是一种“基于能量的模型”,Boltzmann机的神经元就是布尔型的s∈{0,1}n表示n个神经元的状态,wij表示神经元i和j之间的连接权,θi表示神经元i的阈值,则状态向量s所对应的Boltzmann机能量定义为

若网络中的神经元以任意不依赖于输入值的顺序进行更新,则网络最终将达到Boltzmann分布,此时状态向量s出现的概率将仅由其能量与所有可能状态向量的能量确定:对数归一化
5.6 深度学习
再搬一段维基(滑稽):
深度学习(英语:deep learning)是机器学习拉出的分支,它试图使用包含复杂结构或由多重非线性变换构成的多个处理层对数据进行高层抽象的算法。[1][2][3][4][5]
深度学习是机器学习中一种基于对数据进行表征学习的方法。观测值(例如一幅图像)可以使用多种方式来表示,如每个像素强度值的向量,或者更抽象地表示成一系列边、特定形状的区域等。而使用某些特定的表示方法更容易从实例中学习任务(例如,人脸识别或面部表情识别[6]
)。深度学习的好处是用非监督式或半监督式的特征学习和分层特征提取高效算法来替代手工获取特征。[7]
表征学习的目标是寻求更好的表示方法并创建更好的模型来从大规模未标记数据中学习这些表示方法。表达方式类似神经科学的进步,并松散地创建在类似神经系统中的信息处理和通信模式的理解上,如神经编码,试图定义拉动神经元的反应之间的关系以及大脑中的神经元的电活动之间的关系。[8]
典型的深度学习模型就是很深层的神经网络。多隐层的神经网络难以用经典算法(例如标准BP算法)进行训练,因为误差在多隐层内逆传播时,往往在“发散”而不能收敛到稳定状态。
- 无监督逐层训练:将上一层隐结点的输出直接作为输入,而本层隐结点的输出直接作为下一层隐结点的输入,称为“预训练”。各层预训练全部完成后,再对整个网络进行“微调”。
- 权共享:让一组神经元使用相同的连接权,例如:卷积神经网络
下一篇:《机器学习》西瓜书学习笔记(四)