深度强化学习(DQN-Deep Q Network)之应用-Flappy Bird
本文系作者原创,转载请注明出处:https://www.cnblogs.com/further-further-further/p/10811587.html
目录
1.达到的目的
2.思路
2.1.强化学习(RL Reinforcement Learing)
2.2.深度学习(卷积神经网络CNN)
3.踩过的坑
4.代码实现(python3.5)
5.运行结果与分析
1.达到的目的
游戏场景:障碍物以一定速度往左前行,小鸟拍打翅膀向上或向下飞翔来避开障碍物,如果碰到障碍物,游戏就GAME OVER!
目的:小鸟通过训练,能够自动识别障碍物,做出正确的动作(向上或向下飞翔)。

2.思路
小鸟飞翔的难点是如何准确判断下一步的动作(向上或向下)?而这正是强化学习想要解决的问题。因为上一节案例网格的所有状态(state)数目是比较小的(16),所以可以通过遍历所有状态,计算所有状态的回报,生成 Q-Table(记录所有状态的价值)。但是本节的应用场景有所不同,它的状态是图片中的像素,如果图片大小是 84 * 84,batch = 4,每个像素大小在[0,255]范围内,有 256 种可能(256 个状态),那么最终 Q-Table 大小是

 数据计算量是非常庞大的。这里我们采用强化学习 + 深度学习(卷积神经网络),也就是 DQN(Deep Q Network)。
数据计算量是非常庞大的。这里我们采用强化学习 + 深度学习(卷积神经网络),也就是 DQN(Deep Q Network)。
卷积神经网络决策目的是预测当前状态所有行为的回报(Q-value)->目标预测值( )以及参数的更新;
)以及参数的更新;
强化学习的目的是根据马尔科夫决策过程以及贝尔曼价值函数计算出当前状态所有行为的回报 ->目标真实值( )
)
整张图片作为一个状态(因为小鸟不关心是像素还是图片,它只关心它下一步动作的方向),4张图片就是 4 个状态,且这 4 张图片在时间上是连续的。将所有状态(States:80*80*4)以及行为(Actions:1*2)作为卷积神经网络的输入值,卷积神经网络输出为当前状态的所有行为的价值(1*2),结构如下图

2.1 强化学习
贝尔曼最优方程如下(当前状态所有行为价值 = 当前即时奖励 + 下一状态所有行为的价值)
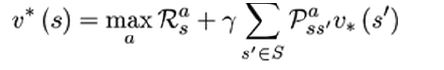
代码实现
1 readout_j1_batch = sess.run(readout, feed_dict = {s : s_j1_batch}) 2 for i in range(0, len(minibatch)): 3 terminal = minibatch[i][4] 4 # if terminal, only equals reward 5 if terminal: # 碰到障碍物,终止 6 y_batch.append(r_batch[i]) 7 else: # 即时奖励 + 下一阶段回报 8 y_batch.append(r_batch[i] + GAMMA * np.max(readout_j1_batch[i]))
minibatch保存了一个batch(32)下当前状态(s_j_batch)、当前行动(a_batch)、当前状态的即时奖励(r_batch)、当前状态下一时刻的状态(s_j1_batch)。
将当前状态下一时刻的状态(s_j1_batch)作为网络模型输入参数,就能得到下一状态(相对当前状态)所有行为的价值(readout_j1_batch),然后通过贝尔曼最优方程计算得到当前状态的Q-value。
大家可能会有这样的疑问:为什么当前状态价值要通过下一个状态价值得到,常规来说都是上一状态价值来得到?
贝尔曼最优方程充分体现了尝试这一核心思想,计算下一个状态价值是为了更新当前状态价值,从而找到最优状态行为。
2.2 深度学习
在输入数据进入神经网络结构之前,需要对图片数据进行预处理,从而减少运算量。
需要安装opencv库:pip install opencv-python,如果下载较慢,可以用国内镜像代替
pip install opencv-python -i http://pypi.douban.com/simple --trusted-host pypi.douban.com。
图片灰度处理:将彩色图片转变为灰度图片,图片大小设置成(80 * 80);
x_t = cv2.cvtColor(cv2.resize(x_t, (80, 80)), cv2.COLOR_BGR2GRAY)
二值化:设置图片像素阈值为 1,大于 1 的像素值更新为 255(白色),反之为 0(黑色)。
ret, x_t = cv2.threshold(x_t,1,255,cv2.THRESH_BINARY)
获取连续帧(4)图片:复制当前帧图片 -> 堆积成4帧图片 -> 将获取到得下一帧图片替换当前第4帧,如此循环就能保证当前的batch图片是连续的。
s_t = np.stack((x_t, x_t, x_t, x_t), axis=2)
s_t1 = np.append(x_t1, s_t[:, :, :3], axis=2)
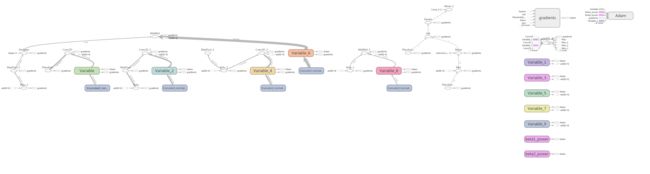
卷积神经网络模型
这里采用了3个卷积层(8*8*4*32, 4*4*32*64,3*3*64*64),3个池化层,4个Relu激活函数,2个全连接层,具体如下图
(建议对照图看代码,注意数据流的变化)

注意:要注意每个卷积层的Stride,因为padding = "SAME",与输入图片卷积后数据宽,高 = 输入图片宽,高/Stride。
比如,输入图片数据与第一个卷积层(8*8*4*32)卷积后,图片数据宽,高 = (80,80)/4 = (20,20),其他层卷积依次类推。
tensorboard可视流程图(具体生成操作步骤见 深度学习之卷积神经网络(CNN)详解与代码实现(二))
图片可能不是很清楚,在图片位置点击鼠标右键->在新标签页面打开图片,就可以放缩图片了。
3.踩过的坑
1.一定要弄明白深度强化学习的输入和输出。
强化学习的核心思想是尝试,深度学习的核心思想是训练。通过不断的将预测值和真实值的残差计算,不断的更新训练模型的参数,使残差值越来越小,最终收敛于一个稳定值,从而得到最佳的训练参数模型。
这里的预测值是通过深度学习得到,而真实值是通过强化学习得到,所以才有了深度强化学习的概念(DQN-Deep Q Network)。
卷积神经网络前向传播输入:4帧连续图片作为不同的状态States;
卷积神经网络前向传播输出:readout(2个不同的方向对应的价值);
卷积神经网络反向传播(通过损失函数获取损失,计算梯度,更新参数)输入:
i.y_batch(32, 2):通过强化学习得到的真实目标值[32 表示神经网络训练时每次批量处理数目,2表示Action不同方向对应的价值 ];
ii.a_batch(32, 2):每个行动的不同方向,在训练时更新步骤:初始化都为0 ->深度学习(卷积神经网络)输出readout_t(1, 2)-> 找到输出价值最大的索引 ->将a_batch中action相同索引置为1(表示最优价值的方向),达到更新得目的。
iii.s_j_batch(32, 80, 80, 4):下一个连续4帧,每一组是4帧,批量处理32组。
2.不要陷入常规的思维模式。
一般常规的思维模式是 A + B => C,这个 C 一般在计算或设计之前,在我们脑海中会计算出来,能够具体化。但是深度学习是打破这一常规思维模式的,它能够通过训练自发的学习,获取内在知识或规则。
以本节为例,在我们脑海中,总是想着下面几个问题
1. 为什么深度学习的结果就是行为的各个方向的价值,而不是其他?
解答:这是根据真实目标值决定的,卷积神经网络的要求是最后的输出值一定要跟真实目标值大小相同。损失函数计算损失,然后更新各个网络层的参数,不停的循环,使输出无限的逼近真实值,稳定后获取模型。
2. 在上一节强化学习时都是人为指定了方向的映射(0=up, 1=right, 2=down, 3=left),为什么深度强化学习不需要指定,它自己就能识别?
解答:当前一组帧和下一组帧之间在时间上是连续的,小鸟的每个动作在时间上也是连续的,通过深度学习后获取的模型其实已经学会了游戏的内在规则,知道在当前状态的下一步动作的方向,所以不需要我们人为指定,这正是深度学习的神奇之处。
4.代码实现(python3.5)
入口在代码最下端main,代码流程分为三个阶段:观察、探索、训练。由 OBSERVE 和 EXPLORE 设定
这也符合一般逻辑,先观察环境,然后再看看怎么飞。所以观察次数一般偏小,其实在探索时就已经在训练了,为什么要分开呢?
分开的目的是考虑更一般的情况,使模型更准确。比如某个状态向上和向下的价值一样,之前都是以向上的价值来计算整个价值,在探索时,我们就考虑向下的价值,然后来更新Q-Table。但是这种探索是随着模型的稳定,次数会越来越少。
工程结构图(整个工程代码可在百度网盘下载: https://pan.baidu.com/s/1faj-BHeYt14g3bNtrzsqXA 提取码: vxeb)

train.py
1 #!/usr/bin/env python 2 from __future__ import print_function 3 4 import tensorflow as tf 5 import cv2 6 import sys 7 sys.path.append("game/") 8 try: 9 from . import wrapped_flappy_bird as game 10 except Exception: 11 import wrapped_flappy_bird as game 12 import random 13 import numpy as np 14 from collections import deque 15 ''' 16 先观察一段时间(OBSERVE = 1000 不能过大), 17 获取state(连续的4帧) => 进入训练阶段(无上限)=> action 18 19 ''' 20 GAME = 'bird' # the name of the game being played for log files 21 ACTIONS = 2 # number of valid actions 往上 往下 22 GAMMA = 0.99 # decay rate of past observations 23 OBSERVE = 1000. # timesteps to observe before training 24 EXPLORE = 3000000. # frames over which to anneal epsilon 25 FINAL_EPSILON = 0.0001 # final value of epsilon 探索 26 INITIAL_EPSILON = 0.1 # starting value of epsilon 27 REPLAY_MEMORY = 50000 # number of previous transitions to remember 28 BATCH = 32 # size of minibatch 29 FRAME_PER_ACTION = 1 30 31 # GAME = 'bird' # the name of the game being played for log files 32 # ACTIONS = 2 # number of valid actions 33 # GAMMA = 0.99 # decay rate of past observations 34 # OBSERVE = 100000. # timesteps to observe before training 35 # EXPLORE = 2000000. # frames over which to anneal epsilon 36 # FINAL_EPSILON = 0.0001 # final value of epsilon 37 # INITIAL_EPSILON = 0.0001 # starting value of epsilon 38 # REPLAY_MEMORY = 50000 # number of previous transitions to remember 39 # BATCH = 32 # size of minibatch 40 # FRAME_PER_ACTION = 1 41 42 def weight_variable(shape): 43 initial = tf.truncated_normal(shape, stddev = 0.01) 44 return tf.Variable(initial) 45 46 def bias_variable(shape): 47 initial = tf.constant(0.01, shape = shape) 48 return tf.Variable(initial) 49 # padding = ‘SAME’=> new_height = new_width = W / S (结果向上取整) 50 # padding = ‘VALID’=> new_height = new_width = (W – F + 1) / S (结果向上取整) 51 def conv2d(x, W, stride): 52 return tf.nn.conv2d(x, W, strides = [1, stride, stride, 1], padding = "SAME") 53 54 def max_pool_2x2(x): 55 return tf.nn.max_pool(x, ksize = [1, 2, 2, 1], strides = [1, 2, 2, 1], padding = "SAME") 56 """ 57 数据流:80 * 80 * 4 58 conv1(8 * 8 * 4 * 32, Stride = 4) + pool(Stride = 2)-> 10 * 10 * 32(height = width = 80/4 = 20/2 = 10) 59 conv2(4 * 4 * 32 * 64, Stride = 2) -> 5 * 5 * 64 + pool(Stride = 2)-> 3 * 3 * 64 60 conv3(3 * 3 * 64 * 64, Stride = 1) -> 3 * 3 * 64 = 576 61 576 在定义h_conv3_flat变量大小时需要用到,以便进行FC全连接操作 62 """ 63 64 def createNetwork(): 65 # network weights 66 W_conv1 = weight_variable([8, 8, 4, 32]) 67 b_conv1 = bias_variable([32]) 68 69 W_conv2 = weight_variable([4, 4, 32, 64]) 70 b_conv2 = bias_variable([64]) 71 72 W_conv3 = weight_variable([3, 3, 64, 64]) 73 b_conv3 = bias_variable([64]) 74 75 W_fc1 = weight_variable([576, 512]) 76 b_fc1 = bias_variable([512]) 77 # W_fc1 = weight_variable([1600, 512]) 78 # b_fc1 = bias_variable([512]) 79 80 W_fc2 = weight_variable([512, ACTIONS]) 81 b_fc2 = bias_variable([ACTIONS]) 82 83 # input layer 84 s = tf.placeholder("float", [None, 80, 80, 4]) 85 86 # hidden layers 87 h_conv1 = tf.nn.relu(conv2d(s, W_conv1, 4) + b_conv1) 88 h_pool1 = max_pool_2x2(h_conv1) 89 90 h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2, 2) + b_conv2) 91 h_pool2 = max_pool_2x2(h_conv2) 92 93 h_conv3 = tf.nn.relu(conv2d(h_conv2, W_conv3, 1) + b_conv3) 94 h_pool3 = max_pool_2x2(h_conv3) 95 96 h_pool3_flat = tf.reshape(h_pool3, [-1, 576]) 97 #h_conv3_flat = tf.reshape(h_conv3, [-1, 1600]) 98 99 h_fc1 = tf.nn.relu(tf.matmul(h_pool3_flat, W_fc1) + b_fc1) 100 #h_fc1 = tf.nn.relu(tf.matmul(h_conv3_flat, W_fc1) + b_fc1) 101 102 # readout layer 103 readout = tf.matmul(h_fc1, W_fc2) + b_fc2 104 105 return s, readout, h_fc1 106 107 def trainNetwork(s, readout, h_fc1, sess): 108 # define the cost function 109 a = tf.placeholder("float", [None, ACTIONS]) 110 y = tf.placeholder("float", [None]) 111 # reduction_indices = axis 0 : 列 1: 行 112 # 因 y 是数值,而readout: 网络模型预测某个行为的回报 大小[1, 2] 需要将readout 转为数值, 113 # 所以有tf.reduce_mean(tf.multiply(readout, a), axis=1) 数组乘法运算,再求均值。 114 # 其实,这里readout_action = tf.reduce_mean(readout, axis=1) 直接求均值也是可以的。 115 readout_action = tf.reduce_mean(tf.multiply(readout, a), axis=1) 116 cost = tf.reduce_mean(tf.square(y - readout_action)) 117 train_step = tf.train.AdamOptimizer(1e-6).minimize(cost) 118 119 # open up a game state to communicate with emulator 120 game_state = game.GameState() 121 # 创建队列保存参数 122 # store the previous observations in replay memory 123 D = deque() 124 125 # printing 126 a_file = open("logs_" + GAME + "/readout.txt", 'w') 127 h_file = open("logs_" + GAME + "/hidden.txt", 'w') 128 129 # get the first state by doing nothing and preprocess the image to 80x80x4 130 do_nothing = np.zeros(ACTIONS) 131 do_nothing[0] = 1 132 x_t, r_0, terminal = game_state.frame_step(do_nothing) 133 #cv2.imwrite('x_t.jpg',x_t) 134 x_t = cv2.cvtColor(cv2.resize(x_t, (80, 80)), cv2.COLOR_BGR2GRAY) 135 ret, x_t = cv2.threshold(x_t,1,255,cv2.THRESH_BINARY) 136 s_t = np.stack((x_t, x_t, x_t, x_t), axis=2) 137 138 # saving and loading networks 139 tf.summary.FileWriter("tensorboard/", sess.graph) 140 saver = tf.train.Saver() 141 sess.run(tf.initialize_all_variables()) 142 checkpoint = tf.train.get_checkpoint_state("saved_networks") 143 """ 144 if checkpoint and checkpoint.model_checkpoint_path: 145 saver.restore(sess, checkpoint.model_checkpoint_path) 146 print("Successfully loaded:", checkpoint.model_checkpoint_path) 147 else: 148 print("Could not find old network weights") 149 """ 150 # start training 151 epsilon = INITIAL_EPSILON 152 t = 0 153 while "flappy bird" != "angry bird": 154 # choose an action epsilon greedily 155 # 预测结果(当前状态不同行为action的回报,其实也就 往上,往下 两种行为) 156 readout_t = readout.eval(feed_dict={s : [s_t]})[0] 157 a_t = np.zeros([ACTIONS]) 158 action_index = 0 159 if t % FRAME_PER_ACTION == 0: 160 # 加入一些探索,比如探索一些相同回报下其他行为,可以提高模型的泛化能力。 161 # 且epsilon是随着模型稳定趋势衰减的,也就是模型越稳定,探索次数越少。 162 if random.random() <= epsilon: 163 # 在ACTIONS范围内随机选取一个作为当前状态的即时行为 164 print("----------Random Action----------") 165 action_index = random.randrange(ACTIONS) 166 a_t[action_index] = 1 167 else: 168 # 输出 奖励最大就是下一步的方向 169 action_index = np.argmax(readout_t) 170 a_t[action_index] = 1 171 else: 172 a_t[0] = 1 # do nothing 173 174 # scale down epsilon 模型稳定,减少探索次数。 175 if epsilon > FINAL_EPSILON and t > OBSERVE: 176 epsilon -= (INITIAL_EPSILON - FINAL_EPSILON) / EXPLORE 177 178 # run the selected action and observe next state and reward 179 x_t1_colored, r_t, terminal = game_state.frame_step(a_t) 180 # 先将尺寸设置成 80 * 80,然后转换为灰度图 181 x_t1 = cv2.cvtColor(cv2.resize(x_t1_colored, (80, 80)), cv2.COLOR_BGR2GRAY) 182 # x_t1 新得到图像,二值化 阈值:1 183 ret, x_t1 = cv2.threshold(x_t1, 1, 255, cv2.THRESH_BINARY) 184 x_t1 = np.reshape(x_t1, (80, 80, 1)) 185 #s_t1 = np.append(x_t1, s_t[:,:,1:], axis = 2) 186 # 取之前状态的前3帧图片 + 当前得到的1帧图片 187 # 每次输入都是4幅图像 188 s_t1 = np.append(x_t1, s_t[:, :, :3], axis=2) 189 190 # store the transition in D 191 # s_t: 当前状态(80 * 80 * 4) 192 # a_t: 即将行为 (1 * 2) 193 # r_t: 即时奖励 194 # s_t1: 下一状态 195 # terminal: 当前行动的结果(是否碰到障碍物 True => 是 False =>否) 196 # 保存参数,队列方式,超出上限,抛出最左端的元素。 197 D.append((s_t, a_t, r_t, s_t1, terminal)) 198 if len(D) > REPLAY_MEMORY: 199 D.popleft() 200 201 # only train if done observing 202 if t > OBSERVE: 203 # 获取batch = 32个保存的参数集 204 minibatch = random.sample(D, BATCH) 205 # get the batch variables 206 # 获取j时刻batch(32)个状态state 207 s_j_batch = [d[0] for d in minibatch] 208 # 获取batch(32)个行动action 209 a_batch = [d[1] for d in minibatch] 210 # 获取保存的batch(32)个奖励reward 211 r_batch = [d[2] for d in minibatch] 212 # 获取保存的j + 1时刻的batch(32)个状态state 213 s_j1_batch = [d[3] for d in minibatch] 214 # readout_j1_batch =>(32, 2) 215 y_batch = [] 216 readout_j1_batch = sess.run(readout, feed_dict = {s : s_j1_batch}) 217 for i in range(0, len(minibatch)): 218 terminal = minibatch[i][4] 219 # if terminal, only equals reward 220 if terminal: # 碰到障碍物,终止 221 y_batch.append(r_batch[i]) 222 else: # 即时奖励 + 下一阶段回报 223 y_batch.append(r_batch[i] + GAMMA * np.max(readout_j1_batch[i])) 224 # 根据cost -> 梯度 -> 反向传播 -> 更新参数 225 # perform gradient step 226 # 必须要3个参数,y, a, s 只是占位符,没有初始化 227 # 在 train_step过程中,需要这3个参数作为变量传入 228 train_step.run(feed_dict = { 229 y : y_batch, 230 a : a_batch, 231 s : s_j_batch} 232 ) 233 234 # update the old values 235 s_t = s_t1 # state 更新 236 t += 1 237 238 # save progress every 10000 iterations 239 if t % 10000 == 0: 240 saver.save(sess, 'saved_networks/' + GAME + '-dqn', global_step = t) 241 242 # print info 243 state = "" 244 if t <= OBSERVE: 245 state = "observe" 246 elif t > OBSERVE and t <= OBSERVE + EXPLORE: 247 state = "explore" 248 else: 249 state = "train" 250 251 print("terminal", terminal, \ 252 "TIMESTEP", t, "/ STATE", state, \ 253 "/ EPSILON", epsilon, "/ ACTION", action_index, "/ REWARD", r_t, \ 254 "/ Q_MAX %e" % np.max(readout_t)) 255 # write info to files 256 ''' 257 if t % 10000 <= 100: 258 a_file.write(",".join([str(x) for x in readout_t]) + '\n') 259 h_file.write(",".join([str(x) for x in h_fc1.eval(feed_dict={s:[s_t]})[0]]) + '\n') 260 cv2.imwrite("logs_tetris/frame" + str(t) + ".png", x_t1) 261 ''' 262 263 def playGame(): 264 sess = tf.InteractiveSession() 265 s, readout, h_fc1 = createNetwork() 266 trainNetwork(s, readout, h_fc1, sess) 267 268 def main(): 269 playGame() 270 271 if __name__ == "__main__": 272 main()
5.运行结果与分析
因为不能上传视频,所以只能截取几张典型图片了。我训练了2920000次生成的模型,以这个模型预测,小鸟能够自动识别障碍物,不会发生碰撞。按如下配置训练和预测:
训练:OBSERVE = 1000,EXPLORE = 3000000
预测:OBSERVE = 100000,EXPLORE = 3000000 (预测是引用模型,所以不需要训练,OBSERVE要尽可能大)
预测时在train.py文件中将下面引用模型注释打开
""" if checkpoint and checkpoint.model_checkpoint_path: saver.restore(sess, checkpoint.model_checkpoint_path) print("Successfully loaded:", checkpoint.model_checkpoint_path) else: print("Could not find old network weights") """
小鸟运行结果图片



在预测状态,运行代码,小鸟会自动飞翔,这时也会相应打印一些参数结果出来:

参数结果
terminal:是否碰撞到障碍物(True :是,False:否);
TIMESTEP:表示运行次数;
STATE:当前模型运行状态(observe:观察,explore:探索,train:训练);
EPSILON:表示进入探索阶段的阈值,是逐渐减小的;
ACTION:行动方向最大价值的索引;
REWARD:即时奖励;
Q_MAX:输出行动方向的最大价值;
不要让懒惰占据你的大脑,不要让妥协拖垮了你的人生。青春就是一张票,能不能赶上时代的快车,你的步伐就掌握在你的脚下。