1. 噪声类型
a.椒盐噪声:黑色像素和白色像素随机出现的一类噪声。
b.脉冲噪声:白色像素随机出现的一类噪声
c.高斯噪声:高斯噪声是指它的强度变化服从高斯分布(即正态分布)的一类噪声。
2. Correlation filtering(相关滤波)

从图像左上角像素开始计算
窗口大小是(2k+1)(2k+1)
h(u,v)函数为针对每一个邻近像素点所赋予的权重,上式被记为
eg:
均值滤波:各个邻近像素赋予同样的权重
高斯滤波:权重函数为高斯函数,抑制高频噪声
应用:sharpening(锐化)

需要考虑的问题:boundary issue,边界处的像素不能参与到上述操作,在matlab中,针对此问题,有三种操作:

边界扩张的几种方法:copy edge(复制最边缘像素)、reflect across edge(以最边缘像素为轴,对称复制像素)、clip filter(直接四周加黑边)、wrap around(图像大小通过将图像看成是一个二维周期函数的一个周期来扩展)
3. Convolution(卷积)

从图像右下角像素开始计算,注意与correlation的区别,符号表示为
在有些情况下,卷积的核函数是可以进行分解,变成向量与向量的乘积
计算卷积需要的乘法次数
4.sobel算子
下图左右部分分别为提取竖直边缘和水平边缘的sobel算子

5.中值滤波
适合处理脉冲噪声、椒盐噪声,能够保留边缘信息
6.Edge detect(边缘检测)
核心思想:寻找梯度变化最大的地方
Step1:图像去噪,减少噪声的影响
Step2:利用梯度检测边缘
卷积导数定理:
h为kernel函数,f为图像,即对图像先进行卷积操作,再求导获取边缘信息,可以转换成,直接对kernel求导,然后再与图像进行卷积操作。

7.Laplacian of Gaussian(高斯-拉普拉斯算子)


LOG是集平滑和边沿检测于一身的算子模型,即先进行高斯滤波,再进行拉普拉斯算子运算,拉普拉斯算子可用高斯差分近似
8. 边缘检测常规的步骤
a. 平滑:抑制噪声
b. 边缘增强:通过滤波器
c. 边缘定位:确定哪些是真正的边缘,哪些是噪声(设置一个 threshold,低于这个值的边缘设置为 0,高于这个值的边缘设置为 1)
Canny 边缘检测算子(双阈值检测,如果边缘梯度值小于高阈值,大于低阈值,则标记为弱边缘点)

9.Chamfer distance(倒角距离):
Average distance to nearest feature,一种对于图像的距离变换(distance transform),常用于 shaped based object detection。对两幅图像进行匹配: 其中一幅计算 Chamfer distance transform, 将另外一幅的特征点叠加在 DT 上,计算特征点对应的 DT 值的均值,那么曲线和图像之间的距离就可以通过叠加这些点上的 DT 的某种均值来计算,比如 root mean square(rms)。
10. 二值图像分析的基本步骤
a. 将图像转换为二值图像
b. 使用形态学相关操作(腐蚀、膨胀)处理二值图像
c. 提取单独的区域
d. 描述区域属性
11. Morphological operators(形态学算子)
a. dilation(膨胀) :Expands connected componentsif current pixel is 1, then set all the output pixels corresponding to structuring element to 1.
b. erosion(腐蚀)



c. opening(开操作):先腐蚀操作,再膨胀操作,去掉微小的区域,保留原始的形状
d. closing(闭操作):先膨胀再腐蚀,填充空洞
12. 二值图像进行处理的优缺点
优点:计算简单,易于存储,可以应用简单的处理技巧,相关的一些描述子很有用
缺点:很难得到清晰的轮廓,现实中的场景往往是嘈杂的,这种表示比较粗糙,不
是三维的信息。
13. Texture feature(纹理特征)
(1)filter bank
Eg.

14. Global feature 与 local feature
Global feature:颜色特征、纹理特征、边缘特征,全局特征容易受到光照、形变、视点不同、尺寸、遮挡的影响。
Local feature:sift 特征等,通常不会单独使用
15. Harris Corner
性质:旋转不变性,对亮度变化不敏感,但是对尺度变化敏感
人们通常通过在一个小的窗口区域内观察点的灰度值大小来识别角点,如果往任何方向移动窗口都会引起比较大的灰度变换那么往往这就是我们要找的角点

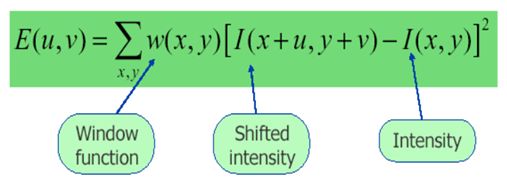
[x,y]平移[u,v]个单位后,I表示强度,如果是强度恒定的区域,值就接近于0.
a. 计算图像x,y方向的梯度Ix,Iy
b. 计算每个像素点的梯度平方
c. 计算梯度在每个像素点的和
d. 定义在每个像素点的矩阵 H,也就是前面的 M
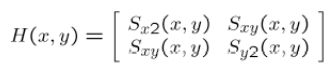
e. 计算每个像素的角点响应
f. 设置阈值找出可能点并进行非极大值抑制
16. Sift(scale invariant feature transform,尺度不变特征变换)
Sift 是一种检测和描述局部特征的描述子,对尺度、旋转、亮度,对仿射,噪声,遮挡,视角具有一定鲁棒性:

a.Scale space:高斯金字塔模型,包含 gaussian blurring 和 down sampling 两个部分
b.Take DOG:相当于提取 edge 特征
c.Locate DoG extrema
d.得到潜在的特征点
e.过滤掉一些无效关键点:low contrast, strong edge with response in one direction only
f.为关键点选取主方向(旋转不变性)
g.构建特征点描述子(4*4*8=128 维)

寻找主方向

17. Sift 应用
a. 关键点匹配:计算 sift 特征描述子间的距离
b. 图像匹配
18. Surt 特征(speeded up robust features)

19. Brsik(Binary Robust Invariant Scalable Keypoints)
20. CNN feature learning
传统的:手工设计的特征

深度学习方法:

21. RANSAC(RANdom SAmple Consensus(随机抽样一致))
Intuition:如果离群点参与了拟合的话,那么势必会造成得到的直线对其他正常点的贴近程度变小。
RANSAC 算法的输入是一组观测数据(往往含有较大的噪声或无效点),一个用于解释观测数据的参数化模型以及一些可信的参数。RANSAC 通过反复选择数据中的一组随机子集来达成目标。步骤如下:
a.随机选择一些点,并假设其为局内点,得到模型,即所有的未知参数都能从假设的局内点计算得出。
b.用 1 中得到的模型去测试所有的其它数据,如果某个点适用于估计的模型,认为它也是局内点。
c.如果有足够多的点被归类为假设的局内点,那么估计的模型就足够合理。然后,用所有假设的局内点去重新估计模型(譬如使用最小二乘法),因为它仅仅被初始的假设局内点估计过。
d. 最后,通过估计局内点与模型的错误率来评估模型。上述过程被重复执行固定的次数,每次产生的模型要么因为局内点太少而被舍弃,要么因为比现有的模型更好而被选用。
该算法的评价:
优点:简单,使用范围广(simple and general) ,适用于许多不同的问题,实际效果好
缺点:参数需要优化,局内点的比例太少时,效果不会太好,不能总是根据最少的样本数对模型进行良好的初始化。
22. Voting 思想

23. Hough transform(霍夫变换) :检测直线

霍夫变换步骤
24. matching:对两张图片中的特征对进行匹配
总体思路:
a. Find a set of distinctive key-points
b. Define a region around each keypoint
c. Extract and normalize the region content
d. Compute a local descriptor from the normalized region
e. Match local descriptors
25. grouping
目的:将属于同一个目标的特征聚集在一起
方法:自顶向下 vs 自下而上
Gestalt 理论:图像整体包含的信息大于部分信息的总和,不同部分之间的关系可以产生出新的特征。
常用算法:K-means

26. mean-shift(均值漂移)
Mean shift 算法是基于核密度估计的爬山算法,可用于聚类、图像分割、跟踪等
Mean-shift 聚类流程
a. 在未被标记的数据点中随机选择一个点作为中心 center;
b. 找出离 center 距离在 bandwidth 之内的所有点,记做集合 M,认为这些点属于簇 c。同时,把这些求内点属于这个类的概率加 1,这个参数将用于最后步骤的分类
c. 以 center 为中心点,计算从 center 开始到集合 M 中每个元素的向量,将这些向量相加,得到向量 shift。
d. center = center + shift。即 center 沿着 shift 的方向移动,移动距离是||shift||。
e. 重复步骤 b,c,d,直到 shift 的大小很小(就是迭代到收敛),记住此时的center。注意,这个迭代过程中遇到的点都应该归类到簇 c。
f. 如果收敛时当前簇 c 的 center 与其它已经存在的簇 c2 中心的距离小于阈值,那么把 c2 和 c 合并。否则,把 c 作为新的聚类,增加 1 类。
g. 重复 a,b,c,d,e 直到所有的点都被标记访问。
h. 根据每个类,对每个点的访问频率,取访问频率最大的那个类,作为当前点集的所属类。
总结起来就是,mean shift 就是沿着密度上升的方向寻找同属一个簇的数据点。
优缺点:

27. Segmentation by Graph Cuts(使用了图论的相关理论)
28. Alignment:对两张图片中的特征对进行匹配
29. 齐次坐标

30. 几种变换
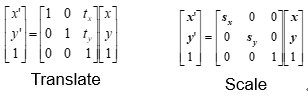
平移与缩放


仿射变换
31. Image-alignment(图像对齐)
(1) 基于像素的对齐方法
(2) 基于特征的对齐方法
32. Object recognition(目标识别)
(1) statistic learning framework:先训练,通过设置一定的损失函数优化参数,使用测试集进行测试
(2) 传统的方法:手工设计特征,然后进行训练
(3) “bag of words”(词包模型)
a. Extract local features, such as sift
b. Learn “visual vocabulary”, build codebook, usually by clustering.
c. Quantize local features using visual vocabulary
d. Represent images by frequencies of “visual words”
(4)spatial pyramid(空间金字塔)
33. Nearest neighbor vs. linear classifiers

34. Support vector machines(支持向量机)
Motivation:寻找正负样本间的最大间隔


针对非线性的边界:non-linear SVM,将数据从低维空间映射到高维空间Kernel trick:

常见的几种核函数:
a. radial basis function (RBF) kernel(高斯核)

b. linear:
c. Polynomials of degree up to d
d. Histogram intersection
Hard margin SVM:

Soft margin SVM:

优势:可以使用 kernel、目标函数是凸函数,存在全局最优解并且可以得到,方便理论分析扩展,在小数据集上表现好
劣势:没有直接的多分类 SVM,计算量大
35. SVM 用于多分类问题
(1) ONE VS ONE
(2) ONE VS OTHERS
36. 使用 SVM
a. Select a kernel function.
b. Compute pairwise kernel values between labeled examples.
c. Use this “kernel matrix” to solve for SVM support vectors & alpha weights.
d. To classify a new example: compute kernel values between new input and support vectors, apply alpha weights, check sign of output.
37. Underfitting、overfitting、generalization ability、train/validation/test
38. Deep learning
39. Projective Geometry and Camera Models
(1) Vanishing points and vanishing lines

(2) Pinhole camera model and camera projection matrix


(3) Homogeneous coordinates
K 为相机内参数矩阵

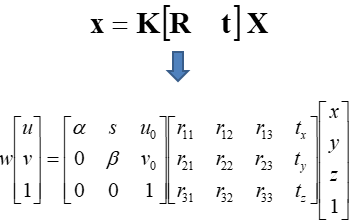

40. Face recognition
降维:

方法:PCA
41. The Eigenfaces Algorithm(特征脸算法)
Assumption:假设所有的脸都落在方差最大的前 k 个特征组成的子空间中
方法:使用 PCA 找到张成这个子空间的基向量,或者叫 eigenfaces,然后将所有图片用这些基向量的线性组合来表示。
算法 training 步骤:
a. 将所有的图片进行对齐
b. 计算平均脸

c. Compute the difference image (the centered data matrix)

d. Compute the covariance matrix Σ

e. Compute the eigenvectors of the covariance matrix Σ
f. Compute each training image xi ‘s projections as
g. Visualize the estimated training face xi

算法缺点:所有图片的尺寸大小要相同,脸部要对齐,并且对角度比较敏感
优点:非迭代算法,可以找到全局最优解
特点:completely knowledge free
42. LDA(Linear Discriminant Analysis,线性判别分析)
目标:寻找两个类之间的最好分隔投影面

应用算法:Fisherfaces
PCA 与 LDA 的区别:PCA preserves maximum variance,LDA Find projection that maximizes scatter between classes and minimizes scatter within classes