前言
这一节我想要探讨一下如何在遗传算法中处理约束。 这部分内容主要是对Coello Coello大神的经典文章《Theoretical and numerical constraint-handling techniques used with evolutionary algorithms: a survey of the state of the art》的再加工以及代码实现。想要更加深入了解的同学,强烈推荐阅读一下这篇文章。
罚函数法简介和实现思路
罚函数法的基本思想
用遗传算法求解约束优化问题时,罚函数法是最常见的一种有效手段。罚函数法的基本思想就是通过在适应度函数中对违反约束的个体施加惩罚,将约束优化问题转化为求解无约束优化问题。
罚函数法在使用中面临的最大问题是如何选取合适的惩罚系数:
- 惩罚系数较大,族群会更加集中在可行域中,而不鼓励向不可行域探索。当惩罚系数过大,容易使算法收敛于局部最优;
- 惩罚系数较小,族群会更积极在不可行域中进行大量探索,一定程度上能帮助寻找全局最优,但也有浪费算力的风险。当惩罚系数过小,算法可能会收敛于不可行解。
在通常的罚函数设计中,有三种惩罚的思路:
- 无论违反约束的程度如何,只要违反了约束,就施加以同样力度的惩罚;
- 根据违反约束程度的不同加以惩罚;
- 根据不可行解“修复”的难度或者距离可行域的距离施加惩罚。
实施思路
依照Carlos A. Coello Coello教授的综述,罚函数法主要有以下几种:
- 死亡惩罚(Death Penalty)
死亡惩罚简单粗暴,对于非可行解,直接将其适应度函数调整到极容易被淘汰的大小(常用归零),使其“死亡”。 - 静态惩罚(Static Penalty)
顾名思义,在静态惩罚中,通过在适应度函数中整合惩罚项,降低违反约束的个体的适应度,在计算中惩罚系数为常数,不会随着算法迭代变化。 - 动态惩罚(Dynamic Penalty)
在动态惩罚中,惩罚系数会随着代数变化。通常为保证收敛性,惩罚系数会随着迭代进行而逐渐增大。 - 退火惩罚(Annealing Penalty)
结合模拟退火的思想,惩罚系数在一定代数内保持稳定,呈阶梯式调整。 - 自适应惩罚(Adaptive Penalty)
自适应惩罚的思想是从遗传算法迭代的过程中获得反馈,由得到的解质量来判定是要加大还是较小惩罚系数。
各类罚函数详解与代码实现
死亡惩罚(Dealth Penalty)
死亡惩罚就是对所有违反约束的解个体分配一个极差的适应度,例如归零或者在最小化问题中设为一个很大的值。通过这样操作,在后续的选择和变异操作中,不可行解就会被筛选掉。
死亡惩罚是在进化算法中非常流行的惩罚策略,其优点在于实施简单,但是缺点也不少:首先,它只能适用于可行域占解空间比例较大的情况,如果可行域很小,那么初始生成个体很可能没有落于其中的,那么就会全部死亡,使算法陷入停滞;其次,它没有从不可行解中利用任何信息,不能为下一步的进化提供指导,也就是前人的牺牲对于后人完全没有意义。各类研究都表明死亡惩罚是一种比较弱的方法,基本所有其他惩罚方法都能在结果或搜索效率上吊锤它。
可以利用DEAP提供的装饰器很容易的实现死亡惩罚:
def feasible(ind):
# 判定解是否满足约束条件
# 如果满足约束条件,返回True,否则返回False
if feasible:
return True
return False
## 用装饰器修饰评价函数
toolbox.register('evaluate', evalFit) # 不加约束的评价函数
# 假设时最小化问题,并且已知的最小值远小于1e3
toolbox.decorate('evaluate', tools.DeltaPenalty(feasible, 1e3)) # death penalty
# 这样添加装饰器之后,在feasible返回True的时候,评价函数会返回evalFit的返回值;否则会返回1e3。
这里稍微解释下函数,该函数专门用来装饰评价函数,装饰后的返回为
其中是个体;是自定义的一个常数,通常将它设置为远劣于一般个体的适应度;是第个函数的权重,在定义问题时由weights参数指定,对于单目标优化问题没有特别的意义;给定的distance函数,指示到可行域的距离,如果不给定distance参数,则默认为0。
静态惩罚(Static Penalty)
静态惩罚会将违反约束的程度作为一种考量,在加权后纳入到适应度函数当中。权重在迭代过程当中保持不变,这就是“静态”名字的由来。相比于死亡惩罚绝不允许个体踏出可行域,静态惩罚允许一定程度的由外至内的搜索,因此其搜索效果会相对较好 -- 尤其考虑到很多约束优化的最优解会落在可行域边界和顶点上。
以Hoffmeister和Sprave提出的惩罚函数构造为例:
其中是Heaviside Function:
这种构造对违反了约束/或者没有违反约束的部分进行惩罚/奖励。这个函数的主要缺点在于:由于约束函数没有经过均一化,因此在搜索过程中有biased的可能 -- 违反代价较小的约束而满足代价较高的约束。
动态惩罚(Dynamic Penalty)
动态惩罚是对于静态惩罚的一种改进,它的思想是在迭代过程中动态改变惩罚系数,在扩大搜索范围和保证收敛性之间取得动态平衡。
Joines和Houck提出的一种惩罚函数:
其中是用户自定义的参数,在文章中,作者选取了,定义为:
而定义为:
退火惩罚(Annealing Penalty)
退火惩罚实际上也是一种动态惩罚,只是它的惩罚系数调整的方式来自于模拟退火算法,以一种类似模拟退火中的temperature schedule的方式来动态调整惩罚系数。
Carlson Skalak基于模拟退火的思路,给出了如下的一套惩罚方案:
基于如下公式:
其中
就是模拟退火算法中的cooling schedule,其定义如下:
其中是前一次迭代中的温度。
自适应惩罚(Adaptive Penalty)
自适应惩罚是对动态惩罚的一种演进,它的主要思路在于从迭代过程中取得反馈,用这个反馈来指导迭代系数的调整。
Bean和Hadj-Alouane设计了这样一套惩罚方式:
其中,在每代中以如下方式更新:
其中并且。
这套惩罚函数会利用搜索过程中的反馈,其思路如下:
- case 1: 若过去代最优解均可行,较小惩罚系数,扩大搜索空间;
- case 2: 若过去代最优解均不可行,增大惩罚系数,将族群收束入可行域;
- case 3: 若过去代最优解在可行域与不可行域之间震荡,不改变惩罚系数。
在原文中,是根据用线性规划法预先求得的解来估算的,并不适合通用问题。
Dummy测试
用简单的函数来测试各类约束下的GA算法是否能够如预期般工作。
目标函数:
测试的惩罚方式有:
- 死亡惩罚
- 静态惩罚
- 动态惩罚
施加死亡惩罚
死亡惩罚可以用DEAP的装饰器实现,评价函数与装饰部分代码如下:
# 用死亡惩罚实现约束
def evalSimple(ind):
# 朴素的评价函数
return (ind[0]**2 + ind[1] **2),
def feasible(ind):
# 判定解是否可行
if (ind[0]**2 + ind[1] **2) < 25:
return True
return False
toolbox.register('evaluate',evalSimple)
toolbox.decorate('evaluate', tools.DeltaPenalty(feasible, 100))
只要个体不落在可行域内,就使其适应度为100,这个值要远大于其他可行解的适应度,因此我们可以期待这种个体很快就会在迭代中被淘汰灭绝,从而留下的解都能落在可行域之内。
结果(红色虚线代表可行域范围,蓝色点代表族群中的个体):
施加静态惩罚
静态惩罚就是原先的目标函数加上一个静态惩罚项,实现起来也较为容易:
# 用静态惩罚实现约束
def evalStatic(ind):
# 朴素的评价函数 + 静态惩罚项
return (ind[0]**2 + ind[1] **2 + StaticPenalty(ind)),
def StaticPenalty(ind):
# 判定解是否可行
if (ind[0]**2 + ind[1] **2) < 25:
return 0
# 当解不可行时,施加静态惩罚
return np.sqrt(ind[0]**2 + ind[1] **2 - 25)
toolbox.register('evaluate',evalStatic)
结果(红色虚线代表可行域范围,蓝色点代表族群中的个体):

施加动态惩罚
动态惩罚需要记录个体的迭代代数,为了简单实现,我们在生成个体的时候就直接赋予一个gen属性以记录当前迭代步数:
## 问题定义
creator.create('FitnessMin', base.Fitness,weights=(-1.0,))
creator.create('DynamicIndividual', list, fitness=creator.FitnessMin, gen=None) # 给个体加上gen参数用以记录当前代数,方便施加动态惩罚
## 个体编码
toolbox = base.Toolbox()
IND_SIZE = 2 # 2位实数编码
def genRand(icls, n):
genome = list()
for i in range(n):
genome.append(-10 + 20*random.random())
return icls(genome)
toolbox.register('dynamicIndividual', genRand, creator.DynamicIndividual, n=IND_SIZE)
这样在迭代的时候每一代更新个体的gen参数,计算动态惩罚的时候就可以调用:
## 评价函数
def evalDynamic(ind):
# 朴素的评价函数 + 动态惩罚项
return (ind[0]**2 + ind[1] **2 + DynamicPenalty(ind)),
def DynamicPenalty(ind):
# 判定解是否可行
if ind.gen:
# 求解惩罚函数,用默认参数 C = 0.5, alpha = 2, beta = 2
cons = ind[0]*ind[0] + ind[1]*ind[1]- 5*5
cons = np.where(cons > 0, cons, 0)
SVC = np.sum(np.square(cons))
return (0.5*ind.gen)*(0.5*ind.gen)*SVC
# 第0代时,没有惩罚
else:
return 0
toolbox.register('evaluate',evalDynamic)
结果(红色虚线代表可行域范围,蓝色点代表族群中的个体):

小结
- 三种惩罚方式都能够实现约束的施加,在这样一个简单的dummy问题上,到第6代左右就将所有的个体压入了可行域;
- 当前采用的算法,动态惩罚的力度和静态惩罚的力度似乎差不多,这可能是因为迭代步数还比较少的时候个体就已经全部进入了可行域;动态惩罚随着迭代步数增长惩罚力度加大的特性还没有能够完整展现。
实际问题测试
问题描述
本次测试中选取的问题是Himmelblau's nonlinear optimization problem,问题描述如下:
在该问题中,一共有6个非线性不等式约束和10个边界条件。
程序实现
个体编码
这里的个体编码采用5个实数进行编码。由于每个基因片段的上下界都不同,DEAP自带的函数中没有合用的,因此自行编写一个函数生成个体编码,代码如下:
## 问题定义
creator.create('FitnessMin', base.Fitness, weights=(-1.0,)) # 定义最小化问题
creator.create('Individual', list, fitness=creator.FitnessMin)
## 个体编码 -- 实数编码,5位数字
def genInd(icls, lbs, ubs):
# 由于每个基因片段上下界都不同,无现成可用的函数,自定义一个函数生成个体编码
# 输入:icls -- individual class
# lbs -- 列表,包含各个位置的下界
# ubs -- 列表,包含各个位置的上界
genome = list()
for i in range(len(lbs)):
genome.append(random.uniform(lbs[i], ubs[i]))
return icls(genome)
toolbox = base.Toolbox()
lbs = [78, 33, 27, 27, 27] # 变量下界
ubs = [102, 45, 45, 45, 45] # 变量上界
toolbox.register('individual', genInd, creator.Individual, lbs, ubs)
生成个体:
toolbox.individual()
# 结果:
#[93.19512323757041,
# 38.391863981234835,
# 40.57660906070499,
# 31.899218074010903,
# 30.20060853399646]
评价函数 -- 死亡惩罚
# 评价函数
def himmelblauFun(ind):
return (5.3578547*ind[2]*ind[2]+0.8356891*ind[0]*ind[4]+37.293239*ind[0]-40792.141),
# 施加约束
def feasible(ind):
# 判定解是否可行
g1 = 85.334407+0.0056858*ind[1]*ind[4]+0.00026*ind[0]*ind[3]-0.0022053*ind[2]*ind[4]
g2 = 80.51249+0.0071317*ind[1]*ind[4]+0.0029955*ind[0]*ind[1]+0.0021813*ind[2]*ind[2]
g3 = 9.300961+0.0047026*ind[2]*ind[4]+0.0012547*ind[0]*ind[2]+0.0019085*ind[2]*ind[3]
cond1 = (g1 >= 0) and (g1 <= 92)
cond2 = (g2 >= 90) and (g2 <= 110)
cond3 = (g3 >= 20) and (g3 <= 25)
if cond1 and cond2 and cond3:
return True
return False
# 注册评价函数
toolbox.register('evaluate', himmelblauFun)
toolbox.decorate('evaluate', tools.DeltaPenalty(feasible, 1e3)) # death penalty
评价函数 -- 静态惩罚
# 评价函数
def himmelblauFun_StaticCons(ind):
return (5.3578547*ind[2]*ind[2]+0.8356891*ind[0]*ind[4]+37.293239*ind[0]-40792.141+1000*StaticCons(ind)),
# 施加约束
def StaticCons(ind):
# 求解惩罚函数
g1 = 85.334407+0.0056858*ind[1]*ind[4]+0.00026*ind[0]*ind[3]-0.0022053*ind[2]*ind[4]
g2 = 80.51249+0.0071317*ind[1]*ind[4]+0.0029955*ind[0]*ind[1]+0.0021813*ind[2]*ind[2]
g3 = 9.300961+0.0047026*ind[2]*ind[4]+0.0012547*ind[0]*ind[2]+0.0019085*ind[2]*ind[3]
cons = np.array([-g1, g1-92, -g2 + 90, g2 - 110, -g3 + 20, g3 - 25])
coefs = np.where(cons > 0, 1, 0) # Heaviside Function
return np.sqrt(np.sum(coefs * np.square(cons)))
## 注册工具,评价,选择,交叉和突变
toolbox.register('evaluate', himmelblauFun_StaticCons)
计算结果
用DEAP自带的eaSimple,选择方法为size为2的锦标赛选择,交叉方法为eta设置为1的SBX,突变方法为eta设置为1的多项式突变,设定参数为交叉概率0.8,突变概率0.005,迭代200代。
用死亡惩罚施加约束的迭代过程:
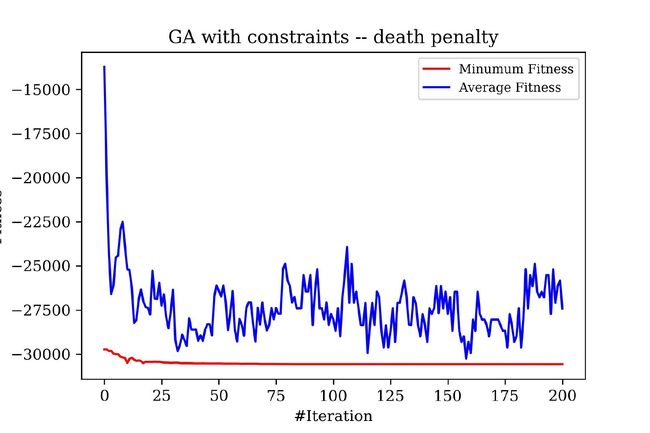
得到的解为:
最优解为:[78.00000731273633, 38.48845011594168, 30.63533574187458, 44.99999295025696, 35.1910465634886]
最小函数值为:(-30560.909364277628,)
用静态惩罚施加约束的迭代过程:
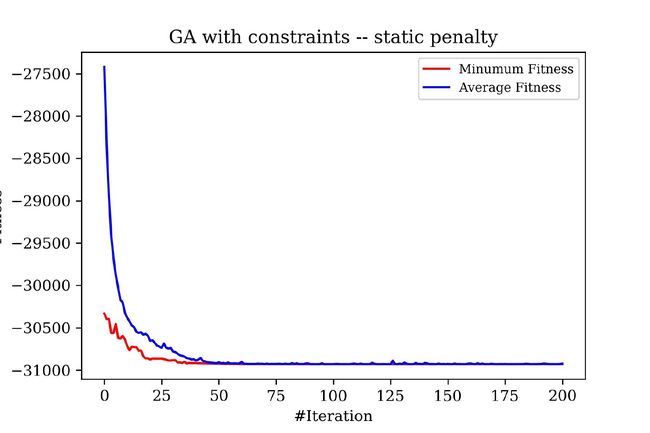
得到的解为:
最优解为:[78.00000000012348, 34.11212342755739, 28.022462847734758, 44.99999999189595, 42.11566726210167]
最小函数值为:(-30930.710699844665,)
可以看到,死亡惩罚在迭代过程中,均值震荡较为厉害,而静态惩罚则很快就达到了收敛;并且后者得到的解质量也更优。