用Python实现一个面向主题的网络爬虫程序,并完成以下内容:
(注:每人一题,主题内容自选,所有设计内容与源代码需提交到博客园平台)
一、主题式网络爬虫设计方案(15分)
1.主题式网络爬虫名称
爬取智联招聘网站的厦门地区java工程师的招聘
2.主题式网络爬虫爬取的内容与数据特征分析
爬取的内容涉及如下:公司所在的地点、公司名称、公司规模和类型(民营,上市公司,股份制企,国企……),岗位职责,技能要求,薪资,工作经验要求以及学历要求。
数据特征分析:对薪资分布,学历要求,工作经验做成相关数据透视表,即为薪资分布饼状图和柱状图,学历要求饼状图和折线图工作经验柱状图,以及学历_薪资的分布图
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
执行爬虫项目过程中有时返回的不是HTML页面而是json数据格式,
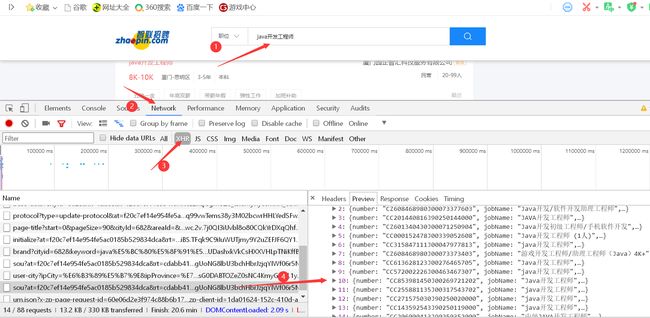
(1)打开浏览器,输入智联招聘关键字,登录进去才可以搜索相关职位
(2)f12打开调试者工具,f5刷新。
(3)点击下一页发现浏览器网址栏没有变化,所以判断可能是异步加载,
去调试者工具中点击xhr,在其中发现携带网页内容的json数据。查看该调数据的请求头,
(4)找到真正json数据的网址。点击下一页,发现该网址的结构只有start参数呈现90步长的变动,因为使用for循环即可实现url的构造。
(5)接下来使用requests请求网址,然后从响应的json数据中取出目标数据存入csv文件即可
二、主题页面的结构特征分析(15分)
1.主题页面的结构特征

2.Htmls页面解析
智联招聘上的网页由于是异步加载,直接请求是没有数据的,所以在页面上通过鼠标右击查看页面源代码可以得到HTML页面解析
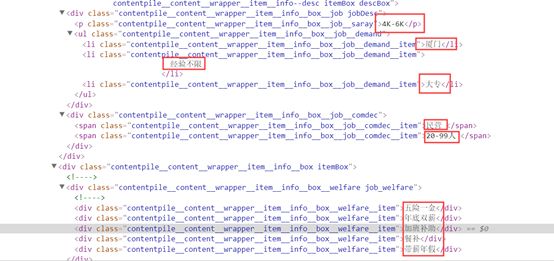
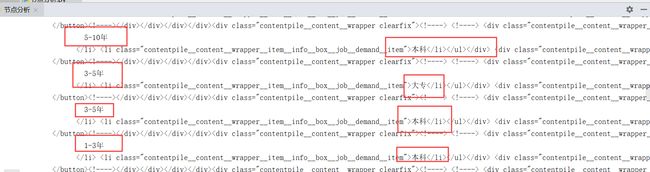
3.节点(标签)查找方法与遍历方法(必要时画出节点树结构)
网页由于是异步加载,直接请求是没有数据的,所以通过:selenium库把整个网页下载下来,进行节点分析。selenium 是一个用于Web应用程序测试的工具

三、网络爬虫程序设计(60分)
爬虫程序主体要包括以下各部分,要附源代码及较详细注释,并在每部分程序后面提供输出结果的截图。
1.数据爬取与采集(完整代码)
1 # -*- coding: utf-8 -*- 2 # @Author :LMD 3 # @FILE : 智联招聘.py 4 # @Time : 2019/12/1 15:35 5 # @Software : PyCharm 6 import requests 7 import time 8 import random 9 import csv 10 import codecs 11 import json 12 13 def get_json_content(url,headers,writer): 14 #模拟浏览器发送请求: 15 rq = requests.get(url, headers=headers) 16 #设置随机休眠:不然爬取速度过快,会被封IP 17 time.sleep(random.choice(range(1,3))) 18 #取出json数据 19 rq_json=rq.json()['data']['results'] 20 #取出的json格式数据是列表,循环取出 21 for i in rq_json: 22 # pprint(i) 23 #工作名称 24 jobName=i['jobName'] 25 print(jobName) 26 #城市 27 try: 28 city=i['city']['display'] 29 except: 30 city='暂无' 31 print(city) 32 #工作经验 33 try: 34 workingExp=i['workingExp']['name'] 35 except: 36 workingExp='暂无' 37 print(workingExp) 38 #学历 39 try: 40 eduLevel=i['eduLevel']['name'] 41 except: 42 eduLevel='暂无' 43 print(eduLevel) 44 #薪资 45 salary=i['salary'] 46 print(salary) 47 #工作类型 48 try: 49 jobType=i['jobType']['items'][0]['name'] 50 except: 51 jobType='暂无' 52 print(jobType) 53 #雇主印象 54 try: 55 bestEmployerLabel_list=i['bestEmployerLabel'] 56 #定义一个空列表 57 bestEmployerLabels=[] 58 #取出的bestEmployerLabel_list是列表,循环取出其包裹的字典,并取value值 59 for x in bestEmployerLabel_list: 60 state_velue=x['value'] 61 #将取出的值依次添加到定义的列表中 62 bestEmployerLabels.append(state_velue) 63 #列表转字符,并用,分隔 64 bestEmployerLabel=','.join(bestEmployerLabels) 65 if len(bestEmployerLabel)==0: 66 bestEmployerLabel = '暂无' 67 except: 68 bestEmployerLabel='暂无' 69 print(bestEmployerLabel) 70 #公司名称 71 company=i['company']['name'] 72 print(company) 73 #公司规模 74 try: 75 company_size=i['company']['size']['name'] 76 except: 77 company_size='暂无' 78 print(company_size) 79 #公司类型 80 try: 81 company_type=i['company']['type']['name'] 82 except: 83 company_type='暂无' 84 print(company_type) 85 #任职类型 86 emplType=i['emplType'] 87 print(emplType) 88 #职位亮点 89 welfare=','.join(i['welfare']) 90 print(welfare) 91 #招聘现状 92 timeState=i['timeState'] 93 print(timeState) 94 #更新时间 95 updateDate=i['updateDate'] 96 print(updateDate) 97 #技能要求标签 98 try: 99 skillLabel_lists=i['positionLabel'] 100 #取出的是str类型,使用json.loads()转json类型 101 skillLabel_list=json.loads(skillLabel_lists)['skillLabel'] 102 # 定义一个空列表 103 skillLabels=[] 104 #循环该列表,并取值 105 for y in skillLabel_list: 106 sat_v=y['value'] 107 # 将取出的值依次添加到定义的列表中 108 skillLabels.append(sat_v) 109 # 列表转字符,并用,分隔 110 skillLabel=','.join(skillLabels) 111 if len(skillLabel)==0: 112 skillLabel = '暂无' 113 except: 114 skillLabel='暂无' 115 print(skillLabel) 116 #详情页链接 117 positionURL=i['positionURL'] 118 print(positionURL) 119 #将各个字段存入csv 120 writer.writerow([jobName,city,workingExp,eduLevel,salary,jobType,bestEmployerLabel,company,company_size,company_type, 121 emplType,welfare,timeState,updateDate,skillLabel,positionURL]) 122 print('*' * 50) 123 #关闭csv文件 124 fp.close() 125 126 127 128 if __name__=='__main__': 129 # 第一次打开,为了防止在windows下直接打开csv文件出现乱码,指定编码 130 with open("data.csv", "ab+") as fp: 131 fp.write(codecs.BOM_UTF8) 132 # 中文需要指定编码,'a+',表示在后面添加新数据,不覆盖。newline=''去除csv文件后面的空行 133 fq = open('data.csv', 'a+', newline='', encoding='utf-8') 134 #定义writer 135 writer = csv.writer(fq) 136 #第一行写入标题 137 writer.writerow(['工作名称', '城市', '工作经验', '学历', '薪资', '工作类型', '雇主印象', '公司名称', '公司规模', '公司类型', '任职类型', '职位亮点','招聘现状', '更新时间', '技能要求', '详情链接']) 138 # 总共5页 139 for offset in range(6): 140 page=90*offset 141 #构建请求头 142 headers = { 143 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36', 144 } 145 #构建url,start= ,这里改变,即可实现翻页start=0是第一页,start=90是第二页,以此类推 146 url='https://fe-api.zhaopin.com/c/i/sou?start={}&pageSize=90&cityId=682&salary=0,0&workExperience=-1&education=-1&companyType=-1&employmentType=-1&jobWelfareTag=-1&kw=java开发工程师&kt=3'.format(str(page)) 147 #运行get_json_content函数 148 get_json_content(url,headers,writer)
程序运行结果如下:
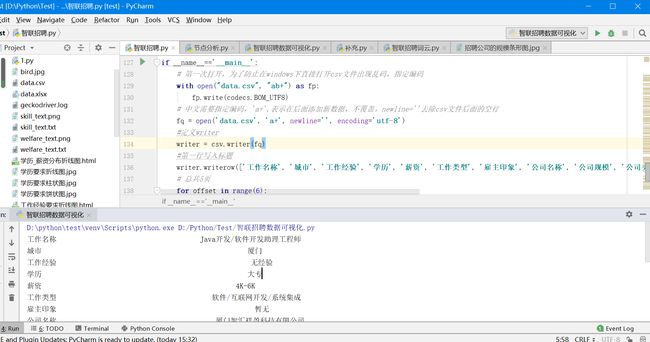
爬取出来的数据存为CSV文件(data.csv)
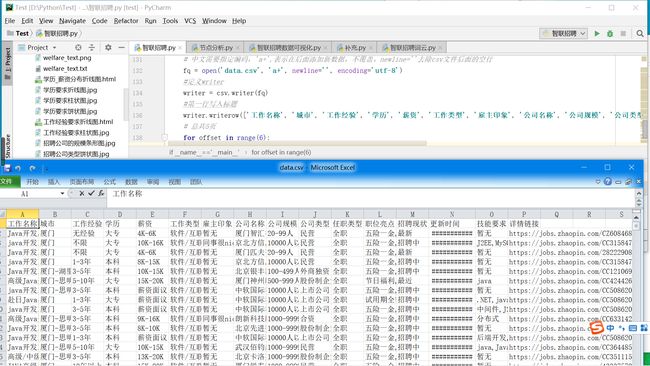
2.对数据进行清洗和处理
import pandas as pd import csv df=pd.read_csv('C:/Users/LMD/CSVFile/data.csv', encoding='utf-8') df.head()#查询数据前五条
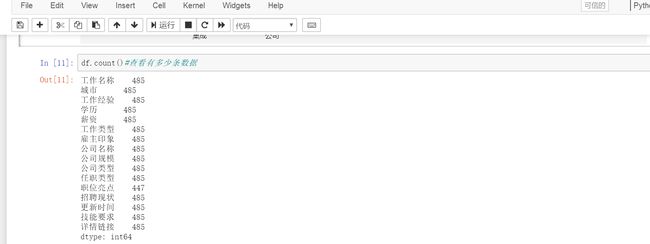
df.count()#再查看数据量
df.duplicated()#查看文件中的重复值 df=df.drop_duplicates()#去掉文件中的重复值 df.count()#再查看数据量


3.文本分析(可选):jieba分词、wordcloud可视化
(1)待遇--分词

(2)技能--分词

4.数据分析与可视化
(例如:数据柱形图、直方图、散点图、盒图、分布图、数据回归分析等)
先导要用到的模块
import pandas as pd #数据框操作 import matplotlib.pyplot as plt #绘图 import matplotlib as mpl #配置字体 from pyecharts.charts import Pie,Grid from pyecharts.faker import Faker from pyecharts import options as opts from pyecharts.charts import Bar from pyecharts.charts import Line import numpy as np from pyecharts.globals import ThemeType
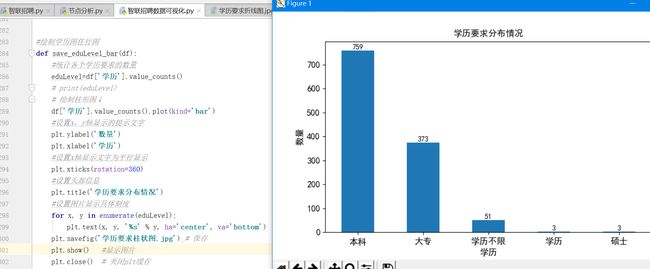
4.1学历柱状图
1 def sava_bar(): 2 mpl.rcParams['font.sans-serif'] = ['SimHei'] #这个是绘图格式,不写这个的话横坐标无法变成我们要的内容 3 #配置绘图风格 4 #设置x,y轴提示文字大小 5 plt.rcParams['axes.labelsize'] = 12. 6 # 设置x,y轴坐标文字大小 7 plt.rcParams['xtick.labelsize'] = 12. 8 plt.rcParams['ytick.labelsize'] = 12. 9 plt.rcParams['legend.fontsize'] =10. 10 #设置图片800*800大小 11 plt.rcParams['figure.figsize'] = [8.,8.] 12 #读取数据的CSV文件 13 df = pd.read_csv('data.csv') 14 #查看第一行 15 cow1=df.loc[0] 16 print(cow1) 17 #选择运行的函数 18 save_eduLevel_bar(df) 19 save_workingExp_bar(df) 20 save_compay_type_pie(df) 21 save_salary_pie(df) 22 save_company_size_barh(df) 23 save_zx(df) 24 save_jingy(df) 25 def save_eduLevel_bar(df): 26 #统计各个学历要求的数量 27 eduLevel=df['学历'].value_counts() 28 # print(eduLevel) 29 # 绘制柱形图↓ 30 df['学历'].value_counts().plot(kind='bar') 31 #设置x,y轴显示的提示文字 32 plt.ylabel('数量') 33 plt.xlabel('学历') 34 #设置x轴显示文字为平行显示 35 plt.xticks(rotation=360) 36 #设置头部信息 37 plt.title('学历要求分布情况') 38 #设置图片显示具体刻度 39 for x, y in enumerate(eduLevel): 40 plt.text(x, y, '%s' % y, ha='center', va='bottom') 41 plt.savefig('学历要求柱状图.jpg') # 保存 42 plt.show() #显示图片 43 plt.close() # 关闭plt缓存 44 if __name__=='__main__': 45 sava_bar()
4.2经验柱状图
1 def save_workingExp_bar(df): 2 # 统计各个工作经验的数量 3 workingExp = df['工作经验'].value_counts() 4 # 绘制柱形图↓ 5 df['工作经验'].value_counts().plot(kind='bar') 6 # 设置x,y轴显示的提示文字 7 plt.ylabel('数量') 8 plt.xlabel('工作经验') 9 # 设置x轴显示文字为平行显示 10 plt.xticks(rotation=360) 11 # 设置头部信息 12 plt.title('工作经验要求分布情况') 13 # 设置图片显示具体刻度 14 for x, y in enumerate(workingExp): 15 plt.text(x, y, '%s' % y, ha='center', va='bottom') 16 plt.savefig('工作经验要求柱状图.jpg') 17 plt.show() #显示图片 18 plt.close()
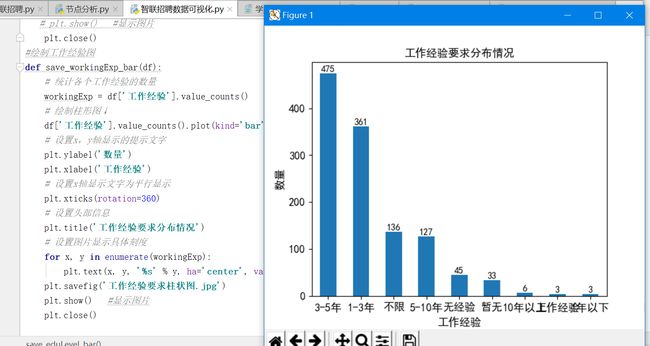
4.3学历与工资的关系
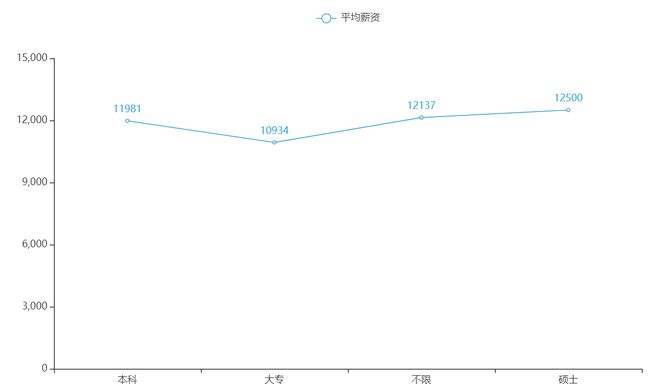
1 def benk(df): 2 #取学历是本科的数据,赋值给df1 3 df1=df[(df['学历'] == '本科')] 4 #取所有学历是本科的薪资,并转换成列表 5 benke=df1['薪资'].tolist() 6 avg_bs=[] 7 for x in benke: 8 #薪资面议的是字符串,无法计算,排除 9 if x=='薪资面议': 10 pass 11 else: 12 #薪资去掉K,变成3-5,然后用split分隔,变成['3','5'] 13 #然后去最低值和最高值 14 benke_num1=float(x.replace('K','').split('-')[0])*1000 15 benke_num2=float(x.replace('K','').split('-')[1])*1000 16 #相加除以二,求平均 17 avg_b=(benke_num1+benke_num2)/2 18 #将平均值依次添加到表内 19 avg_bs.append(avg_b) 20 #计算列表内元素的总和 21 sum_avg_bs=sum(avg_bs) 22 #计算列表内元素的个数 23 len_avg_bs=len(avg_bs) 24 #计算列表元素的平均值,该值就是所有本科学历的平均薪资 25 avg_benke=sum_avg_bs/len_avg_bs 26 return avg_benke 27 #学历为硕士,大专,不限的逻辑代码块上面一样# 28 def save_zx(df): 29 benke=benk(df)#本科 30 zhuanke=zhuank(df)#专科 31 buxin=buxian(df)#学历不限 32 shuoshi=suoshi(df)#硕士 33 xueli_list=['本科','大专','不限','硕士'] 34 xinzi_list=[int(benke),int(zhuanke),int(buxin),int(shuoshi)] 35 # 使用pyecharts绘制饼状图 36 bar = Line(init_opts=opts.InitOpts(theme=ThemeType.LIGHT)) 37 bar.add_xaxis(xueli_list) 38 bar.add_yaxis("平均薪资", xinzi_list) 39 # 不显示数据 40 # bar.add_yaxis("A", v1,label_opts=opts.LabelOpts(is_show=False)) 41 bar.render('学历_薪资分布折线图.html')
学历_薪资折线图
4.4经验和工资的关系
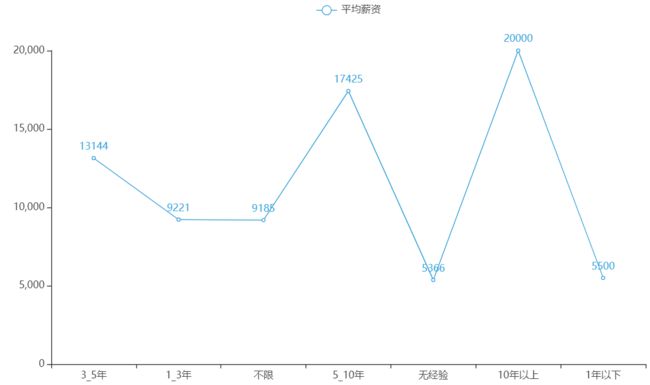
1 def s_w(df): 2 df1 = df[(df['工作经验'] == '3-5年')] 3 benke = df1['薪资'].tolist() 4 avg_bs = [] 5 for x in benke: 6 if x == '薪资面议': 7 pass 8 else: 9 benke_num1 = float(x.replace('K', '').split('-')[0]) * 1000 10 benke_num2 = float(x.replace('K', '').split('-')[1]) * 1000 11 avg_b = (benke_num1 + benke_num2) / 2 12 avg_bs.append(avg_b) 13 sum_avg_bs = sum(avg_bs) 14 len_avg_bs = len(avg_bs) 15 avg_benke = sum_avg_bs / len_avg_bs 16 return avg_benke 17 18 def save_jingy(df): 19 san_wu = s_w(df) #3-5工作经验 20 yi_san = y_s(df) #一年工作经验 21 buxian = b_x(df) #工作经验不限 22 wu_shi = w_s(df) #5-10年的工作经验 23 wu = w(df) #5年工作经验 24 shi = s(df) #10年工作经验 25 yi = y(df) #一年工作经验 26 xueli_list = ['3_5年', '1_3年', '不限', '5_10年', '无经验', '10年以上', '1年以下'] 27 xinzi_list = [int(san_wu), int(yi_san), int(buxian), int(wu_shi), int(wu), int(shi), int(yi)] 28 # 使用pyecharts绘制饼状图 29 bar = Line(init_opts=opts.InitOpts(theme=ThemeType.LIGHT)) 30 bar.add_xaxis(xueli_list) 31 bar.add_yaxis("平均薪资", xinzi_list) 32 # 不显示数据 33 # bar.add_yaxis("A", v1,label_opts=opts.LabelOpts(is_show=False)) 34 bar.render('经验_薪资分布折线图.html')
经验_薪资折线图
5.数据持久化
#将各个字段存入csv writer.writerow([jobName,city,workingExp,eduLevel,salary,jobType,bestEmployerLabel,company,company_size,company_type, emplType,welfare,timeState,updateDate,skillLabel,positionURL]) print('*' * 50) #关闭csv文件 fp.close()

6.附完整程序代码(完整代码在本题第一小题)
四、结论(10分)
1.经过对主题数据的分析与可视化,可以得到哪些结论?
厦门地区招聘java工程师的需求还是不少的。这个职位对各个学历要求都有涉及,然而最重要的是经验要求,经验年限越高,工资就越高。对比学历的要求,大部分公司要求是本科,对比学历_薪资折线图,本科和大专的薪资相差不是很大。所以最重要的还是工作经验
2.对本次程序设计任务完成的情况做一个简单的小结。
遇到了很多问题,比如第一次爬取智联招聘网站时怎么爬取不到数据,都是乱码的一堆英文符号。然后各种百度询问他人,原来网页是异步加载,模拟ajax请求,找到了它的json格式的数据url,而且使用这种url也省时省力。还有就是导入模块的问题,有时候明明已经导入模块,jupyter运行的时却出现找不到模块的问题。最后用PyCharm(这个导入模块很方便)可以运行。最后克服了很多困难,学到很多使用爬虫库的方法,自己又进步了许多。