LeetCode -- 6. ZigZag Conversion
题目描述
The string "PAYPALISHIRING" is written in a zigzag pattern on a given number of rows like this: (you may want to display this pattern in a fixed font for better legibility)
P A H N
A P L S I I G
Y I RAnd then read line by line: "PAHNAPLSIIGYIR"
Write the code that will take a string and make this conversion given a number of rows:string convert(string text, int nRows);
convert("PAYPALISHIRING", 3)should return"PAHNAPLSIIGYIR".
题意解析
题目的大致意思是将给定的原字符串"PAYPALISHIRING"通过一个** 给定的行数 携程如下这中 Z型模式: **
P A H N
A P L S I I G
Y I R
然后一行一行的读取:“PAHNAPLSIIGYIR”
写代码读入一个字符串并通过给定的行数进行这个转换:
string convert(string text, int nRows);
调用convert("PAYPALISHIRING",3),应该返回"PAHNAPLSIIGYIR"。
如果还没偶明白题意,我们可以观看下图: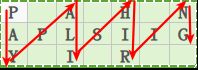
了解完题目的意思后,我们现在就可以开始思考如何用程序实现。
第一种方法
我个人认为比起先说算法思想,不如先贴上算法思想对应的算法代码,这样你看完之后,可能不需要看算法思想就立马明白了怎么回事,即使不明白,带着问题去看算法思路,也是比较好的一种学习方法。
算法实现
public static String convert_easy_understand(String s, int nRows) {
// 将字符串转换成字符数组,便于取出制定位置字符
char c[] = s.toCharArray();
// 字符串长度
int len = c.length;
// 建立长度为nRows的字符串数组,以nRows=4为例
StringBuffer sb[] = new StringBuffer[nRows];
// 按照ZigZag模式排列,总共有四行,可以看下图,
// 每一行用一个字符串存储,最后四个字符串按照顺序输出既是答案
for (int i = 0; i < nRows; i++) {
sb[i] = new StringBuffer();
}
// 用变量 i 表示现在应该取出字符数组中的第几个字符
int i = 0;
while (i < len) {
// 字符串索引j值从0开始,即从首行开始,那么索引值每次加1
for (int j = 0; j < nRows && i < len; j++) {
sb[j].append(c[i++]);
}
// 字符串索引j值从nRows=n-2开始,即从倒数第二行开始,那么索引值每次减1
for (int j = nRows - 2; j >= 1 && i < len; j--) {
sb[j].append(c[i++]);
}
}
// 将四个字符串按照顺序连接成一个字符串
for (int j = 1; j < sb.length; j++) {
sb[0].append(sb[j]);
}
return sb[0].toString();
}
算法思想
我们现将原字符串转换成字符数组c[]={ 'P' ,'A' ,'Y' ,'P' ,'A' ,'L' ,'I' ,'S' ,'H' ,'I' ,'R' ,'I' ,'N' ,'G' };以nRows=4为例,那么按照** "ZigZag" **的排序规则,如下图:
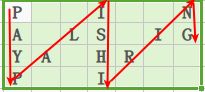
如上图,总共四行,那么我们可以先建一个长度为nRows=4的字符串数组:
// 建立长度为nRows的字符串数组,以nRows=4为例
StringBuffer sb[] = new StringBuffer[nRows];
// 按照ZigZag模式排列,总共有四行,可以看下图,
// 每一行用一个字符串存储,最后四个字符串按照顺序输出既是答案
for (int i = 0; i < nRows; i++) {
sb[i] = new StringBuffer();
}
sb[0]存储第一行字符,即sb[0] = { "P" ,"I" ,"N" };sb[1]存储第二行字符,即sb[1] = { "A" ,"L" ,"S" ,"I" ,"G" };sb[2]存储第三行字符,即sb[2] = { "Y" ,"A" ,"H" ,"R" };sb[3]存储第四行字符,即sb[3] = { "P" ,"I" }。
我们一共有四个字符串,sb[0] ,sb[1] ,sb[2] ,sb[3],最终所有的字符会分别归属为上面四个字符串。那么我们按照上图中箭头的顺序依次检索原字符串中的字符,那么按照字符的归属字符串顺序为:sb[0] ,sb[1] ,sb[2] ,sb[3] ,sb[2] ,sb[1] ,sb[0] ,sb[1] ,sb[2] ,sb[3] ....... 。
如果 nRows=n时,即:sb[0] ,sb[1] , .... ,sb[n-1] ,sb[n-2] ,sb[n-3] , ..... ,sb[1] ,sb[0] ,sb[1] ......, 即字符串索引为首行时,每次循换字符串索引+1,当字符串索引到了最后一行时,即索引值为nRows=n-1时,字符串索引每次循环再减1.
代码实现为:
// 用变量 i 表示现在应该取出字符数组中的第几个字符
int i = 0;
while (i < len) {
// 字符串索引j值从0开始,即从首行开始,那么索引值每次加1
for (int j = 0; j < nRows && i < len; j++) {
sb[j].append(c[i++]);
}
// 字符串索引j值从nRows-2开始,即从倒数第一行开始,那么索引值每次减1
for (int j = nRows - 2; j >= 1 && i < len; j--) {
sb[j].append(c[i++]);
}
}
所以经过以上算法,字符串中的所有字符就分别在sb[0],sb[1],sb[2],sb[3]中了,下面我们只需将这个四个字符串按照顺序连接成一个字符串,该字符串就是我们所求字符串,程序如下:
// 将四个字符串按照顺序连接成一个字符串
for (int j = 1; j < sb.length; j++) {
sb[0].append(sb[j]);
}
return sb[0].toString();
第二种方法
第二种方法与第一种方法算法思路一样,只是实现起来有点不同,现在提供代码,自行参考。
算法实现
public static String convert_Three(String s, int numRows) {
if (numRows <= 1) return s;
StringBuilder[] sb = new StringBuilder[numRows];
for (int i = 0; i < sb.length; i++) {
sb[i] = new StringBuilder(""); //init every sb element **important step!!!!
}
int incre = 1;
int index = 0;
for (int i = 0; i < s.length(); i++) {
sb[index].append(s.charAt(i));
// 当为首行时,index应该是递加,每次加1
if (index == 0) {
incre = 1;
}
// 当为最后一行时,index应该每次减1
if (index == numRows - 1) {
incre = -1;
}
index += incre;
}
String re = "";
for (int i = 0; i < sb.length; i++) {
re += sb[i];
}
return re.toString();
}
第三种方法
第三种方法我先把算法思路写在前面是因为,相比较第一种方法,第三种方法看一遍后如果不自己动手演算,无法明白为什么这样实现,所以我先把算法思路写在前面,这样看算法时会比较轻松。
算法思路
下面我们以nRows=4为例,当nRows=4时,原字符串“Z型模式”如下图:
然后一行一行的读取:“PAHNAPLSIIGYIR”,那么我们现在来探讨每一行相邻字符在原字符串中的位置关系:
- 第0行:0 6 12
- 第1行:1 5 7 11 13
- 第2行:2 4 8 10
- 第3行:3 9
第0行和第3行中每行相邻字符的位置差为(4-1)2*
第1行相邻字符位置差为(4-1-1)2、12、(4-1-1)2、12,即按照(4-1-1)2、12**位置差规律进行排序;
第2行相邻字符位置差为(4-2-1)2、22、(4-2-1)2、22,即按照(4-2-1)2、22**位置差规律进行排序;
那么我们可以观察出规律第0行和第3行每行相邻字符位置差可以写成(4-0-1)2、02、(4-0-1)2、02,即按照(4-0-1)2、02**的位置差规律进行排序,那我们可以总结出以下的规律:
以字母 i记为当前为第几行,那么我们就可以总结出每行字符排列的规律:(nRows - i - 1) * 2、i * 2交叉排序
所以设置两个变量step1、step2分别用来表示(nRows - i - 1) * 2、i * 2,所以程序代码如下:
int step1, step2;
int len = s.length();
// 字符串按照每行进行处理
for (int i = 0; i < nRows; ++i) {
step1 = (nRows - i - 1) * 2;
step2 = (i) * 2;
// pos用来表示每行字符位置
int pos = i;
// 处理每行第一个字符
if (pos < len)
result += c[pos];
// 处理每行除了第一个字符外的所有字符
while (true) {
pos += step1;
if (pos >= len)
break;
// 该条件是为了防止将同一个位置的字符添加两次
if (step1 != 0)
result += c[pos];
pos += step2;
if (pos >= len)
break;
// 该条件是为了防止将同一个位置的字符添加两次
if (step2 != 0)
result += c[pos];
}
}
return result;
如果还不是太懂,自己可在纸上按照程序步骤亲自动手演算一遍,这样你就能很清楚的了解算法思路。
算法实现
public static String convert_Two(String s, int nRows) {
String result = "";
// 将字符串转换成字符数组,便于取出制定位置字符
char c[] = s.toCharArray();
// 如果行数只为1,那么就是原字符串
if (nRows == 1)
return s;
int step1, step2;
int len = s.length();
// 字符串按照每行进行处理
for (int i = 0; i < nRows; ++i) {
step1 = (nRows - i - 1) * 2;
step2 = (i) * 2;
int pos = i;
// 处理每行第一个字符
if (pos < len)
result += c[pos];
// 处理每行除了第一个字符外的所有字符
while (true) {
pos += step1;
if (pos >= len)
break;
if (step1 != 0)
result += c[pos];
pos += step2;
if (pos >= len)
break;
if (step2 != 0)
result += c[pos];
}
}
return result;
}
总结
我尽量做完一道算法题,都将自己的实现的还有一些别人实现的,也是比较好的算法给记录下来,对自己也算一种锻炼,如果还能帮助别人那是再好不过了,如有错误,或者描述不当之处请谅解,语言组织能力不太好,一些算法思想可能不能很好的描述出来,如果有什么差错的地方,欢迎大家指正!