Hello everyone, it's been a while not updating my papers, cause I have changed my jobs from automated trading to data mining. But no matter what, the challenges and oppotunities are always in the first place. The first project I completed is about labeling behavior attributes of medicine consumers.
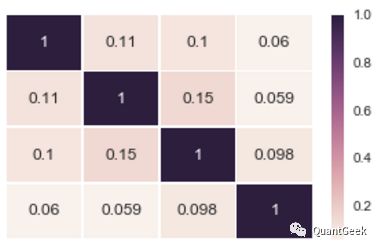
The original data are the receipts, which are unconstructed. So we need to extract useful data to establish constructed database. Then we have to build our features based on the understanding of business. For instance, the original constructed data fieild contains like orderNo(订单号), card ID(会员号), buy date, sex, age, pay money(订单金额), count(购买数量), product name, per customer transaction(客单价), per customer consumption(客品数), company of product, ATC(ATC四级分类), approval(国药准字号) and etc. Then we extract features to denote higher level labels, like loyalty, consuming capacity, health consciousness, activity(活跃度), season consumption distribution, medicine preference(for disease prediction of customers), user value(for precision market) and so on. And the features of each higher level labels should not be relevant, we can use seaborn to draw heatmap for observation.
After validating the rationality of those clusters, then we can put the models into practical use.
The process we using fundamental data to build something denoted higher level labels(attributes), is called feature engineering, which is most critical and involves business privacy. So this paper just for recording my working experience. Well, let's begin.
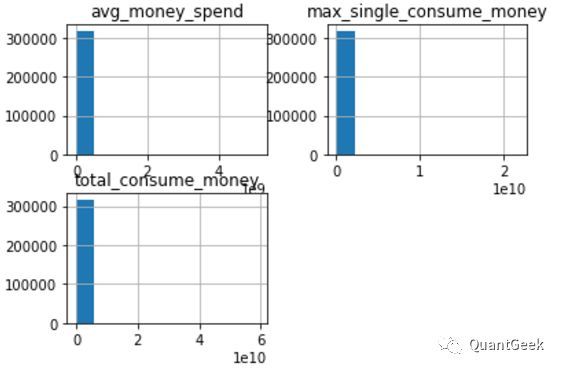
Firstly, data procssing, I think this step is the most time-wasting, and second in importance only to feature engineering. Cause you will confront many issues like default, redundancy, error logic data, error type data, outliers detection, data transformation(like logarithmic processing) and etc. And different dealing methods will be used under different business senario. For example, there are some ditributions below, extremely unbalanced, with long-tail.
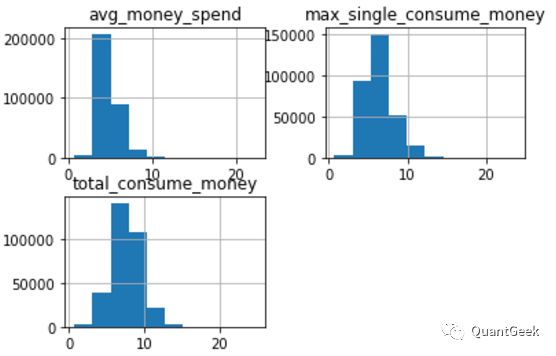
Then we need to make it from non-normal distribution to normal or close to normal distribution, which has better statistical attributes and fulfills the basic hypothesis of some clustering algorithms like k-means. So I did log-transformation, then looks like left-skewed normal distribution. Also you can do sqrt-transform, reciprocal-transform or inverse trigonometric transform.
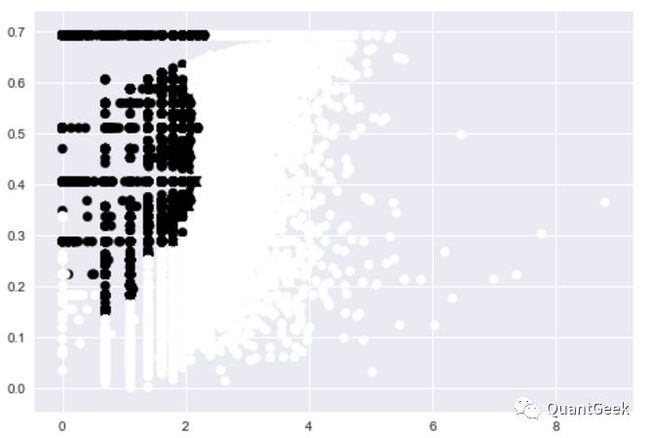
As for outlier detection, you can use non machine-learning method like quartile detection, n-fold-sigma criterion. If you have clear definitions of outiers from business perspective, I think it would be better and time-saving to use non train-needed method. As for train-needed methods, I preferredIsolation Forest(abbr. IFrorest). When using this method, you could just use "pure" data(without outliers) as training set, which would not affect the result in test set. This process is calledNovelty Detection, it is often used when our outliers are very little(like spam). Sklearn has embeded IForest, we can use it directly. The result do not look so good. No matter what kind of training set(pure or impure) I build, all performed bad. There are nearly 320 thousand data, with 280 thousand inliers and 40 thousand outliers after IForest detection. The pics below informs that black points denote inliers and white points denote outliers. Therefore, most outliers detection is based on understanding of pratical senarios.
After preparing data set, then we can do some training for fun. K-means, Mini-batch-Kmeans, Birch, MeanShift, GaussianMixture(GMM), whatever you like, just try. However I do not suggest you just use one of that for pratical use. I imitate Adaboost rationale, use muti-clustering methods as weak clustering(this method will not be performed here). Or we can use MeanShfit which do not need to designate specific number of clusters, to combine with those methods need to set up the number of clusters. For example, we could use MeanShfit firstly, to find out cluster points without assginment of cluster count(here is 10).
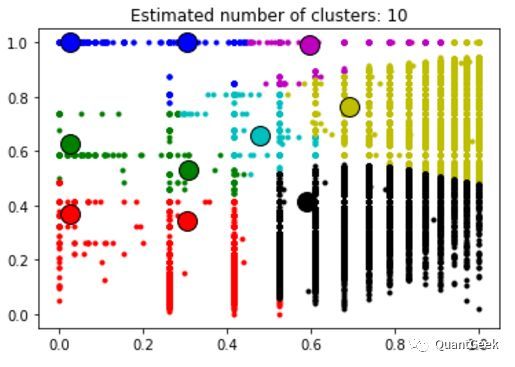
Then utilize those cluster points as input for K-means or GaussainMixture, and designate the cluster number we need.
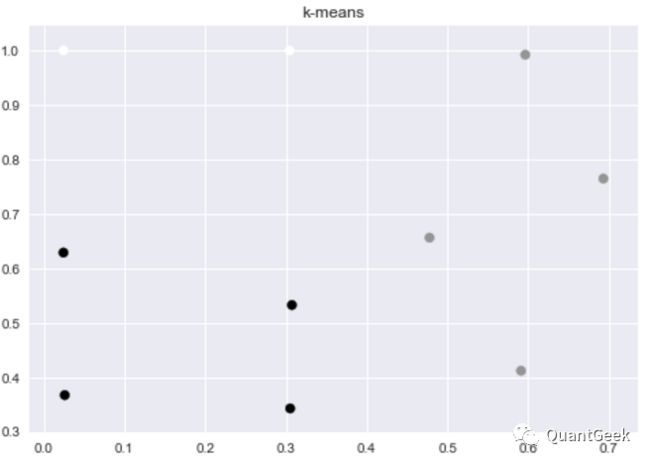
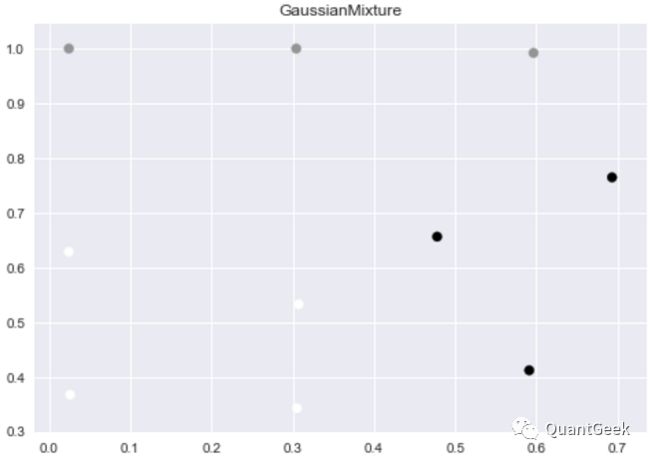
Eventually, the clustering result looks like below:

We still can not confirm whether the result is good or not. For instance, this label contains 3 features, and we need to build up 3 clusters denoting "High", "Median", "Low" respectively. And according to those features, we create 3 clusters, but still we do not ensure which represents "High", "Median" or "Low". Here, I give 3 features weights from business considering, and calculating 3 clusters final "score". If the "scores" are apperantly different from each others, then I can ensure the whole features and methods we use are pratical.