Zookeeper 作为分布式协调框架,在实际生产中有着不可替代的位置,它作为管理框架,大多数时间是不需要我们去维护的。也正是由于它是协调全局的管理者,所以它的一些内部原理我们还是要了解的。
今天我们就从以下几个方面,来深入探讨下 ZK 的工作原理:
-
攘外 :Zookeeper 的读写过程
-
安内 : 集群 leader 选举方式
-
图解攘外安内背后的 ZAB 算法
-
ZK 状态同步
-
ZK 分布式锁的应用
01 攘外: 图说 ZK 的读写过程
-
写过程:
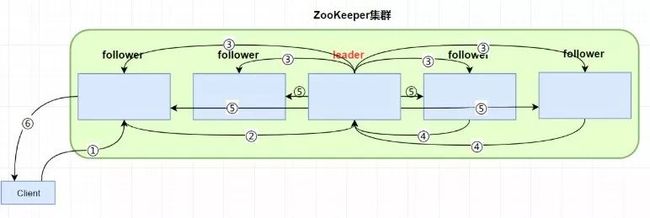
1 客户端向 zk 集群写入数据,如 create /dsjjh ;与一个 follower 建立 session 连接,连接的是 从节点 follower 01
2 从节点 follower 01 将写请求转发给 leader
3 leader收到消息发出 proposal 提案(创建 /dsjjh)到每个 follower ,每个 follower 记录下要创建 /dsjjh
4 超过半数 quorum(参与者,包括 leader 自己)同意提案,则leader commit提案,leader本地先创建 /dsjjh节点
5 leader 通知所有 follower 也 commit 提案,follower 在本地创建 /dsjjh
6 follower 01 响应 client
-
读过程:
读过程比较简单,过程如下:
1 客户端先与某个 ZK 服务器建立 Session
2 然后 直接从此 ZK 服务器读取数据,并返回客户端
3 关闭session
02 安内 :图说 ZK 集群 leader选举
zk 服务器共有 4 种状态-- Looking followering leadering observing。
集群 leader 选举 分为 全新集群选举 和 非全新集群选举,这两种方式都遵循内部的选举公式。
Q:
什么是选举公式?
A:
选举公式是 ZK 集群内部选举 leader时 遵循的规则。信息选举的格式为 :vote(sid,zxid),其中sid 为 机器编号,zxid 为事务编号。
选举过程中,先判断 zxid ,再判断 sid ,小编号遵从大编号。
-
全新集群选举
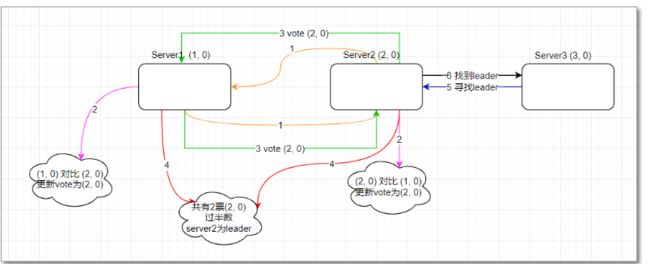
1 server1 启动时 将投票投给自己, 投票信息为 vote(1,0) 没有超过半数
2 server2 启动,server1 投票给自己和其他服务器,server2 投票给自己和其他服务器,server1 收到的自己的投票为 vote(1,0) 和 server2的投票为vote(2,0),server2 收到server1的投票为 vote(1,0) 和 自己的投票 为vote(2,0)
3 处理投票,只能投一票
server1 (1,0)(2,0) --> (2,0)
server2 (1,0) (2,0) --> (2,0)
根据选举公式, zxid相同的,sid大的胜出,server1 和 server2 都保留了 (2,0) 票
4 再次投票选举,server1 和 server2 投票(2,0),投给自己和其他服务器:
server1 有自己的 (2,0)和server2 投票的 (2,0), 两票选举 server2 为leader,server2 有自己的(2,0) 和 server1 投票的 (2,0),两票选举 server2 为leader。
统计投票结果,server1 选举 server2 ,server2选举server2,超过半数 server2 被选举为leader
改变服务器状态,server2由looking改为leadering ,server1由looking改为followering
5 当server3 启动时发现已经有leader ,不再选举 直接从 Looking 改为 following。
-
非全新集群选举
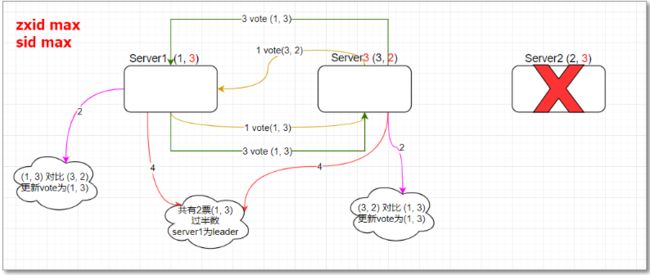
非全新集群选举与全新类似,如图当 server2 挂掉,重新选举
1 server1 投票给自己 和 server3,server3类似
2 server1 票(1,3)(3,2),server3 得票 (1,3)(3,2)
3 根据选举公司处理得票结果
server1 -- (1,3)
server3 -- (1,3)
4 重新选举 server1 投票给自己和server3,server3类似
server1 票 (1,3)(1,3) -- 选举结果为 server1
server3 票 (1,3)(1,3) -- 选举结果为 server1
超过半数选举server1 ,server1 由looking 改为 leadering。
03 图解攘外安内背后的 ZAB 算法
-
ZAB 算法
在看 ZAB 算法前,需要先了解下 仲裁 (quorum) 与 网络分区的相关知识。
quorum (仲裁)
在 leader 发起 proposal 提议时,多数派同意即生效,即半数原则,这就是 仲裁 。
quorum 数选择: (集群节点数/2 )+1 ,只有集群大于等于 quorum 数集群才能正常工作
为什么用 quorum 呢,主要有以下两点:
1 不需要所有服务器都响应结果,多数派响应,提议即生效,如果需要所有服务器都响应结果,一旦出现网络原因,可能会造成大量延迟
2 加快集群响应速度,假设有5台zk服务器,只要其中半数 3台同意提案,就能给客户端响应结果
2 网络分区 、脑裂
网络分区:网络通信故障,集群被分成二个部分
脑裂:出现多leader情况。原leader 在一个分区,新分区由于网络分区,又选举出来一个 leader,从而出现2个leader的情况。
ZAB 算法 与 raft 算法类似,它们之间的差别很小,不同点在于:
ZAB 心跳 从 follower 到 leader,raft 相反
ZAB的任期叫 epoch ,raft 叫 term。
下面以 raft 算法为例,来看看算法的实现过程:
点击 “动态演示”,可查看 raft 算法动态演示过程。
-
raft 算法

图片中 ⚪形状 解释
黑边包围的⚪代表 leader ,有凹边的⚪表示follower ,每个follower 都会倒计时,在倒计时结束前收到 leader 心跳则重新倒计时,若倒计时结束前未收到leader 心跳,则所有follower 开始新一轮leader 选举。
图1 是正常运行的集群,NodeB 为leader (leader最外层是黑圈),集群通过心跳连接
图2 出现网络分区 上面3个节点无法与 下面2个节点通信,由于上面的节点无法通信,在一段时间内没有收到心跳,状态由followeing 变为 looking,开始选举leader
图3 上面三个节点 NodeE 选举为 leader ,同时由于网络分区, 原来的 Node B也是leader, 出现多主的情况
图4 此时一个客户端连接上 NodeB 发送写请求,NodeB 将写请求提案, NodeA 同意提案,由于 此集群 quorum 数为 3,但只有 NodeB、NodeA两台机器同意,所以此次写请求不会被提交;类似的 当另一个客户端连接 NodeE 发送写请求,由于提案通过数为 3,所以写的请求通过
图5 网络分区消失后,各个节点能相互通信,此时第一任leader 发送心跳,第二人leader发送心跳,当 原leader NodeB 收到信Leader NodeE的心跳信息,发现NodeE 任期 term 为 2 ,出现了新的leader ,自己降级为 follower
图6 下面的 follower NodeA,NodeB 收到新leader 心跳 将任务 term 改成2 并进行状态同步,同步第二任 leader 的状态。
04 ZK 集群状态同步
Q:
为什么需要状态同步?
A:
完成 leader 选举后,zk 集群进入状态同步阶段,之所以进行同步是因为新的 leader 刚刚选举出来后,follower 上的节点信息有可能与 leader 不一致,经过状态同步后使得集群 follower 节点 与 leader 节点数据保持一致。
-
ZK 状态同步

1 leader 发送 newLeader 包到 follower 节点
2 follower 节点收到包后比较 zxid 是否比 leader 的zxid小,如果小则进行状态同步
3 leader 开启 followerlearner 线程,给需要同步的 每个 follower线程,进行数据同步
4 leader 主线程等待 follower线程处理结果
5 半数 follower 线程状态同步成功后,leader 才开始对外服务。
followerlearner 线程逻辑:
1 接收 follower的最大 zxid
2 将 follower 最大zxid 与 leader max zxid 比较
如果相等 则说明follower zxid 是最新的
如果follower zxid 小(或者大),则需要与 leader zxid 保持同步
3 以上消息完毕之后,发送UPTODATE封包告知follower当前数据就是最新的了。
05 ZK 分布式锁的应用
Q:
为什么用到分布式锁?
A:
为了保证一个方法在高并发情况下的同一时间只能被同一个线程执行,在分布式系统中,由于分布式系统多线程、多进程并且分布在不同机器上,这将使原单机部署情况下的并发控制锁策略失效,为了解决这个问题就需要一种跨JVM的互斥机制来控制共享资源的访问,这就是分布式锁要解决的问题。
-
ZK 实现分布式锁原理浅析
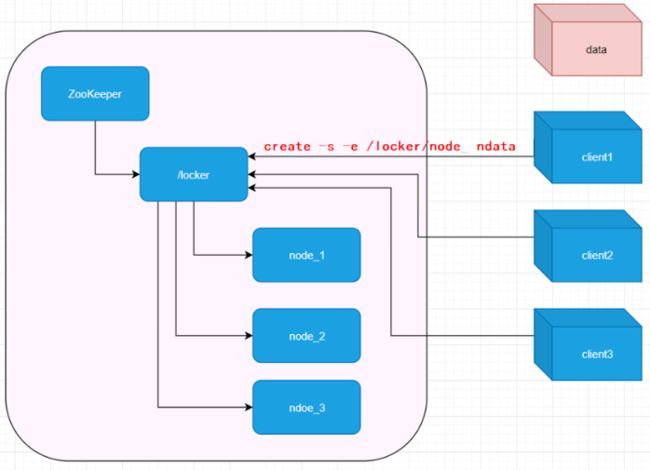
1 分布式锁使用的 是 临时顺序节点
2 在 ZK 某个持久节点下,进行判断如图的 /lockers
3 此时有3个客户端,争抢锁,同时在 /locks 下创建临时有序节点
client1 --- 创建节点 node_1
client2 --- 创建节点 node_2
client3 --- 创建节点 node_3
4 获取锁时 判断 所有的临时节点 哪个最小,则哪个客户端获取到锁,执行对应逻辑,逻辑执行后需要释放锁 即将对应临时节点删除
5 如果获取锁失败即不是最小节点,则往本身节点的前一个节点注册监听器,即如果是 node_2 节点则监听 node_1,如果是 node_3 节点则监听 node_2,
在回调函数中 设置监听逻辑 ,如果最小节点释放锁,最小节点被删除的同时, 触发监听器,再去判断是否是最小节点,执行获取锁的逻辑,后释放锁,
6最终每个客户端都会获取到锁,创建的临时有序节点最终也都会被删除。
ZK 实现分布式锁的代码关注公众号 “大数据江湖” 回复:“分布式锁”,即可领取。
本文我们通过图文的方式了解了 ZK 集群的相关工作原理,虽然 ZK 相关的维护在日常工作中我们涉及的比较少,但是也正是由于它是协调全局的管理者,理解其相关原理也就变得格外重要。另外文末的“分布式锁”代码不要忘记关注领取哦 ~
![]()
— THE END—