


文章发布于公号【数智物语】 (ID:decision_engine),关注公号不错过每一篇干货。
来源 | 上海交通大学计算机科学与工程系
作者 | 余锴
摘要:规则引擎起源于基于规则的专家系统,属于人工智能的范畴,通过模仿人类的推理方式,通过试探性推理,使用人类能够理解的方式证明其结论。规则引擎在现实应用中实现了业务和代码分离,通过代理的方式将业务语言定义传递到系统中,维护和管理复杂的业务规则,从而起到支撑业务灵活多变的作用。本文提出一种新的轻型规则引擎,旨在及时交付并提供更为灵活和复杂的逻辑控制功能,并且能基于类似随机森林的方法优化业务规则,可以应用在自动化信贷审批。
关键词:规则引擎;信贷审批;随机森林;
01
引言
规则引擎起源于基于规则的专家系统(CLIPS:源于1984年NASA的人工智能项目),规则引擎通过模拟人类的思考方式,使用试探性推理方法得到结果,并使用人类能够理解的方式证明其结论。
规则引擎自80年代至今,已经产生了多种商业及开源的产品,基本上都是基于Java开发, 既有商业产品,也有开源项目,其中最出名的是Drools。
目前绝大部分规则引擎都基于RETE算法设计,RETE算法是一种归纳法推理算法,主要由规则库,工作内存和推理引擎三部分组成,通过构建网络保存中间信息,能极大的提高规则匹配的效率。自1982年Forgy提出该算法以来经过几次优化,受到广泛的认可,其他还有一些匹配算法比如LFA,TREAI,LEAPS,但效率比不上RETE。
规则引擎目前主要的应用场景是CRM和审批系统。通过规则引擎企业得以快速灵活的制定和实施业务规则,从而快速的对市场做出反应或者是对审批流程进行快速的调整。
近年来经济形势的发展要求企业提高更快更好的服务,而且同时需要控制快速上涨的人力成本,越来越多的企业正在引入人工智能技术,其中之一就是规则引擎。目前规则引擎基本是使用Java构建的,一般只有大型企业才有技术和资金实力来构建这样的系统。本文以信贷审批作为默认的业务场景,提出一种新的灵活的规则引擎设计,完全使用Python实现。
规则引擎把复杂、冗余的业务规则与程序分离,做到架构的可复用移植。通过约定好的规范,接受用户的输入,解析用户的业务规则,最后执行解析好的业务规则作出决策。
一般情况下,所有的业务规则都可以表达成类似IF … THEN的条件语句,但由于企业的快速发展,业务规则会迅速增加,维护和管理这些业务规则会变得越来越困难,而规则引擎将至少具有三个作用:
(1)管理复杂的规则
(2)使用过程不再需要二次编程
(3)知识的管理和发现
以上三方面可以使得业务人员把注意力放到真正有意义的领域,减少重复性工作。从业务的角度上说,重要的是知识的获取和复用,由于规则引擎将规则逻辑从代码中分离,使得业务人员可以着重考虑规则中蕴含的知识,而规则引擎的推理和运行机制又解放了维护人员浪费大量的时间在逻辑判断代码上,在实际应用中起到了巨大的作用。
本文第一节进行概述,第二节简单介绍RETE算法及设计的动机,第三节具体介绍AJIT规则引擎结构的设计,第四节介绍引擎核心的三个算法,第五节将对本文做总结。
02
RETE算法
2.1 算法介绍
RETE算法是1982年由卡内基大学的Forgy提出的一种高效的模式匹配方法。由于其推理的效率很高,因为不少优秀的规则引擎都是基于RETE或者RETE的改良算法设计的。
RETE采用了一种基于树排序的方式,将规则的LHS(左手边条件)进行网络编码,在初次编译的时候保存推理的信息路径,而在运行时只需要去查询和匹配这些结果就完成了推理,从而大大节约了推理的时间。
2.2 相关概念
算法分为两个部分:
(1) 规则编译:根据规则集生成推理网络的过程。
(2) 运行时执行:将数据送入推理网络进行筛选的过程。
算法中的定义:
(1) 事实:对象之间及对象属性之间的关系。
(2) 规则:由条件和结论构成的推理语句。一个规则的IF部分被称为LHS,THEN部分被称为RHS。
(3) 模式: IF语句的条件。IF语句有可能是由几个更小的条件组成的大条件,而模式是指不能再分割的最小的原子条件。
算法是基于网络的:
(1) Alpha网络:将规则中每一个模式的集合生成Alpha memory。有两种类型的节点,过滤类型的节点和其他条件过滤的节点。
(2) Beta网络:有两种类型的节点Beta memory和Join Node。前者主要存储Join完成后的集合,后者包含两个输入口,分别输入需要匹配的两个集合,由Join节点做合并工作传输给下一个节点。
RETE存在的不足:事实上,从规则引擎的意义来说,RETE在对知识的获取,验证和更新上是存在困难的,而在避免重复运行代码上也存在一定局限性。原因如下:
(1) 网络结构
RETE的网络是基于所有规则的模式的,RETE通过保存操作过程中的状态避免大量计算。因此当新增加规则时应当更新网络结构,重新编译,当业务存在频繁变化时,RETE的效果不会太好。
(2) 黑盒子推理
RETE更大的隐患是在于其推理过程。由于网络是基于所有事实生成的,一旦在应用时规则出错,定位问题将会耗费海量的时间,工作的重心又会回到代码层面,不利于知识的学习。
03
AJIT规则引擎结构设计
本文提出的一种非常灵活的轻量规则引擎—AJIT(A just in time Rule Engine),完全使用Python语言实现,是在实际的业务中摸索出的一种创新性规则引擎。AJIT在性能上追求的是及时交付,其优点在于使用简洁的结构和算法,大量节约使用者和维护者的时间,使之把精力放在业务的思考上而非代码的修改上。并且Python可以方便地引入最新的机器学习或者AI的组件,使得AJIT更容易集成最先进的算法用于更复杂的决策。
3.1 规则结构
AJIT运行的基本单元是规则,每条规则都可以视为IF …(LHS) THEN …(RHS)的形式。
LHS:规则触发的条件,可以视为自变量,有以下几种情况:
(1)数据缺失。
(2)数据错误。
(3)数据正常的变量,又分为分类型变量(如性别)和连续性变量(如年龄)。
RHS:规则执行的动作,可以视为因变量,有以下几种情况:
(1)空操作:为了满足一部分特殊的情况,空操作不产生任何动作。
(2)选择操作:进行标记动作,不影响决策结果。
(3)决策操作:又可分为分类型决策(如审批通过, 审批拒绝, 人工调整)和
量化型决策(改变金融方案的条件)。
从存储的表结构来看,可以将规则分为扁平化规则和层级化规则:
(1)扁平化结构:穷举LHS的组合,枚举规则的所有情况。这种结构适用于简单的规则,通过矩阵并行运算,执行速度非常快。
(2)层级化结构:以决策树的结构进行层级化存储,通过迭代执行,避免维度的组合爆炸问题。
3.2 规则逻辑块
AJIT模拟人类一般处理问题的逻辑,把规则划分为三大逻辑块,R1,R2,R3。
R1:强规则,即可以通过这类型的规则给出直接的审批决定,比如申请人如果在黑名单中,拒绝贷款。
R2:弱规则,大部分此类的规则需要调整阈值做出决定,一般可以做出拒绝或者提高贷款要求。
R3:关于规则的规则,这部分用来进行综合判断和控制。
AJIT运行时会依次运行这三块逻辑,并允许在任何一个位置终止。通过这种划分可以让业务人员更容易理解规则的设置,发现问题时容易追溯。从引擎程序的角度来说,进行必要的划分也使控制变的更简单。
3.3 数据表设计
AJIT通过设计丰富的控制字段和状态字段使程序控制变的简单,由于规则表现为高度结构化的形态,因此可以存储在结构化数据库中。数据表可分为三个部分:数据表, 规则表, 策略表。
(1) 数据表
数据表描述规则依赖的数据定义,以及规则运行过程保存的数据。
(a) LHS变量定义:定义LHS变量的数据源位置,对于静态数据源只读取一次,对于动态数据源则每次重新读取。
(b) LHS查询记录:每次申请查询的LHS变量, 包含申请人的ID,申请编号,变量值, 查询的顺序等信息。
(c) LHS组合表:每条规则对应一个LHS变量的组合。
(d) 规则追溯表:每次申请运行规则情况,包含申请人的ID,申请编号,规则所属的逻辑块,是否命中,对应的策略,以及触发的原因等。
(2) 规则表
(a) LHS映射表:定义LHS变量的分箱映射,分为离散型变量和连续性变量。
(b) RHS定义表:定义RHS的值, 操作的类型有指定分类,加法控制, 比例控制,决策的结果有分类, 界限, 累加几种,以及对应的变量值。
(c) 规则定义表:定义规则的IF...THEN内容, 对于扁平化规则,存储规则对应的LHS变量的全部组合, 对于层级化规则,存储每一层变量的下一跳变量(每条路径至少有一个RHS)。
(d) 规则属性表:定义规则的属性,包括规则的ID,名称,规则所属的逻辑块, 规则的控制字段(反转,强制命中,可执行),规则的重要性,规则修改需要的权限,创建规则的用户, 规则属于的规则集。
(3) 策略表
(a) 策略定义:定义策略的名称和作用。
(b) 策略匹配表:存储策略到规则集的映射。规则集是规则的一个分类,一个规则可以属于多个规则集。
04
引擎核心算法
引擎的核心算法构成完成了规则引擎的基本功能,负责规则导入,运行和优化的相关功能。
4.1 冲突解决
冲突解决算法完成规则的导入动作,要保证添加新规则之后,引擎决策的结果仍然是一致的。
从集合的角度来看,规则是由LHS变量集合触发,得到RHS变量集合的过程,本质上同样的LHS定义应该得到近似的RHS结构.因此首先要根据LHS集合的情况进行匹配,而后比较RHS的情况。
RHS比较的结果可以分为四类:冲突, 分歧, 细化, 简化。冲突指LHS集合完全相同时,决策结果的矛盾(比如通过和拒绝),不允许存在冲突。分歧指LHS集合相交,决策结果的矛盾。细化指新的LHS集合包含了已有的LHS集合。简化指新的LHS集合属于某个已有的LHS集合。
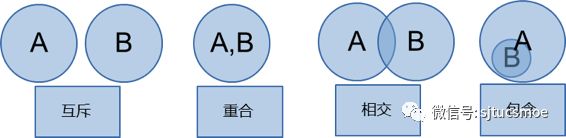
图4-1LHS集合的四种情况
伪代码:
Ifset(New.LHS)&set(Old.LHS) == Null:
write(New) into DataBase #互斥,不存在任何冲突
Else ifset(New.LHS)==set(Old.LHS): # 重合,可能存在冲突
If New.RHS contradict Old.RHS:
Cancel New Or Overwrite Old # 冲突,二者取其一
Else if set(New.RHS) != set(Old.RHS) :
warning # 仅给出警告,规则仍然可以写入
Else ifset(New.LHS) intersect set(Old.LHS): # 相交
intersect_LHS = set(New.LHS) intersect set(Old.LHS) # 共同的LHS部分
If intersect_LHS.RHS_New != intersect_Old.RHS Or contradict:
warning #仅给出警告,规则仍然可以写入
Else: # 包含与被包含
If New.LHS belongs to Old.LHS:
suggest_check: reduction (简化规则建议)
Elif New.LHS contains Old.LHS:
suggest_check: enhance (细化规则建议 )
冲突是由相同的信息得到不同的结果,只能选取其一;分歧是由不同额外的信息导致不同结果,可以同时存在,但是需要业务人员持续关注;简化或者细化是对原有规则的修改,这几部分工作均可以由根据实际业务情况逐渐使用机器学习的方法自动化。
4.2规则流水线
根据预先指定的策略,根据规则的逻辑块及依赖关系组织规则的运行。
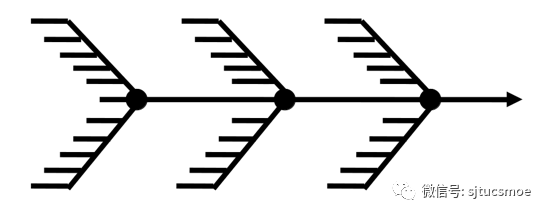
图4-2 规则流水线
伪代码:
step1根据策略选出待执行的所有规则。
step2将规则根据逻辑位置按顺序分块(R1,R2,R3)。
step3 For R in [R1,R2,R3]:
创建同步任务列表 sync_task = []
创建异步任务列表 async_task = []
step3.1 (同步规则)执行规则顺序>=0的规则 # 规则顺序为0的优先级最高
If rules are hierarchical rules: #层级化规则
For rule in rules:
sync_task.append(规则)
Else if rules are flat rules: # 规则是扁平化规则
rule_matrix = load(rules)
sync_task.append(rule_matrix)
step3.2 (异步规则)执行规则顺序 = -1 的规则
If rules are hierarchical rules: #
For rule in rules:
task = register_async_task(rule)
async_task.append(task)
Else if rules are flat rules:
rule_matrix = load(rules)
task =register_async_task(rule_matrix)
async_task.append(task)
step3.3执行规则
For task in sync_task:
sync execute task #同步阻塞的方式执行任务
For task in async_task:
async execute task #异步并行的方式执行任务
容易看出,引擎的执行时间只受限制于每个规则逻辑块中的同步规则(需要阻塞式顺序执行的规则)。这些规则一般是选择性规则或者是比较复杂的规则,这部分是规则流水线的时间瓶颈。
4.3 规则优化
利用类似随机森林的算法,通过对引擎内的规则进行总结和随机实验进行策略调优和知识发现。
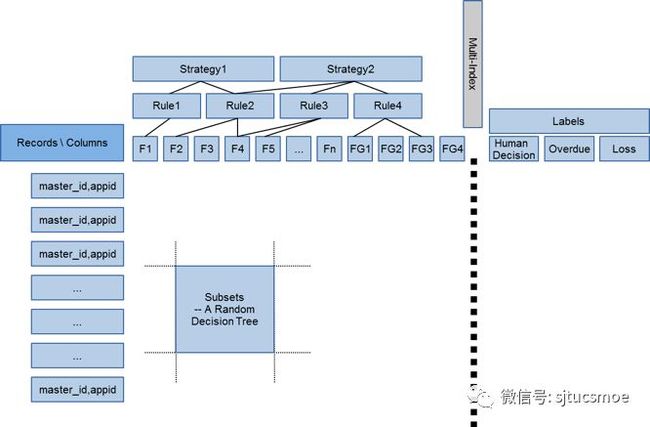
图4-3 规则优化数据结构图
关键字段说明:
F1~Fn:使用的LHS变量。
FG1~FGn:根据基本的LHS变量衍生出的LHS变量。
Rule:基于Fn的组合。
Strategy: 基于Rule的组合。
Label: 机器学习的目标。
伪代码:
Step1参数指定:
随机样本N, 用来建决策树所使用的记录数。
随机变量维度m. 总的规则数M, 满足m < Step2随机生成树 # 数据维度上的随机优化 For N in sample_over_records(): For m in sample_over_features(): y = label_choose() random_tree =make_decision_tree() For tree in existed_trees: If random_treebetter than tree: suggest(random_tree)# 建议更优的策略 Step3优化生成树 set_criteria() # 选择一个优化指标,比如信息值 feature = get_current_lhs() # 获取当前树用的LHS集合 y = label_chose() #选择一个目标变量 optimize_decision_trees() # 优化树的分类 Step4随机森林 trees = make_random_trees(tree_number) # 根据指定的数量生成n棵树 y = label_choose() #选择一个目标变量 for tree in trees: predict.append(vote by tree) #所有的树进行投票预测 从业务上看,该算法提供三方面的支持: (1)规则的阈值优化:通过树的优化,修改最初规则配置。 (2)新的策略发现:找到更有效的策略。 (3)组合模型预测:多棵树的投票,利于在缺失数据维度较多的情况下更好的决策。 05 总结 本文介绍了RETE算法在实际应用中的一些困难,并提出一种新的规则引擎AJIT, 通过流水线式的结构设计使得AJIT可进行更复杂的逻辑控制,并且可以很灵活的响应业务需求.以下从四方面总结AJIT的实践经验: (1)工程实施 集成性。由于Python语言有数量众多的包,因此数据清洗,矩阵运算,异步调度,服务部署等功能完全可以实现,仅有同用户交互的前端技术需要用到JavaScript和HTML5。 解耦性。每个功能块都是相对独立的,因此实际工程可以根据实际情况最小化的实施。 (2)算法学习 由于所有的数据都是结构化存储的,因此可以非常方便的进行用算法学习来替代人工来进行知识发现.通过可视化交互,业务管理人员可以理解规则引擎的建议,并做出合理原则。 (3)功能扩展 规则的执行过程是高度灵活的,Python在网络爬虫和人工智能方面有天然优势,我们曾经在规则引擎中插入问卷验证用户的真实身份, 问卷的内容则是通过程序实时爬取的。资源允许的情况下,任何规则都可以灵活调用各种算法来扩展功能。 (4)性能 现实中,用Pandas数据框(毫秒级/操作)结构代替Numpy矩阵(50微秒级/操作)进行实施,因此引擎的运行速度较慢,每个申请的整体运行时间在15s左右, 但对于实时要求并不高的审批申请业务来说,这个时间是完全能够接受的。事实上,AJIT设计并不适合追求极致的速度,考虑到要接入众多的算法,即使采用并行技术,总体时间仍然会受限于最慢的算法。 AJIT引擎是在实际应用场景下催生出的一种规则引擎,三种基本算法还需要不断的调优才能达到有效帮助人工提高效率,帮助企业做出更有效的决策。 从AJIT引擎本身特性来说,对于实时性要求不高的场景都可以进行扩展的研究和应用。 参考文献: [1]Charles.Forgy. Rete: A Fast Algorithmfor the Many Pattern/Many Object Pattern Match Problem, Carnegie-Mellon, 1982 [2]Alex Rupp. The Logic of the BottomLine: An Introduction to The Drools Project,TheServerSide.com,2004 [3]Jboss Drools Team.DroolsDocumentation:Chapter5 Hybrid Reasoning, 2016 [4]Max.Tardiveau. RETE Business Rule Engines,AutomatedBusiness Logic LLC, 2012 [5]鲍金玲. 基于规则引擎技术的Rete算法的研究,《科技信息》,2008,32(32):90-90 [6]孙懿青. 基于规则引擎的自解析匹配推理原型系统研究,南京师范大学,2006 [7]张剑,孟波. 基于规则引擎的一种智能工作流系统研究,《计算机工程与设计》, 2006, 27(14):2591-2593 [8]赵凡. 基于规则引擎的研究与应用,《多语种信息技术研究室, 2007》 星标我,每天多一点智慧


