课堂作业
- 爬取解密大数据专题所有文章列表,并输出到文件中保存
- 每篇文章需要爬取的数据:作者,标题,文章地址,摘要,缩略图地址,阅读数,评论数,点赞数和打赏数
参考资料
-
- Beautiful Soup 4.4.0 文档英文版
谢谢曾老师的指导和分享。感谢已经做完这次作业的同学,其中的一些经验值得借鉴。joe同学的这次作业很详尽,而且用到了正则表达式匹配的方法和一些新函数,结合商业数据分析课程学到的知识做了一些图表和分析,大家可以去瞻仰一下。
爬虫作业的难度变大了。在对python的函数不熟悉,对各个爬虫工具官方文档比较陌生的情况下,遇到了不少问题。
中文字符解码是我最近2次爬虫作业遇到的主要问题之一,这个问题也困扰了不少其他同学。不知道新生大学的课程中会不会涉及?有没有什么系统的教程或文档可以借鉴?
为什么要给种子页面或实际有效页面加上后缀
&page=%d,是因为这是比较通用的模拟页面动态(异步)加载的方法吗?这样才能完整加载并读取这个目标页面的所有内容?曾老师在7月29日的课堂里提到过,可截图里我没看出什么情况下会出现带如http://www.jianshu.com/c/9b4685b6357c/?order_by=added_at&page=1的链接。我在自己Windows 7 64位的Chrome里面未观察出来。这次抓取的信息较多,路径也比较复杂,比较考验观察和编写代码的细致程度。这点上有Joe同学作榜样,我花了不少时间,但错误基本都改了。
代码部分:beautifulsoup4实现
- 导入模块
- 基础的下载函数:download
- 抓取专题页上文章列表区域的函数:crawl_list
- 抓取每篇文章目标标签信息的函数:crawl_paper_tag
- 把抓取到的文章标签信息按文章写入不同文件的函数:write_file
- 把标题中不适合做文件名的字符替换的函数:clean_title
- 执行爬取并写入文件的函数:crawl_papers
导入模块
import os
import time
import urllib2
from bs4 import BeautifulSoup
import urlparse
download函数
def download(url, retry=2):
"""
下载页面的函数,会下载完整的页面信息
:param url: 要下载的url
:param retry: 重试次数
:return: 原生html
"""
print "downloading: ", url
# 设置header信息,模拟浏览器请求
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36'
}
try: #爬取可能会失败,采用try-except方式来捕获处理
request = urllib2.Request(url, headers=header) #设置请求数据
html = urllib2.urlopen(request).read() #抓取url
except urllib2.URLError as e: #异常处理
print "download error: ", e.reason
html = None
if retry > 0: #未超过重试次数,可以继续爬取
if hasattr(e, 'code') and 500 <= e.code < 600: #错误码范围,是请求出错才继续重试爬取
print e.code
return download(url, retry - 1)
time.sleep(1) #等待1s,避免对服务器造成压力,也避免被服务器屏蔽爬取
return html
crawl_list函数
def crawl_list(url):
"""
爬取文章列表
:param url 下载的种子页面地址
:return:
"""
html = download(url) #下载页面
if html == None: # 下载页面为空,表示已爬取到最后
return
soup = BeautifulSoup(html, "html.parser") # 格式化爬取的页面数据
return soup.find(id='list-container').find('ul', {'class': 'note-list'}) # 文章列表
这一部分是基于老师课堂上的代码。
crawl_paper_tag函数
def crawl_paper_tag(list, url_root):
"""
获取文章列表详情
:param list: 要爬取的文章列表
:param url_root: 爬取网站的根目录
:return:
"""
paperList = [] # 文章属性集列表
lists = list.find_all('li')
# print (lists)
for paperTag in lists:
author = paperTag.find('div', {'class': 'content'}).find('a', {'class': 'blue-link'}).text # 作者
title = paperTag.find('div', {'class': 'content'}).find('a', {'class': 'title'}).text # 标题
paperURL = paperTag.find('div', {'class': 'content'}).find('a', {'class': 'title'}).get('href') # 文章网址
abstract = paperTag.find('div', {'class': 'content'}).find('p', {'class': 'abstract'}).text # 文章摘要
if paperTag.find('a', {'class': 'wrap-img'}) != None:
pic = paperTag.find('a', {'class': 'wrap-img'}).find('img').get('src') # 文章缩略图
else:
pic = 'No Pic'
metaRead = paperTag.find('div', {'class': 'content'}).find('i', {'class': 'iconfont ic-list-read'}).find_parent('a').text # 阅读数
metaComment = paperTag.find('div', {'class': 'content'}).find('i', {'class': 'iconfont ic-list-comments'}).find_parent('a').text # 评论数
metaLike = paperTag.find('div', {'class': 'content'}).find('i', {'class': 'iconfont ic-list-like'}).find_parent('span').text # 点赞数
if paperTag.find('div', {'class': 'content'}).find('i', {'class': 'iconfont ic-list-money'}) != None:
metaReward = paperTag.find('div', {'class': 'content'}).find('i', {'class': 'iconfont ic-list-money'}).find_parent('span').text# 打赏数
else:
metaReward = 0
paperAttr = {
'author': author,
'title': title,
'url': urlparse.urljoin(url_root, paperURL),
'abstract': abstract,
'pic': pic,
'read': metaRead,
'comment': metaComment,
'like': metaLike,
'reward': metaReward
}
# print (paperAttr)
write_file(title, paperAttr)
paperList.append(paperAttr)
return paperList
基于曾老师课堂上提供的代码补充和修改。尝试过把含字典变量的列表直接写入文件无法正确对字符进行编码,可能需要再做个循环才能写入正确字符。这里直接调用写入文件函数把字典变量写入文件。
write_file函数
def write_file(title, paperattr):
if os.path.exists('spider_output/') == False: # 检查保存文件的地址
os.mkdir('spider_output/')
cleaned_title = clean_title(title)
file_name = 'spider_output/' + cleaned_title + '.txt' #设置要保存的文件名 # 设置要保存的文件名
# if os.path.exists(file_name):
# os.remove(file_name) # 删除文件
# return # 已存在的文件不再写
file = open(file_name, 'wb')
content = 'Author:' + (unicode(paperattr['author']).encode('utf-8', errors='ignore')) + '\n' \
+ 'Title:' + (unicode(paperattr['title']).encode('utf-8', errors='ignore')) + '\n' \
+ 'URL:' + (unicode(paperattr['url']).encode('utf-8', errors='ignore')) + '\n' \
+ 'Abstract:' + (unicode(paperattr['abstract']).encode('utf-8', errors='ignore')) + '\n' \
+ 'ArtilcePic:' + (unicode(paperattr['pic']).encode('utf-8', errors='ignore')) + '\n' \
+ 'Read:' + (unicode(paperattr['read']).encode('utf-8', errors='ignore')) + '\n' \
+ 'Comment:' + (unicode(paperattr['comment']).encode('utf-8', errors='ignore')) + '\n' \
+ 'Like:' + (unicode(paperattr['like']).encode('utf-8', errors='ignore')) + '\n' \
+ 'Reward:' + (unicode(paperattr['reward']).encode('utf-8', errors='ignore')) + '\n'
file.write(content)
file.close()
clean_title函数
def clean_title(title):
"""
替换特殊字符,否则根据文章标题生成文件名的代码会运行出错
"""
title = title.replace('|', ' ')
title = title.replace('"', ' ')
title = title.replace('/', ',')
title = title.replace('<', ' ')
title = title.replace('>', ' ')
title = title.replace('\x08', '')
return title
上面2个函数是把目标标签信息写入带文章标题的文件中,标题替换函数参考了别的同学的代码。
crawl_papers函数
def crawl_papers(url_seed, url_root):
"""
抓取所有的文章列表
:param url_seed: 下载的种子页面地址
:param url_root: 爬取网站的根目录
:return:
"""
i = 1
flag = True # 标记是否需要继续爬取
while flag:
url = url_seed % i # 真正爬取的页面
i += 1 # 下一次需要爬取的页面
article_list = crawl_list(url) # 下载文章列表
article_tag = crawl_paper_tag(article_list, url_root)
if article_tag.__len__() == 0: # 下载文章列表返回长度为0的列表,表示已爬取到最后
flag = False
目前实际执行的理解需要通过递增调用&page=%d这个参数才能爬取所有的文章列表信息。当没有文章列表信息可以抓取到时,终止爬取。
调用函数执行页面抓取
url_root = 'http://www.jianshu.com/'
url_seed = 'http://www.jianshu.com/c/9b4685b6357c/?order_by=added_at&page=%d'
crawl_papers(url_seed, url_root)
Python Console的输出结果如下
downloading: http://www.jianshu.com/c/9b4685b6357c/?order_by=added_at&page=1
downloading: http://www.jianshu.com/c/9b4685b6357c/?order_by=added_at&page=2
downloading: http://www.jianshu.com/c/9b4685b6357c/?order_by=added_at&page=3
downloading: http://www.jianshu.com/c/9b4685b6357c/?order_by=added_at&page=4
downloading: http://www.jianshu.com/c/9b4685b6357c/?order_by=added_at&page=5
downloading: http://www.jianshu.com/c/9b4685b6357c/?order_by=added_at&page=6
downloading: http://www.jianshu.com/c/9b4685b6357c/?order_by=added_at&page=7
downloading: http://www.jianshu.com/c/9b4685b6357c/?order_by=added_at&page=8
downloading: http://www.jianshu.com/c/9b4685b6357c/?order_by=added_at&page=9
downloading: http://www.jianshu.com/c/9b4685b6357c/?order_by=added_at&page=10
downloading: http://www.jianshu.com/c/9b4685b6357c/?order_by=added_at&page=11
downloading: http://www.jianshu.com/c/9b4685b6357c/?order_by=added_at&page=12
downloading: http://www.jianshu.com/c/9b4685b6357c/?order_by=added_at&page=13
downloading: http://www.jianshu.com/c/9b4685b6357c/?order_by=added_at&page=14
downloading: http://www.jianshu.com/c/9b4685b6357c/?order_by=added_at&page=15
downloading: http://www.jianshu.com/c/9b4685b6357c/?order_by=added_at&page=16
downloading: http://www.jianshu.com/c/9b4685b6357c/?order_by=added_at&page=17
downloading: http://www.jianshu.com/c/9b4685b6357c/?order_by=added_at&page=18
downloading: http://www.jianshu.com/c/9b4685b6357c/?order_by=added_at&page=19
downloading: http://www.jianshu.com/c/9b4685b6357c/?order_by=added_at&page=20
downloading: http://www.jianshu.com/c/9b4685b6357c/?order_by=added_at&page=21
downloading: http://www.jianshu.com/c/9b4685b6357c/?order_by=added_at&page=22
downloading: http://www.jianshu.com/c/9b4685b6357c/?order_by=added_at&page=23
downloading: http://www.jianshu.com/c/9b4685b6357c/?order_by=added_at&page=24
downloading: http://www.jianshu.com/c/9b4685b6357c/?order_by=added_at&page=25
downloading: http://www.jianshu.com/c/9b4685b6357c/?order_by=added_at&page=26
downloading: http://www.jianshu.com/c/9b4685b6357c/?order_by=added_at&page=27
downloading: http://www.jianshu.com/c/9b4685b6357c/?order_by=added_at&page=28
downloading: http://www.jianshu.com/c/9b4685b6357c/?order_by=added_at&page=29
downloading: http://www.jianshu.com/c/9b4685b6357c/?order_by=added_at&page=30
downloading: http://www.jianshu.com/c/9b4685b6357c/?order_by=added_at&page=31
downloading: http://www.jianshu.com/c/9b4685b6357c/?order_by=added_at&page=32
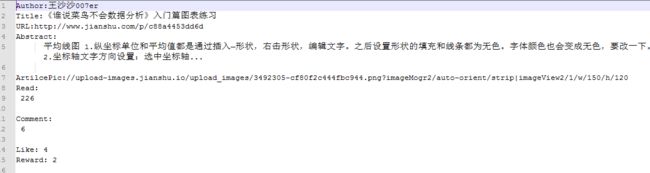
抓取的结果文件如下: