转载请标明作者以及文章来源,谢谢!
作者介绍:
姓名:李航
工作经历:5年多互联网工作经验,先后在58同城,汽车之家,优酷土豆集团工作。
目前主要在优酷土豆集团任职高级开发工程师,负责分布式缓存/存储系统等建设工作。
主要关注领域Nginx,Redis,分布式系统,分布式存储~
微博:http://weibo.com/lidaohang
github:https://github.com/lidaohang
本分享来源于Redis技术交流群,本群为纯粹讨论Redis和Tidb的微信技术讨论群,目前人数较多请加本文作者或者群主微信拉群,作者和楼主微信二维码分别如下:


大家好,首先自我介绍下,我是来自优酷土豆集团基础平台高级工程师李航。目前主要负责大数据基础平台Redis集群开发及运维等工作。很荣幸能加入这么多大牛的微信群,第一次在这么多大牛的微信群分享,请大家多多指教!
这次主要是给大家分享的提纲如下:
1.Redis架构的方案经历阶段
2.为什么选择Nginx开发Proxy
3.Nginx Proxy+Redis Cluster架构功能及优化
4.监控告警
1.Redis架构的方案经历阶段
1.1.客户端分片
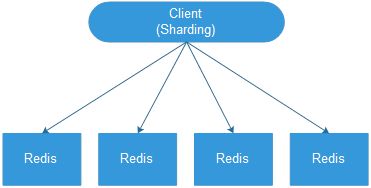
优点
不依赖于第三方中间件,实现方法和代码自己掌控,可随时调整
这种分片机制的性能比代理式更好(少了一个中间分发环节)
可控的分发请求,分发压力落在客户端,无服务器压力增加
缺点
不能平滑的水平扩展节点,扩容/缩容时,必须手动调整分片程序
出现故障,不能自动转移,运维性很差
客户端得自己维护一套路由算法
升级复杂
1.2.Twemproxy

优点
运维成本低。业务方不用关心后端Redis实例,跟操作Redis一样
Proxy的逻辑和存储的逻辑是隔离的
缺点
代理层多了一次转发,性能有所损耗
进行扩容/缩容时候,部分数据可能会失效,需要手动进行迁移,对运维要求较高,而且难以做到平滑的扩缩容
出现故障,不能自动转移,运维性很差
升级复杂
1.3.RedisCluster

优点
无中心节点
数据按照Slot存储分布在多个Redis实例上
平滑的进行扩容/缩容节点
自动故障转移(节点之间通过Gossip协议交换状态信息,进行投票机制完成Slave到Master角色的提升)
降低运维成本,提高了系统的可扩展性和高可用性
缺点
严重依赖外部Redis-Trib
缺乏监控管理
需要依赖Smart Client(连接维护,缓存路由表, MultiOp和Pipeline支持)
Failover节点的检测过慢,不如“中心节点ZooKeeper”及时
Gossip消息的开销
无法根据统计区分冷热数据
Slave“冷备”,不能缓解读压力
1.4.Proxy+RedisCluster
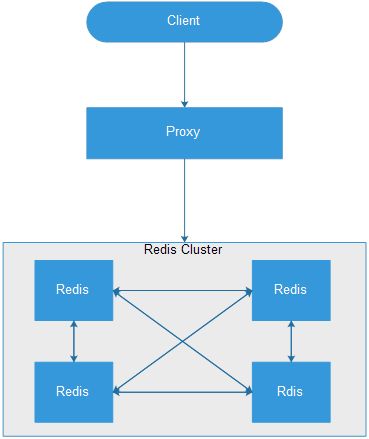
Smart Client vs Proxy:
优点
SmartClient:
a.相比于使用代理,减少了一层网络传输的消耗,效率较高。
b.不依赖于第三方中间件,实现方法和代码自己掌控,可随时调整。
Proxy:
a.提供一套HTTP Restful接口,隔离底层存储。对客户端完全透明,跨语言调用。
b.升级维护较为容易,维护Redis Cluster,只需要平滑升级Proxy。
c.层次化存储,底层存储做冷热异构存储。
d.权限控制,Proxy可以通过秘钥控制白名单,把一些不合法的请求都过滤掉。并且也可以控制用户请求的超大Value进行控制,和过滤。
e.安全性,可以屏蔽掉一些危险命令,比如Keys、Save、Flush All等。
f.容量控制,根据不同用户容量申请进行容量限制。
g.资源逻辑隔离,根据不同用户的Key加上前缀,来进行资源隔离。
h.监控埋点,对于不同的接口进行埋点监控等信息。
缺点
SmartClient:
a.客户端的不成熟,影响应用的稳定性,提高开发难度。
b.MultiOp和Pipeline支持有限。
c.连接维护,Smart客户端对连接到集群中每个结点Socket的维护。
Proxy:
a.代理层多了一次转发,性能有所损耗。
b.进行扩容/缩容时候对运维要求较高,而且难以做到平滑的扩缩容。
2.为什么选择Nginx开发Proxy
1.单Master多Work模式,每个Work跟Redis一样都是单进程单线程模式,并且都是基
于Epoll事件驱动的模式。
2.Nginx采用了异步非阻塞的方式来处理请求,高效的异步框架。
3.内存占用少,有自己的一套内存池管理方式,。将大量小内存的申请聚集到一块,能够比Malloc更快。减少内存碎片,防止内存泄漏。减少内存管理复杂度。
4.为了提高Nginx的访问速度,Nginx使用了自己的一套连接池。
5.最重要的是支持自定义模块开发。
6.业界内,对于Nginx,Redis的口碑可称得上两大神器。性能也就不用说了。
3.Proxy+Redis Cluster介绍
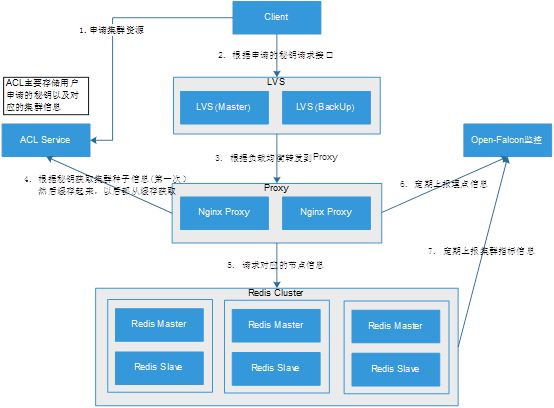
3.1Proxy+Redis Cluster架构方案介绍
1.用户在ACL平台申请集群资源,如果申请成功返回秘钥信息。
2.用户请求接口必须包含申请的秘钥信息,请求至LVS服务器。
3.LVS根据负载均衡策略将请求转发至Nginx Proxy。
4.Nginx Proxy首先会获取秘钥信息,然后根据秘钥信息去ACL服务上获取集群的种子信息。(种子信息是集群内任意几台IP:PORT节点)
然后把秘钥信息和对应的集群种子信息缓存起来。并且第一次访问会根据种子IP:PORT获取集群Slot对应节点的Mapping路由信息,进行缓存起来。最后根据Key计算SlotId,从缓存路由找到节点信息。
5.把相应的K/V信息发送到对应的Redis节点上。
6.Nginx Proxy定时(60s)上报请求接口埋点的QPS,RT,Err等信息到Open-Falcon平台。
7.Redis Cluster定时(60s)上报集群相关指标的信息到Open-Falcon平台。
3.2Nginx Proxy功能介绍
目前支持的功能:
HTTP
Restful接口:
解析用户Post过来的数据,并且构建Redis协议。客户端不需要开发Smart
Client,对客户端完全透明、跨语言调用
权限控制:
根据用户Post数据获取AppKey,Uri,然后去ACL Service服务里面进行认证。如果认证通过,会给用户返回相应的集群种子IP,以及相应的过期时间限制等信息
限制数据大小:
获取用户Post过来的数据,对Key,Value长度进行限制,避免产生超大的Key,Value,打满网卡、阻塞Proxy
数据压缩/解压:
如果是写请求,对Value进行压缩(Snappy),然后在把压缩后的数据存储到Redis Cluster。
如果是读请求,把Value从Redis Cluster读出来,然后对Value进行解压,最后响应给用户。
缓存路由信息:
维护路由信息,Slot对应的节点的Mapping信息
结果聚合:
MultiOp支持
批量指令支持(Pipeline/Redis+Lua+EVALSHA进行批量指令执行)
资源逻辑隔离:
根据用户Post数据获取该用户申请的NameSpace,然后以NameSpace作为该用户请求Key的前缀,从而达到不同用户的不同NameSpace,进行逻辑资源隔离
重试策略:
针对后端Redis节点出现Moved,Ask,Err,TimeOut等进行重试,重试次数可配置
连接池:
维护用户请求的长连接,维护后端服务器的长连接
配额管理:
根据用户的前缀(NameSpace),定时的去抓取RANDOMKEY,根据一定的比率,估算出不同用户的容量大小值,然后在对用户的配额进行限制管理
过载保护:
通过在Nginx
Proxy Limit模块进行限速,超过集群的承载能力,进行过载保护。从而保证部分用户可用,不至于压垮服务器
监控管理:
NginxProxy接入了Open-Falcon对系统级别,应用级别,业务级别进行监控和告警
例如:接口的QPS,RT,ERR等进行采集监控,并且展示到DashBoard上
告警阈值的设置非常灵活,配置化
待开发的功能列表:
层次化存储:
利用Nginx Proxy共享内存定制化开发一套LRU本地缓存实现,从而减少网络请求
冷数据Swap到慢存储,从而实现冷热异构存储
主动Failover节点:
由于Redis Cluster是通过Gossip通信,超过半数以上Master节点通信(cluster-node-timeout)认为当前Master节点宕机,才真的确认该节点宕机。判断节点宕机时间过长,在Proxy层加入Raft算法,加快失效节点判定,主动Failover
3.3Nginx Proxy性能优化
3.3.1批量接口优化方案
1.子请求变为协程
案例:
用户需求调用批量接口mget(50Key)要求性能高,吞吐高,响应快。
问题:
由于最早用的Nginx
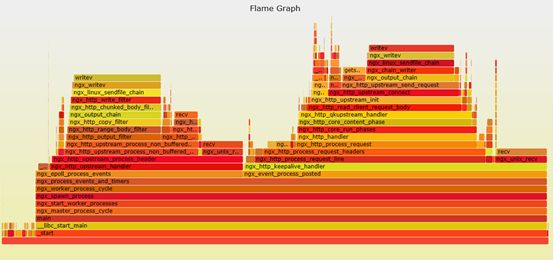
Subrequest来做批量接口请求的处理,性能一直不高,CPU利用率也不高,QPS提不起来。通过火焰图观察分析子请求开销比较大。
解决方案:
子请求效率较低,因为它需要重新从Server Rewrite开始走一遍Request处理的PHASE。并且子请求共享父请求的内存池,子请求同时并发度过大,导致内存较高。
协程轻量级的线程,占用内存少。经过调研和测试,单机一两百万个协程是没有问题的,
并且性能也很高。
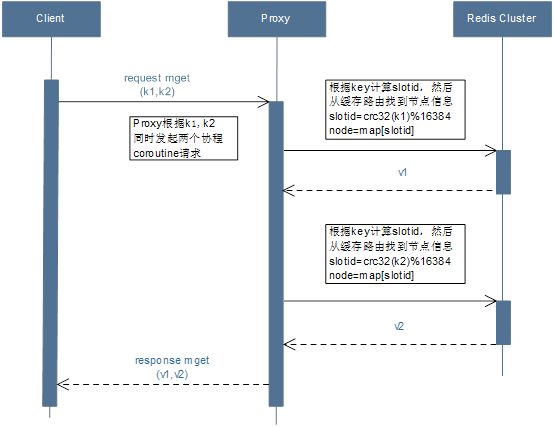
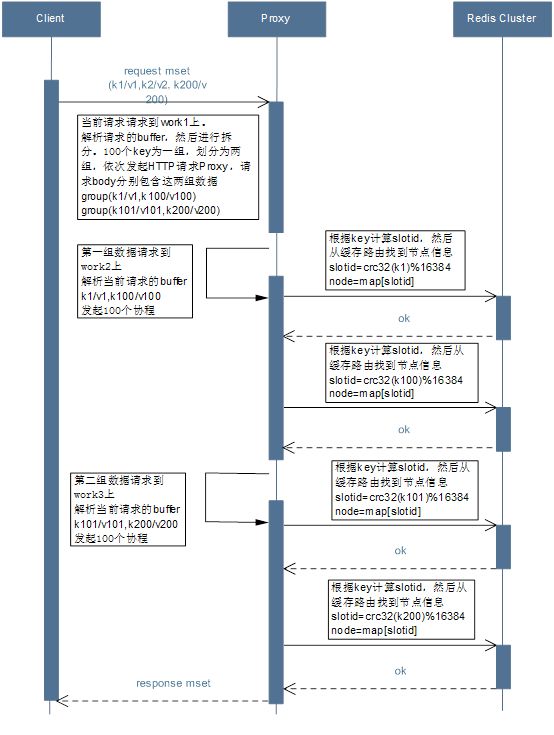
优化前:
a)用户请求mget(k1,k2)到Proxy
b)Proxy根据k1,k2分别发起子请求subrequest1,subrequest2
c)子请求根据key计算slotid,然后去缓存路由表查找节点
d)子请求请求Redis Cluster的相关节点,然后响应返回给Proxy
e)Proxy会合并所有的子请求返回的结果,然后进行解析包装返回给用户

优化后:
a)用户请求mget(k1,k2)到Proxy
b)Proxy根据k1,k2分别计算slotid,然后去缓存路由表查找节点
c)Proxy发起多个协程coroutine1, coroutine2并发的请求Redis Cluster的相关节点
d)Proxy会合并多个协程返回的结果,然后进行解析包装返回给用户
2.合并相同槽,批量执行指令,减少网络开销
案例:
用户需求调用批量接口mget(50key)要求性能高,吞吐高,响应快。
问题:
经过上面协程的方式进行优化后,发现批量接口性能还是提升不够高。通过火焰图观察分析网络开销比较大。
解决方案:
因为在Redis
Cluster中,批量执行的key必须在同一个slotid。所以,我们可以合并相同slotid的key做为一次请求。然后利用Pipeline/Lua+EVALSHA批量执行命令来减少网络开销,提高性能。
优化前:
a)用户请求mget(k1,k2,k3,k4)到Proxy。
b)Proxy会解析请求串,然后计算k1,k2,k3,k4所对应的slotid。
c)Proxy会根据slotid去路由缓存中找到后端服务器的节点,并发的发起多个请求到后端服务器。
d)后端服务器返回结果给Proxy,然后Proxy进行解析获取key对应的value。
e)Proxy把key,value对应数据包装返回给用户。

优化后:
a)用户请求mget(k1,k2,k3,k4)到Proxy。
b)Proxy会解析请求串,然后计算k1,k2,k3,k4所对应的slotid,然后把相同的slotid进行合并为一次Pipeline请求。
c)Proxy会根据slotid去路由缓存中找到后端服务器的节点,并发的发起多个请求到后端服务器。
d)后端服务器返回结果给Proxy,然后Proxy进行解析获取key对应的value。
e)Proxy把key,value对应数据包装返回给用户。

3.对后端并发度的控制
案例:
当用户调用批量接口请求mset,如果k数量几百个甚至几千个时,会导致Proxy瞬间同时发起几百甚至几千个协程同时去访问后端服务器Redis Cluster。
问题:
RedisCluster同时并发请求的协程过多,会导致连接数瞬间会很大,甚至超过上限,CPU,连接数忽高忽低,对集群造成不稳定。
解决方案:
单个批量请求对后端适当控制并发度进行分组并发请求,反向有利于性能提升,避免超过Redis Cluster连接数,同时Redis Cluster波动也会小很多,更加的平滑。
优化前:
a)用户请求批量接口mset(200个key)。(这里先忽略合并相同槽的逻辑)
b)Proxy会解析这200个key,会同时发起200个协程请求并发的去请求Redis Cluster。
c)Proxy等待所有协程请求完成,然后合并所有协程请求的响应结果,进行解析,包装返回给用户。
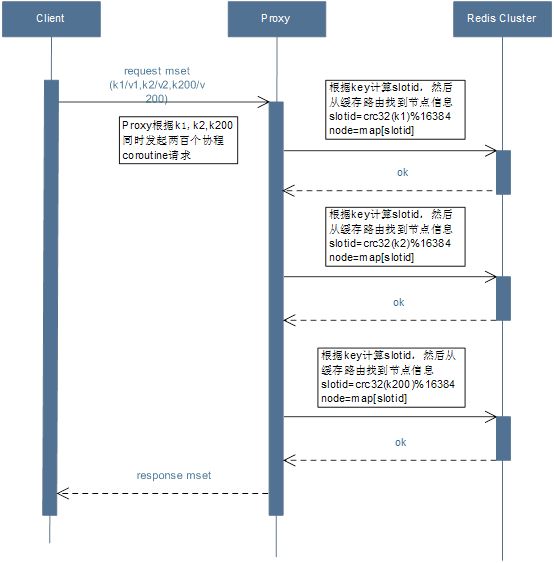
优化后:
a)用户请求批量接口mset(200个key)。(这里先忽略合并相同槽的逻辑)
b)Proxy会解析这200个key,进行分组。100个key为一组,分批次进行并发请求。
c)Proxy先同时发起第一组100个协程(coroutine1, coroutine100)请求并发的去请求Redis Cluster。
d)Proxy等待所有协程请求完成,然后合并所有协程请求的响应结果。
e)Proxy然后同时发起第二组100个协程(coroutine101, coroutine200)请求并发的去请求Redis Cluster。
f)Proxy等待所有协程请求完成,然后合并所有协程请求的响应结果。
g)Proxy把所有协程响应的结果进行解析,包装,返回给用户。
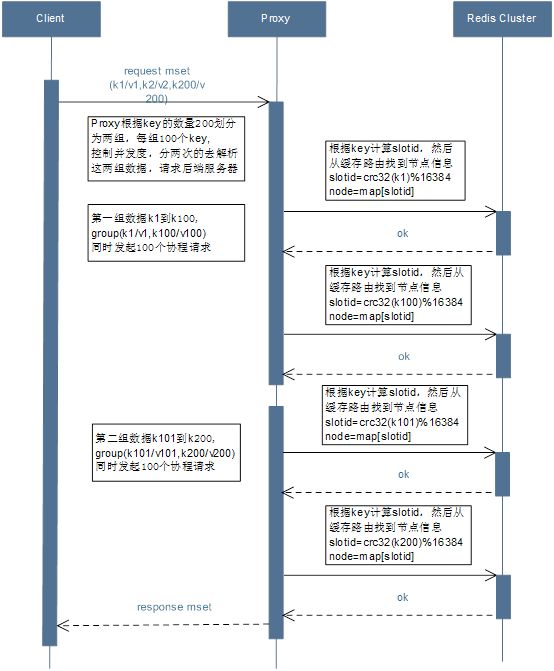
4.单Work分散到多Work
案例:
当用户调用批量接口请求mset,如果k数量几百个甚至几千个时,会导致Proxy瞬间同时发起几百甚至几千个协程同时去访问后端服务器Redis Cluster。
问题:
由于Nginx的框架模型是单进程单线程,所以Proxy发起的协程都会在一个Work上,这样如果发起的协程请求过多就会导致单Work CPU打满,导致Nginx的每个Work CPU使用率非常不均,内存持续暴涨的情况。(nginx的内存池只能提前释放大块,不会提前释放小块)
解决方案:
增加一层缓冲层代理,把请求的数据进行拆分为多份,然后每份发起请求,控制并发度,在转发给Proxy层,避免单个较大的批量请求打满单Work,从而达到分散多Work,达到Nginx多个Wrok CPU使用率均衡。
优化前:
a)用户请求批量接口mset(200个key)。(这里先忽略合并相同槽的逻辑)
b)Proxy会解析这200个key,会同时发起200个协程请求并发的去请求Redis Cluster。
c)Proxy等待所有协程请求完成,然后合并所有协程请求的响应结果,进行解析,包装返回给用户。

优化后:
a)用户请求批量接口mset(200个key)。(这里先忽略合并相同槽的key的逻辑)
b)Proxy会解析这200个key,然后进行拆分分组以此来控制并发度。
c)Proxy会根据划分好的组进行一组一组的发起请求。
d)Proxy等待所有请求完成,然后合并所有协程请求的响应结果,进行解析,包装返回给用户。
总结,经过上面一系列优化,我们可以来看看针对批量接口mset(50个k/v)性能对比图,Nginx Proxy的响应时间比Java版本的响应时间快了5倍多。
Java版本:

Nginx版本:

3.3.2网卡软中断优化
irqbalance根据系统中断负载的情况,自动迁移中断保持中断的平衡。但是在实时系统中会导致中断自动漂移,对性能造成不稳定因素,在高性能的场合建议关闭。
1.首先关闭网卡软中断
service irqbalance stop
service cpuspeed stop
2.查看网卡是队列
grep eth /proc/interrupts | awk '{print $1,$NF}'
77: eth0
78: eth0-TxRx-0
79: eth0-TxRx-1
80: eth0-TxRx-2
81: eth0-TxRx-3
82: eth0-TxRx-4
83: eth0-TxRx-5
84: eth0-TxRx-6
85: eth0-TxRx-7
3.绑定网卡软中断到CPU0-2号上
(注意这里的echo是十六进制)
echo "1" >/proc/irq/78/smp_affinity
echo "1" >/proc/irq/79/smp_affinity
echo "2" >/proc/irq/80/smp_affinity
echo "2" > /proc/irq/81/smp_affinity
echo "2" >/proc/irq/82/smp_affinity
echo "4" >/proc/irq/83/smp_affinity
echo "4" >/proc/irq/84/smp_affinity
echo "4" >/proc/irq/85/smp_affinity
3.3.3绑定进程到指定的CPU
绑定nginx或者redis的pid到cpu3-cpu10上:
taskset -cp 3 1900
taskset -cp 4 1901
taskset -cp 5 1902
taskset -cp 6 1903
taskset -cp 7 1904
taskset -cp 8 1905
taskset -cp 9 1902
taskset -cp 10 1902
或者通过Nginx Proxy配置:
worker_cpu_affinity绑定CPU亲缘性
3.3.4性能优化神器火焰图
3.4Redis Cluster运维
3.4.1运维功能
1.创建集群
2.集群扩容/缩容
3.节点宕机
4.集群升级
5.迁移数据
6.副本迁移
7.手动failover
8.手动rebalance
以上相关运维功能,目前是通过脚本配置化一键式操作,依赖于官方的redis-rebalance.rb进行扩展开发。运维非常方便快捷。
3.5性能测试报告
3.5.1测试环境
软件:
Jmeter
Nginx Proxy(24核)
Redis集群(4 Master,4Slave)
测试Key(100000)
硬件:
OS:Centos6.6
CPU:24核
带宽:千兆
内存:62G
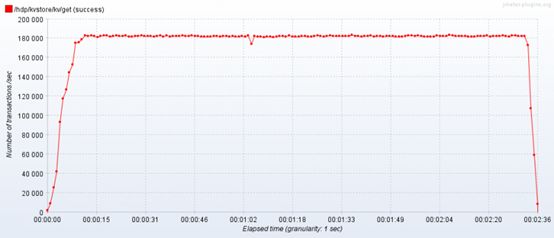
测试结果:
场景:普通K/V
QPS:18W左右
RT:99都在10ms以内
CPU:Nginx Proxy CPU在50%左右
4.监控告警
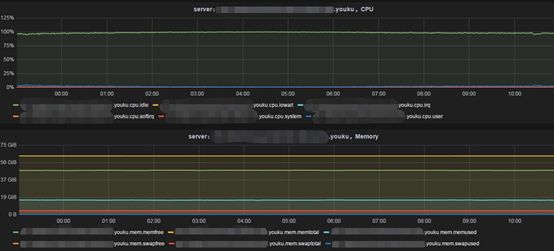
4.1系统级别
通过Open-Falcon Agent采集服务器的CPU、内存、网卡流量、网络连接、磁盘等信息。
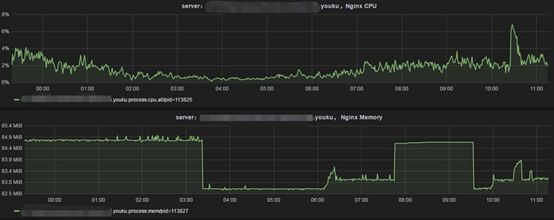
4.2应用级别
通过Open-Falcon Plugin采集Nginx/Redis进程级别的CPU,内存,Pid等信息。
4.3业务级别
通过在Proxy里面埋点监控业务接口QPS,RT(50%,99%,999%),请求流量,错误次数等信息,定时的上报给Open-Falcon。
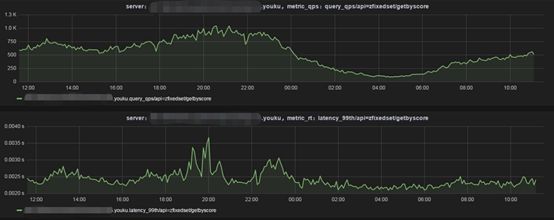
通过Open-Falcon Plugin采集Redis Cluster集群信息,QPS,连接数等相关指标指标信息。
分享完毕,在此非常感谢大家的收听,感谢微信群主@鹏程给了我这个直播平台跟大家一起交流学习,也感谢我们老大@高嵩,同事@张海雷。
最后打个广告,我们团队(优酷土豆大数据基础平台)目前正在寻找大数据领域的优秀人才加盟,如果你对redis/hbase/spark/storm/kafka等大数据领域有深厚的兴趣和钻研精神,
希望能够接触到海量数据的实时计算和存储平台的搭建以及攻克各种线上的疑难问题,
请将你的简历发送给[email protected],加入我们,互相学习,共同成长。
5.QA
Q:问个问题哈,Redis适合大数据的查询和结果集的Union?
A:由于Redis是单进程单线程的,不适合大数据的查询和分析。
Q:是所有应用的数据都打散放在各个实例中了吗,数据不均衡怎么办?
A:数据是根据Redis Cluster内部的crc32(key)%16384每个实例都有部分槽,并且槽可以进行迁移
Q:我看刚才说99的请求在10ms内,那平均的响应时常在多少呢?
A:平均响应时间都在1ms以内
Q:Proxy是否有出现瓶颈,有案例吗?如何解决类似情况?
A: Proxy是单Master多Work的,可以充分内用多核,cpu配置高更好了。并且Proxy是无状态的,可以水平扩展
Q:这些都是采用开源组件的吗?其他人也可以搭建吗,如何搭建的?
A:这个是因为Nginx支持之定义模块开发,所以需要在c/c++模块里面进行开发,并且进行埋点,压缩等工作。并不是搭建就可以的。
Q:我对那个平滑扩容的一直没太理解,貌似刚入群的时候我就问过了?
A:这个你可以学习Redis Cluster,它内部自身提供该功能。
Q:OpenResty Lua处理部分在当前使用比例?
A:批量接口用到了lua的协程,所以目前批量接口都是用lua+c/c++结合开发,普通接口目前都是用c/c++模块开发的。
Q:是否有开源的计划,这样大家也好研究?
A:后续我们对Proxy还有部分工作要进一步完善,例如在Proxy层加入Raft算法,加快失效节点判定,主动Failover。等完善的更健壮,会有开源的计划。
Q:在Proxy完成Failover对Redis Cluster的改动就大了?
A:Proxy只是去检查master节点是不是真的挂掉,然后多个Proxy进行判决,由一个Proxy给Redis Cluster发起主动Failover命令,不涉及改动Redis Cluster。
Q:不同业务部门的数据物理是存储在一起的吗?
A:不同的业务需要申请我们的合一平台集群资源,获得appkey,uri,每个业务都有自己的namespace,
你可以放到同一个集群,他们是通过namespace+key来进行逻辑隔离的,跟其它业务不会产生冲突。
如果对于非常重要的业务建议还是分开单独部署一套集群比较好。
Q: Nginxc/c++模块开发,特别c++开发,有学习资料共享吗?
A:对于Nginx提供几种模块开发Handler模块,SubRequest模块,Filter模块,Upstream模块,
我目前是有一本书《深入理解Nginx模块开发与架构解析》陶辉写的。
或者你可以看看tengine整理的教程http://tengine.taobao.org/book/
关于语言基础书推荐《C++ Primer Plus》
Q:mset即然是分成多个请求发到不同的Cluster节点,那么如果部分成功部分失败,Proxy如何给客户端返回结果?
A:对于mset我们采取的是要么全部成功,要么就是失败。
所以,针对你这种部分失败,我们内部也会有重试机制的,如果达到最大重试次数,这个时候就认为真的是失败的,
不过客户端可以根据失败进行再次重试。
Q:读写操作都是在master上执行的吗?
A:目前我们的读写都在master,如果slave提供读,你得容忍数据不一致,延迟的问题。
Q:Nginx上的LuaJIT的性能对Redis/Memcached影响大吗?比如LuaJIT的Intepreter模式跟LuaJIT的JIT方式,性能会在nginx+cache的这种架构下带来多少性能开销?
A:这个我有对比过纯c/c++模块跟lua模块的性能,确实有些损耗,经过优化效果还是不错,但是批量接口Nginx的subrequest效率本身就比较低。这块有Lua的协程来处理的。
Nginx是多进程的,这样用户请求可以充分利用多核。您说的LuaJIT这两种方式我没有具体对比过,不好意思。不过线下我们可以私聊,进步交流互相学习下。
Q: Redis在合一的应用场景
A:目前优土全站的视频播放数服务是我们最大的一个服务,每天支撑300多亿次的请求,峰值QPS在80w时,
整体系统的CPU在20%以下;另外还有用户视频推荐的相关信息等。
Q:Nginx+Redis Clustet这样的结果支持跨机房部署吗?能扩展读操作吗?
A:本着数据接近计算的原则,我们的服务是在多IDC部署的,每个应用方在申请资源时,
我们会给他分配一个最近的IDC提供资源,以最大限度保障服务可用性。
可以在Proxy层封装和扩展任何Redis底层的接口,另外也可以利用Redis本身嵌入Lua来扩展。
Q:对于用户来讲,是怎么说服他们使用你们包装的HTTP协议而不是原生Redis协议的?
A:提供统一的HTTP Restful接口,客户端不需要开发Smart
Client,对客户端完全透明、跨语言调用。这样不用依赖官方的驱动,
并且官方的驱动包有些bug,客户端也不好维护,并且得跟着官方驱动包升级,这个成本还是很大的。
相反如果是简单的HTTP RestfulProxy平滑升级即可,客户端不需要操作什么。
Q:24核心测试环境下只有18w qps其实不算太高的性能,单核心的Redis在没有Pipeline的情况下也有五六万的,Proxy会不会成为性能瓶颈?
A: 18w是控制cpu在50%以内,并且响应时间都在999
10ms以内,并不是极限压测。并且Proxy是无状态的,可以水平扩展。
Q: 你们规定的HTTP协议如何处理二进制存储需求的?
A:由于目前没有这种场景,所以目前并不支持二进制存储。