下载源码:
github地址
- 解压:
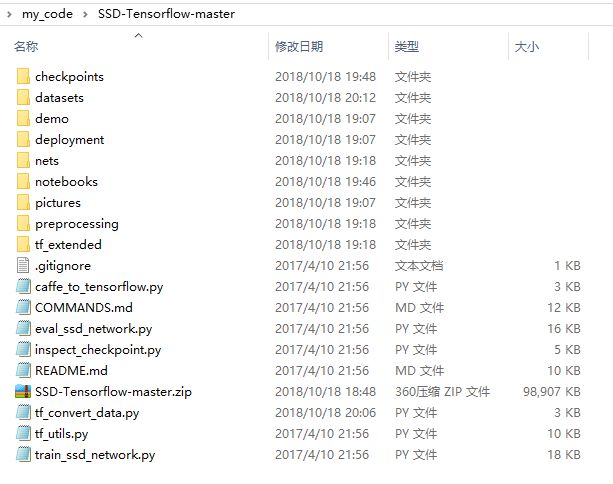
这里的代码比较全:
- datasets是数据工厂
- notebooks是测试文件
- checkpoints是cpkt文件,解压到当前目录。
- demo和pictures均是图片
- net是网络结构文件
- deployment是训练用的部署文件
开始玩玩这个代码
其他暂时未追究,分三步。
1.测试
2.验证
3.训练
测试
在notebook中有ssd_tests.ipynb文件
在SSD-Tensorflow-master根目录,在cmd中输入,shitf + 鼠标右键
jupyter notebook
会在浏览器打开jupyter notebook

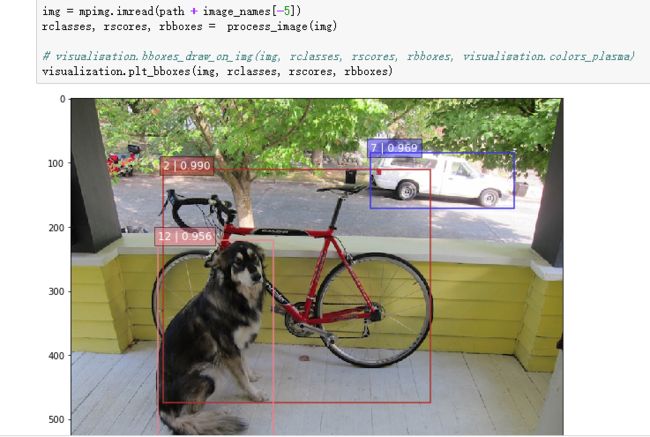
直接运行所有的cell,记得解压checkpoints的文件。
验证
先做数据,先还是下载VOC 2007数据
这里有数据地址:
链接:https://pan.baidu.com/s/15Tster6-DhDc1J5rhguHoA
提取码:1j36
- 先生成tfrecord
修改datasets/pascalvoc_to_tfrecords.py 代码,如下,

在根目录下运行tf_convert_data.py
公认的操作如下,linux下建立.sh文件:
DATASET_DIR=./VOC2007/test/
OUTPUT_DIR=./tfrecords
python tf_convert_data.py \
--dataset_name=pascalvoc \
--dataset_dir=${DATASET_DIR} \
--output_name=voc_2007_train \
--output_dir=${OUTPUT_DIR}
我是如下操作,没在cmd输入参数,修改了tf_convert_data.py的参数默认值。
tf.app.flags.DEFINE_string(
'dataset_name', 'pascalvoc',
'The name of the dataset to convert.')
tf.app.flags.DEFINE_string(
'dataset_dir', 'F:/my_code/object_detector/VOCdevkit/VOC2007/',
'Directory where the original dataset is stored.')
tf.app.flags.DEFINE_string(
'output_name', 'voc_2007_test',
'Basename used for TFRecords output files.')
tf.app.flags.DEFINE_string(
'output_dir', './datasets/',
'Output directory where to store TFRecords files.')
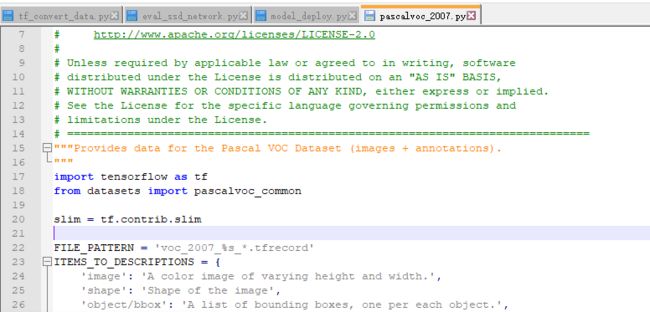
注意这里的
tf.app.flags.DEFINE_string(
'output_name', 'voc_2007_test',
'Basename used for TFRecords output files.')
最好以voc_2007_*_ 这样的格式,其他格式会报错,因为在pascalvoc_2007.py中如下。
制作train数据 和 test数据:
voc_2007_train 和 voc_2007_test
结果:
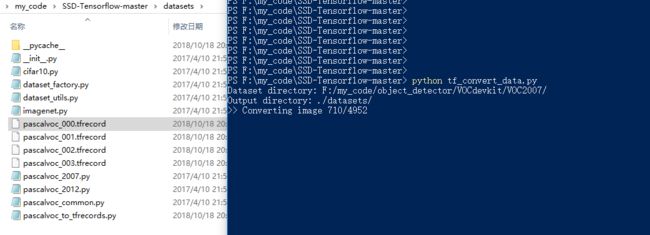
- 得到tfcord文件:

- 开始测试模型的精度
报错:

点这里解决
在eval_ssd_network.py加一个函数flatten()
def flatten(x):
result = []
for el in x:
if isinstance(el, tuple):
result.extend(flatten(el))
else:
result.append(el)
return result
如下:

再修改:
eval_op=flatten(list(names_to_updates.values())),
输入:
python .\eval_ssd_network.py
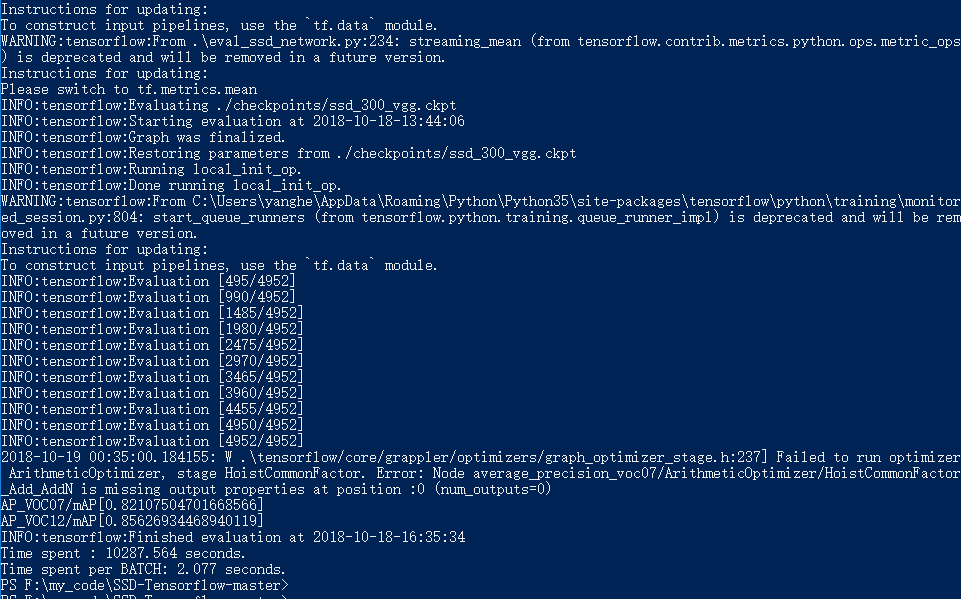
搞定得到日志文件:
运行tensorboard:

训练
- 生成数据
- 也是建立.sh文件。
#!/bin/bash
#The directory where the dataset files are stored.
DATASET_DIR=/home/doctorimage/kindlehe/common/dataset/VOC2007/VOCtrainval_06-Nov-2007/VOCdevkit/VOC2007_tfrecord/
#../../../../common/dataset/VOC2007/VOCtrainval_06-Nov-2007/VOCdevkit/VOC2007_tfrecord/
#Directory where checkpoints and event logs are written to.
TRAIN_DIR=.././log_files/log_finetune/
#The path to a checkpoint from which to fine-tune
CHECKPOINT_PATH=/home/doctorimage/kindlehe/common/models/tfmodlels/SSD/VGG_VOC0712_SSD_300x300_ft_iter_120000/VGG_VOC0712_SSD_300x300_ft_iter_120000.ckpt
#../../../../common/models/tfmodlels/SSD/VGG_VOC0712_SSD_300x300_ft_iter_120000/VGG_VOC0712_SSD_300x300_ft_iter_120000.ckpt
python3 ../train_ssd_network.py \
--train_dir=${TRAIN_DIR} \
--dataset_dir=${DATASET_DIR} \
--dataset_name=pascalvoc_2007 \
--dataset_split_name=train \
--model_name=ssd_300_vgg \
--checkpoint_path=${CHECKPOINT_PATH} \
--save_summaries_secs=60 \
--save_interval_secs=600 \
--weight_decay=0.0005 \
--optimizer=adam \
--learning_rate=0.001 \
--batch_size=32
我是win10玩家:
python ./train_ssd_network.py --train_dir=./train_model/ --dataset_dir=./tfrecords_/ --dataset_name=pascalvoc_2007 --dataset_split_name=train --model_name=ssd_300_vgg --checkpoint_path=./checkpoints/vgg16.ckpt --checkpoint_model_scope=vgg_16 --checkpoint_exclude_scopes=ssd_300_vgg/conv6,ssd_300_vgg/conv7,ssd_300_vgg/block8,ssd_300_vgg/block9,ssd_300_vgg/block10,ssd_300_vgg/block11,ssd_300_vgg/block4_box,ssd_300_vgg/block7_box,ssd_300_vgg/block8_box,ssd_300_vgg/block9_box,ssd_300_vgg/block10_box,ssd_300_vgg/block11_box --trainable_scopes=ssd_300_vgg/conv6,ssd_300_vgg/conv7,ssd_300_vgg/block8,ssd_300_vgg/block9,ssd_300_vgg/block10,ssd_300_vgg/block11,ssd_300_vgg/block4_box,ssd_300_vgg/block7_box,ssd_300_vgg/block8_box,ssd_300_vgg/block9_box,ssd_300_vgg/block10_box,ssd_300_vgg/block11_box --save_summaries_secs=60 --save_interval_secs=600 --weight_decay=0.0005 --optimizer=adam --learning_rate=0.001 --learning_rate_decay_factor=0.94 --batch_size=24 --gpu_memory_fraction=0.9
注意:
- –dataset_name=pascalvoc_2007
- –dataset_split_name=train
- –model_name=ssd_300_vgg这三个参数不要自己随便取,在代码里,这三个参数是if…else…语句,有固定的判断值,所以要根据实际情况取选择
- tf.contrib.slim.learning.training函数中max-step为None时训练会无限进行
参考:
Kindle君
SSD-tensorflow 测试与训练实践