Adding full support for a language touches many different parts of the spaCy library. This guide explains how to fit everything together, and points you to the specific workflows for each component.
添加一个完整的语言支持涉及很多不同部分的spaCy库,本文针对如何融合所有内容,并说明每个组件的工作流程。
WORKING ON SPACY'S SOURCE(使用spaCy资源)
To add a new language to spaCy, you'll need to modify the library's code. The easiest way to do this is to clone the repository and build spaCy from source. For more information on this, see the installation guide. Unlike spaCy's core, which is mostly written in Cython, all language data is stored in regular Python files. This means that you won't have to rebuild anything in between –you can simply make edits and reload spaCy to test them.
要为spaCy添加新语言,需要修改library的代码,最简单的方法是克隆repository(https://github.com/explosion/spaCy),之后从源码build。参见安装指南中关于此方法的详细内容。spaCy的核心代码基本上都是用Cython写的,不过所有的语言数据都是以常规的Python文件。这样就不需要重建任何代码,只需简单的修改和重新调用spaCy就可以进行语言测试。
Obviously, there are lots of ways you can organise your code when you implement your own language data. This guide will focus on how it's done within spaCy. For full language support, you'll need to create a Language subclass, define custom language data, like a stop list and tokenizer exceptions and test the new tokenizer. Once the language is set up, you can build the vocabulary, including word frequencies, Brown clusters and word vectors. Finally, you can train the tagger and parser, and save the model to a directory.
部署自定义语言数据时有很多方法可以组织代码。本文将聚焦于如何用spaCy完成。完整的语言支持,需要创建Language子集,声明自定义语言数据,比如停用词列表和例外分词,并且测试新的分词器。语言设置完成,就可以创建词汇表,包括词频、布朗集(Brown Cluster)和词向量。然后就可以训练并保存Tagger和Parser模型了。
For some languages, you may also want to develop a solution for lemmatization and morphological analysis.
对于有的语言,可能还可以开发词形还原和词型分析的方案。
Language data 语言数据
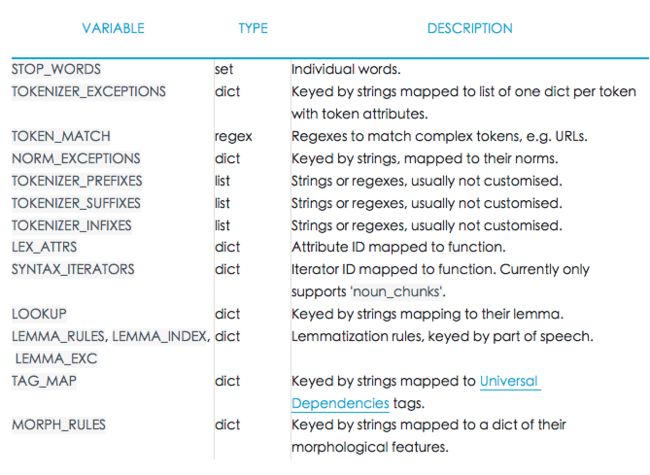
Every language is different – and usually full of exceptions and special cases, especially amongst the most common words. Some of these exceptions are shared across languages, while others are entirely specific – usually so specific that they need to be hard-coded. The lang module contains all language-specific data, organised in simple Python files. This makes the data easy to update and extend.
每一种语言都不相同 – 而且通常都有很多例外和特殊情况,尤其是最常见的词。其中一些例外情况是各语言间通用的,但其他的则是完全特殊的– 经常是特殊到需要硬编码。spaCy中的lang模块包含了大多数特殊语言数据,以简单的Python文件进行组织,以便于升级和扩展数据。
The shared language data in the directory root includes rules that can be generalised across languages – for example, rules for basic punctuation, emoji, emoticons, single-letter abbreviations and norms for equivalent tokens with different spellings, like " and ”. This helps the models make more accurate predictions. The individual language data in a submodule contains rules that are only relevant to a particular language. It also takes care of putting together all components and creating the Language subclass – for example,English or German.
在根目录中的通用语言数据包含了广义的跨语言规则,例如:基本的标点、表情符号、情感符号、单字母缩写的规则以及不同拼写的等义标记,比如“and”。这样有助于模型作出更准确的预测。子模块中的特定语言数据包含的规则仅与特定语言相关,还负责整合所有组件和创建语言子集– 例如:英语 或 德语。
from spacy.lang.en import English
from spacy.lang.de import German
nlp_en = English() # includes English data
nlp_de = German() # includes German data

Stop words stop_words.py
List of most common words of a language that are often useful to filter out, for example "and" or "I". Matching tokens will return True for is_stop.
停用词语言中进行数据处理之前或之后通常会自动过滤掉某些字或词的列表
Tokenizer exceptions tokenizer_exceptions.py
Special-case rules for the tokenizer, for example, contractions like “can’t” and abbreviations with punctuation, like “U.K.”.
例外分词特殊分词,例如:缩写can’t和带标点的缩写词U.K.(常规中文好像没这情况)
Norm exceptions norm_exceptions.py
Special-case rules for normalising tokens to improve the model's predictions, for example on American vs. British spelling.
Punctuation rules punctuation.py
Regular expressions for splitting tokens, e.g. on punctuation or special characters like emoji. Includes rules for prefixes, suffixes and infixes.
标点规则标点或特殊字符(如表情)等等正则表达式,包括前缀、后缀和连接符的规则。
Character classes char_classes.py
Character classes to be used in regular expressions, for example, latin characters, quotes, hyphens or icons.
字符集正则表达式中所用的字符集,例如:拉丁、引用、连字符或图标等
Lexical Attributes lex_attrs.py
Custom functions for setting lexical tributes on tokens, e.g. like_num, which includes language-specific words like “ten” or “hundred”.
词性例如:like_num:包括十、百、千等特殊词。
Syntax iterators syntax_iterators.py
Functions that compute views of a Doc object based on its syntax. At the moment, only used for noun-chunkes。
Lemmatizer lemmatizer.py
Lemmatization rules or a lookup-based lemmatization table to assign base forms, for example "be" for "was".
词型还原英语讨厌的时态、单复数,伟大的中文不这么土
Tag map tag_map.py
Dictionary mapping strings in your tag set to Universal Dependencies tags.
Morph rules morph_rules.py
Exception rules for morphological analysis of irregular words like personal pronouns.
词变形规则
The individual components expose variables that can be imported within a language module, and added to the language's Defaults. Some components, like the punctuation rules, usually don't need much customisation and can simply be imported from the global rules. Others, like the tokenizer and norm exceptions, are very specific and will make a big difference to spaCy's performance on the particular language and training a language model.
个别组件可以到语言模块中,被加入到语言的Defaults。有些组件比如标点符号规则,通常不需要很多自定义,而是简单的引入通用规则。其他的如tokenizer和norm exceptions很特别,会较大程度上影响spaCy对特定语言和训练语言模型的性能效果。
SHOULDI EVER UPDATE THE GLOBAL DATA?
Reuseable language data is collected as atomic pieces in the root of the spacy.lang package. Often, when a new language is added, you'll find a pattern or symbol that's missing. Even if it isn't common in other languages, it might be best to add it to the shared language data, unless it has some conflicting interpretation. For instance, we don't expect to see guillemot quotation symbols (» and «) in English text. But if we do see them, we'd probably prefer the tokenizer to split them off.
是否应更新全局数据
可复用的语言数据作为原子碎片被置于spacy.lang包的根节点。通常,添加新语言后,会发现有图案或符号缺失。即使在其他语言中并不常见,或许最好还是将其加入通用语言数据中,除非有冲突。
FORLANGUAGES WITH NON-LATIN CHARACTERS
In order for the tokenizer to split suffixes, prefixes and infixes, spaCy needs to know the language's character set. If the language you're adding uses non-latin characters, you might need to add the required character classes to the global char_classes.py . spaCy uses the regex library to keep this simple and readable. If the language requires very specific punctuation rules, you should consider overwriting the default regular expressions with your own in the language's Defaults.
中文的全角标点符号需要定义。
The Language subclass 语言子集
Language-specific code and resources should be organised into a subpackage of spaCy, named according to the language's ISO code. For instance, code and resources specific to Spanish are placed into a directory spacy/lang/es, which can be imported as spacy.lang.es.
特定语言代码和资源应组织为spaCy的子包,以语言标准编码(ISO)命名,例如:中文应位于spacy/lang/zh目录,就能够以 spacy.lang.zh 引入了。
To get started, you can use our templates for the most important files. Here's what the class template looks like:
最重要的文件的模版:
__INIT__.PY (EXCERPT)
# import language-specific data
from .stop_words import STOP_WORDS
from .tokenizer_exceptions import TOKENIZER_EXCEPTIONS
from .lex_attrs import LEX_ATTRS
from ..tokenizer_exceptions import BASE_EXCEPTIONS
from ...language import Language
from ...attrs import LANG
from ...util import update_exc
# create Defaults class in the module scope (necessary for pickling!)
class XxxxxDefaults(Language.Defaults):
lex_attr_getters = dict(Language.Defaults.lex_attr_getters)
lex_attr_getters[LANG] = lambda text: 'xx' # language ISO code
# optional: replace flags with custom functions, e.g. like_num()
lex_attr_getters.update(LEX_ATTRS)
# merge base exceptions and custom tokenizer exceptions
tokenizer_exceptions = update_exc(BASE_EXCEPTIONS, TOKENIZER_EXCEPTIONS)
stop_words = STOP_WORDS
# create actual Language class
class Xxxxx(Language):
lang = 'xx' # language ISO code
Defaults = XxxxxDefaults # override defaults
# set default export – this allows the language class to be lazy-loaded
__all__ = ['Xxxxx']
WHY LAZY-LOADING?
Some languages contain large volumes of custom data, like lemmatizer lookup tables, or complex regular expression that are expensive to compute. As of spaCy v2.0, Language classes are not imported on initialisation and are only loaded when you import them directly, or load a model that requires a language to be loaded. To lazy-load languages in your application, you can use the util.get_lang_class() helper function with the two-letter language code as its argument.
为什么要延迟加载
有些语言包含大量的定制数据,复杂规则等,计算成本很高。spaCy2.0中,语言集不在初始化时引入,仅于import的时候才加载,或者加载包含语言的模型。在应用中延迟加载语言,使用util.get_lang_class(),参数为两位语言编码。
Stop words 停用词
A "stop list" is a classic trick from the early days of information retrieval when search was largely about keyword presence and absence. It is still sometimes useful today to filter out common words from a bag-of-words model. To improve readability, STOP_WORDS are separated by spaces and newlines, and added as a multiline string.
停用词意义不用多说了,一切为了效率和质量。
WHAT DOES SPACY CONSIDER ASTOP WORD?
There's no particularly principled logic behind what words should be added to the stop list. Make a list that you think might be useful to people and is likely to be unsurprising. As a rule of thumb, words that are very rare are unlikely to be useful stop words.
spaCy是如何考虑停用词的?
关于什么词应该加入停用词表,没有什么特别的原则性逻辑。建议直接参考使用复旦或哈工大的停用词,比较成熟。
关键还是怎么定义怎么用,看定义样例:
EXAMPLE
STOP_WORDS = set(""" a about above across after afterwards again against all almost alone along already also although always am among amongst amount an and another any anyhow anyone anything anyway anywhere are around as at back be became because become becomes becoming been before before hand behind being below beside besides between beyond both bottom but by """).split())
样例中引号里的一堆词就是停用词们,把中文的停用词表加进去就OK了。
IMPORTANT NOTE
When adding stop words from an online source, always include the link in a comment. Make sure to proofread and double-check the words carefully. A lot of the lists available online have been passed around for years and often contain mistakes, like unicode errors or random words that have once been added for a specific use case, but don't actually qualify.
重要!!!
一定要反复校对那些词,网上的很多词表已经过时了,而且经常有错误(最常见unicode错误)。
Tokenizer exceptions 例外分词
spaCy's tokenization algorithm lets you deal with whitespace-delimited chunks separately. This makes it easy to define special-case rules, without worrying about how they interact with the rest of the tokenizer. Whenever the key string is matched, the special-case rule is applied, giving the defined sequence of tokens. You can also attach attributes to the subtokens, covered by your special case, such as the subtokens LEMMA orTAG.
spaCy的分词算法可以处理空格和tab分隔。很容易定义特殊情况规则,不需担心与其他分词器的相互影响。一旦key string匹配,规则就会生效,给出定义好的分词序列。也可以附加属性覆盖特殊情况定义,例如 LEMMA 或 TAG。
IMPORTANTNOTE
If an exception consists of more than one token, the ORTH values combined always need to match the original string. The way the original string is split up can be pretty arbitrary sometimes –for example "gonna" is split into"gon" (lemma "go") and "na" (lemma"to"). Because of how the tokenizer works, it's currently not possible to split single-letter strings into multiple tokens.
重要!!!
例如:Gonna 定义为 gon(go)和 na(to),单个字母不可能再split。中文没这么垃圾的东西吧。
Unambiguous abbreviations, like month names or locations in English, should be added to exceptions with a lemma assigned, for example {ORTH: "Jan.", LEMMA: "January"}. Since the exceptions are added in Python, you can use custom logic to generate them more efficiently and make your data less verbose. How you do this ultimately depends on the language. Here's an example of how exceptions for time formats like"1a.m." and "1am" are generated in the English tokenizer_exceptions.py:
缩写问题,月份缩写,地点缩写等,例如:Jan. 还原为 January,那么中文就还原为 一月吧,具体情况取决于语言,比如定制中文时,忽略 Jan这种情况。以下是英文时间的定义样例tokenizer_exceptions.py:
# use short, internal variable for readability
_exc = {}
for h in range(1, 12 + 1):
for period in["a.m.", "am"]:
# always keep an eye onstring interpolation!
_exc["%d%s" %(h, period)] = [
{ORTH: "%d"% h},
{ORTH: period, LEMMA:"a.m."}]
for period in["p.m.", "pm"]:
_exc["%d%s" %(h, period)] = [
{ORTH: "%d"% h},
{ORTH: period, LEMMA:"p.m."}]
# only declare this at the bottom
TOKENIZER_EXCEPTIONS = _exc
GENERATINGTOKENIZER EXCEPTIONS
Keep in mind that generating exceptions only makes sense if there's a clearly defined and finite number of them, like common contractions in English. This is not always the case –in Spanish for instance, infinitive or imperative reflexive verbs and pronouns are one token (e.g. "vestirme"). Incases like this, spaCy shouldn't be generating exceptions for all verbs.Instead, this will be handled at a later stage during lemmatization.
生成TOKENIZER EXCEPTIONS
要注意,只有明确定义的和有限数量的例外定义才合理,比如英文中的常见缩写。其他语言视具体情况不同,spaCy不能够为所有词汇生成例外规则。可以试试后文提到的lemmatization(词干提取)。
When adding the tokenizer exceptions to theDefaults, you can use the update_exc() helper function to merge them with the global base exceptions (including one-letter abbreviations and emoticons). The function performs a basic check to make sure exceptions are provided in the correct format. It can take any number of exceptions dicts as its arguments, and will update and overwrite the exception in this order. For example, if your language's tokenizer exceptions include a custom tokenization pattern for "a.", it will overwrite the base exceptions with the language's custom one.
在缺省定义中添加tokenizer exceptions时,可以使用update_exc() 辅助函数以合并至全局设置(包括单字符缩写和表情)。该函数执行基本的格式合法性检验,且可以使用多个例外字典作为参数,并且将更新覆盖原定义。
EXAMPLE
from ...util import update_exc
BASE_EXCEPTIONS = {"a.": [{ORTH: "a."}], ":)": [{ORTH:":)"}]}
TOKENIZER_EXCEPTIONS = {"a.": [{ORTH: "a.", LEMMA:"all"}]}
tokenizer_exceptions = update_exc(BASE_EXCEPTIONS, TOKENIZER_EXCEPTIONS)
# {"a.": [{ORTH: "a.", LEMMA: "all"}],":}": [{ORTH: ":}"]]}
ABOUTSPACY'S CUSTOM PRONOUN LEMMA
Unlike verbs and common nouns, there's no clear base form of a personal pronoun. Should the lemma of "me" be "I", or should we normalize person as well, giving "it" —or maybe "he"? spaCy's solution is to introduce a novel symbol, -PRON-, which is used as the lemma for all personal pronouns.
关于spaCy的代词词元定义
不同于动词和常规名词,人称代词没有基本格式。中文比英文好些,拿英文说事吧,me应该是I,或者应该规范为人也行,还有it或者也可以是he?spaCy的解决方案是引入一个专有标志 –PRON- ,用来标记所有人称代词。
Norm exceptions 例外规范
In addition to ORTH or LEMMA, tokenizer exceptions can also set a NORM attribute. This is useful to specify a normalised version of the token –for example, the norm of "n't" is "not". By default, a token's norm equals its lowercase text. If the lowercase spelling of a word exists, norms should always be in lowercase.
除了ORTH和词元之外,tokenizer exceptions也可以设置一个规范属性。指定一个标准版本的token很有用,例如,还是英文举例(中文好像没这么乱吧):n’t是not。默认情况下,一个token的规范是小写文本。如果一个词的小写存在,规范应该一直是小写(中文的小写大写问题好像只有数字吧,该不该算进去呢?)。
NORMS VS. LEMMAS
doc = nlp(u"I'm gonna realise")
norms = [token.norm_ for token in doc]
lemmas = [token.lemma_ for token in doc]
assert norms == ['i', 'am', 'going', 'to', 'realize']
assert lemmas == ['i', 'be', 'go', 'to', 'realise']
spaCy usually tries to normalise words with different spellings to a single, common spelling. This has no effect on any other token attributes, or tokenization in general, but it ensures that equivalent tokens receive similar representations. This can improve the model's predictions on words that weren't common in the training data, but are equivalent to other words –for example, "realize" and "realise", or "thx" and"thanks".
spaCy通常会尝试将同一个词的不同拼写规范化,常规化(这就是拼写文字和象形文字的不同了)。这在其他token属性或一般tokenization中没有效果,但是这确保等效tokens得到类似的表述。这样就能够提升模型对那些在训练数据中不常见,但是同其他词差不多的词的预测能力,例如:realize和realizse,或者thx和thanks。(中文有啥?谢了 – 谢谢了 – 谢谢您了 – 太谢谢您了 ……中文有这必要吗)
Similarly, spaCy also includes global base norms for normalising different styles of quotation marks and currency symbols. Even though $ and €are very different, spaCy normalises them both to $. This way, they'll always be seen as similar, no matter how common they were in the training data.
同样的,spaCy也包括将不通类型的引号和货币符号规范化的全局基本规范(https://github.com/explosion/spaCy/blob/master/spacy/lang/norm_exceptions.py)。即使 $ 和¥ 有很大差别,spaCy会将它们统一规范为 $。这样,不论它们在训练数据中有多常见,都将被同等处理。
Norm exceptions can be provided as a simple dictionary. For more examples, see the English norm_exceptions.py .
Norm exceptions可以被作为一个简单的字典。更多样例参见英文语言中的norm_exceptions.py
EXAMPLE
NORM_EXCEPTIONS = {
"cos":"because",
"fav":"favorite",
"accessorise":"accessorize",
"accessorised":"accessorized"
}
To add the custom norm exceptions lookup table, you can use the add_lookups() helper functions. It takes the default attribute getter function as its first argument, plus a variable list of dictionaries. If a string's norm is found in one of the dictionaries, that value is used – otherwise, the default function is called and the token is assigned its default norm.
通过add_lookups()辅助函数来添加自定义norm exceptions查询表。它使用默认属性的getter函数作为其第一个参数,外加一个字典变量表。如果在某个字典中发现了一个字符串的规范,则取值– 否则,调用默认函数并且将默认规范赋值给token。
lex_attr_getters[NORM] =add_lookups(Language.Defaults.lex_attr_getters[NORM], NORM_EXCEPTIONS, BASE_NORMS)
The order of the dictionaries is also the lookup order –so if your language's norm exceptions overwrite any of the global exceptions, they should be added first.Also note that the tokenizer exceptions will always have priority over the attribute getters.
字典的排序也是查询排序– 所以,如果语言的norm exceptions覆盖了任何全局exceptions,将被首先添加。同时注意tokenizer exceptions总是优先于属性getter。
Lexical attributes 词性
spaCy provides a range of Token attributes that return useful information on that token –for example, whether it's uppercase or lowercase, a left or right punctuation mark, or whether it resembles a number or email address. Most of these functions, like is_lower or like_url should be language-independent. Others, like like_num(which includes both digits and number words), requires some customisation.
spaCy提供了一堆Token属性来返回token的有用信息,例如:无论大写还是小写形式,左右引号,或不论是类似于数字或email地址。大部分函数,比如:is_lower或者like_urls都应该是独立语言的。其他的像like_num(包括数字和大写数字),则需要进行定制。
BEST PRACTICES
English number words are pretty simple, because even large numbers consist of individual tokens, and we can get away with splitting and matching strings against a list. In other languages, like German, "two hundred and thirty-four" is one word, and thus one token. Here, it's best to match a string against a list of number word fragments (instead of a technically almost infinite list of possible number words).
最佳方案
英文数字单词非常简单,因为即使大数字也是由独立的tokens组成的,我们可以避免分隔和靠列表匹配字符串。其他语言中,比如德语,two hundred and thirty-four是一个词,也是一个token。这里最好是基于一个数字单词片段的列表(而不是技术上几乎无限的可能的数字单词的列表)进行字符串匹配。(这一块中文也应该是一样原理了)
英文词性定义样例:
LEX_ATTRS.PY
_num_words = ['zero', 'one', 'two', 'three', 'four', 'five', 'six','seven',
'eight', 'nine','ten', 'eleven', 'twelve', 'thirteen', 'fourteen',
'fifteen','sixteen', 'seventeen', 'eighteen', 'nineteen', 'twenty',
'thirty', 'forty','fifty', 'sixty', 'seventy', 'eighty', 'ninety',
'hundred','thousand', 'million', 'billion', 'trillion', 'quadrillion',
'gajillion','bazillion']
def like_num(text):
text = text.replace(',','').replace('.', '')
if text.isdigit():
return True
if text.count('/') == 1:
num, denom =text.split('/')
if num.isdigit() anddenom.isdigit():
return True
if text.lower() in _num_words:
return True
return False
LEX_ATTRS = {
LIKE_NUM: like_num
}
By updating the default lexical attributeswith a custom LEX_ATTRS dictionary in the language's defaults vialex_attr_getters.update(LEX_ATTRS), only the new custom functions are overwritten.
通过lex_getters.update(LEX_ATTRS)使用一个定制LEX_ATTRS字典更新语言默认词性属性,只有新定义的函数会被覆盖。
Syntax iterators 语法迭代器
Syntax iterators are functions that compute views of a Doc object based on its syntax. At the moment, this data is only used for extracting noun chunks, which are available as the Doc.noun_chunks property.Because base noun phrases work differently across languages, the rules to compute them are part of the individual language's data. If a language does not include a noun chunks iterator, the property won't be available. For examples, see the existing syntax iterators:
语法迭代器是计算基于语法的DOC对象的视图的函数。目前,数据仅用来提取词块,其属性为Doc.noun_chunks。因为基本名词短语的工作各语言不同,计算规则为各语言数据的一部分。如果语言不包含一个词块迭代器,则没有noun_chunks属性。如下例:
NOUN CHUNKS EXAMPLE
doc = nlp(u'A phrase with another phrase occurs.')
chunks = list(doc.noun_chunks)
assert chunks[0].text == "A phrase"
assert chunks[1].text == "another phrase"

Lemmatizer词形还原器
As of v2.0, spaCy supports simple lookup-based lemmatization. This is usually the quickest and easiest way to get started. The data is stored in a dictionary mapping a string to its lemma. To determine a token's lemma, spaCy simply looks it up in the table. Here's an example from the Spanish language data:
截至v2.0,spaCy支持简单的基于查询的词形还原。这一般是最快最简单的入门方法。字典数据映射词形字符串。要判定一个token的词形,spaCy会于查询表中快速查找。西班牙文样例:
LANG/ES/LEMMATIZER.PY (EXCERPT)
LOOKUP = {
"aba":"abar",
"ababa":"abar",
"ababais":"abar",
"ababan":"abar",
"ababanes":"ababán",
"ababas":"abar",
"ababoles":"ababol",
"ababábites":
"ababábite"
}
To provide a lookup lemmatizer for your language, import the lookup table and add it to the Language class as lemma_lookup:
引入查询表到语言子集的lemma_lookup,为语言提供词型还原器,方法如下例:
lemma_lookup = dict(LOOKUP)
Tag map
Most treebanks define a custom part-of-speechtag scheme, striking a balance between level of detail and ease of prediction. While it's useful to have custom tagging schemes, it's also useful to have a common scheme, to which the more specific tags can be related. The tagger can learn a tag scheme with any arbitrary symbols. However, you need to define how those symbols map down to the Universal Dependencies tag set. This is done by providing a tag map.
多数树库都声明一个自定义词类标签体系,打破细节和易预测性水平之间的平衡(没搞明白)。自定义标签体系很有用,常规体系也很有用,其中更多的标签可以关联起来。标记器能够以任意符号学习一个标签体系。不过需要定义这些符号映射到Universal Dependencies tag set(这玩意儿很有用)。这就要通过提供一个tag map做到了。
The keys of the tag map should be strings in your tag set. The values should be a dictionary. The dictionary must have an entry POS whose value is one of the Universal Dependencies tags. Optionally, you can also include morphological features or other token attributes in the tag map as well. This allows you to do simple rule-based morphological analysis.
Tag map的keys应该是标签集中的字符串。Value应该是字典。字典必须有POS记录,其值为Universal Dependencies tags中的一个。另外,还可以在tag map中包含词法特征或者token的其他属性,这样就可以进行简单的基于规则的形态分析了。
下面看样例:
EXAMPLE
from ..symbols import POS, NOUN, VERB, DET
TAG_MAP = {
"NNS": {POS: NOUN, "Number":"plur"},
"VBG": {POS: VERB, "VerbForm":"part", "Tense": "pres", "Aspect":"prog"},
"DT": {POS: DET}
}
Morph rules 形态规则
The morphology rules let you set token attributes such as lemmas, keyed by the extended part-of-speech tag and token text. The morphological features and their possible values are language-specific and based on the Universal Dependencies scheme.
形态规则设置token的属性,比如词形,键的扩展词性标签和token的文本。词法(形态)特征及其可能的值为语言特征,且基于Universal Dependencies体系。
EXAMPLE
from ..symbols import LEMMA
MORPH_RULES = {
"VBZ": {
"am": {LEMMA:"be", "VerbForm": "Fin", "Person":"One", "Tense": "Pres", "Mood":"Ind"},
"are": {LEMMA:"be", "VerbForm": "Fin", "Person":"Two", "Tense": "Pres", "Mood":"Ind"},
"is": {LEMMA:"be", "VerbForm": "Fin", "Person":"Three", "Tense": "Pres", "Mood":"Ind"},
"'re": {LEMMA:"be", "VerbForm": "Fin", "Person":"Two", "Tense": "Pres", "Mood":"Ind"},
"'s": {LEMMA:"be", "VerbForm": "Fin", "Person":"Three", "Tense": "Pres", "Mood":"Ind"}
}
}
上例中“am”的属性如下:

IMPORTANT NOTE
The morphological attributes are currently not all used by spaCy. Full integration is still being developed. In the meantime, it can still be useful to add them, especially if the language you're adding includes important distinctions and special cases. This ensures that as soon as full support is introduced, your language will be able to assign all possible attributes.
重要!!!
形态属性目前没有完全应用于spaCy,完整内容还在开发中。其间,加上该属性还是很有用的,特别是如果添加的语言包含重要区别和特殊情况。这样就确保了当完整支持完成后,就可以快速引入所有可能的属性了。
Testing the language 测试语言
Before using the new language or submitting a pull request to spaCy, you should make sure it works as expected. This is especially important if you've added custom regular expressions for token matching or punctuation –you don't want to be causing regressions.
在使用一个新的语言或者向spaCy提交更新请求前,应确定它能达到预期。特别重要的是如果添加了自定义token匹配或标点符号的正则表达式,省的后悔。。。
SPACY'STEST SUITE
spaCy uses the pytest framework for testing.For more details on how the tests are structured and best practices for writing your own tests, see our tests documentation.
spaCy的测试包
spaCy使用pytest框架进行测试。关于更多的测试结构和制作自己的测试的最佳方案,参见测试文档https://github.com/explosion/spaCy/blob/master/spacy/tests
The easiest way to test your new tokenizer is to run the language-independent "tokenizer sanity" tests located in tests/tokenizer . This will test for basic behaviours like punctuation splitting, URL matching and correct handling of whitespace. In the conftest.py, add the new language ID to the list of _languages:
测试新tokenizer的最简单方法是运行“tokenizer sanity”,位于tests/tokenizer。这将对一些基本功能进行测试,如标点符号分隔,URL匹配以及空格的正确处理(中文还空格?)。在conftest.py文件的_languages列表中添加新语言的ID。
_languages = ['bn', 'da', 'de', 'en', 'es', 'fi', 'fr', 'he', 'hu', 'it','nb',
'nl', 'pl', 'pt','sv', 'xx'] # new language here
GLOBAL TOKENIZER TEST EXAMPLE
# use fixture by adding it as an argument
def test_with_all_languages(tokenizer):
# will be performed on ALL language tokenizers
tokens = tokenizer(u'Some texthere.')
The language will now be included in the tokenizer test fixture, which is used by the basic tokenizer tests. If you want to add your own tests that should be run over all languages, you can use this fixture as an argument of your test function.
现在语言已经被包含到tokenizer测试fixture里了,用来进行基本的tokenizer测试。如果想用自己的测试运行所有语言,可以将这个fixture以参数形式加入测试函数。
Writing language-specific tests 写一个特定语言的测试
It's recommended to always add at least some tests with examples specific to the language. Language tests should be located in tests/lang in a directory named after the language ID. You'll also need to create a fixture for your tokenizer in the conftest.py . Always use the get_lang_class() helper function within the fixture, instead of importing the class at the top of the file. This will load the language data only when it's needed. (Otherwise, all data would be loaded every time you run a test.)
强烈推荐为定制的语言添加测试集。语言测试集应位于tests/lang路径内的以语言ID命名的目录中。同时,需要在conftest.py中创建一个fixture。在fixture内使用get_lang_class()函数,不要在文件头import class。这样就会仅在需要时加载语言数据。(否则,在每次执行测试时都会加载所有数据,就累了。。。)
@pytest.fixture
def en_tokenizer():
returnutil.get_lang_class('en').Defaults.create_tokenizer()
When adding test cases, always parametrize them –this will make it easier for others to add more test cases without having to modify the test itself. You can also add parameter tuples, for example, a test sentence and its expected length, or a list of expected tokens. Here's an example of an English tokenizer test for combinations of punctuation and abbreviations:
添加测试案例时,使其参数化,以便于别人方便的添加更多测试案例,而不用去修改测试主体。还可以添加参数元祖,比如:一条测试语句及其预期长度,或者预期tokens的列表。下面例子是一个英文的标点符号和缩写组合的tokenizer测试:
EXAMPLE TEST
@pytest.mark.parametrize('text,length', [
("The U.S. Army likesShock and Awe.", 8),
("U.N. regulations arenot a part of their concern.", 10),
("“Isn't
it?”", 6)])
def test_en_tokenizer_handles_punct_abbrev(en_tokenizer, text, length):
tokens = en_tokenizer(text)
assert len(tokens) == length
Training训练一个语言模型
spaCy expects that common words will be cached in a Vocab instance. The vocabulary caches lexical features, and makes it easy to use information from unlabelled text samples in your models. Specifically, you'll usually want to collect word frequencies, and train word vectors. To generate the word frequencies from a large, raw corpus, you can use the word_freqs.py script from the spaCy developer resources.
spaCy认为一般词汇都可以在词汇表实例中获得。词汇获得词性标注,使用模型为标记的文本信息也变得简单了。特别是收集词频,训练词向量。从一个又大又新大语料中生成词频,可以使用spaCy developer resources中的word_freqs.py。
Note that your corpus should not be preprocessed (i.e. you need punctuation for example). The word frequencies should be generated as a tab-separated file with three columns:
1、The number of times the word occurred in your language sample.
2、The number of distinct documents the word occurred in.
3、The word itself.
注意:语料需未经预处理(即要为样本加上标点符号)。词频文件应被生成为tab分隔的三列内容:
第一列:词条在语言样品出现的次数。
第二列:出现词条的文档数
第三列:词条内容
ES_WORD_FREQS.TXT
6361109 111 Aunque
23598543 111 aunque
10097056 111 claro
193454 111 aro
7711123 111 viene
12812323 111 mal
23414636 111 momento
2014580 111 felicidad
233865 111 repleto
15527 111 eto
235565 111 deliciosos
17259079 111 buena
71155 111 Anímate
37705 111 anímate
33155 111 cuéntanos
2389171 111 cuál
961576 111 típico
BROWN CLUSTERS 布朗聚类
Additionally, you can use distributional similarity features provided by the Brown clustering algorithm.You should train a model with between 500 and 1000 clusters. A minimum frequency threshold of 10 usually works well.
另外,可以使用布朗聚类算法提供的分布相似性特征。可以训练一个500-1000clusters的模型,最低频的阀值为10通常效果不错。
You should make sure you use the spaCy tokenizer for your language to segment the text for your word frequencies. This will ensure that the frequencies refer to the same segmentation standards you'll be using at run-time. For instance, spaCy'sEnglish tokenizer segments "can't" into two tokens. If we segmented the text by whitespace to produce the frequency counts, we'll have incorrect frequency counts for the tokens "ca" and "n't".
你应该确定要用spaCy的tokenizer为你的语言进行词频的分词。这样就可以确保在运行时,词频参考相同的分词标准。比如说,spaCy的英文tokenizer将can’t分词为两个tokens。如果用空格处理词频计数,结果将出现ca和n’t的错误词频计数。
Training the word vectors 训练词向量
Word2vec and related algorithms let you train useful word similarity models from unlabelled text.This is a key part of using deep learning for NLP with limited labelled data.The vectors are also useful by themselves – they power the .similarity()methods in spaCy. For best results, you should pre-process the text with spaCy before training the Word2vec model. This ensures your tokenization will match.You can use our word vectors training script , which pre-processes the text with your language-specific tokenizer and trains the model using Gensim. The vectors.bin file should consist of one word and vector per line.
Word2vec以及相关算法能够从未标记文本中训练有用的词条相似度模型,这是对有限标记数据NLP的关键部分。向量本身也是很有用的-power了spaCy中的.similarity()函数。为了最佳结果,训练word2vec模型之前应该先用spaCy对文本进行预处理,这就确保了tokenizer能够匹配。可以直接用spaCy的vector训练脚本(https://github.com/explosion/spacy-dev-resources/blob/master/training/word_vectors.py),对定制语言文本tokenizer进行预处理,并且用Gensim(https://radimrehurek.com/gensim/)训练模型。vectors.bin文件的每一行包含一个词条和向量值。
Training the tagger and parser 训练标签器和解释器
You can now train the model using a corpus for your language annotated with Universal Dependencies.If your corpus uses the CoNLL-U format, i.e. files with the extension .conllu, you can use the convert command to convert it to spaCy's JSON format for training. Once you have your UD corpus transformed into JSON, you can train your model use the using spaCy's train command.
现在可以用定制语言的语料和Universal Dependencies训练模型了。如果语料使用CoNLL-U格式,即以.conllu为扩展名的文件,可以用convert命令将其转换为spaCy的JSON格式进行训练。UD语料转换为JSON后就可以用spaCy的train命令训练模型了。
For more details and examples of how to train the tagger and dependency parser, see the usage guide on training.
更关于训练tagger和parser的细节和样例请看分析模型训练指南。