定位
基于数据库增量日志解析,提供增量数据订阅和消费
工作原理

- canal 模拟 MySQL slave 的交互协议,伪装自己为 MySQL slave ,向 MySQL master 发送dump 协议
- MySQL master 收到 dump 请求,开始推送 binary log 给 slave (即 canal )
- canal 解析 binary log 对象(原始为 byte 流)
QuickStart
1.配置MySQL
- 开启MySql的binlog功能
/usr/local/etc/my.cnf
[mysqld]
log-bin=mysql-bin # 开启 binlog
binlog-format=ROW # 选择 ROW 模式
server_id=1 # 配置 MySQL replaction 需要定义,不要和 canal 的 slaveId 重复
简单测试,my.cnf配置是否生效
mysql> show variables like 'binlog_format';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| binlog_format | ROW |
+---------------+-------+
mysql> show variables like 'log_bin';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| log_bin | ON |
+---------------+-------+
- 授权 canal 链接 MySQL 账号具有作为 MySQL slave 的权限, 如果已有账户可直接 grant
CREATE USER canal IDENTIFIED BY 'canal';
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON . TO 'canal'@'%';
FLUSH PRIVILEGES;
mysql> show grants for 'canal';
+---------------------------------------------------------------------------+
| Grants for canal@% |
+---------------------------------------------------------------------------+
| GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON . TO 'canal'@'%' |
+---------------------------------------------------------------------------+
1 row in set (0.00 sec)
2. 下载解压
下载地址: https://github.com/alibaba/canal/releases/
这里以1.1.3为例
https://github.com/alibaba/canal/releases/download/canal-1.1.3/canal.deployer-1.1.3.tar.gz
解压
tar zxvf canal.deployer-$version.tar.gz
项目结构
修改配置
vi conf/example/instance.properties
## mysql serverId
canal.instance.mysql.slaveId = 1
#position info,需要改成自己的数据库信息
canal.instance.master.address = 127.0.0.1:3306
canal.instance.master.journal.name =
canal.instance.master.position =
canal.instance.master.timestamp =
#canal.instance.standby.address =
#canal.instance.standby.journal.name =
#canal.instance.standby.position =
#canal.instance.standby.timestamp =
#username/password,需要改成自己的数据库信息
canal.instance.dbUsername = canal
canal.instance.dbPassword = canal
canal.instance.defaultDatabaseName =
canal.instance.connectionCharset = UTF-8
#table regex
canal.instance.filter.regex = .\*\\\\..\*
- canal.instance.connectionCharset 代表数据库的编码方式对应到 java 中的编码类型,比如 UTF-8,GBK , ISO-8859-1
- 如果系统是1个 cpu,需要将 canal.instance.parser.parallel 设置为 false
3.启动
- 启动
sh bin/startup.sh
- 查看日志
vi logs/canal/canal.log
com.alibaba.otter.canal.deployer.CanalStater - ## the canal server is running now ......
- 查看 instance 的日志
vi logs/example/example.log
c.a.otter.canal.instance.core.AbstractCanalInstance - start successful...
- 关闭
sh bin/stop.sh
启动模式
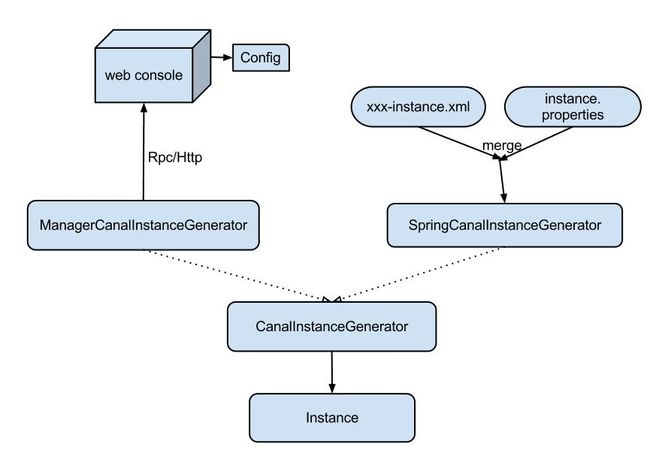
canal配置方式有两种:
ManagerCanalInstanceGenerator: 基于manager管理的配置方式,目前alibaba内部配置使用这种方式。大家可以实现CanalConfigClient,连接各自的管理系统,即可完成接入。
SpringCanalInstanceGenerator:基于本地spring xml的配置方式,目前开源版本已经自带该功能所有代码,建议使用
1. Spring配置
spring配置的原理是将整个配置抽象为两部分:
- xxxx-instance.xml (canal组件的配置定义,可以在多个instance配置中共享)
- xxxx.properties (每个instance通道都有各自一份定义,因为每个mysql的ip,帐号,密码等信息不会相同)
通过spring的PropertyPlaceholderConfigurer通过机制将其融合,生成一份instance实例对象,每个instance对应的组件都是相互独立的,互不影响
1.1 properties配置文件
properties配置分为两部分:
- canal.properties (系统根配置文件)
- instance.properties (instance级别的配置文件,每个instance一份)
- instance列表定义 (列出当前server上有多少个instance,每个instance的加载方式是spring/manager等)
- common参数定义,比如可以将instance.properties的公用参数,抽取放置到这里,这样每个instance启动的时候就可以共享. 【instance.properties配置定义优先级高于canal.properties】
instance.properties介绍:
a. 在canal.properties定义了canal.destinations后,需要在canal.conf.dir对应的目录下建立同名的文件
比如:
canal.destinations = example1,example2
这时需要创建example1和example2两个目录,每个目录里各自有一份instance.properties.
ps. canal自带了一份instance.properties demo,可直接复制conf/example目录进行配置修改
b. 如果canal.properties未定义instance列表,但开启了canal.auto.scan时
server第一次启动时,会自动扫描conf目录下,将文件名做为instance name,启动对应的instance
server运行过程中,会根据canal.auto.scan.interval定义的频率,进行扫描
- 发现目录有新增,启动新的instance
- 发现目录有删除,关闭老的instance
- 发现对应目录的instance.properties有变化,重启instance
-
几点说明:
- mysql链接时的起始位置
- canal.instance.master.journal.name + canal.instance.master.position : 精确指定一个binlog位点,进行启动
- canal.instance.master.timestamp : 指定一个时间戳,canal会自动遍历mysql binlog,找到对应时间戳的binlog位点后,进行启动
不指定任何信息:默认从当前数据库的位点,进行启动。(show master status)
- mysql解析关注表定义
标准的Perl正则,注意转义时需要双斜杠:\ - mysql链接的编码
目前canal版本仅支持一个数据库只有一种编码,如果一个库存在多个编码,需要通过filter.regex配置,将其拆分为多个canal instance,为每个instance指定不同的编码
instance.xml配置文件
目前默认支持的instance.xml有以下几种:
spring/memory-instance.xml
spring/default-instance.xml
spring/group-instance.xml
- 在介绍instance配置之前,先了解一下canal如何维护一份增量订阅&消费的关系信息:
解析位点 (parse模块会记录,上一次解析binlog到了什么位置,对应组件为:CanalLogPositionManager)
消费位点 (canal server在接收了客户端的ack后,就会记录客户端提交的最后位点,对应的组件为:CanalMetaManager)
对应的两个位点组件,目前都有几种实现:
memory (memory-instance.xml中使用)
zookeeper
mixed
period (default-instance.xml中使用,集合了zookeeper+memory模式,先写内存,定时刷新数据到zookeeper上)
- memory-instance.xml介绍:
所有的组件(parser , sink , store)都选择了内存版模式,记录位点的都选择了memory模式,重启后又会回到初始位点进行解析
特点:速度最快,依赖最少(不需要zookeeper)
场景:一般应用在quickstart,或者是出现问题后,进行数据分析的场景,不应该将其应用于生产环境
- default-instance.xml介绍:
store选择了内存模式,其余的parser/sink依赖的位点管理选择了持久化模式,目前持久化的方式主要是写入zookeeper,保证数据集群共享.
特点:支持HA
场景:生产环境,集群化部署.
- group-instance.xml介绍:
主要针对需要进行多库合并时,可以将多个物理instance合并为一个逻辑instance,提供客户端访问。
场景:分库业务。 比如产品数据拆分了4个库,每个库会有一个instance,如果不用group,业务上要消费数据时,需要启动4个客户端,分别链接4个instance实例。使用group后,可以在canal server上合并为一个逻辑instance,只需要启动1个客户端,链接这个逻辑instance即可.
- instance.xml设计初衷:
允许进行自定义扩展,比如实现了基于数据库的位点管理后,可以自定义一份自己的instance.xml,整个canal设计中最大的灵活性在于此
HA模式配置
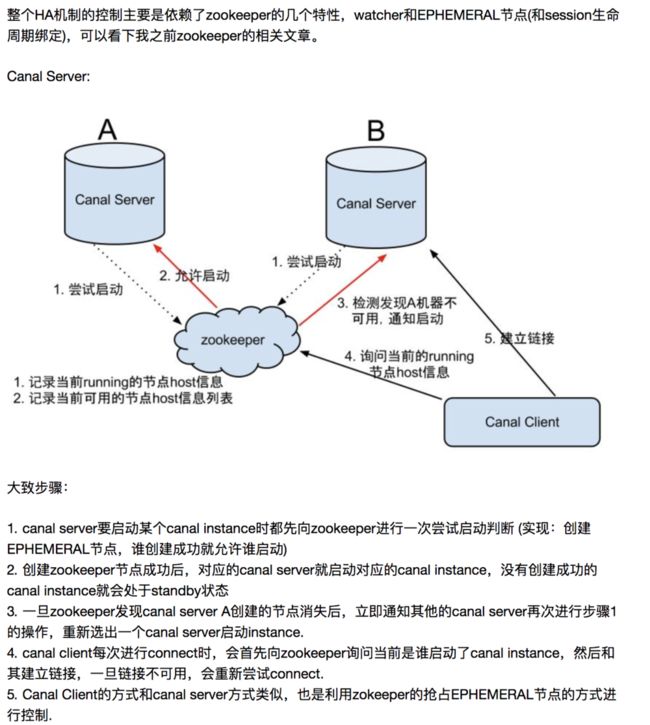
1.canal HA工作原理
2.配置
-
- 机器准备
a. 运行canal的机器: 10.20.144.22 , 10.20.144.51.
b. zookeeper地址为:10.20.144.51:2181
c. mysql地址:10.20.144.15:3306
- 机器准备
-
- 按照部署和配置,在单台机器上各自完成配置,演示时instance name为example
a. 修改canal.properties,加上zookeeper配置
- 按照部署和配置,在单台机器上各自完成配置,演示时instance name为example
canal.zkServers=10.20.144.51:2181
canal.instance.global.spring.xml = classpath:spring/default-instance.xml
b. 创建example目录,并修改instance.properties
canal.instance.mysql.slaveId = 1234 ##另外一台机器改成1235,保证slaveId不重复即可
canal.instance.master.address = 10.20.144.15:3306
注意: 两台机器上的instance目录的名字需要保证完全一致,HA模式是依赖于instance name进行管理,同时必须都选择default-instance.xml配置
-
- 启动两台机器的canal
ssh 10.20.144.51
sh bin/startup.sh
ssh 10.20.144.22
sh bin/startup.sh
启动后,你可以查看logs/example/example.log,只会看到一台机器上出现了启动成功的日志。
结合MQ使用
canal 作为 MySQL binlog 增量获取和解析工具,可将变更记录投递到 MQ 系统中,比如 Kafka/RocketMQ,可以借助于 MQ 的多语言能力。
目前canal默认支持的MQ有kafka和RocketMQ
下面在我的本子上演示kafka quick start.
环境版本
- 操作系统:macOS
- java版本: jdk1.8
- canal 版本: 请下载最新的安装包,本文以当前v1.1.3 的canal.deployer-1.1.3.tar.gz为例
- MySQL版本 :5.7
注意 : 关闭所有机器的防火墙,同时注意启动可以相互telnet ip 端口
1. 安装zookeeper
zookeeper
2. 安装MQ
kafka
3. 修改canal配置
vi /conf/canal.properties
# ...
# 可选项: tcp(默认), kafka, RocketMQ
canal.serverMode = kafka
# ...
# kafka/rocketmq 集群配置: 192.168.1.117:9092,192.168.1.118:9092,192.168.1.119:9092
canal.mq.servers = 127.0.0.1:9092
canal.mq.retries = 0
# flagMessage模式下可以调大该值, 但不要超过MQ消息体大小上限
canal.mq.batchSize = 16384
canal.mq.maxRequestSize = 1048576
# flatMessage模式下请将该值改大, 建议50-200
canal.mq.lingerMs = 1
canal.mq.bufferMemory = 33554432
# Canal的batch size, 默认50K, 由于kafka最大消息体限制请勿超过1M(900K以下)
canal.mq.canalBatchSize = 50
# Canal get数据的超时时间, 单位: 毫秒, 空为不限超时
canal.mq.canalGetTimeout = 100
# 是否为flat json格式对象
canal.mq.flatMessage = true
canal.mq.compressionType = none
canal.mq.acks = all
# kafka消息投递是否使用事务
canal.mq.transaction = false