阅读对象
只要你想读,你就读呗!最好点个赞再走。。。:-)
本文尽量通过例子和直观描述,来说明人工智能中机器学习和数据挖据的主要概念,分类,和使用方法,并通过例子描述如何使用它来促进公司业务发展。虽然标题偏技术,但内容涵盖面较广,涉及业务,产品,技术等多方面。主要目的是说清楚公司如何使用数据挖据为业务提速,所以推荐的阅读对象,是公司中高级运营管理人员,创始人。但并不一定合适人工智能,数据挖据的技术专家,因为它基本不涉及人工智能和数据挖据的底层技术,也不涉及深层次的数学原理和算法研究。
前言
近年来,人工智能,大数据是一个非常热门的词汇。与一些更加前沿的科技例如量子计算,神经网络,虚拟现实,区块链等等不同,这一类技术里面,已经有一些分类,实实在在地被商用并且产生了可观的效益。简单地说,本文所描述的数据挖据相关内容,事实上就是人工智能和大数据的一种结合。
哪儿有数据挖掘哪儿就有“啤酒与尿布”, “沃尔玛啤酒和尿布的故事”这个经典的案例是从事这行研究的人都知道的一个故事,说的是沃尔玛超市(Walmart)会在周末时把啤酒移到尿布货架的未端,这是因为沃尔玛的数据挖掘专家告诉老板,他们的研究结果显示男士通常会在周末购买尿布,而他们同时也喜欢在周末喝啤酒,如果放在一起那肯定会提升销售,老板照做了,结果啤酒销售果然增加了40%以上。。。很想知道这个经典案例是真实的还是为了宣传数据挖掘而制造的,也不知道这个案例是沃尔玛自己说的还是别人说的,沃尔玛有明确的官方声明么。。。?
反正听着很提神。
现在世界上几乎所有的大型公司都在使用数据挖掘,并且目前尚未使用数据挖掘的公司已经或在不久的将来,就会发现自己处于极大的劣势。成为Low逼是肯定的,直接失去业务机会和竞争力,也是肯定的。
那么,如何能让我们的公司跟上数据挖掘的大潮呢?
本文汇总了四个最有用和常用的数据挖据方法,同时使用了一个叫WEKA(Waikato Environment for Knowledge Analysis)的人工智能+数据挖据研究工具(这个工具是JAVA语言开发的),来做一些实实在在的开发和演示,来研究并确定一下这个沃尔玛神话的可信性和可行性有多高。
让我们现在就开始。
概念和准备工作
什么是数据挖掘?
数据挖掘,就其核心而言,是指将大量数据转变为有实际意义的模型和规则。并且,它还可以分为两种类型:直接的和间接的。
在 直接的 数据挖掘中,我们会尝试预测一个特定的数据点 — 比如,以给定的一个房子的售价来预测邻近地区内的其他房子的售价,或者,用以往的车辆销售成交数据,来预测一辆车的成交价格或者由此制定最合理的定价。
在 间接的 数据挖掘中,公司会尝试收集和创建数据群组或找到现有数据内的模式 — 比如,创建 “中产阶级白领女性人群”,或者收集一批“最近5年买过某某车的用户”,然后去分析和预测他们的行为。
现代的数据挖掘开始于 20 世纪 90 年代,那时候计算的强大以及计算和存储的成本均到达了一种很高的程度,各公司开始可以自己进行计算和存储,而无需再借助外界的计算帮助。
此外,术语数据挖掘是全方位的,可指代诸多查看和转换数据的技术和过程。本文只触及能用数据挖掘实现的常用功能和概念。当然,数据挖掘的专家往往是数据统计方面的博士,并在此领域有 N 年(10年以上)的研究经验。
这会给大家留下一种印象,即只有大公司才能负担得起数据挖掘。
多年来,我脑海中经常浮现《功夫熊猫》中乌龟大师的一句名言: Your mind is like this water, my friend , when it is agitated ,it becomes difficult to see ,but if you allow it to settle , the answer becomes clear. (你的思想就如同水,我的朋友,当水波摇曳时,很难看清,不过当它平静下来,答案就清澈见底了。)
思想如此,很多时候,科技也是如此。所以,事实上数据挖据在使用上并非如此难,当然它不像打印一张电子数据统计表那么简单,但也不像有些人想的那样难,难到靠自己或者自己公司团队根本无法实现。
其实很多时候,在一个从事业务型的公司,我们只需要所谓的技术专家的 10% 的专业知识就能创建具有 90% 效力的产品和服务。而无须去补上剩下的 10% 的服务。因为那10%基本是没有用户关心的,而为了弥补那10%去创建一个完美的技术模型将需要 90% 甚至更多的额外的时间和资源投入,或者长达 10年,20 年,这,还是留给一些专门从事某方面研究的科技研究公司或者高校去完成吧。
“我们不生产水,我们只是水的搬运工”
数据挖掘的最终目标,是要创建一个模型,这个模型可改进解读现有数据并正确预测将来的数据。在阅读了本文章后 ,您应该能够自己根据自己的数据集正确决定要使用的技术,然后采取必要的步骤对它进行优化。您将能够为您自己的数据创建一个足够好的模型。
在本文中,我们将研究四种数据挖据技术和如何在自己的JAVA系统中,导入weka.jar做数据挖掘开发:
**1、 “回归模型”及其WEKA实现
2、 “分类模型”及其WEKA实现
3、 “群集/聚类模型”及其WEKA实现
4、 “最近邻模型”及其WEKA实现
5、 将weka.jar 使用到自己的程序
我们将分别举例子来说明这四种技术对业务的帮助。
什么是WEKA及WEKA的安装
有一种软件可以实现那些价格不菲的数据挖据商业软件所能实现的全部功能 — 这个软件就是 WEKA(请上百度搜索相关说明)。WEKA 诞生于 University of Waikato(新西兰)并在 1997 年首次以其现代的格式实现。它使用了 GNU General Public License (GPL)。该软件以 Java™ 语言编写并包含了一个图形界面来与数据文件交互并生成可视结果(比如表和曲线)。
WEKA除了作为一个独立PC应用外,它居然还有一个通用 API weka.jar,所以我们可以像嵌入其他的库一样将 WEKA 嵌入到自己的应用程序以完成诸如服务器端自动数据挖掘这样的任务。。。哇哇哇,这应该就是程序员最想要的,世界上总有那么一批好人提供免费的馅饼!!!
接下来我们来安装 WEKA。因为它基于 Java,所以如果您在计算机上没有安装Java环境,那么请下载一个包含 JRE 的 WEKA 版本,如果有了,就下载不包含JRE的包,它会小的多,不过要注意JDK版本的兼容。
看一看,下面是我下载的安装包(需要安装包的自行搜索下载,别问我要哦):
我下载的时间是2018年2月份,到那时为止WEKA最新版本 weka-3-8-2。
本来机器上有JKD1.7,但是安装WEKA后报错,版本不对,需要JDK1.8,于是下载了1.8。
双击安装,然后启动,看到如下KEKA开始屏幕界面。
在启动 WEKA 时,会弹出图形界面选择器,让您选择使用 WEKA 和数据的四种方式。对于本文章系列中的例子,我们只选择了 Explorer 选项。对于我们要在这些系列文章中所需实现的功能,这已经足够。点 Explorer ,将看到如下界面:
在安装和启动 WEKA 后,我们就可以来研究我们的人工智能 之 机器学习 之 数据挖据了。
我们来看看我们的第一个数据挖掘:回归模型。
模型一。回归模型
回归模型的使用场景,一般是用来确定有某一些因素确定的某一个商品的价值,比如房价的估计。
回归是比较简单易用的一个概念。此模型数学上是一种输入和输出之间的线性关系,可以简单到只有一个输入变量和一个输出变量。当然,也可以远比此复杂,可以包括很多输入变量。实际上,所有回归模型均符合同一个通用模式。多个“自变量”综合在一起可以生成一个结果 — 一个“因变量”。在分析大量历史数据后生成一个回归模型,然后用这个回归模型根据给定的这些自变量的值预测一个未知的因变量的结果。
其实我们每个人都可能使用过或看到过回归模型,甚至曾在头脑里创建过一个回归模型。只是我们自己不这么认为而已。
在如今的社会,人们能立即想到的一个例子大概是给房子定价了。房子的价格(因变量)是很多自变量 — 房子的面积、占地的大小、位置、装修状况等等组合的结果。所以,不管是购买过一个房子还是销售过一个房子,我们大脑中都会创建一个回归模型来为房子定价。这个模型建立在邻近地区内的其他有可比性的房子的售价的基础上(模型),然后再把新的房子的值放入此模型来产生一个预期价格。
一个长期从事某个地区×××中介工作的人,会自然而然在大脑中形成一个正确的模型,告知他/她相关的参数,也就是告诉他/她你房子的基本情况,他/她就可以立即告诉你合理的估价。联系到人工智能方面,这其实是一个典型机器学习(监督学习)的过程加上数据挖据的过程。
让我们继续以这个房屋定价的回归模型为例,创建一些真实的数据。假定最近我有一个房子想要出售,我试图找到我自己房子的合理价格。我不是一个长期从事房屋交易的中介,同时因为一些合理的原因,也并不是很相信中介给我提供的价格,那将如何是好?在这里,事情将变得比较很容易,你将很容易解决这个问题。
首先,你需要通过一些途径,询问一下你周边邻居或者同一个地段的房子,包括他们的价格和一些影响价格的主要因素,因为是同一个地段,所以影响价格的因素就相对简单了很多。
这里先罗列汇总一下影响房价的几个主要因素:
1、小区位置,小区所在的地理位置
2、楼座位置,某栋楼所在的位置
3、交通情况,交通是否便利
4、小区基础设施,物业和小区基础设施是否好
5、周边设施,周边生活学习是否方便
6、环境绿化,绿化程度
7、房龄,房屋年龄
8、面积,房子多大
9、房屋朝向,是否朝南
10、房座位置,位于一栋楼两边还是中间,位于两边的认为采光较好
11、装修情况,装修的情况
因为在本例中,我是想通过和邻近房子比较,来预估自己的房子价格,所以在上面11个因素中,其实只需要关心2、8、9、10、11三个就可以了,因为其它方面都可以认为是一样的。
然后我们将因素和值表示一下:
面积:具体面积数字,平方米
楼座位置:分为靠马路1和不靠马路2
朝向:朝南1,不朝南2
房座位置:两边1,中间2
装修:1豪华,2精装,3普通,4毛坯
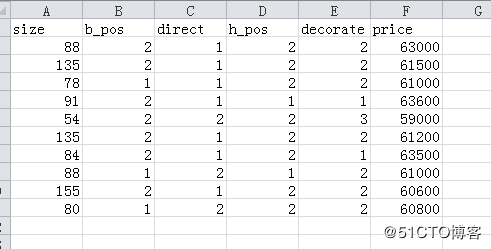
接下来,必须花一些时间,了解了一下周边房屋售价情况,假定获得的数据如下。
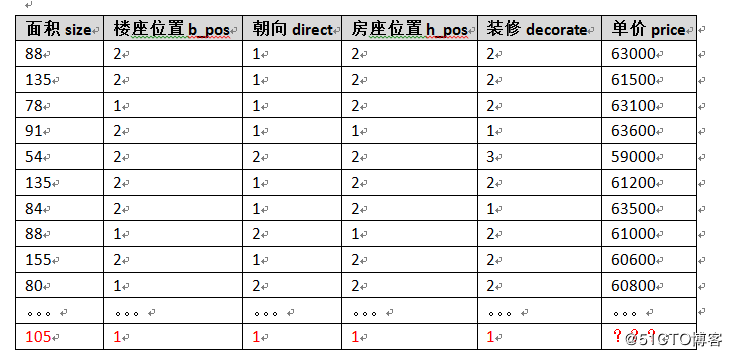
最后那个,红色的,假定就是我的房子,我想知道单价应该是多少呢?
为 WEKA 构建数据集
为了将数据加载到 WEKA,我们必须将数据放入一个我们能够理解的格式。WEKA 建议的加载数据的格式是 Attribute-Relation File Format (ARFF),您可以在其中定义所加载数据的类型,然后再提供数据本身。在这个文件内,我们定义了每列以及每列所含内容。对于回归模型,只能有 NUMERIC 或 DATE 列。最后,以逗号分割的格式提供每行数据。我们为 WEKA 使用的 ARFF 文件如下所示。请注意在数据行内,并未包含我的房子。因为我们在创建模型,我房子的价格还不知道,所以我当然不能输入我的房子。
WEKA 文件格式
@RELATION house
@ATTRIBUTE size NUMERIC
@ATTRIBUTE b_pos NUMERIC
@ATTRIBUTE direct NUMERIC
@ATTRIBUTE h_pos NUMERIC
@ATTRIBUTE decorate NUMERIC
@ATTRIBUTE price NUMERIC
@DATA
88,2,1,2,2,63000
135,2,1,2,2,61500
78,1,1,2,2,63100
91,2,1,1,1,63600
54,2,2,2,3,59000
135,2,1,2,2,61200
84,2,1,2,1,63500
88,1,2,1,2,61000
155,2,1,2,2,60600
80,1,2,2,2,60800
如何将你的统计转换成WEKA认识的arff格式。
你的统计文件最有可能的是txt,excel格式文件。
如果是如下格式的txt:

首先导入excel,变成如下格式:
注意第一行,是你添加的属性行,然后保存为csv 格式。
接下来就容易了,用WEKA explorer ,打开 csv文件,然后保存为 arff格式即可。我这里保存为house.arff

将数据载入 WEKA
数据创建完成后,就可以开始创建我们的回归模型了。启动 WEKA,然后选择 Explorer。将会出现 Explorer 屏幕,其中 Preprocess 选项卡被选中。选择 Open File 按钮并选择在上一节中创建的 house.arff 文件。在选择了文件后,WEKA Explorer 应该类似于下图所示的这个屏幕快照。

在这个视图中,WEKA 允许您查阅正在处理的数据。在 Explorer 窗口的左边,给出了您数据的所有列(Attributes)以及所提供的数据行的数量(Instances)。若选择一列,Explorer 窗口的右侧就会显示数据集内该列数据的信息。比如,通过选择左侧的 size 列(它应该默认选中),屏幕右侧就会变成显示有关该列的统计信息。它显示了数据集内此列的最大值为 155 平方米,最小值为 54 平方米。平均大小为 98.8 平方米,标准偏差为 31.773平方米(标准偏差是一个描述差异的统计量度)。此外,还有一种可视的手段来查看数据,单击 Visualize All 按钮即可。由于在这个数据集内的行数有限,因此可视化的功能显得没有更多数据点(比如,有数百个)时那么功能强大。
好了,对数据的介绍已经够多了。让我们立即创建一个模型来获得我房子的价格。
用 WEKA 创建一个回归模型
为了创建这个模型,单击 Classify 选项卡。第一个步骤是选择我们想要创建的这个模型,以便 WEKA 知道该如何处理数据以及如何创建一个适当的模型:
单击 Choose 按钮,然后扩展 functions 分支。
选择 LinearRegression 。
这会告诉 WEKA 我们想要构建一个回归模型。除此之外,还有很多其他的选择,这说明可以创建的的模型有很多。我们之所以选择LinearRegression而不是SimpleLinearRegression,是因为目前我们这个模型有五个变量,需要输出一个因变量。回归分析中,只包括一个自变量和一个因变量,且二者的关系可用一条直线近似表示,这种回归分析称为一元线性回归分析。如果回归分析中包括两个或两个以上的自变量,且因变量和自变量之间是线性关系,则称为多元线性分析。很明显我们这个是多元的。
选择了正确的模型后,WEKA Explorer 应该类似于下图。

现在,选择了想要的模型后,我们必须告诉 WEKA 它创建这个模型应该使用的数据在哪里。虽然很显然我们想要使用在 ARFF 文件内提供的那些数据,但实际上有不同的选项可供选择,有些甚至远比我们将要使用的选项高级。其他的三个选择是:Supplied test set 允许提供一个不同的数据集来构建模型; Cross-validation 让 WEKA 基于所提供的数据的子集构建一个模型,然后求出它们的平均值来创建最终的模型;Percentage split WEKA 取所提供数据的百分之一来构建一个最终的模型。这些不同的选择对于不同的模型非常有用,我们在本系列后续文章中会看到这一点。对于回归,我们可以简单地选择 Use training set。这会告诉 WEKA 为了构建我们想要的模型,可以使用我们在 ARFF 文件中提供的那些数据。
创建模型的最后一个步骤是选择因变量(即我们想要预测的列)。在本例中指的就是房屋的销售单价,因为那正是我们想要的。在这些测试选项的正下方,有一个组合框,可用它来选择这个因变量。列 price 应该默认选中。
我们准备好创建模型后,单击 Start。下图显示了输出结果。

放大,直接看模型公式:

让我们来算算我那个房子的单价:
price =
-21.7669 105 +
-818.8863
1 +
-2457.072 1 +
-1346.4475
1 +
71025.121 = 64094 元
数据挖掘绝不是仅仅是为了输出一个数值:它关乎的是识别模式和规则。它不是严格用来生成一个绝对的数值,而是要创建一个模型来让您探测模式、预测输出并根据这些数据得出结论。让我们更进一步来解读一下我们的模型除了房屋价格之外告诉我们的模式和结论:
• 房坐位置无关紧要 — WEKA 将只使用在统计上对模型的正确性有贡献的那些列。它将会抛弃并忽视对创建好的模型没有任何帮助的那些列。所以这个回归模型告诉我们,房子处于一栋楼的两边还是中间,似乎并不会影响房子的价格。就我个人的经验是,两边的房子比较明亮通透,但也面临着墙壁更容易漏水的危险。
• 装修的影响是非常大的 — 看看装修数字对房价的影响就知道了,随着数字增大,也就是装修质量变差,房价是哗哗往下降啊。为什么我的房子那么贵,豪装啊!有道理!!
• 较大的房子单价反而低 — WEKA 告诉我们房子越大,销售单价越低?这可以从 size 变量前面负的系数看出来。此模型告诉我们房子每多出一平方米都会使房单价减少 21元,虽然影响的并不明显,但的确如此。这个怎么说呢,正确的应该说是在一定范围之外,比如超过某个面积后,的确是单价会随着房屋面积变大而变小,按照经验这个情况是存在的,因为总价高么。
回归模型结束语
本章探讨了第一个数据挖掘模型:回归模型(特指线性回归多变量模型),另外还展示了如何在 WEKA 中使用它。这个回归模型很容易使用,并且可以用于很多数据集。您会发现这个模型是我们日常工作生活中最有用的一个。
然而,数据挖掘不仅局限于简单的回归,在不同的数据集及不同的输出要求的情况下,您会发现其他的模型也许是更好的解决方案。接下来我们看看其它模型。
模型二。分类模型
分类模型的使用场景,是根据已有的属性和分类结果的历史记录,生成一个模型,这个模型能对新的已知属性但不知道分类的用户,物品或商品推算出其分类结果。所以我们这里的分类模型生成,是属于监督学习。
说到分类,就会说到决策树。决策树是一种十分常用的和直观的方法分类方法。它是一种监督学习,所谓监督学习就是给定一堆样本,每个样本都有一组属性和一个类别,这些类别是事先确定的,那么通过学习得到一个分类器,这个分类器能够对新出现的对象给出正确的分类。
决策树的思维,其实在我们日常工作和思考中,都会存在。。。比如一个有经验的推销人员,看到一个用户,通过一眼观察和简单聊天,就能推算出这个用户有没有可能转换成自己的客户。在比如,当有人给适婚男女介绍一个朋友的时候,他们的脑子里面都会有类似如下的决策树来考虑要不要见见:

当简单的现象上升到高科技层面的时候,决策树就会有很多种算法:CHAID,CART,C4.5,C5.0。不过决策树的核心理论都其实差不多,本文不去研究每个算法的实现而是通过例子,去使用和比较这些算法。
首先举个最简的的决策树例子:
假定有如下11个人的完整资料如下,现在需要判断第12个人,是东方人还是西方人?
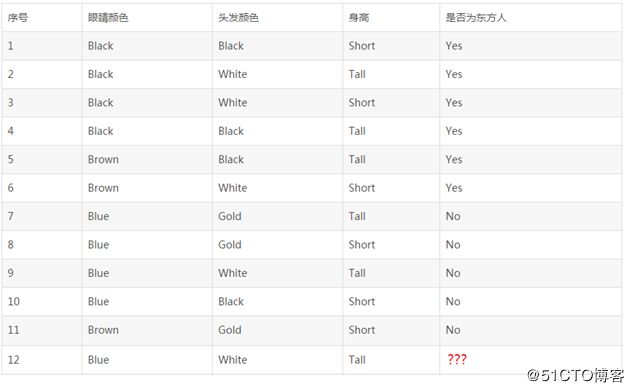
首先,我们根据前面11个人的资料,生成一个决策树,如下:
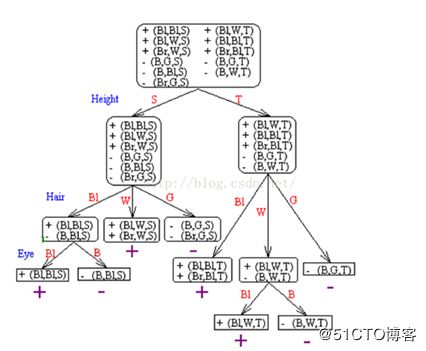
或者入下:
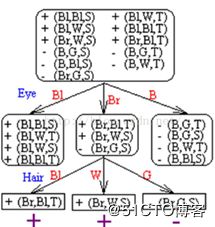
然后把第12个人的资料,按照他的属性代入这两个棵决策树中间的任何一棵,结果就会发现,这个人是西方人。
再次说明,我们不讨论这棵树的实现方法,现实中的决策也不会那么简单,用于生成决策树的历史记录也不会那么少。如何根据已经有的资料,生成最合理的决策树,是算法需要考虑的问题,WEKA就是专门做这个事情的,等会我们再举例说明。
我们这里需要了解的是,各种分类算法,哪种分类算法生成的决策树,最符合我们的需要,还有就是,生成的决策树模型,其分类正确率是多少,是否符合公司的业务需要和场景。
下面我们用工具WEKA,尝试建立一个较为复杂的决策树模型。
打开WEKA,载入其安装目录下面 data目录下的 iris.arff
这是一个经典的鸢尾花分类决策树例子。
鸢尾花有三种类型:setosa,versicolor,virginica这三种类型基本上靠其花瓣和花萼的四种外形来决定。下面是 arff 文件的例子截图:
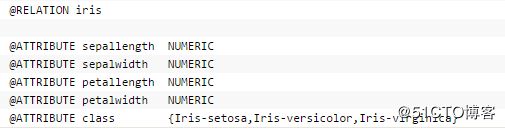

载入 iris.arff
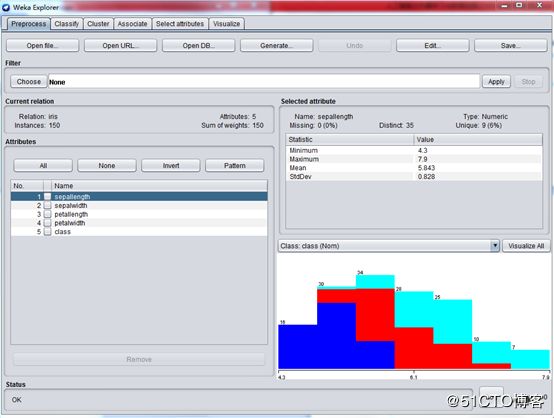
选择Classify ,选择tree - J48分类算法
在 Test options 下面,选择 Cross-validation ,Folds填写10,这个表示生成模型后交叉验证模型。WEKA会将数据分成10份,一份用于生成决策树模型,一份用来验证正确度。
在生成决策树模型中,一般会需要选择Cross-validation ,通过对未知数据的预测结果验证,来验证模型的通用性。
一切设定好后,按“Start”。。。界面如下:
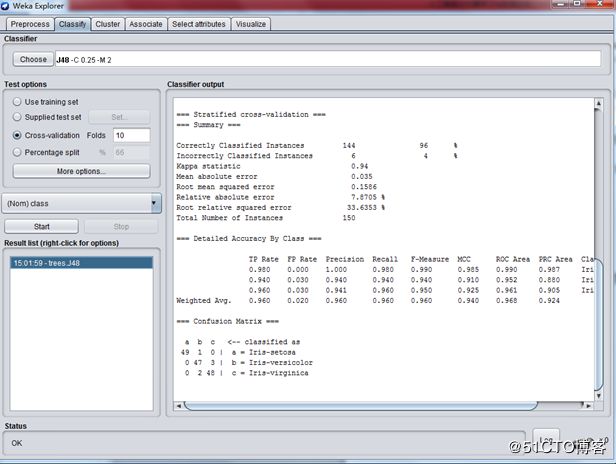
最需要了解的是这一条信息:
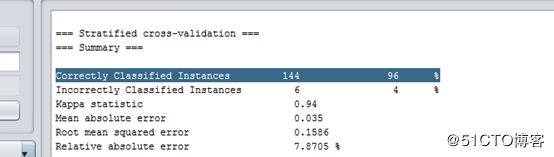
这表示这个模型分类正确率是 96% ,应该是比较高的了。
我们再来直观地看看WEKA生成的树吧:
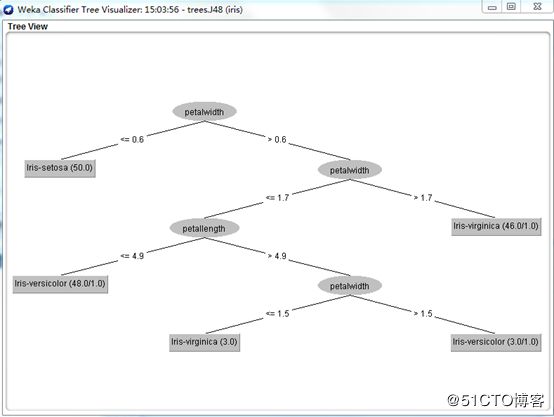
分类模型结束语
决策树或者分类树就是要创建一个具有分支、节点和枝叶的树,能够让我们拿一个未知的数据点,将此数据点的属性应用到这个树并顺着这个树下移,直到到达一个叶子并且数据点的未知输出可以断定。为了创建一个好的分类树模型,我们必须要有一个输出已知的现有数据集,从这个数据集才能构建我们的模型。我们还看到了我们需要将我们的数据集分成两个部分:一个用来创建模型的训练集 ;一个用来验证模型是否正确且没有过拟合的测试集。因为在某些时候,即便是创建了一个自己认为正确的数据模型,它也可能不正确,所以需要验证。
在有些时候,我们也有可能必须要摒弃原来的整个模型和算法以寻找更好的模型和算法解决方案。因为有时候同一个业务目标,其实可以有不同的数据挖掘方法,这个我们会在第三章 - 最近邻算法里面提到并作一些比较。
模型三。群集模型(聚类模型)
对于一般的用户,群集有可能是最为有用的一种数据挖掘方法。它可以迅速地将整个数据集分成组,让我们快速发现并且提取某个组的共同特征,快速得出结论和做相应的改善。个人觉得,群集模型对于商业拓展和业务、产品指导方面,肯定是最有效的数据挖掘模型之一。
就人工智能而言,群集模型属于非监督算法,也就是我们采集或者获得一组数据后,虽然对这个数据有一定了解,但也许并不知道它应该怎么分类,也不知道这些数据有哪些特征,这也是使用群集模型的一个难点。
所以,使用群集的一个主要劣势是用户需要提前知道他想要创建的组的数量。若用户对其数据知之甚少,这可能会很困难。是应该创建三个组?五个组?还是十个组?所以在决定要创建的理想组数之前,可能需要进行几个步骤的尝试和出错。这要求用户对采集的数据目的比较明确。
就算法而言,简单说来,群集或聚类算法核心,是通过计算各个数据之间的距离,将距离比较近的数据归在一起。当然,说起来比较简单,实现起来不是那么简单。有一个比较简单的例子,可以帮助我们了解集群的算法核心:

上图是平面坐标里面的6个点,分成两个组。如果通过我们的眼睛来看,凭经验判断,那是非常简单了,左下角三个点一组,右上角三个点一组,一秒钟的事情。如果要通过群集算法怎么实现呢?下面就是步骤:
1.选择初始大哥:
我们就选P1和P2
2.计算小弟和大哥的距离:
P3到P1的距离从图上也能看出来(勾股定理),是√10 = 3.16;P3到P2的距离√((3-1)^2+(1-2)^2 = √5 = 2.24,所以P3离P2更近,P3就跟P2混。同理,P4、P5、P6也这么算,如下:
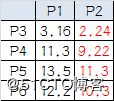
P3到P6都跟P2更近,所以第一次站队的结果是:
• 组A:P1
• 组B:P2、P3、P4、P5、P6
3.人民代表大会:
组A没啥可选的,大哥还是P1自己
组B有五个人,需要选新大哥,这里要注意选大哥的方法是每个人X坐标的平均值和Y坐标的平均值组成的新的点,为新大哥,也就是说这个大哥是“虚拟的”。
因此,B组选出新大哥的坐标为:P哥((1+3+8+9+10)/5,(2+1+8+10+7)/5)=(6.2,5.6)。
综合两组,新大哥为P1(0,0),P哥(6.2,5.6),而P2-P6重新成为小弟
4.再次计算小弟到大哥的距离:

这时可以看到P2、P3离P1更近,P4、P5、P6离P哥更近,所以第二次站队的结果是:
• 组A:P1、P2、P3
• 组B:P4、P5、P6(虚拟大哥这时候消失)
5.第二届人民代表大会:
按照上一届大会的方法选出两个新的虚拟大哥:P哥1(1.33,1) P哥2(9,8.33),P1-P6都成为小弟
6.第三次计算小弟到大哥的距离:
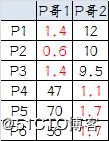
这时可以看到P1、P2、P3离P哥1更近,P4、P5、P6离P哥2更近,所以第二次站队的结果是:
• 组A:P1、P2、P3
• 组B:P4、P5、P6
我们发现,这次站队的结果和上次没有任何变化了,说明已经收敛,聚类结束,聚类结果和我们最开始设想的结果完全一致。
以上就是群集或者聚类算法的基本思想。
WEKA演示
加载数据文件 bank.arff
选择Cluster选项,然后选择 SimpleKMeans算法。
点算法选择框,在弹出框的 numClusters 里面输入6 ,表示生成6个组。
然后按Start,可以看到输出结果如下:


这里我们很快会不可避免地提出两个问题,第一,我们怎么知道将数据集分成几个组呢,第二,分成不同组以后,怎么去分析不同组的特性,并发现规律呢?
我也不是很清楚,比如上面的分组,我对银行业务没有了解,所以实在是的不出什么结论。网上有这么一段话可以参考。
在聚类数据挖掘中,业务专家的作用非常大,主要体现在聚类变量的选择和对于聚类结果的解读:
比如要对于现有的客户分群,那么就要根据最终分群的目的选择不同的变量来分群,这就需要业务专家经验支持。如果要优化客户服务的渠道,那么就应选择与渠道相关的数据;如果要推广一个新产品,那就应该选用用户目前的使用行为的数据来归类用户的兴趣。算法是无法做到这一点的
欠缺经验的分析人员和经验丰富的分析人员对于结果的解读会有很大差异。其实不光是聚类分析,所有的分析都不能仅仅依赖统计学家或者数据工程师。
下面有一个群集的例子,带有分组业务分析。
话说有一家宝马经销店。这个经销店保留了人们如何在经销店以及展厅行走、他们看了哪些车以及他们最终购车的机率的记录。经销店期望通过寻找数据内的模式挖掘这些数据并使用群集来判断其客户是否有某种行为特点。历史记录中有 100 行数据,并且每个列都描述了顾客在他们各自的 BMW 体验中所到达的步骤,比如列中的 1 表示到达这一步的顾客看过这辆车,0 表示他们不曾到达看过车的这一步。下面清单显示了在 WEKA 中所使用的 ARFF 数据。
@attribute Dealership numeric
@attribute Showroom numeric
@attribute ComputerSearch numeric
@attribute M5 numeric
@attribute 3Series numeric
@attribute Z4 numeric
@attribute Financing numeric
@attribute Purchase numeric
@data
1,0,0,0,0,0,0,0
1,1,1,0,0,0,1,0
经过一番操作后,得到下面的输出:
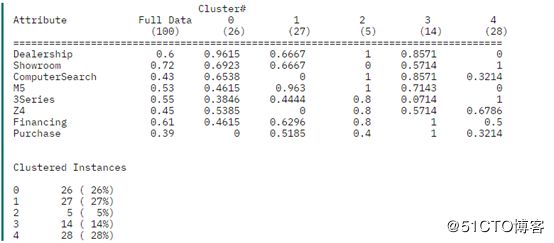
下面是业务分析:
群集 0— 这个组我们可以称之为 “Dreamers”,因他们围着经销店徘徊,查看在停车场上停着的车,却不步入店面内,且更糟的是,他们没有购买过任何东西。
群集 1— 我们将这一组称为是 “M5 Lovers”,因为他们常常会径直走到 M5 车型区,对 3-系列的车型和 Z4 均视而不见。不过,他们也没有多高的购买率 — 只有 52 %。这表明存在潜在问题,也是经销店今后改进的重点,比如可以派更多的销售人员到 M5 区。
群集 2— 这个组很小,我们可以称之为 “Throw-Aways”,因为他们没有统计意义上的相关性,我们也不能从其行为得出任何好的结论。(这种情况若在群集上发生,可能表明应该减少所创建的群集的数量。)
群集 3— 这个组,我们称之为 “BMW Babies”,因为他们总是会购买一辆车而且还会支付车款。正是在这里,数据向我们显示了一些有趣的事情:他们一般会在停车场内查看各种车型,然后返回到经销店内的计算机处搜索中意的车型是否有货。他们最终会购买 M5 或 Z4 车型(但从不购买 3-系列的)。这个群集告诉经销店它应该考虑让它的搜索计算机在停车场处就能很容易地被看到(或安置一台室外的搜索计算机),并且让 M5 或 Z4 在搜索结果中更为醒目。一旦顾客决定购买汽车,他总是符合购车款的支付条件并能够圆满完成这次购买。
群集 4— 这个组我们将称之为 “Starting Out With BMW”,因为他们总是看 3-系列的车型,从不看贵很多的 M5。他们会径直步入展厅,而不会在停车场处东看西看,而且也不会使用计算机搜索终端。他们中有 50 % 会到达支付车款的阶段,但只有 32 % 会最终成交。经销店可以得出这样的结论:这些初次购买 BMW 车的顾客知道自己想要的车型是哪种( 3-系列的入门级车型)而且希望能够符合购车款的支付条件以便买得起。经销店可以通过放松购车款的支付条件或是降低 3- 系列车型的价格来提高这一组的销售。
群集模型结束语
总觉得“分类”和“聚类”,往往可以配合使用。我们做一下发散性思维。
考虑上面提到的宝马经销店,如果是一家不差钱的大型店,我们考虑设置这么一套系统。
在店门口和店内,几个重要的点安装上人脸自动之别系统,此系统同时和银行或者政府个人资料库关联,当一个人经过的时候,可以自动识别身份,并且瞬间获知其年龄,收入,婚姻,×××等等信息。采集这些信息,并且记录此人从店门口经过开始到入店(也可能不进店),离开店的全部过程。后面对接一个“群集模型”和“分类模型”数据挖掘系统。
我们不难想象,这个经销商店可以在经销方面做到多么细致。马路上走过来一个人,立马可以计算出他/她对什么最有可能购买,并且知道他/她当前的经济情况,合适推荐什么相关服务和金融方案。对店内的设备和布置来说,可以根据集群得出的结论,正确设计展台,选择展品车型,布局各种展品的位置,增加一些有趣味的高科技设计,采取多种方法提高进店率等等。
永远不要忘记,我们使用“数据挖掘”的目的是为了服务于业务这一个基本点。
模型四。最近邻模型
最近邻思想的提出和应用场景非常典型,假定一个客户登录了某购物网站,我们怎么给他/她推荐商品呢?或者说我们怎么知道他/她最有可能买什么商品呢?
假定现在手里有下面这些顾客购买的历史数据:
Customer Age Income Purchased Product
1 45 46k Book
2 39 100k TV
3 35 38k DVD
4 69 150k Car Cover
现在提出一个问题,下面第5个客户,最有可能购买什么商品?
5 58 51k ???
结局这个问题,就要用到“最近邻”的思想,我们需要考虑这第五个客户,和哪个客户最相似,和哪个客户最相似,我们认为他就会购买一样的商品。
步骤1: Determine Distance Formula/确定一个距离计算公式
Distance = SQRT( ((58 - Age)/(69-35))^2) + ((51000 - Income)/(150000-38000))^2 )
步骤2: Calculate the Score/计算每个客户和新客户的距离分数
Customer Score Purchased Product
1 .385 Book
2 .710 TV
3 .686 DVD
4 .941 Car Cover
5 0.0 ???
现在我们就可以回答“第 5 个顾客最有可能购买什么产品”这一问题,答案第5个客户将最有可能买的是一本书。这是因为第 5 个顾客与第 1 个顾客之间的距离要比第 5 个顾客与其他任何顾客之间的距离都短(实际上是短很多)。基于这个模型,可以得出这样的结论:由最像第 5 个顾客的顾客可以预测出第 5 个顾客的行为。
不过,最近邻的好处远不止于此。最近邻算法可被扩展成不仅仅限于一个最近匹配,而是可以包括任意数量的最近匹配。可将这些最近匹配称为是 “N-最近邻”(比如 3-最近邻)。回到上述的例子,如果我们想要知道第 5 个顾客最有可能购买的两个产品,那么这次的结论以此是书和 DVD。而对于我们曾经提到的亚马逊的例子,如果想要知道某个顾客最有可能购买的 12 个产品,就可以运行一个 12-最近邻算法(但亚马逊实际运行的算法要远比一个简单的 12-最近邻算法复杂)。
下面我们用分类模型同样的数据集合,来验证一下其在“最近邻”模型下面的正确率。
载入鸢尾花 iris.arff ,然后选择算法 lazy – Ibk,结果如下:
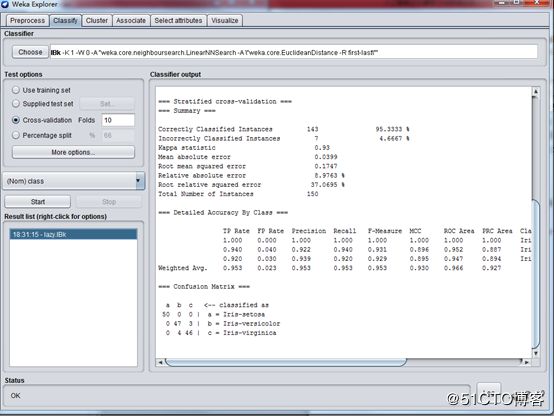
最近邻模型下的正确率为 95.33%,接近与用“J48分类”算法的正确率。
而且我把K调到了6,发现正确率变高了,如下图:

正确率达到了 96.7%。
最近邻模型结束语
我们在例子中用到的k近邻法(k-nearest neighbor, k-NN)是1967年由Cover T和Hart P提出的一种基本分类与回归方法。它的工作原理是:存在一个样本数据集合,也称作为训练样本集,并且样本集中每个数据都存在标签,即我们知道样本集中每一个数据与所属分类的对应关系。输入没有标签的新数据后,将新的数据的每个特征与样本集中数据对应的特征进行比较,然后算法提取样本最相似数据(最近邻)的分类标签。一般来说,我们只选择样本数据集中前k个最相似的数据,这就是k-近邻算法中k的出处,通常k是不大于20的整数。最后,选择k个最相似数据中出现次数最多的分类,作为新数据的分类。
回到刚开始提到的应用场景,假定我们有一个 2000 万用户的购物平台,此算法将非常准确,因为数据库中与某用户有着类似购买习惯的潜在客户很多。最近邻会非常相似。因而,所创建的模型会十分准确和高效。相反,如果能比较的数据点相对很少的话,这个模型很快就会损坏,不再准确。在线电子商务店铺的初期,比如只有 50 个顾客,那么产品推荐特性很可能一点都不准确,因为最近邻实际上与您本身相差甚远。
最近邻技术可能存在的一个挑战是该算法的计算成本有可能会很高。在一个很大的平台的例子中,比如对于有 2000 万客户的平台,每个新客户都必须针对其他的 2000 万客户进行计算以便找到最近邻。首先,如果我们的业务也有 2000 万的客户群,那么这便不成问题,因为您会财源广进。其次,这种类型的计算非常适合用云来完成,因为它们能够被分散到许多计算机上同时完成,并最终完成比较(比如MapReduce)。不过,实际上如果我只是购买了一本书,那么根本不必针对我对比数据库内的2000万个客户。只需将我与其他的购书者进行对比来寻找最佳匹配,这样一来,就将潜在的邻缩小到整个数据库的一部分。
最后部分。如何用weka.jar直接写程序
上面我们用到WEKA做一些例子有演示,但作为开发者来说,WEKA 最酷的一件事情是它不仅是一个独立的应用程序,而且还是一个完备的 Java JAR 文件,可以将其投入到您服务器的 lib 文件夹并从您自己的JAVA应用代码进行调用。
这能为我们的应用程序带来很多实用的、和重要的功能。您可以添加充分利用了我们到目前所学的全部数据挖掘技术的报告。您可以为您的电子商务网站/平台创建一个“产品推荐”小部件,类似于亚马逊站点上的那个。
现在,我们应该看看如何将它集成到您的自己代码中。
实际上,我们已经下载了这个 WEKA API JAR,你可以在安装目录中找到它 weka.jar它就是您启动 WEKA Explorer 时调用的那个 JAR 文件。为了访问此代码,让您的 Java 环境在此类路径中包含这个 JAR 文件。在您自己的代码中使用第三方 JAR 文件的步骤如常。
正如您所想,WEKA API 内的这个中心构建块就是数据。数据挖掘围绕此数据进行,当然所有我们已经学习过的这些算法也都是围绕此数据的。
那么让我们看看如何将我们的数据转换成 WEKA API 可以使用的格式。让我们从简单的开始,先来看看本系列有关房子定价的第一篇文章中的那些数据。
一.加载数据
// 定义数据属性
Attribute a1 = new Attribute("houseSize", 0);
Attribute a2 = new Attribute("lotSize", 1);
Attribute a3 = new Attribute("bedrooms", 2);
Attribute a4 = new Attribute("granite", 3);
Attribute a5 = new Attribute("bathroom", 4);
Attribute a6 = new Attribute("sellingPrice", 5);
// 加载属性
FastVector attrs = new FastVector();
attrs.addElement(a1);
attrs.addElement(a2);
attrs.addElement(a3);
attrs.addElement(a4);
attrs.addElement(a5);
attrs.addElement(a6);
// 加载一条或者多条数据.
Instance i1 = new Instance(6);
i1.setValue(a1, 3529);
i1.setValue(a2, 9191);
i1.setValue(a3, 6);
i1.setValue(a4, 0);
i1.setValue(a5, 0);
i1.setValue(a6, 205000);
....
Instances dataset = new Instances("housePrices", attrs, 7);
dataset.add(i1);
dataset.add(i2);
dataset.add(i3);
dataset.add(i4);
dataset.add(i5);
dataset.add(i6);
dataset.add(i7);
… …
//设定输出变量,
dataset.setClassIndex(dataset.numAttributes() - 1);
假定现在我们已经将数据载入了 WEKA。看起来比较麻烦一点,但这里只是个演示,我们可以看到编写自己的包装器类来快速从数据库或者文件提取数据并将其放入一个 WEKA 实例类还是很简单的。
让我们把我们的数据通过回归模型进行处理并确保输出与我们使用 Weka Explorer 计算得到的输出相匹配。实际上使用 WEKA API 让数据通过回归模型得到处理非常简单,远简单于实际加载数据。
// 选择并初始化模型,实际上我们这里需要的是多维线性回归模型 LinearRegression
LinearRegression linearRegression = new LinearRegression();
// 这个就是根据绑定的数据生成了模型
linearRegression.buildClassifier(dataset);
// 获取模型参数,为了计算我们自己的房价
double[] coef = linearRegression.coefficients();
// 把我们自己的房子属性代入模型公式
double myHouseValue = (coef[0] 3198) +
(coef[1]
9669) +
(coef[2] 5) +
(coef[3]
3) +
(coef[4] * 1) +
coef[6];
//打印出房价,这个房价应该是和通过直接使用WEKA应用程序一致的。
System.out.println(myHouseValue);
// outputs 219328.35717359098
结束语
我们马上能意识到,将以上代码嵌入我们的后台管理系统,就是一个非常专业和智能化的房价定价后台,这个后台加以调整,可以分城市,地区甚至分小区生成更佳的定价模型。另外,如果绑定最近3个月的实时成交数据,这个模型公式还会根据最近的成交价格自动调整参数,其价值远远大于平均值和人工自定义公式。
对于其它三种模型,我们也可以通过学习weka.jar API 的用法,自动绑定到我们的程序,这样就可以形成一个强大的数据挖掘和业务支撑系统。
本文是由五个章节,分别向大家介绍了几个数据挖掘的重要概念,包括回归模型,分类模型和聚类(群集)模型,同时给大家介绍了 WEKA 软件的使用方法,并且通过使用WEKA例子,使得大家对提到的四种数据挖掘有了直观感觉。文章的最后一章,给大家演示了将weka API weka.jar接入我们系统的基本方法。
对大多数人来说,并不需要深入研究人工智能或者数据挖掘的算法,成为这种算法和模型专家,都需要数年甚至十数年的积累,而且你还必须颇具天赋。但作为一般的产品人员,程序开发人员甚至是公司管理决策人员、创业人员,花一点时间,找到合适的工具,去了解人工智能和数据挖掘相关的概念以及如何在日常工作中应用它,其实并不是非常难的事情,而且是非常有价值的事情。
希望阅读这篇文章的每个人,都能成为这方面的专家!