1. 综述
经过R-CNN和Fast RCNN的积淀,Ross B. Girshick在2016年提出了新的Faster RCNN,在结构上,Faster RCNN已经将特征抽取(feature extraction),proposal提取,bounding box regression(rect refine),classification都整合在了一个网络中,使得综合性能有较大提高,在检测速度方面尤为明显。
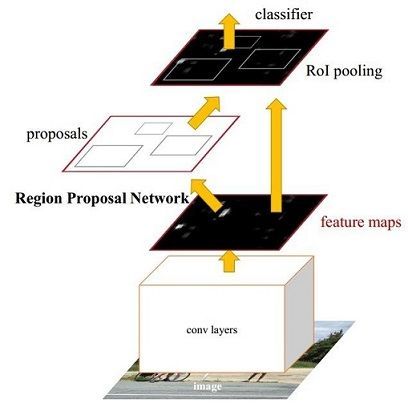
Faster RCNN其实可以分为4个主要内容:
- Conv layers。作为一种CNN网络目标检测方法,Faster RCNN首先使用一组基础的conv+relu+pooling层提取image的feature maps。该feature maps被共享用于后续RPN层和全连接层。
- Region Proposal Networks。RPN网络用于生成region proposals。该层通过softmax判断anchors属于foreground或者background,再利用bounding box regression修正anchors获得精确的proposals。
- RoI Pooling。该层收集输入的feature maps和proposals,综合这些信息后提取proposal feature maps,送入后续全连接层判定目标类别。
-
Classification。利用proposal feature maps计算proposal的类别,同时再次bounding box regression获得检测框最终的精确位置。
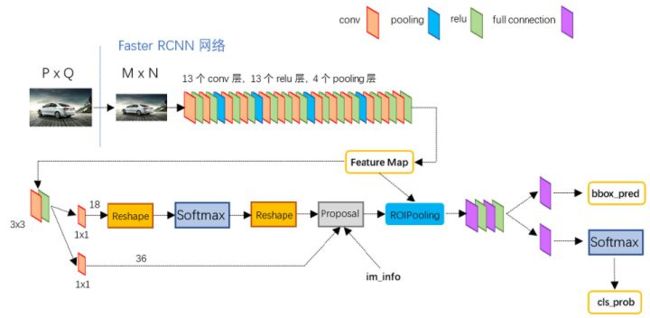
python版本中的VGG16模型中的faster_rcnn_test.pt的网络结构,可以清晰的看到该网络对于一副任意大小PxQ的图像,首先缩放至固定大小MxN,然后将MxN图像送入网络;而Conv layers中包含了13个conv层+13个relu层+4个pooling层;RPN网络首先经过3x3卷积,再分别生成foreground anchors与bounding box regression偏移量,然后计算出proposals;而Roi Pooling层则利用proposals从feature maps中提取proposal feature送入后续全连接和softmax网络作classification(即分类proposal到底是什么object)。
2 Conv layers
Conv layers包含了conv,pooling,relu三种层。以python版本中的VGG16模型中的faster_rcnn_test.pt的网络结构为例,如图2,Conv layers部分共有13个conv层,13个relu层,4个pooling层。这里有一个非常容易被忽略但是又无比重要的信息,在Conv layers中:
- 所有的conv层都是:kernel_size = 3, pad = 1, stride = 1
- 所有的pooling层都是:kernel_size = 2, pad = 0, stride = 2
为何重要?在Faster RCNN Conv layers中对所有的卷积都做了扩边处理( pad=1,即填充一圈0),导致原图变为 (M+2)x(N+2)大小,再做3x3卷积后输出MxN 。正是这种设置,导致Conv layers中的conv层不改变输入和输出矩阵大小。如图3:
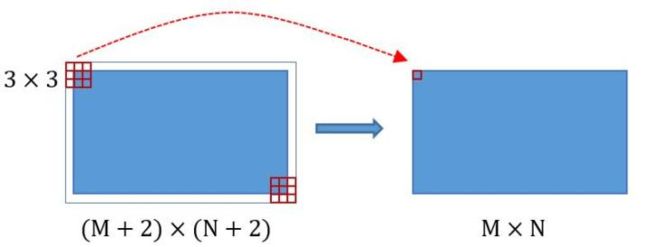
类似的是,Conv layers中的pooling层kernel_size=2,stride=2。这样每个经过pooling层的MxN矩阵,都会变为(M/2)x(N/2)大小。综上所述,在整个Conv layers中,conv和relu层不改变输入输出大小,只有pooling层使输出长宽都变为输入的1/2。
那么,一个MxN大小的矩阵经过Conv layers固定变为(M/16)x(N/16)!这样Conv layers生成的featuure map中都可以和原图对应起来。
3 Region Proposal Networks(RPN)
经典的检测方法生成检测框都非常耗时,如OpenCV adaboost使用滑动窗口+图像金字塔生成检测框;或如R-CNN使用SS(Selective Search)方法生成检测框。而Faster RCNN则抛弃了传统的滑动窗口和SS方法,直接使用RPN生成检测框,这也是Faster R-CNN的巨大优势,能极大提升检测框的生成速度。
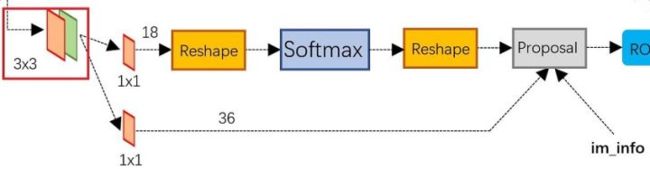
RPN网络的具体结构:可以看到RPN网络实际分为2条线,上面一条通过softmax分类anchors获得foreground和background(检测目标是foreground),下面一条用于计算对于anchors的bounding box regression偏移量,以获得精确的proposal。而最后的Proposal层则负责综合foreground anchors和bounding box regression偏移量获取proposals,同时剔除太小和超出边界的proposals。其实整个网络到了Proposal Layer这里,就完成了相当于目标定位的功能。
3.1 anchors
提到RPN网络,就不能不说anchors。所谓anchors,实际上就是一组由rpn/generate_anchors.py生成的矩形。直接运行作者demo中的generate_anchors.py可以得到以下输出:
[[ -84. -40. 99. 55.]
[-176. -88. 191. 103.]
[-360. -184. 375. 199.]
[ -56. -56. 71. 71.]
[-120. -120. 135. 135.]
[-248. -248. 263. 263.]
[ -36. -80. 51. 95.]
[ -80. -168. 95. 183.]
[-168. -344. 183. 359.]]
其中每行的4个值(x1, y1, x2, y2) 表矩形左上和右下角点坐标。9个矩形共有3种形状,长宽比为大约为with:height∈{1:1, 1:2, 2:1}三种,如图6。实际上通过anchors就引入了检测中常用到的多尺度方法。
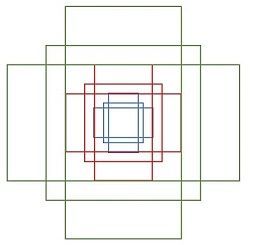
注:关于上面的anchors size,其实是根据检测图像设置的。在python demo中,会把任意大小的输入图像reshape成800x600(即图2中的M=800,N=600)。再回头来看anchors的大小,anchors中长宽1:2中最大为352x704,长宽2:1中最大736x384,基本是cover了800x600的各个尺度和形状。
那么这9个anchors是做什么的呢?借用Faster RCNN论文中的原图,遍历Conv layers计算获得的feature maps,为每一个点都配备这9种anchors作为初始的检测框。这样做获得检测框很不准确,不用担心,后面还有2次bounding box regression可以修正检测框位置。
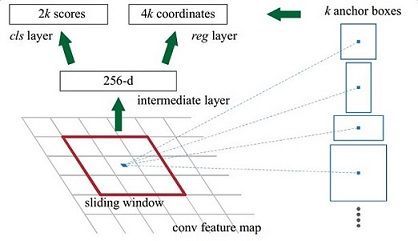
解释一下上面这张图的数字。
在原文中使用的是ZF model中,其Conv Layers中最后的conv5层num_output=256,对应生成256张特征图,所以相当于feature map每个点都是256-dimensions
在conv5之后,做了rpn_conv/3x3卷积且num_output=256,相当于每个点又融合了周围3x3的空间信息,同时256-d不变
假设在conv5 feature map中每个点上有k个anchor(默认k=9),而每个anhcor要分foreground和background,所以每个点由256d feature转化为cls=2k scores;而每个anchor都有[x, y, w, h]对应4个偏移量,所以reg=4k coordinates
补充一点,全部anchors拿去训练太多了,训练程序会在合适的anchors中随机选取128个postive anchors+128个negative anchors进行训练(什么是合适的anchors下文有解释)
3.2 softmax判定foreground与background
一副MxN大小的矩阵送入Faster RCNN网络后,到RPN网络变为(M/16)x(N/16),不妨设 W=M/16,H=N/16。在进入reshape与softmax之前,先做了1x1卷积

该1x1卷积的caffe prototxt定义如下:
layer {
name: "rpn_cls_score"
type: "Convolution"
bottom: "rpn/output"
top: "rpn_cls_score"
convolution_param {
num_output: 18 # 2(bg/fg) * 9(anchors)
kernel_size: 1 pad: 0 stride: 1
}
}
可以看到其num_output=18,也就是经过该卷积的输出图像为WxHx18大小。这也就刚好对应了feature maps每一个点都有9个anchors,同时每个anchors又有可能是foreground和background,所有这些信息都保存WxHx(9*2)大小的矩阵。为何这样做?后面接softmax分类获得foreground anchors,也就相当于初步提取了检测目标候选区域box(一般认为目标在foreground anchors中)。
3.3 bounding box regression
如图所示绿色框为飞机的Ground Truth(GT),红色为提取的foreground anchors,即便红色的框被分类器识别为飞机,但是由于红色的框定位不准,这张图相当于没有正确的检测出飞机。所以我们希望采用一种方法对红色的框进行微调,使得foreground anchors和GT更加接近。

对于窗口一般使用四维向量 (x, y, w, h)表示,分别表示窗口的中心点坐标和宽高。对于图 10,红色的框A代表原始的Foreground Anchors,绿色的框G代表目标的GT,我们的目标是寻找一种关系,使得输入原始的anchor A经过映射得到一个跟真实窗口G更接近的回归窗口G'
对proposals进行bounding box regression:

先来看一看上图11中1x1卷积的caffe prototxt定义:
layer {
name: "rpn_bbox_pred"
type: "Convolution"
bottom: "rpn/output"
top: "rpn_bbox_pred"
convolution_param {
num_output: 36 # 4 * 9(anchors)
kernel_size: 1 pad: 0 stride: 1
}
}
可以看到其 num_output=36,即经过该卷积输出图像为WxHx36,在caffe blob存储为[1, 4x9, H, W],这里相当于feature maps每个点都有9个anchors,每个anchors又都有4个用于回归的变换量
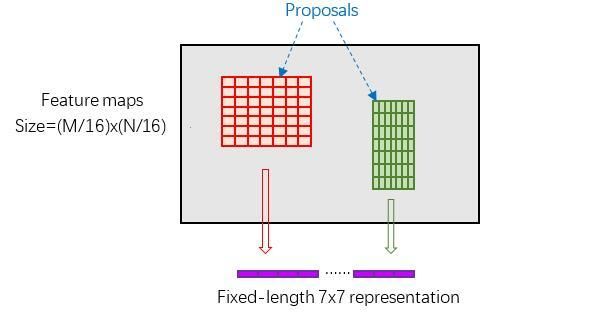
3 RoI pooling
而RoI Pooling层则负责收集proposal,并计算出proposal feature maps,送入后续网络。从图中可以看到Rol pooling层有2个输入:
- 原始的feature maps
- RPN输出的proposal boxes(大小各不相同)
先来看一个问题:对于传统的CNN(如AlexNet,VGG),当网络训练好后输入的图像尺寸必须是固定值,同时网络输出也是固定大小的vector or matrix。如果输入图像大小不定,这个问题就变得比较麻烦。有2种解决办法:

- 从图像中crop一部分传入网络
- 将图像warp成需要的大小后传入网络
回忆RPN网络生成的proposals的方法:对foreground anchors进行bounding box regression,那么这样获得的proposals也是大小形状各不相同,即也存在上述问题。所以Faster R-CNN中提出了RoI Pooling解决这个问题。不过RoI Pooling确实是从Spatial Pyramid Pooling发展而来。。
RoI Pooling layer forward过程:在之前有明确提到: 是对应MxN尺度的,所以首先使用spatial_scale参数将其映射回(M/16)x(N/16)大小的feature maps尺度;之后将每个proposal水平和竖直分为pooled_w和pooled_h份,对每一份都进行max pooling处理。这样处理后,即使大小不同的proposal,输出结果都是相同大小,实现了fixed-length output(固定长度输出)。
4 Classification
Classification部分利用已经获得的proposal feature maps,通过full connect层与softmax计算每个proposal具体属于那个类别(如人,车,电视等),输出cls_prob概率向量;同时再次利用bounding box regression获得每个proposal的位置偏移量bb从PoI Pooling获取到7x7=49大小的proposal feature maps后,送入后续网络,可以看到做了如下2件事:
- 通过全连接和softmax对proposals进行分类,这实际上已经是识别的范畴了
- 再次对proposals进行bounding box regression,获取更高精度的rect boxox_pred,用于回归更加精确的目标检测框。