首先介绍一下solr
Solr现在是一个独立的服务器。
从Solr5.0开始,Solr不再发布为在任何Servlet容器(tomcat等 自带一个jetty服务器)中部署的“war”Web应用程序包(Web Application Archive)。Solr现在部署为一个独立的java服务器应用程序,包含在Unix、linux和Windows平台上可以使用的启动和停止脚本,以及将Solr作为服务安装到类Unix平台的/etc/init.d下的安装脚本。
从本质上看,Solr仍然以Servlet APIs实现,并在Jetty上运行,但只是作为一个实现。部署为“webapp”到其他的Servlet容器(或其他Jetty实例)上不被支持,可能在未来的Solr 5.x版本不会工作。而可能会带来Solr的其他改变,事实上是利用自定义网络协议栈功能
一、安装JAVA环境以及JRE
# cd /tmp/
# tar zxvf jdk-7u9-linux-x64.tar.gz
# mv jdk1.7.0_09 /usr/
# vi /etc/profile
在最后一行复制以下代码添加如下内容:
JAVA_HOME=/usr/jdk1.7.0_09/
CLASSPATH=.:$JAVA_HOME/lib/tools.jar
PATH=$JAVA_HOME/bin:$PATH
export JAVA_HOME CLASSPATH PATH
保存退出(:wq!)后,执行下面命令生效:
source /etc/profile
二、安装Solr5.3.1
去http://www.apache.org/dyn/closer.lua/lucene/solr/5.3.1下载Solr安装文件solr-5.3.1.tgz。
将solr-5.3.1.tgz文件放到/home/solr目录下,执行如下脚本:
创建应用程序目录
# mkdir -p /home/solr
# cd /home/solr
# tar -zxvf solr-5.3.1.tgz // 解压压缩包
创建运行solr的用户并赋权
# groupadd solr
# useradd -g solr solr
# chown -R solr.solr /home/solr 将home/solr下面的所有目录修改成solr用户权限
三、安装solr服务
# solr-5.3.1/bin/install_solr_service.sh solr-5.3.1.tgz -d /home/solr/data -i /home/solr
至此已经安装好solr5.3.1然后检查服务状态
#service solr status
将会看到如下输出:
Solr process 29692 running on port 8983
{
"solr_home":"/home/solr/data/",
"version":"5.3.1 1696229 - noble - 2015-12-4 17:10:43",
"startTime":"2015-12-4T01:32:03.919Z",
"uptime":"0 days, 0 hours, 3 minutes, 6 seconds",
"memory":"89.8 MB (%18.3) of 490.7 MB"
}
说明已经正常启动
四、查看solr命令选项
solr命令用法
定位到solr应用程序目录
# cd /home/solr/solr-5.3.1/solr
# ./bin/solr restart|start|stop 重启|启动|关闭 服务
接下来就是添加core或者集合的时候了
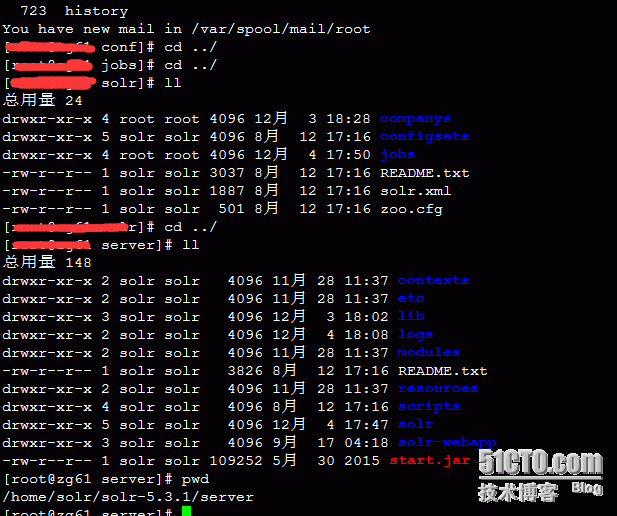
一、首先创建一个core 命令为:su - solr -c "/home/solr/solr-5.3.1/bin/solr create -c companys"或者 切换到/home/solr/solr-5.3.1/ 目录下 通过./bin/solr create -c companys
su - solr意思是切换到solr用户后进行创建core核心
如果以上命令把core创建到/home/solr/data/下面的话 是有问题的 solr默认加载的core目录是在
/home/solr/solr-5.3.1/server/solr/下面,然后可以复制/home/solr/data/下面core或者集合到/home/solr/solr-5.3.1/server/solr/目录下面(纠正:其实这段是有问题的后来查看资料发现solr默认的数据文件是在根目录下面即/home/solr/data)
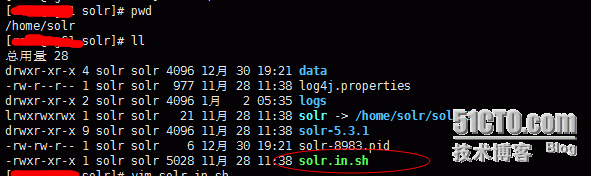
这块的真正原因在于安装脚本的时候默认的路径 其实这里可以修改 如下图所示:
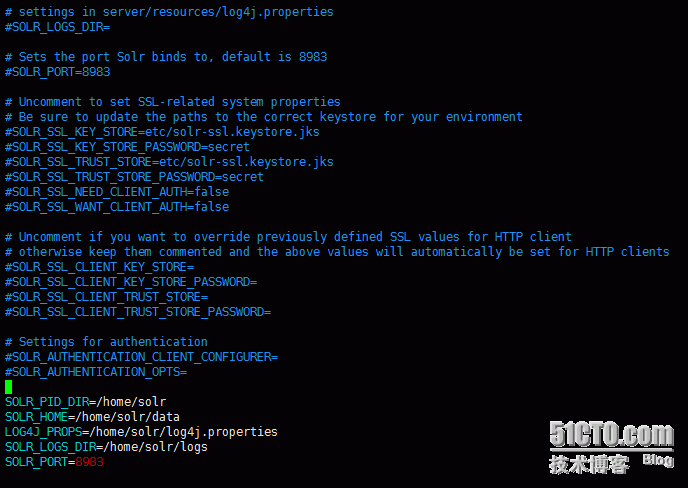
SOLR_PID_DIR=/home/solr
SOLR_HOME=/home/solr/data 主要是这块的配置 如果是在server下面的solr就会将core和索引数据创建到server下面 如果是根目录data那么索引就会在data下面
LOG4J_PROPS=/home/solr/log4j.properties
SOLR_LOGS_DIR=/home/solr/logs
SOLR_PORT=8983
然后重启solr服务
启动步骤:
(1)切换到/home/solr/solr-5.3.1/
(2)执行: # ./bin/solr restart 等待几秒中会自动重启成功
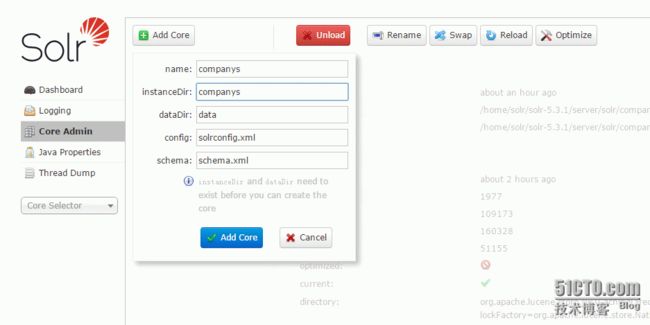
(3)接下来就会创建好相关的core或者集合 如下图所示:
二、接下来看看core里面的组成部分 进入companys core目录下面
里面有conf、data2个目录和core.properties
接着进入conf目录下面里面有下图几个配置文件和相关其他文件

其中solrconfig.xml是solr的相关配置文件
managed_schema主要定义索引的字段和字段类型还有一些分词等等设置 (类似于数据表配置文件貌似是solr5以后的文件名)
data-config.xml是将mysql数据导入到solr的相关配置 首先得在solrconfig.xml中配置开启一个xml选项后
data-config.xml
然后在data-config.xml里面设置以下
注:上面的database_name是你创建的数据库名,userName是数据库用户名,passWord是数据库密码,tableName是你的表名,field区域当中的column对应数据库中的列,而name就是solr中显示的名称。
(1)在配置完以上设置项后还需要将solr-dataimporthandler-5.3.1.jar从solr-5.3.1/dist/文件夹下copy到solr-5.3.1/server/solr-webapp/webapp/WEB-INF/lib当中,此jar包是导入数据用的。
(2)再从mysql官网中下载一个mysql-connector-java-5.1.35.zip压缩包,解压出一个mysql-connector-java-5.1.35-bin.jar包,将它copy到solr-5.3.1/server/lib下。
然后在solr的管理平台才能通过在浏览器中输入:localhost:8983/solr/dataimport?command=full-import或者图形操作来完成全量数据导入,在每次全量数据导入执行的时候,原有索引会被删除,如果不想删除原有索引,可以运行如下命令:localhost:8983/solr/dataimport?command=full-import&clean=false
三、接下来讲解shema的设置
vim managed-schema 之前版本名称叫shema.xml 最新版貌似改了 然后在里面添加数据库相关字段

接下来介绍字段相关知识:
性能须知: 这里包含了很多实际应用不需要的可选项。 为改善性能,你可以:
- 尽量将所有仅用于搜索,而不用于实际返回的字段设置stored="false";
- 尽量将所有仅用于返回,而不用于搜索的字段设置indexed="false";
- 去掉所有不需要的copyField 语句;
- 为了达到最佳的索引大小和搜索性能,对所有的文本字段设置indexed="false",
使用copyField将他们拷贝到“整合字段”name="text"的字段中,使用整合字段进行搜索;
- 使用server模式来运行JVM,同时将log级别调高, 避免输出所有请求的日志。
-->
。。。。。
-->
name: 必须属性 - 字段名
type: 必须属性 - 中定义的字段类型
indexed: 如果字段需要被索引(用于搜索或排序),属性值设置为true
stored: 如果字段内容需要被返回,值设置为true
docValues: 如果这个字段应该有文档值(doc values),设置为true。文档值在门面搜索,分组,排序和函数查询中会非常有用。虽然不是必须的,而且会导致 生成索引变大变慢,但这样设置会使索引加载更快,更加NRT友好,更高的内存使用效率。然而也有一些使用限制:目前仅支持StrField, UUIDFiel d和所有 Trie*Fields, 并且依赖字段类型, 可能要求字段为单值(single-valued)的,必须的或者有默认值。
multiValued: 如果这个字段在每个文档中可能包含多个值,设置为true
termVectors: [false] 设置为true后,会保存所给字段的相关向量(vector)
当使用MoreLikeThis时, 用于相似度判断的字段需要设置为stored来达到最佳性能.
termPositions: 保存和向量相关的位置信息,会增加存储开销
termOffsets: 保存 offset 和向量相关的信息,会增加存储开销
required: 字段必须有值,否则会抛异常
default: 在增加文档时,可以根据需要为字段设置一个默认值,防止为空
sortMissingLast: 指没有该指定字段数据的document排在有该指定字段数据的document的后面
sortMissingFirst: 指没有该指定字段数据的document排在有该指定字段数据的document的前面
omitNorms: 字段的长度不影响得分和在索引时不做boost时,设置它为true。一般文本字段不设置为true。
compressed: 字段是压缩的。这可能导致索引和搜索变慢,但会减少存储空间,只有StrField和TextField是可以压缩,这通常适合字段的长度超过200个字符。
positionIncrementGap: 和multiValued一起使用,设置多个值之间的虚拟空白的数量
-->
id
文档的唯一标识, 必须填写这个field(除非该field被标记required="false"),否则solr建立索引报错。
name
如果搜索参数中没有指定具体的field,那么这是默认的域。
配置搜索参数短语间的逻辑,可以是"AND|OR"。
中文分词后续在介绍。。。。。。。
四、至此所有配置都已经完成,接下来重启solr 进入到/home/solr/solr-5.3.1/solr 然后执行
# ./bin/solr restart
等待启动以后然后通过
http://localhost:8983/solr/#/进入到solr的管理平台页面
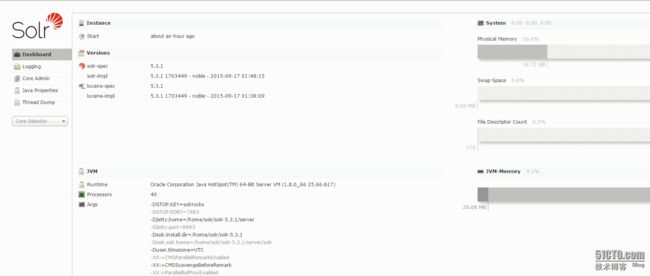
下图就是在添加一个core或者集合 首先得完成上面的那些配置 主要是先通过命令去生成一个core然后配置好或者不配置然后在这里添加,通过错误提示然后进行配置或者文件相关创建或者修改等等
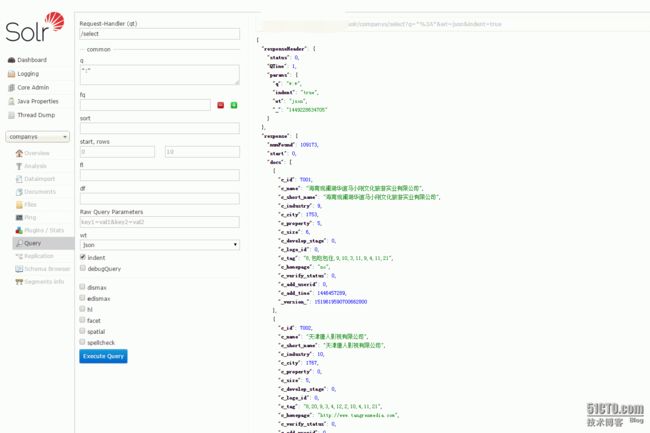
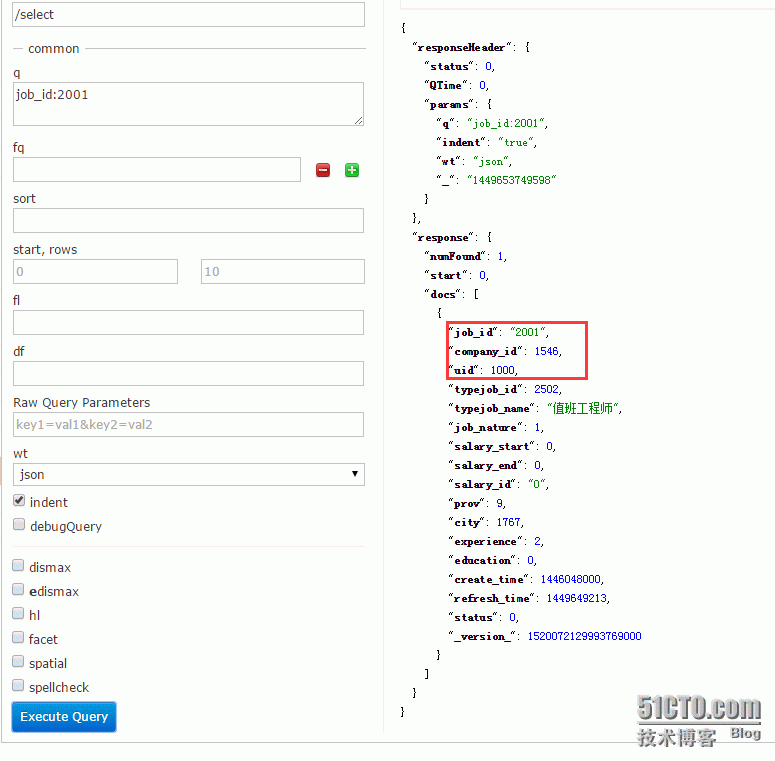
下图展示一个core里面的查询相关的数据:
数据导入有两种实现方式
(1)通过solr自带的导入方式 有全量导入和增量导入 首先得配置好上面第二部分和第三部分红色的
然后点击
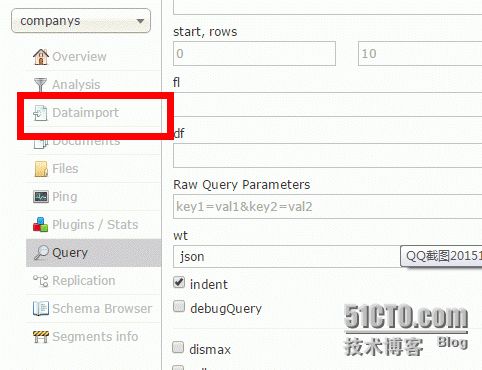
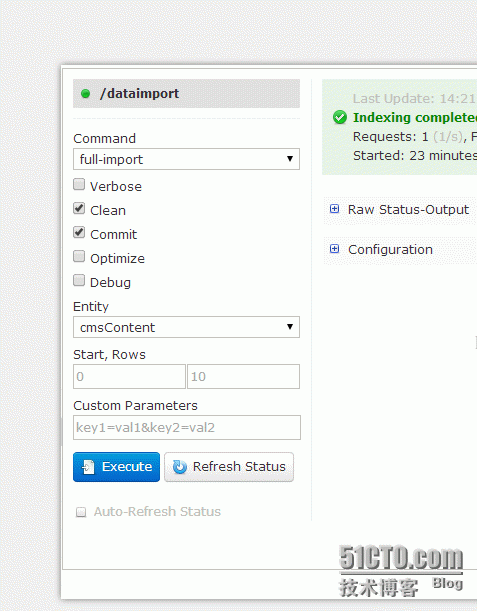
选择好相关选项后点击 execute按钮 就会在右侧显示相关实时动态
最后补充几个容易忽视的问题也会对使用造成干扰
1、
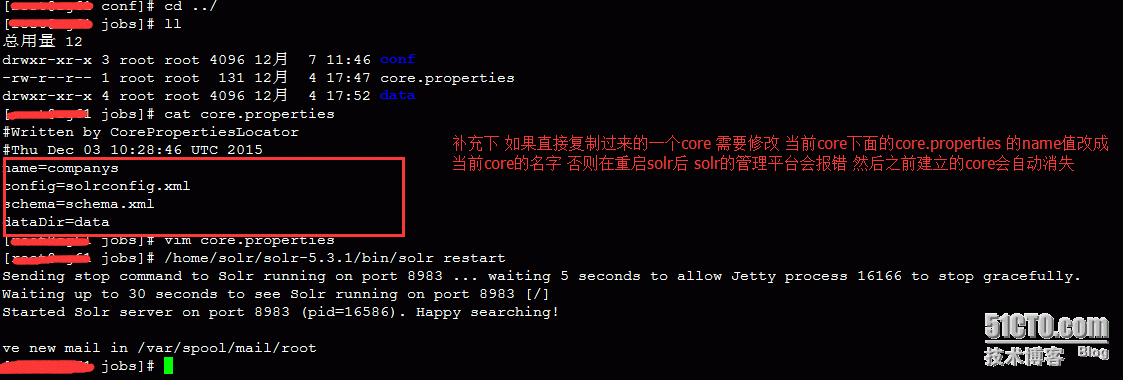
改完重启solr以后 再次打开solr的管理平台 就会自动出现已经创建好的core 如图:

2、配置好的solr没有任何数据,启动时报错:SolrException: Invalid Number: MA147LL/A
这不是你的错,你可能是把solr schema.xml的id设置成了int类型,设置成int类型没什么错,但是solr启动是会扫描conf目录下的elevate.xml文件,这个文件中定义的id值是MA147LL/A所以就会出现异常SolrException: Invalid Number: MA147LL/A
解决问题的方法是修改elevate.xml文件,将其中的id值设置为数字,就可以了。
3、如果配置好后执行更新solr数据命令后 solr报以下错误后
只需要把当前core的managed-schema或者schema.xml配置文件中的自增id改成string类型 重启solr后就不会报错了这是因为solr本身索引是基于文本值的

c_id
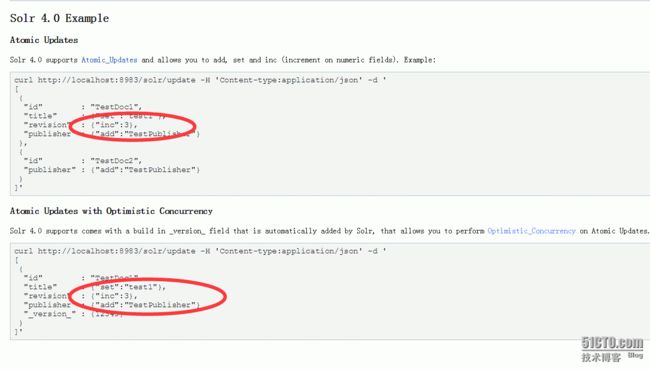
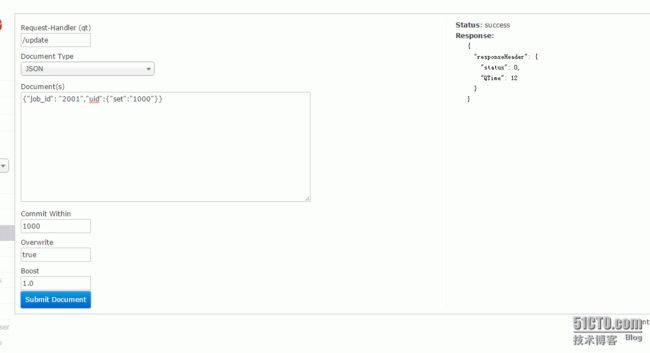
4、solr的原子更新 就是只改某个字段问题解决:
官网文档地址:http://wiki.apache.org/solr/UpdateJSON#Solr_4.0_Example
至此 安装和测试数据整合已经完毕 特此备注下已备忘 欢迎各位拍砖。。。。。
下一篇会讲solr的一些用法solr5使用方法篇以及高级功能facet使用
本文出自 “网站架构技术总结” 博客,请务必保留此出处http://mengphilip.blog.51cto.com/2243393/1719686