虽然最近爬虫的风声很紧,有大数据公司因为爬虫而犯法,但是这简单基础的技术我们还是应该掌握的,做数据挖掘没有数据怎么挖掘,爬取的数据不要用来商用,问题应该不大,下面给大家介绍下scrapy分布式爬虫部署与监控。
一、准备条件
1.scrapy爬虫
项目部署之前需要一个编写完成,并且可以直接运行的scrapy爬虫,这里只介绍爬虫的部署与监控,如果想了解scrapy的知识,请进入scrapy的官网:
https://scrapy-chs.readthedocs.io/zh_CN/0.24/intro/tutorial.html
2.scrapyd
Scrapyd是一个服务,用来运行scrapy爬虫的,可以部署和管理scrapy项目,它允许你部署你的scrapy项目以及通过HTTP JSON的方式控制你的爬虫。官方文档:http://scrapyd.readthedocs.org/
安装:
pip install scrapyd
安装完成后,在你当前的python环境根目录F:\software\Python37\Scripts下,有一个scrapyd.exe:
打开命令行,输入scrapyd,如下图:
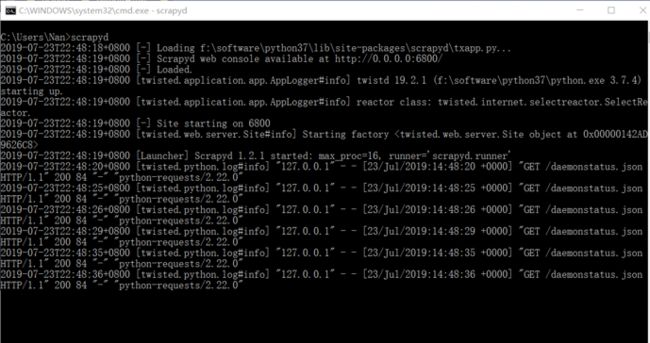
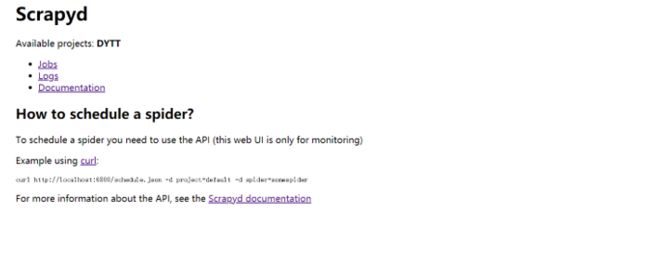
这样scrapyd就运行起来了,访问127.0.0.1:6800即可看到可视化界面:
注:如果在命令行运行scrapyd报错如下图:
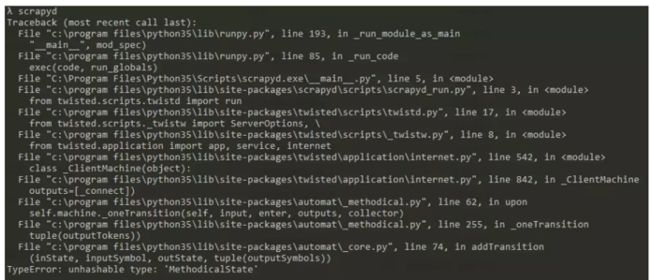
先pip list 查看你的attrs这个包的版本 然后降到16.3 再试试。
理解scrapyd
scrapyd其实就是一个服务器端,真正在部署爬虫的时候,我们需要两个东西:
scrapyd (安装在服务器端)
scrapy-client (客户端)
scrapy-client,它允许我们将本地的scrapy项目打包发送到scrapyd 这个服务端
安装 scrapy-client:pip install scrapyd-client
二、部署scrapy服务
在scrapy项目目录下,有一个scrapy.cfg的配置文件:

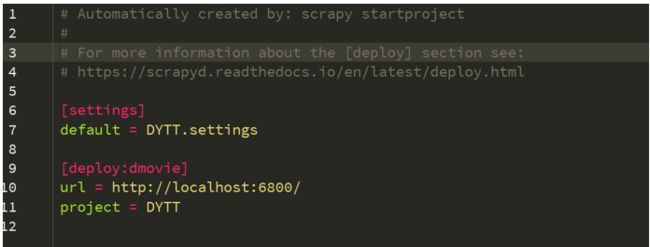
把原先注释掉的url那一行取消注释,这个就是我们要部署到目标服务器的地址,
然后,把[deploy]这里改为[deploy:dmovie],这里是命名为dmovie,命名可以任意怎么都可以,只要能标识出来项目就可以。
下边的project 就是我们的工程名,到此配置文件更改完成。
接着,执行scrapyd-deploy,这个命令在windows下是运行不了的,(在mac和linux下都是可以的)因为在我们安装的根目录C:\Program Files\Python35\Scripts中可以查看这个文件是没有后缀名的:
解决方法:在同目录下,新建文件scrapyd-deploy.bat


上边代码是调用的我的环境中的python.exe路径,大家可以根据自己环境来改变路径做配置。
这样就可以执行scrapyd-deploy这个命令了。
然后,进入到我们爬虫的根目录,运行scrapyd-deploy:

显示这个就证明我们成功执行了scrapyd-deploy,注意:一定要进入爬虫根目录,就是带有scrapy.cfg的那一层及目录。
接着:
运行:scrapyd-deploy dmovie -p DYTT

到这一步,只是把爬虫项目上传到服务端,并没有启动,
接下来看看如何启动:
先运行命令查看服务端状态:curl http://localhost:6800/daemonstatus.json

再执行启动命令:
curl http://localhost:6800/schedule.json-d project=DYTT -d spider=dytt
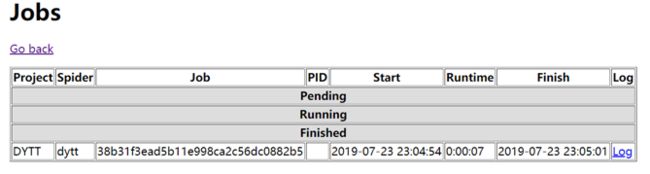
然后查看网页127.0.0.1:6800

点击jobs:
三、scrapydweb
1.安装与配置
a,请先确保所有主机都已经安装和启动 Scrapyd,如果需要远程访问 Scrapyd,则需将 Scrapyd 配置文件中的 bind_address 修改为 bind_address = 0.0.0.0,然后重启 Scrapyd service。
b,开发主机或任一台主机安装 ScrapydWeb:pip install scrapydweb
c,通过运行命令 scrapydweb 启动 ScrapydWeb(首次启动将自动在当前工作目录生成配置文件)。
d,启用 HTTP 基本认证(可选):

e,运行命令 scrapydweb 重启 ScrapydWeb。
2.访问webUi
通过浏览器访问并登录 http://127.0.0.1:5000
Servers 页面自动输出所有 Scrapyd server 的运行状态。
通过分组和过滤可以自由选择若干台 Scrapyd server,然后在上方 Tabs 标签页中选择 Scrapyd 提供的任一 HTTP JSON API,实现一次操作,批量执行。
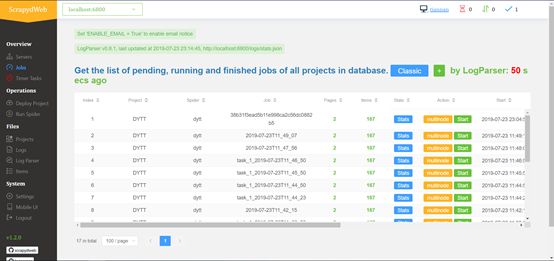
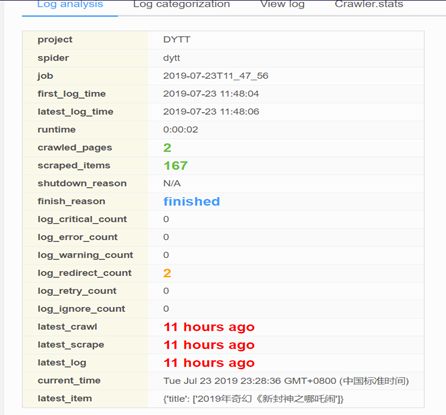
通过集成 LogParser,Jobs 页面自动输出爬虫任务的 pages 和 items 数据。
ScrapydWeb 默认通过定时创建快照将爬虫任务列表信息保存到数据库,即使重启 Scrapyd server 也不会丢失任务信息。(issue 12)
3.项目部署
通过配置 SCRAPY_PROJECTS_DIR 指定 Scrapy 项目开发目录,ScrapydWeb 将自动列出该路径下的所有项目,默认选定最新编辑的项目,选择项目后即可自动打包和部署指定项目。
如果 ScrapydWeb 运行在远程服务器上,除了通过当前开发主机上传常规的 egg 文件,也可以将整个项目文件夹添加到 zip/tar/tar.gz 压缩文件后直接上传即可,无需手动打包为 egg 文件。
支持一键部署项目到 Scrapyd server 集群
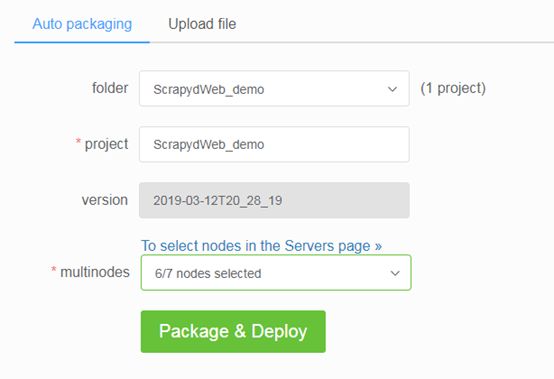
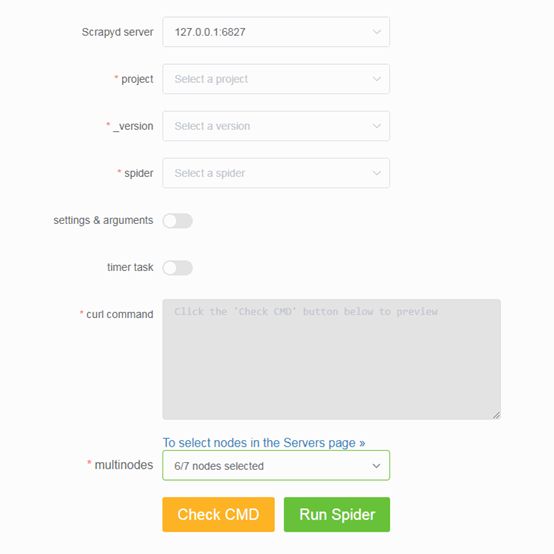
4.运行爬虫
a.通过下拉框依次选择 project,version 和 spider。
b.支持传入 Scrapy settings 和 spider arguments。
c.支持创建基于 APScheduler 的定时爬虫任务。(如需同时启动大量爬虫任务,则需调整 Scrapyd 配置文件的 max-proc参数)
d.支持在 Scrapyd server 集群上一键启动分布式爬虫。
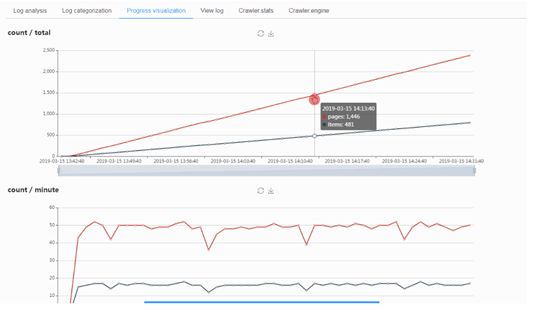
5.日志分析和可视化
如果在同一台主机运行 Scrapyd 和ScrapydWeb,建议设置 SCRAPYD_LOGS_DIR 和 ENABLE_LOGPARSER,则启动 ScrapydWeb 时将自动运行 LogParser,该子进程通过定时增量式解析指定目录下的 Scrapy 日志文件以加快 Stats 页面的生成,避免因请求原始日志文件而占用大量内存和网络资源。
同理,如果需要管理 Scrapyd server 集群,建议在其余主机单独安装和启动LogParser。
如果安装的 Scrapy 版本不大于 1.5.1,LogParser 将能够自动通过 Scrapy 内建的 Telnet Console 读取 Crawler.stats 和 Crawler.engine 数据,以便掌握 Scrapy 内部运行状态。
6.定时爬虫任务
支持查看爬虫任务的参数信息,追溯历史记录
支持暂停,恢复,触发,停止,编辑和删除任务等操作

7.邮件通知
通过轮询子进程在后台定时模拟访问 Stats 页面,ScrapydWeb 将在满足特定触发器时根据设定自动停止爬虫任务并发送通知邮件,邮件正文包含当前爬虫任务的统计信息。
添加邮箱帐号:
SMTP_SERVER = 'smtp.qq.com'
SMTP_PORT = 465
SMTP_OVER_SSL = True
SMTP_CONNECTION_TIMEOUT = 10
EMAIL_USERNAME = '' # defaults to FROM_ADDR
EMAIL_PASSWORD = 'password'
FROM_ADDR = '[email protected]'
TO_ADDRS = [FROM_ADDR]
设置邮件工作时间和基本触发器,以下示例代表:每隔1小时或当某一任务完成时,并且当前时间是工作日的9点,12点和17点,ScrapydWeb将会发送通知邮件。
EMAIL_WORKING_HOURS = [9, 12, 17]
ON_JOB_RUNNING_INTERVAL = 3600
ON_JOB_FINISHED = True
EMAIL_WORKING_DAYS = [1, 2, 3, 4, 5]
除了基本触发器,ScrapydWeb还提供了多种触发器用于处理不同类型的 log,包括 'CRITICAL', 'ERROR', 'WARNING', 'REDIRECT', 'RETRY' 和 'IGNORE'等。
LOG_CRITICAL_THRESHOLD = 3
LOG_CRITICAL_TRIGGER_STOP = True
LOG_CRITICAL_TRIGGER_FORCESTOP = False
# ...
LOG_IGNORE_TRIGGER_FORCESTOP = False
以上示例代表:当日志中出现3条或以上的 critical 级别的 log 时,ScrapydWeb将自动停止当前任务,如果当前时间在邮件工作时间内,则同时发送通知邮件。
#######################################################
创作不易,感觉文章还可以,微信扫一扫打赏给1元喝咖啡。
