这里是 「王喆的机器学习笔记」的第七篇文章,今天我们聊一聊KDD 2018的Best Paper,Airbnb的一篇极具工程实践价值的文章
Real-time Personalization using Embeddings for Search Ranking at Airbnb 。
相信大家已经比较熟悉我选择计算广告和推荐系统相关文章的标准:
1.工程导向的;
2.阿里、facebook、google等一线互联网公司出品的;
3.前沿或者经典的。
Airbnb这篇文章无疑又是一篇兼具实用性和创新性的工程导向的paper。文章的作者Mihajlo发表这篇文章之前在Recsys 2017上做过一个talk,其中涉及了文章中的大部分内容,我也将结合那次talk的slides来讲解这个论文。
废话不多说,我们进入文章的内容。
Airbnb作为全世界最大的短租网站,提供了一个连接房主(host)挂出的短租房(listing)和主要是以旅游为目的的租客(guest/user)的中介平台。这样一个中介平台的交互方式比较简单,guest输入地点,价位,关键词等等,Airbnb会给出listing的搜索推荐列表:
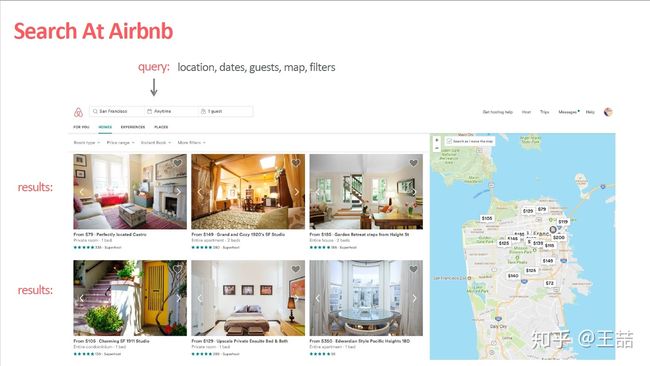
Airbnb的业务场景
容易想见,接下来guest和host之间的交互方式无非有这样几种:
1.guest点击listing (click)
2.guest预定lising (book)
3.host有可能拒绝guest的预定请求 (reject)
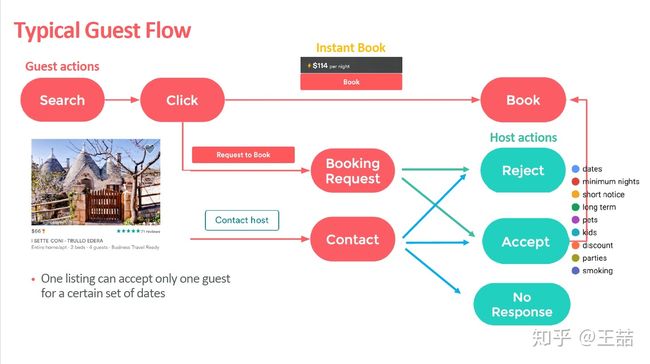
Airbnb的交互方式
基于这样的场景,利用几种交互方式产生的数据,Airbnb的search团队要构建一个real time的ranking model。为了捕捉到用户short term以及long term的兴趣,Airbnb并没有把user history的clicked listing ids或者booked listing ids直接输入ranking model,而是先对user和listing进行了embedding,进而利用embedding的结果构建出诸多feature,作为ranking model的输入。这篇文章的核心内容就是介绍如何生成listing和user的embedding。
具体到embedding上,文章通过两种方式生成了两种不同的embedding分别capture用户的short term和long term的兴趣。
一是通过click session数据生成listing的embedding,生成这个embedding的目的是为了进行listing的相似推荐,以及对用户进行session内的实时个性化推荐。
二是通过booking session生成user-type和listing-type的embedding,目的是捕捉不同user-type的long term喜好。由于booking signal过于稀疏,Airbnb对同属性的user和listing进行了聚合,形成了user-type和listing-type这两个embedding的对象。
我们先讨论第一个对listing进行embedding的方法:
Airbnb采用了click session数据对listing进行embedding,其中click session指的是一个用户在一次搜索过程中,点击的listing的序列,这个序列需要满足两个条件,一个是只有停留时间超过30s的listing page才被算作序列中的一个数据点,二是如果用户超过30分钟没有动作,那么这个序列会断掉,不再是一个序列。

Click Session的定义和条件
这么做的目的无可厚非,一是清洗噪声点和负反馈信号,二是避免非相关序列的产生。
有了由clicked listings组成的sequence,就像我们在之前专栏文章中讲过的item2vec方法一样,我们可以把这个sequence当作一个“句子”样本,开始embedding的过程。Airbnb不出意外的选择了word2vec的skip-gram model作为embedding方法的框架。通过修改word2vec的objective使其靠近Airbnb的业务目标。
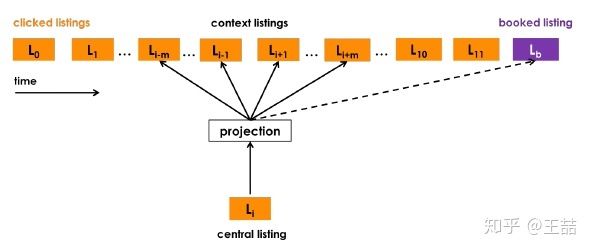
Airbnb的类word2vec embedding方法
我们在之前的专栏文章
万物皆embedding
中详细介绍了word2vec的方法,不清楚的同学还是强烈建议先去弄明白word2vec的基本原理,特别是objective的形式再继续下面的阅读。
我们假设大家已经具备了基本知识,这里直接列出word2vec的skip-gram model的objective如下:
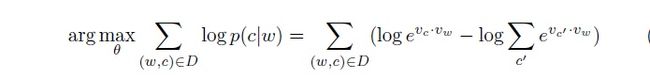
在采用negative sampling的训练方式之后,objective转换成了如下形式:
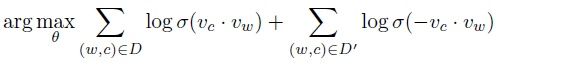
其中σ函数代表的就是我们经常见到的sigmoid函数,D是正样本集合,D'是负样本集合。我们再详细看一下上面word2vec这个objective function,其中前面的部分是正样本的形式,后面的部分是负样本的形式(仅仅多了一个负号)。
为什么原始的objective可以转换成上面的形式,其实并不是显然的,感兴趣的同学可以参考这篇文章,
Negative-Sampling Word-Embedding Method
。这里,我们就以word2vec的objective function为起点,开始下面的内容。
转移到Airbnb这个问题上,正样本很自然的取自click session sliding window里的两个listing,负样本则是在确定central listing后随机从语料库(这里就是listing的集合)中选取一个listing作为负样本。
因此,Airbnb初始的objective function几乎与word2vec的objective一模一样,形式如下:
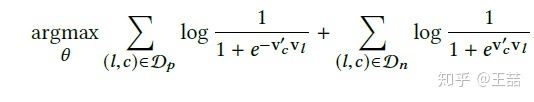
(给大家出个脑筋急转弯,为啥Airbnb objective的正样本项前面是负号,原始的word2vec objective反而是负样本项前面是负号,是Airbnb搞错了吗?)
在原始word2vec embedding的基础上,针对其业务特点,Airbnb的工程师希望能够把booking的信息引入embedding。这样直观上可以使Airbnb的搜索列表和similar item列表中更倾向于推荐之前booking成功session中的listing。从这个motivation出发,Airbnb把click session分成两类,最终产生booking行为的叫booked session,没有的称做exploratory session。
因为每个booked session只有最后一个listing是booked listing,所以为了把这个booking行为引入objective,我们不管这个booked listing在不在word2vec的滑动窗口中,我们都会假设这个booked listing与滑动窗口的中心listing相关,所以相当于引入了一个global context到objective中,因此,objective就变成了下面的样子
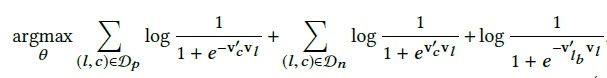
其中最后一项的lb就是代表着booked listing,因为booking是一个正样本行为,这一项前也是有负号的。
需要注意的是最后一项前是没有sigma符号的,前面的sigma符号是因为滑动窗口中的中心listing与所有滑动窗口中的其他listing都相关,最后一项没有sigma符号直观理解是因为booked listing只有一个,所以central listing只与这一个listing有关。
但这里的objective的形式我仍让是有疑问的,因为这个objective写成这种形式应该仅代表了一个滑动窗口中的objective,并不是整体求解的objective。如果是整体的objective,理应是下面的形式:
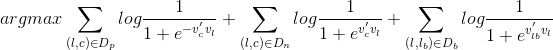
其中Db代表了所有booked session中所有滑动窗口中central listing和booked listing的pair集合。
不知道大家有没有疑问,我们可以在这块多进行讨论。
下面这一项就比较容易理解了,为了更好的发现同一市场(marketplace)内部listing的差异性,Airbnb加入了另一组negative sample,就是在central listing同一市场的listing集合中进行随机抽样,获得一组新的negative samples。同理,我们可以用跟之前negative sample同样的形式加入到objective中。
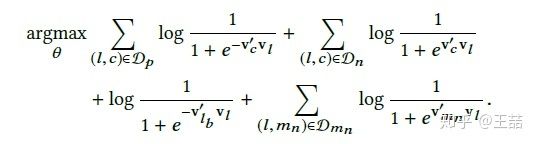
其中Dmn就是新的同一地区的negative samples的集合。
至此,lisitng embedding的objective就定义完成了,embedding的训练过程就是word2vec negative sampling模型的标准训练过程,这里不再详述。
除此之外,文章多介绍了一下cold start的问题。简言之,如果有new listing缺失embedding vector,就找附近的3个同样类型、相似价格的listing embedding进行平均得到,不失为一个实用的工程经验。
为了对embedding的效果进行检验,Airbnb还实现了一个tool,我们简单贴一个相似embedding listing的结果。
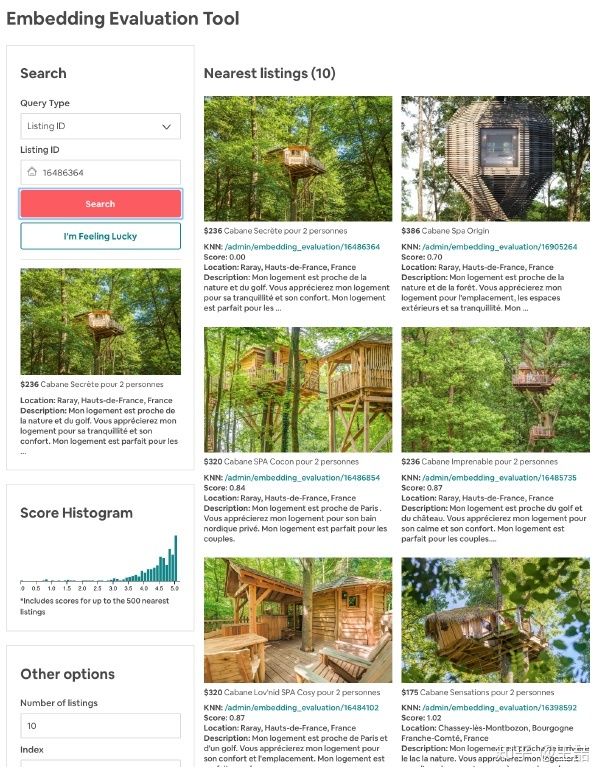
Airbnb Similar Listing
从中可以看到,embedding不仅encode了price,listing-type等信息,甚至连listing的风格信息都能抓住,说明即使我们不利用图片信息,也能从用户的click session中挖掘出相似风格的listing。
至此我们介绍完了Airbnb利用click session信息对listing进行embedding的方法。写到这里笔者基本要断气了,下一篇我们再接着介绍利用booking session进行user-type和listing-type embedding的方法,以及Airbnb如何把这些embedding feature整合到最终的search ranking model中的方法。(下篇已更新
王喆:Airbnb如何解决Embedding的数据稀疏问题?
)
最后给大家三个问题以供讨论:
1.为什么Airbnb objective中正负样本的正负号正好跟word2vec objective的正负号正好相反?
2.Airbnb加入booked listing作为global context,为什么在objective中不加sigma加和符号?
3.这里我们其实只得到了listing的embedding,如果是你,你会怎样在real time search ranking过程中使用得到的listing embedding?

这里是 「王喆的机器学习笔记」的第七篇文章,水平有限,欢迎大家拍砖、吐槽、讨论。觉得有收获的同学也欢迎点赞,谢谢。
参考资料:
1.Search Ranking and Personalization at Airbnb Slides
2.Real-time Personalization using Embeddings for Search Ranking at Airbnb
3.Negative-Sampling Word-Embedding Method
4.Recommender System Paper List