
GraphQL 是一种新的 API 标准,它提供了一种更高效、强大和灵活的数据提供方式,由 Facebook 发起并开源,目前由来自世界各地的大公司和个人共同维护。
GraphQL 本质上是一种基于 API 的查询语言,现在大多数应用程序都需要从服务器中获取数据,这些数据存储可能存储在数据库中,API 的职责是提供与应用程序需求相匹配的存储数据的接口。
我们经常把 GraphQL 和数据库技术相混淆,这是一个误解,GraphQL 是 API 的查询语言,而不是数据库,它是数据库无关的,而且可以在使用 API 的任何环境中有效使用。
我们经常把 GraphQL 和数据库技术相混淆,这是一个误解,GraphQL 是 API 的查询语言,而不是数据库,它是数据库无关的,而且可以在使用 API 的任何环境中有效使用。
GraphQL 是基于 API 之上的一层封装,目的是为了更好、更灵活的适用于业务的需求变化。
GraphQL 产生的历史背景
提起 API 设计的时候,大家通常会想到 SOAP、RESTful 等设计方式,从 2000 年 RESTful 的理论被 Roy Fielding (HTTP 规范的主要编写者之一)在其博士论文中提出的时候,在业界引起了很大反响,因为这种设计理念更易于用户的使用,所以便很快的被大家所接受。
RESTful 是目前(2019 年)从服务器公开 API 的最为流行的方式(没有之一),当 RESTful 的概念被提及出来时,客户端应用程序对数据的需求相对简单,而开发的速度并没有达到今天的水平。
RESTful 对于许多简单的应用程序来说是适合的,然而当业务越来越复杂、客户对系统的扩展性有更高要求时,API 会发生巨大的变化,由此带来了 API 设计的巨大挑战。

更高效的数据加载方式
Facebook 发起 GraphQL 的最初原因是移动端用户的爆发式增长需要更高效的数据加载方式。
GraphQL 最小化了需要网络传输的数据量,从而极大地改善了在这些条件下运行的应用程序。

适应不同的前端框架和平台
各种不同的前端框架和平台,运行客户端应用程序的不同环境,使得我们在构建和维护一个符合所有需求的 API 变得困难,但使用 GraphQL 的每个客户机都可以精确地访问它需要的数据。

加快产品开发速度
持续部署已经成为许多公司的标准,快速的迭代和频繁的产品更新是必不可少的。
对于 RESTful API,服务器公开数据的方式常常需要修改,以满足客户端的特定需求和设计更改,这阻碍了快速开发实践和产品迭代。
在不同前端框架、不同平台下想要加快产品快速开发变的越来越难。
什么是 GraphQL
GraphQL 是一套 API 语言规范,Facebook 于 2012 年应用于移动应用,并于 2015 年开源。

GraphQL 既是一种用于 API 的查询语言也是一个满足你数据查询的运行时。
GraphQL 对 API 中的数据提供了一套易于理解的完整描述,使客户端能够准确地获得它需要的、没有冗余的数据,也使 API 更容易地随着时间推移而演进,还能用于构建强大的开发者工具,GraphQL 可以一次请求获取你所需的所有数据。
GraphQL 是处于 API 层的灵活的、开放的一套规范,将 GraphQL 置于现有后端上,可以比以往更快捷的构建产品。
GraphQL 与 RESTful 简单比较
GraphQL 可以理解为基于 RESTful 的一种封装,目的在于构建使客户端更加易用的服务,可以说 GraphQL 是更好的 RESTful 设计,号称 RESTful 2.0。

在过去的十多年中,RESTful 已经成为设计 WEB API 的实际标准。它提供了一些很棒的想法,比如无状态服务器和结构化的资源访问。然而 RESTful API 表现得过于僵化,无法跟上客户端需求的快速变化。
GraphQL 的开发是为了提高更多的灵活性和效率,它解决了与 RESTful API 交互时开发人员所经历的许多缺点和低效之处。
为了说明获取数据时 RESTful 和 GraphQL 之间的主要区别,让我们考虑一个简单的示例场景:在 blog 应用程序中,应用程序需要显示特定用户的文章的标题。同一屏幕还显示该用户最后 3 个关注者的名称。REST 和 GraphQL 如何解决这种情况?
RESTful 访问数据
使用 RESTful API 来现实时,我们通常可以通过访问多次请求来收集数据。
我们可以通过下面的三步来实现:
- 通过
/user/获取初始用户数据 - 通过
/user/返回用户的所有帖子/posts - 请求
/user/返回每个用户的关注者列表/followers
如下图

在 GraphQL 的世界里我们不用多取数据,也不用担心数据取少了,我们只需要按需获取数据即可。
RESTful 最常见的问题之一是 API 的返回数据过多或者过少,这是因为客户端获取数据的唯一方法是通过访问返回固定数据结构的 endpoint,这就会导致我们设计 API 非常困难,因为它既要能够为客户提供精确的数据需求,又需要满足不同调用者的需求,这本身就是相互矛盾的。GraphQL 的发明者 Lee Byron 提出了一个很重要的概念: “用图形来思考,而不是 endpoint”。
GraphQL 优势
强类型 Schema
对大多数 API 而言,最大的问题在于缺少强类型约束。常见场景为,后端 API 更新了,但文档没跟上,你没法知道新的 API 是干什么的,怎么用,这应该是前后端掐架的原因之一。
GraphQL Schema 是每个 GraphQL API 的基础,它清晰的定义了每个 API 支持的操作,包括输入的参数和返回的内容。
GraphQL Schema 是一份契约,用于指明 API 的功能。
GraphQL Schema 是强类型的,可使用 SDL(GraphQL Schema Definition Language)来定义。相对而言,强类型系统使开发人员自行车换摩托。比如,可以使用构建工具验证 API 请求,编译时检查 API 调用可能发生的错误,甚至可以在代码编辑器中自动完成 API 操作。
Schema 带来的另一个好处是,不用再去编写 API 文档,因为根据 Schema 自动生成了,这改变了 API 开发的玩法。
按需获取
我们经常谈 GraphQL 的主要优点——前端可以从 API 获取想要的数据,不必依赖服务端 RESTful API 返回的固定数据结构。
如此,解决了传统 REST API 的两个典型问题:过度获取(Over Fetching) 和 不足获取(Under Fetching)。
使用 GraphQL,客户端自己决定返回的数据及结构。
过度获取
意味着前端得到了实际不需要的数据,这可能会造成性能和带宽浪费。
通常情况下我们在调用一个通用 API 接口时,客户端获取的信息比应用程序中实际需要的要多。例如 UI 需要显示一个用户列表,而实际上只需要使用他们的名字。在 RESTful API 中通常会调用 /users这个 endpoint,并接收一个带有用户数据的 JSON 数组。但是这个响应可能包含更多关于返回的用户的信息,例如他们的生日或地址,而这些信息对客户来说是无用的,因为它只需要显示用户的名字。
不足获取
不足获取与过度获取想反,API 返回中缺少足够的数据,这意味着前端需要请求额外的 API 得到需要的数据。
最坏的场景下,会导致臭名昭著的 N+1 请求问题:获取数据列表,而没有 API 能够满足列表字段要求,不得不对每行数据发起一次请求,以获取所需额外数据。
假设我们在捣鼓一个博客应用,需要显示 user 列表,除user本身信息外,还要显示每个 user 最近一篇文章的title。然而,调用/users/仅得到用户信息集合,然后不得不对每个user调用/users/获取其最新文章title。
当然你可以再写一个 API 来满足特殊场景,如/users/lastarticles/来满足上面的需求,但需要编写后端相关代码,调试和部署,加班....有这时间何不去陪家人、孩子。
GraphQL 支持快速产品开发
GraphQL 使前端开发人员轻松愉悦,感谢 GraphQL 的前端库(Apollo、Relay或Urql),前端可以用如缓存、实时更新 UI 等功能。
前端开发人员生产力提高,产品开发速度加快,无论 UI 如何变化后端服务不用变。
构建 GraphQL API 的过程大多围绕 GraphQL Scheme。由此,经常听到 Schema-Driven Development(SDD),这只是指一个过程,结构在 Schema 中定义,在 Resolver(解析器)中实现。
有了像GraphQL Faker这样的工具,前端开发可以在 Schema 定义后开始。GraphQL Faker 模拟整个 GraphQL API(依赖于定义的 schema),因此前后端可以独立工作。
Schema 与 java 中的 interface 有点类似,java 开发中,大家可以先定义一个接口(interface),然后基于接口各自干各自的事情,互不干扰。
组合 GraphQL API
Schema 拼接(stitching)是 GraphQL 中的新概念之一,简而言之,可以组合和连接多个 GraphQL API 合并为一个。与 React 或 Vue 中的组件概念类似,一个 GraphQL API 可以由多个 GraphQL API 组合构成。
这对前端开发非常有用,不然,需要与多个 GraphQL endpoint 通信(通常在微服务架构或与第三方 API 集成时)。由于 Schema 拼接,前端只需要处理单个 API endpoint,而协调与各种服务通信的复杂性从前端隐藏。
丰富的开源生态和牛逼闪闪的社区
自 Facebook 正式发布 GraphQL 以来,仅三年多时间,整个 GraphQL 生态系统的成熟程度难以置信。
刚发布时,开发人员使用 GraphQL 的唯一工具是graphql-js参考实现——一个 Express.js 中间件和 GraphQL client Relay。
现在,GraphQL 规范的参考实现几乎覆盖了大部分编程语言,并有大量的 GraphQL 客户端。此外许多工具提供了无缝的工作流程,并在构建 GraphQL API 时提供爽爽的开发体验,如:Primsa、GraphQL Faker、GraphQL Playground、graphql-config 等。
核心概念
SDL(Schema Definition Language)
GraphQL 有一套用于定义 API schema 的类型系统. 编写 schema 的语法我们称其为 schema 定义语言(Schema Definition Language ,简称 SDL)。
以下代码是我们使用 SDL 定义名为Person的简单类型的示例:
type Person {
name: String!
age: Int!
}
Person 类型有两个字段,它们分别叫做name和age,分别是String和Int类型,类型后面的 ! 该表示该字段是必需的。
也可以描述类型之间的关系,以博客应用为例,一个人(Person)可能与一篇文章(Post)相关联:
type Post {
title: String!
author: Person!
}
相应的,关系的另一端需要放在人员(Person)类型上:
type Person {
name: String!
age: Int!
posts: [Post!]!
}
请注意,我们刚刚创建了 Person 和 Post 之间的一对多关系,因为 Person 上的 posts 字段实际上是一个帖子(Post)数组。
使用查询(Query)获取数据
在使用 REST API 时,从特定的端点( endpoint )加载数据。每个端点都有明确定义的返回信息结构。 这意味着客户端的数据要求在其连接的 URL 中有效编码。
GraphQL 采用的方法完全不同。 GraphQL API 通常只暴露单个端点,而不是具有多个返回固定数据结构的端点。 这是有效的,因为返回的数据结构不固定。 相反,它是完全灵活的,让客户决定实际需要什么数据。这意味着客户端需要向服务器发送更多信息以表达其数据需求 - 此信息称为查询。
基本查询
我们看一下客户端可以发送到服务器的示例查询:
{
allPersons {
name
}
}
此查询中的allPersons字段称为查询的根字段。 根字段后面的所有内容称为查询的有效内容。 此查询的有效内容中指定的唯一字段是name。
此查询将返回当前存储在数据库中的所有人员的列表。 这是一个示例响应:
{
"data": {
"allPersons": [
{
"name": "Johnny"
},
{
"name": "Sarah"
},
{
"name": "Alice"
}
]
}
}
请注意,每个人在响应中只有name,但服务器不会返回age。 这正是因为name是查询中指定的唯一字段。
如果客户端还需要人员的age,则只需稍微调整查询并在查询的有效负载中包含新字段:
{
allPersons {
name
age
}
}
添加了age字段的查询将返回
{
"data": {
"allPersons": [
{
"name": "Johnny",
"age": 23
},
{
"name": "Sarah",
"age": 20
},
{
"name": "Alice",
"age": 20
}
]
}
}
嵌套查询
GraphQL 的一个主要优点是它允许查询嵌套。 例如,如果您想加载Person编写的所有posts,您只需按照类型的结构来请求此信息:
{
allPersons {
name
age
posts {
title
}
}
}
嵌套查询的返回
{
"data": {
"allPersons": [
{
"name": "Johnny",
"age": 23,
"posts": [
{
"title": "GraphQL is awesome"
},
{
"title": "Relay is a powerful GraphQL Client"
}
]
},
{
"name": "Sarah",
"age": 20,
"posts": [
{
"title": "How to get started with React & GraphQL"
}
]
},
{
"name": "Alice",
"age": 20,
"posts": []
}
]
}
}
带参数查询
在 GraphQL 中,如果在schema中指定了参数,则每个字段可以包含零个或多个参数。 例如,allPersons字段可以具有last参数,以仅返回特定数量的人。 这是相应的查询的样子:
{
allPersons(last: 2) {
name
}
}
返回结果
{
"data": {
"allPersons": [
{
"name": "Sarah"
},
{
"name": "Alice"
}
]
}
}
使用变更(Mutation)写数据
在从服务器请求信息之后,大多数应用程序还需要某种方式来更改当前存储在后端中的数据。 使用 GraphQL,这些更改是使用所谓的变更(Mutations,有时也叫突变)进行的。 通常有三种变更:
- 创建新数据
- 修改现有数据
- 删除现有数据
变更遵循与查询相同的语法结构,但它们始终需要以mutation关键字开头。以下是我们如何创建新Person的示例:
mutation {
createPerson(name: "Bob", age: 36) {
name
age
}
}
以上代码创建一个name为Bob,age为36的Person对象,并返回执行结果中的name和age字段,执行结果如下:
{
"data": {
"createPerson": {
"name": "Bob",
"age": 36
}
}
}
注意,与我们之前编写的查询类似,变异也有一个根字段 - 在这里为createPerson。 我们还已经了解了字段参数的概念。 在这里,createPerson字段采用两个参数来指定新人的name和age。
与查询一样,我们也可以为变更(mutation)指定有效负载(playload),我们可以在其中请求新Person对象的不同属性。 例子中,我们询问的是name和age - 尽管在我们的例子中这并不是非常有用,因为我们显然已经知道了它们,因为我们将它们传递给了变更。 但是,能够在发送变更时查询信息可以是一个非常强大的工具,允许您在单个往返中从服务器检索新信息!
以后会发现,GraphQL 类型中通常会由服务端创建新对象时生成唯一 ID,在之前的Person类型中添加id字段:
type Person {
id: ID!
name: String!
age: Int!
}
现在,当创建一个新Person时,您可以直接在变更的有效负载中询问id,因为这是事先在客户端上无法获得的信息:
mutation {
createPerson(name: "Alice", age: 36) {
id
name
age
}
}
{
"data": {
"createPerson": {
"id": "cjyz7ocx10mwp0171660kf1gm",
"name": "Alice",
"age": 36
}
}
}
订阅(Subscription)的实时更新
当今许多应用程序的另一个重要要求是与服务器建立实时连接,以便立即了解重要事件。 对于此用例,GraphQL 提供了订阅(subscriptions)的概念。
当客户端订阅某个事件时,它将启动并保持与服务器的稳定连接。 每当该特定事件实际发生时,服务器就将相应的数据推送到客户端。 与典型的“request-response-cycle”之后的查询和更改不同,订阅表示发送到客户端的数据流。
订阅使用与查询和突变相同的语法编写。 这是我们订阅Person类型上发生的事件的示例:
subscription {
newPerson {
name
age
}
}
客户端将此订阅(subscription)发送到服务器后,将在它们之间建立长连接。 然后,每当执行创建新 Person 的变更时,服务器都会将有关此人的信息发送给客户端:
{
"newPerson": {
"name": "Jane",
"age": 23
}
}
定义 Schema
至此,您已经基本了解了query,mutation和subscription,让我们将它们结合起来,并了解如何编写一个 schema,使您能够执行到目前为止看到的示例。
在使用 GraphQL API 时,schema 是最重要的概念之一。
Schema 指定 API 的功能并定义客户端如何请求数据,其通常被视为服务端和客户端之间的契约。
通常,schema 只是 GraphQL 类型的集合。 但是,在为 API 编写 schema 时,有一些特殊的根(root)类型:
type Query { ... }
type Mutation { ... }
type Subscription { ... }
Query,Mutation和Subscription类型是客户端发送的请求的入口点。 要使我们之前看到的allPersons查询可用,必须按如下方式编写Query类型:
type Query {
allPersons: [Person!]!
}
allPersons 被称为 API 的根(root)字段。 再次考虑我们在 allPersons 字段中添加最后一个参数的示例,我们必须按如下方式编写 Query:
type Query {
allPersons(last: Int): [Person!]!
}
同样,对于createPerson变更,我们必须在Mutation类型中添加一个根字段:
type Mutation {
createPerson(name: String!, age: Int!): Person!
}
请注意,此根字段也有两个参数,即新Person的name和age。
最后,对于Subscription,我们必须添加newPerson根字段:
type Subscription {
newPerson: Person!
}
总而言之,这是您在本章中看到的所有查询和变更的完整 schema:
type Query {
allPersons(last: Int): [Person!]!
}
type Mutation {
createPerson(name: String!, age: Int!): Person!
}
type Subscription {
newPerson: Person!
}
type Person {
name: String!
age: Int!
posts: [Post!]!
}
type Post {
title: String!
author: Person!
}
GraphQL 服务端如何执行查询
GraphQL 通常被描述为以前端为中心的 API 技术,因为它使客户能够以比以前更好的方式获取数据。 但是,API 本身当然是在服务器端实现的。 在服务端提供 GraphQL 服务还有许多好处,因为GraphQL 使服务器开发人员能够专注于描述可用数据,而不是实现和优化特定端点。
GraphQL不仅指定了描述Schema和从Schema中检索数据的方法,而且还指定了将查询转换为结果的实际执行算法。 该算法的核心非常简单:逐个遍历查询,为每个字段执行“解析器”,然后返回与请求的结构相对应的结果,该结果通常会是 JSON 的格式。
本节阐述如下内容:
- GraphQL查询
- Schema和解析器
- GraphQL查询执行步骤。
GraphQL查询
GraphQL查询结构非常简单,易于理解。如下:
{
subscribers(publication: "apollo-stack"){
name
email
}
}
上面API响应结果大致如下:
{
subscribers: [
{ name: "Jane Doe", email: "[email protected]" },
{ name: "John Doe", email: "[email protected]" },
...
]
}
响应的结构几乎与查询中的结构相同。 GraphQL的客户端非常简单,它实际上是非常明显的!
但服务端如何?是不是超级复杂?
事实上,GraphQL服务端也非常简单。继续往下看。
Schema与解析器(Resolve Functions)
每个GraphQL服务端都有两个核心部分:Schema和解析器(Resolve Functions)。
Schema是可以通过GraphQL服务端获取的数据模型。 它定义了允许客户端进行的查询,及可以从服务端获取的数据类型以及这些类型中的字段和之间的关系。
下图表示一个简单的GraphQL Schema,有三种类型:Author,Post和Query

使用GraphQL Schema表示,代码如下:
type Author {
id: Int
name: String
posts: [Post]
}
type Post {
id: Int
title: String
text: String
author: Author
}
type Query {
getAuthor(id: Int): Author
getPostsByTitle(titleContains: String): [Post]
}
schema {
query: Query
}
这个Schema非常简单:它声明应用程序有三种类型 - Author,Post和Query。
第三种类型——Query——就是标记Schema的入口。每个查询都必须从其中一个字段开始:getAuthor或getPostsByTitle。可以将它们看作有点像RESTful的断电(endpoints),不过更强大。
Author,Post互相引用:
- 可以通过
Author的posts字段获取Author发布的Post,即从作者获取作者发布的帖子; - 也可以通过
Post的author字段获取Post的Author,即从帖子获取帖子的作者。
Schema告诉服务端允许客户端进行哪些查询,以及不同类型的关联方式,但是它不包含一条关键信息:每种类型的数据来自何处!这是解析器的作用所在,请继续往下看。
解析器(Resolve Functions)
解析函数就像微型“路由器”。
解析器指定了Schema中的类型和字段如何连接到各种后端,回答了“如何获取作者的数据?”和“需要使用哪些后端调用以获取帖子的数据?”等问题。
GraphQL解析器可以包含任意代码,这意味着GraphQL服务端可以连接任何类型的后端,甚至与其它GraphQL服务端进行通信。 例如,Author类型可以存储在SQL数据库中,而Posts存储在MongoDB中,甚至可以由微服务处理。
也许GraphQL的最大特点是它隐藏了客户端的所有后端复杂性。 无论您的应用程序使用多少个后端,所有客户端都会看到一个GraphQL端点(endpoint),并为应用程序提供了一个简单的自带文档的API。
以下是两个解析函数的示例:
getAuthor(_, args){
return sql.raw('SELECT * FROM authors WHERE id = %s', args.id);
}
posts(author){
return request(`https://api.blog.io/by_author/${author.id}`);
}
当然,您不会直接在解析函数中编写查询或URL,而会将其放在单独的模块中,你懂的!!
GraphQL查询执行过程
Alright,既然已了解Schema和解析器(Resolve Functions),那么让我们看一下实际查询的执行。
附注:下面的代码是GraphQL-JS——GraphQL的JavaScript参考实现,但执行模式在所有GraphQL服务端中都是相同的。
本小节来说说GraphQL服务端如何使用Schema和解析器以执行查询并生成所需结果。
这是一个与前面介绍的Schema一起使用的查询。它获取作者的姓名,该作者的所有帖子以及每个帖子的作者姓名。
{
getAuthor(id: 5){
name
posts {
title
author {
name # this will be the same as the name above
}
}
}
}
您会注意到此查询两次获取同一作者的名称。在这里用来说明GraphQL,同时保持Schema尽可能简单。不要慌!!
以下是服务器响应查询所需的三个主要步骤:
- 解析(Parse)
- 验证(Validate)
- 执行(Execute)
第一步:解析查询(Parsing the query)
首先,服务器解析字符串并将其转换为AST - 一种抽象语法树(Abstract Syntax Tree)。如果存在任何语法错误,服务器将停止执行并将语法错误返回给客户端。
第二步:验证(Validate)
查询可以在语法上正确,但仍然没有意义,就像下面的英语句子在语法上是正确的,但没有任何意义:“The sand left through the idea”。
验证阶段确保在执行开始之前查询在给定Schema中是有效的。它会检查以下内容:
-
getAuthor是Query类型的一个字段? -
getAuthor接受名为id的参数吗? -
getAuthor返回的类型上的名称和帖子字段是什么? - 更多…
作为应用程序开发人员,您无需担心此部分,因为GraphQL服务器会自动执行验证操作。
与RESTful API形成对比,RESTful API中取决于开发人员来确保所有参数都有效。
第三步:执行(Execute)
如果验证通过,GraphQL服务端将执行查询。
每个GraphQL查询都树形的,从查询的根(root)开始执行。 首先,执行程序使用提供的参数调用顶级字段的解析器 - 在本例中为getAuthor。 它等待所有解析器返回一个值,然后以树形方式继续向下进行。 如果一个解析器返回promise,则执行程序将等待,直到该promise被解析。
执行从顶部开始。同时执行同一级别的解析器,如下图所示:

如果对如何构建GraphQL服务感兴趣可参见Apollo。

更多参见GraphQL explained-How GraphQL turns a query into a response。
架构
GraphQL 仅作为规范发布。 这意味着 GraphQL 实际上只不过是一个详细描述 GraphQL 服务器行为的长文档。
用例
在本节中,我们将向您介绍包含 GraphQL 服务器的 3 种不同架构:
- 连接数据库的 GraphQL 服务
- GraphQL 服务是许多第三方或遗留系统前面的一层,并通过单个 GraphQL API 集成它们
- 连接数据库和第三方或遗留系统的混合方法,可以通过相同的 GraphQL API 进行访问
所有这三种体系结构都代表了 GraphQL 的主要用例,并展示了可以使用它的上下文的灵活性。
连接数据库的 GraphQL 服务
这种架构将是绿地项目最常见的。 在设置中,您有一个实现 GraphQL 规范的单个(Web)服务器。 当查询到达 GraphQL 服务器时,服务器将读取查询的有效内容并从数据库中获取所需的信息。 这称为解析查询。 然后,它按照官方规范中的描述构造响应对象,并将其返回给客户端。
GraphQL 实际上与传输层无关。 它可以与任何可用的网络协议一起使用。 因此,有可能实现基于 TCP,WebSockets 等的 GraphQL 服务器。
GraphQL 也不关心数据库或用于存储数据的格式。 您可以使用 AWS Aurora 等 SQL 数据库或 MongoDB 等 NoSQL 数据库。

GraphQL 层集成现有系统
GraphQL 的另一个主要用例是将多个现有系统集成在一个统一的 GraphQL API 之后。 对于拥有传统基础架构和许多不同 API 的公司来说,这尤其具有吸引力,这些 API 已经发展多年,现在带来了很高的维护负担。 这些遗留系统的一个主要问题是,它们几乎不可能构建需要访问多个系统的创新产品。
在这种情况下,GraphQL 可用于统一这些现有系统,并隐藏其优秀的 GraphQL API 背后的复杂性。 这样,可以开发新的客户端应用程序,只需与 GraphQL 服务器通信即可获取所需的数据。 然后,GraphQL 服务器负责从现有系统中获取数据并以 GraphQL 响应格式对其进行打包。
就像之前的架构一样,GraphQL 服务器并不关心所使用的数据库类型,在这里它并不关心获取解析(resolve) 查询获取数据所需的数据源。
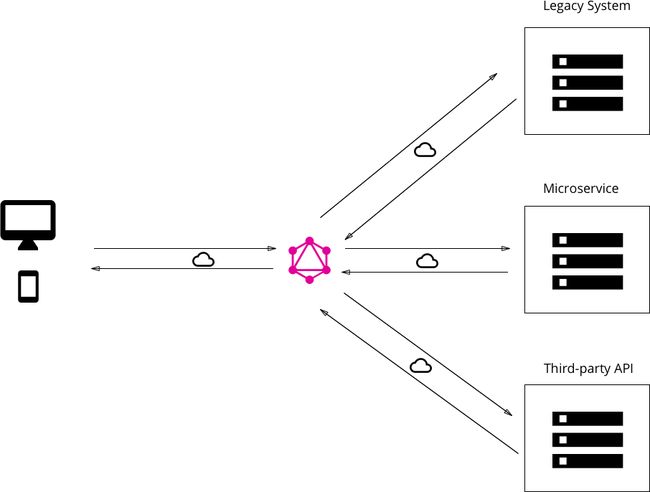
混合方式:连接数据库并与现有系统集成
最后,可以将这两种方法结合起来构建一个 GraphQL 服务器,该服务器具有连接的数据库,但仍然可以与传统或第三方系统进行通信。
当服务器收到查询时,它将解析(resolve)它并从连接的数据库或某些集成的 API 中检索所需的数据。

解析(Resolver)器
但是我们如何通过 GraphQL 获得这种灵活性? 它是如何非常适合这些非常不同的用例?
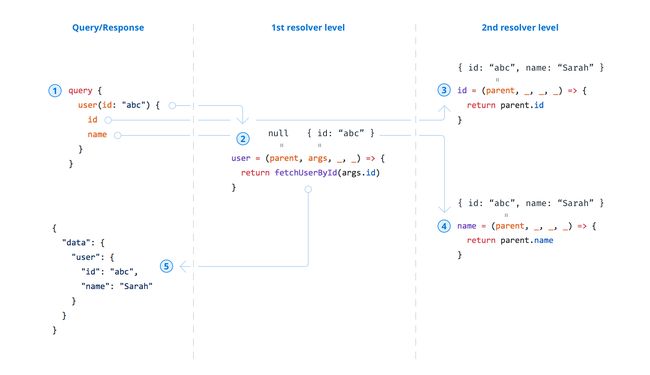
正如您在前面所了解到的,GraphQL 查询(query)或变更(mutation)的有效负载(payload)由一组字段组成。 在 GraphQL 服务器实现中,这些字段中的每一个实际上都对应于一个称为解析器的函数。 解析器功能的唯一目的是获取其字段的数据。
当服务器收到查询时,它将调用查询有效负载中指定的字段的所有函数。 因此,它解析了查询,并能够为每个字段检索正确的数据。 一旦所有解析器返回,服务器将以查询描述的格式打包数据并将其发送回客户端。

GraphQL 客户端库
GraphQL 对于前端开发人员来说特别棒,因为它完全消除了 REST API 遇到的许多不便和缺点,例如上面提到的过度获取和不足获取。 复杂性被推向服务器端,强大的机器可以处理繁重的计算工作。 客户端不必知道它所获取的数据实际来自何处,并且可以使用单个,连贯且灵活的 API。
考虑一下 GraphQL 引入的主要变化,从一个相当命令式的数据获取方法转变为纯粹的声明方式。 从 REST API 获取数据时,大多数应用程序必须执行以下步骤:
- 构造并发送 HTTP 请求(例如,使用 Javascript 中的 fetch)
- 接收和解析服务器响应
- 在本地存储数据(简单地在内存中或持久存储)
- 在 UI 中显示数据
使用理想的声明性数据获取方法,客户不应该超过以下两个步骤:
- 描述数据要求
- 在 UI 中显示数据
应该抽象出所有较低级别的网络任务以及数据存储,并且数据依赖性的声明应该是主要部分。
这正是像 Relay 或 Apollo Client 这样的 GraphQL 客户端库将使您能够做到的事情。 它们提供了所需的抽象,使您能够专注于应用程序的重要部分,而不必处理重复的基础结构实现。
查询和变更
字段(Fields)
{
hero {
name
# 这是备注
friends {
name
}
}
}
返回结果
{
"data": {
"hero": {
"name": "R2-D2",
"friends": [
{
"name": "Luke Skywalker"
},
{
"name": "Han Solo"
},
{
"name": "Leia Organa"
}
]
}
}
}
针对hero的查询包含两个字段:
-
name字段返回String类型, -
friends字段返回数组,其中包含的字段有:-
name字段返回String类型
-
GraphQL 查询能够遍历相关对象及其字段,使得客户端可以一次请求查询大量相关数据,而不像传统 REST 架构中那样需要多次往返查询。
参数(Arguments)
GraphQL 中每一个字段和嵌套对象都可以有的一组参数,从而使得 GraphQL 可以替代多次 API 请求。
{
human(id: "1000") {
name
height(unit: FOOT)
}
}
返回结果
{
"data": {
"human": {
"name": "Luke Skywalker",
"height": 5.6430448
}
}
}
::: warning
GraphQL 中,所有参数必须具名传递。
:::
别名(Aliases)
{
empireHero: hero(episode: EMPIRE) {
name
}
jediHero: hero(episode: JEDI) {
name
}
}
返回结果
{
"data": {
"empireHero": {
"name": "Luke Skywalker"
},
"jediHero": {
"name": "R2-D2"
}
}
}
如果两个hero字段会存在冲突,通过别名以避免.
片段(Fragments)
从这里开始,为了精简本文内容,不再列出返回结果。
::: tip
片段定义了一段可重复使用的查询代码,通常用在复杂的查询场景,如多级嵌套查询。
:::
{
leftComparison: hero(episode: EMPIRE) {
...comparisonFields
}
rightComparison: hero(episode: JEDI) {
...comparisonFields
}
}
fragment comparisonFields on Character {
name
appearsIn
friends {
name
}
}
上面查询在第 10-16 行定义了一个名称为comparisonFields的片段,且其类型为Character,在第 3 和第 6 行使用。
注意,片段不能引用其自身,因为这会导致结果无限循环。
片段中使用变量
片段可以访问查询(query)或变更(mutation)中声明的变量。
query HeroComparison($first: Int = 3) {
leftComparison: hero(episode: EMPIRE) {
...comparisonFields
}
rightComparison: hero(episode: JEDI) {
...comparisonFields
}
}
fragment comparisonFields on Character {
name
friendsConnection(first: $first) {
totalCount
edges {
node {
name
}
}
}
}
使用片段时,片段名称前面的...可以看作 ES6 中的展开运算符类似。
操作名称(Operation name)
query HeroNameAndFriends {
hero {
name
friends {
name
}
}
}
示例代码包含了操作类型(query)和操作名称(HeroNameAndFriends)。
这之前,我们使用了简写句法,省略了
query关键字和操作名称,实际使用其可以代码减少歧义。
-
操作类型
可以是
query、mutation、subscription,用以描述什么类型的操作,简写语法可省略query。 -
操作名称
一个有意义的名称,可以理解为 js 中的函数名称,方便调试和维护。
变量(Variables)
GraphQL 可以将查询或变更的参数分离出来,作为变量传递给查询或变更。
query HeroNameAndFriends($episode: Episode = "JEDI") {
hero(episode: $episode) {
name
friends {
name
}
}
}
可以简单的理解为 js 中的函数定义,不同类型的参数,调用时给参数提供不同的变量值。
变量格式为:$variableName : variableType = defaultValue,其中= defaultValue为默认值,可选。
- 变量名前缀必须为
$,后跟其类型,本例中为Episode - 所有声明的变量都必须是标量、枚举型或者输入对象类型
- 变量定义可以是可选的或者必要的,本例中,
Episode后并没有!,因此其是可选的 - 变量可以带默认值,本例中默认值为
"JEDI"。
指令(Directives)
假设我们需要使用变量,来动态改变查询结果的结构。
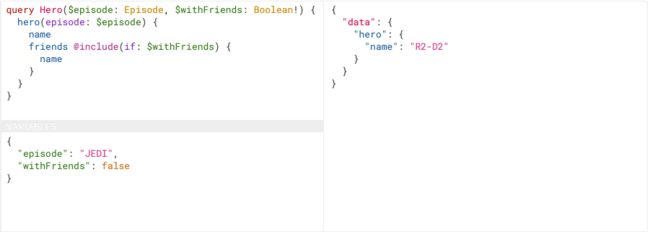
query Hero($episode: Episode, $withFriends: Boolean!) {
hero(episode: $episode) {
name
friends @include(if: $withFriends) {
name
}
}
}
1.当参数为"withFriends": false
{
"episode": "JEDI",
"withFriends": false
}
返回结果如下:
{
"data": {
"hero": {
"name": "R2-D2"
}
}
}
2.当参数为"withFriends": true
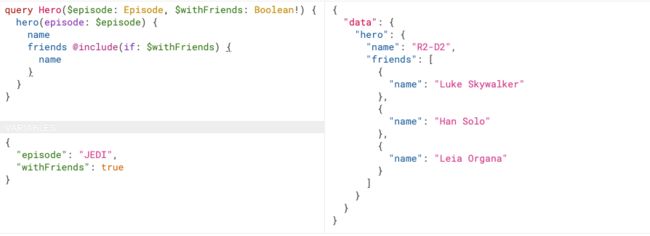
{
"episode": "JEDI",
"withFriends": true
}
返回结果如下:
{
"data": {
"hero": {
"name": "R2-D2",
"friends": [
{
"name": "Luke Skywalker"
},
{
"name": "Han Solo"
},
{
"name": "Leia Organa"
}
]
}
}
}
指令是附加在字段(或片段 fragments 中的字段),并以服务端期待的方式改变查询的执行。
GraphQL 的核心规范包含两个指令,其必须被任何规范兼容的 GraphQL 服务器实现所支持:
-
@include(if: Boolean)仅在参数为 true 时,包含此字段。 -
@skip(if: Boolean)如果参数为 true,跳过此字段。
需要动态改变查询结果结构时记得有指令来帮你搞定。
当然,服务端实现也可以定义新的指令来添加新的特性。
变更(Mutations)
RESTful 中不建议使用GET请求修改数据,建议使用PUT 、POSTHTTP 方法来修改数据。
GraphQL 中 约定采用变更(mutaion)来发送所有会导致数据修改的请求。
变更请求如下例,注意操作类型变成了mutation:
mutation CreateReviewForEpisode($ep: Episode!, $review: ReviewInput!) {
createReview(episode: $ep, review: $review) {
stars
commentary
}
}
参数如下:
{
"ep": "JEDI",
"review": {
"stars": 5,
"commentary": "This is a great movie!"
}
}
返回结果如下:
{
"data": {
"createReview": {
"stars": 5,
"commentary": "This is a great movie!"
}
}
}
注意,createReview操作返回了新建的Review类型的starts和commentary字段,返回结果与 mutation 中定义的结构依然相同;同查询(query)一样,也可以使用嵌套结构的结果。
参数中review并非标量,而是一个对象类型,GraphQL 中称其为输入对象类型(nput object type),详情见 Schema - 输入类型(Input Types)。
变更中的多个操作字段(Multiple fields in mutations)
一个变更中也能包含多个操作字段,和查询一样(参见别名)。
查询(query)是并行执行,而变更(mutation)是线性执行,即一个成功后再接着执行下一个。
在一个请求中发送两个incrementCredits变更,第一个会确保在第二个之前执行。
内联片段(Inline Fragments)
GraphQL schema 也具备定义接口和联合类型的能力(更多参见 Schema-接口(Interface))。
如果查询返回的字段是接口或者联合类型,那么需要使用内联片段来取出下层具体类型的数据。
假如存在如下 schema 定义:
interface Character {
id: ID!
name: String!
}
type Human implements Character {
id: ID!
name: String!
height: Float
}
type Droid implements Character {
id: ID!
name: String!
primaryFunction: String
}
查询如下:
query HeroForEpisode($ep: Episode!) {
hero(episode: $ep) {
name
... on Human {
height
}
... on Droid {
primaryFunction
}
}
}
这个查询中,hero 字段返回 Character 接口类型,取决于 episode 参数实际可能是 Human 或者 Droid 类型。在直接选择的情况下,你只能请求 Character接口中存在的字段,譬如 name。
如果要请求具体类型上的字段,你需要使用类型条件内联片段。因为第一个片段标注为 ... on Droid,primaryFunction字段仅在 hero 返回的 Character 为 Droid 类型时才会执行。 Human 类型的 height 字段也是这个道理。
具名片段也可以用于同样的情况,因为具名片段总是附带了一个类型。
1.当参数为"ep":"EMPIRE"时

{
"ep": "EMPIRE"
}
返回结果如下,包含 Human 类型的height字段:
{
"data": {
"hero": {
"name": "Luke Skywalker",
"height": 1.72
}
}
}
2.当参数为"ep":"JEDI"时

{
"ep": "JEDI"
}
返回结果如下,包含 Droid 类型的primaryFunction字段:
{
"data": {
"hero": {
"name": "R2-D2",
"primaryFunction": "Astromech"
}
}
}
元字段(Meta fields)
有时,我们并不知道从 GraphQL 服务端获取什么类型,这时需要一些方法在客户端处理数据。
GraphQL 允许你在查询的任何位置请求
__typename元字段,以获得其对象类型名称。
{
jediHero: hero(episode: JEDI) {
__typename
}
emprireHero: hero(episode: EMPIRE) {
__typename
}
}
返回
{
"data": {
"jediHero": {
"__typename": "Droid"
},
"emprireHero": {
"__typename": "Human"
}
}
}
如果没有__typename字段,没法获取返回具体的类型到底是什么。
GraphQL 服务提供了不少元字段,剩下的部分用于描述内省系统,更多参见内省(Introspection)。
Schema 和类型

类型系统(Type System)
每一个 GraphQL 服务都会定义一套类型即 schema,用以描述服务端提供什么样的数据。每当查询请求到来,服务端会根据 schema 验证并执行查询。
schema 是对服务端提供数据的准确描述。
类型语言(Type Language)
GraphQL 服务端可以用任何语言编写,其并不依赖于任何特定语言(譬如 JavaScript)来与 GraphQL schema 沟通。
GraphQL schema language —— 它和 GraphQL 的查询语言很相似。
对象类型和字段(Object Types and Fields)
GraphQL schema 中的最基本的组件是对象类型,它就表示你可以从服务端获取到什么类型的对象,以及对象包含哪些字段。
使用 GraphQL schema language,可以这样表示:
type Character {
name: String!
appearsIn: [Episode!]!
}
-
Character是一个 GraphQL 对象类型,表示其是一个拥有一些字段的类型。你的 schema 中的大多数类型都会是对象类型。
name和appearsIn是Character类型上的字段。这意味着在一个操作Character类型的 GraphQL 查询中的任何部分,都只能出现name和appearsIn字段。 -
String是内置的标量类型之一 —— 标量类型是解析到单个标量对象的类型,无法在查询中对它进行次级选择。后面我们将细述标量类型。 -
String!表示这个字段是非空的,GraphQL 服务保证当你查询这个字段后总会给你返回一个值。在类型语言里面,我们用一个感叹号来表示这个特性。 -
[Episode!]!表示一个Episode类型的对象数组。因为它也是非空的,所以当查询appearsIn字段的时候,总能得到一个数组(零个或者多个元素)。且由于Episode!也是非空的,你总是可以预期到数组中的每个项目都是一个Episode对象,而不会为NULL。
Schema 中的参数(Arguments)
GraphQL 对象类型上的每一个字段都可能有零个或者多个参数.
type Starship {
id: ID!
name: String!
length(unit: LengthUnit = METER): Float
}
GraphQL 中,所有参数必须具名传递。
参数可能是必选或者可选的,当一个参数是可选的,可以定义一个默认值。
查询和变更类型(The Query and Mutation Types)
schema 中大部分的类型都是普通对象类型,但是一个 schema 内有两个特殊类型Query和Mutation:
schema {
query: Query
mutation: Mutation
}
Query和Mutation类型定义了每一个 GraphQL 查询的入口。
每一个 GraphQL 服务都有一个 query 类型,可能(也可能没有)有一个 mutation 类型。
如果看到下面的查询:
query {
hero {
name
}
droid(id: "2000") {
name
}
}
则 GraphQL 服务端的 schema 必然有:
type Query {
hero(episode: Episode): Character
droid(id: ID!): Droid
}
标量类型(Scalar Types)
标量类型字段没有任何次级字段,是 GraphQL 查询的叶子节点。
GraphQL 自带一组默认标量类型:
- Int:有符号 32 位整数。
- Float:有符号双精度浮点值。
- String:UTF‐8 字符序列。
- Boolean:true 或者 false。
- ID:ID 标量类型表示一个唯一标识符,通常用以重新获取对象或者作为缓存中的键。ID 类型使用和 String 一样的方式序列化;然而将其定义为 ID 意味着并不需要人类可读型。
大部分的 GraphQL 服务实现中,都有自定义标量类型。例如,我们可以定义一个 Date 类型:
scalar Date
自定义标量就取决于服务端的实现时如何定义将其序列化、反序列化和验证。例如,你可以指定 Date 类型应该总是被序列化成整型时间戳,而客户端应该知道去要求任何 Date 字段都是这个格式。
枚举类型(Enumeration Types)
枚举类型是一种特殊的标量,它限制在一个特殊的可选值集合内。
定义一个Episode枚举
enum Episode {
NEWHOPE
EMPIRE
JEDI
}
列表和非空(Lists and Non-Null)
可以给类型附加类型修饰符。
type Character {
name: String!
appearsIn: [Episode]!
}
非空
类型名后面添加一个感叹号
!将其标注为非空。
有点像数据库表结构定义时字段不允许为空。即服务端对于这个字段,总是会返回一个非空值。
如果它结果得到了一个空值,那么事实上将会触发一个 GraphQL 执行错误,以让客户端知道发生了错误。
非空类型修饰符也可以用于参数,如果参数上传递了一个空值(不管通过 GraphQL 字符串还是变量),那么会导致服务器返回一个验证错误。
如:
query DroidById($id: ID!) {
droid(id: $id) {
name
}
}
参数为"id": null
{
"id": null
}
服务端返回验证错误
{
"errors": [
{
"message": "Variable \"$id\" of required type \"ID!\" was not provided.",
"locations": [
{
"line": 1,
"column": 17
}
]
}
]
}
列表
通过方括号
[和]将类型包裹起来以表示列表。
即服务端会返回列表类型,列表用于参数也类似。
非空和列表修饰符可以组合使用。例如你可以要求一个非空字符串的数组:
myField: [String!]
这表示数组本身可以为空,但是其不能有任何空值成员。用 JSON 举例如下:
myField: null // 错误
myField: [] // 有效
myField: ['a', 'b'] // 有效
myField: ['a', null, 'b'] // 有效
可以根据需求嵌套任意层非空和列表修饰符。
接口(Interfaces)
接口是一个抽象类型,它包含某些字段,而接口的实现必须包含这些字段。
例如,Character 接口用以表示《星球大战》三部曲中的任何角色:
interface Character {
id: ID!
name: String!
}
注意,上面代码中的interface,其表示定义一个接口。
一旦定义了接口,那么任何实现 Character 接口的类型都要必须具有这些字段,并有对应参数和返回类型。例如:
type Human implements Character {
id: ID!
name: String!
height: Float
}
type Droid implements Character {
id: ID!
name: String!
primaryFunction: String
}
如上代码所示,Human和Droid类型是对Character接口的实现,同时也具有自己的字段height和primaryFunction。
如查询和变更-内联片段中所示:
query HeroForEpisode($ep: Episode!) {
hero(episode: $ep) {
name
... on Human {
height
}
... on Droid {
primaryFunction
}
}
}
当返回一个对象或者一组对象,特别是一组不同的类型时,接口就显得特别有用。
可参见内联片段了解更多相关信息。
联合类型(Union Types)
联合类型和接口十分相似,但是它并不指定类型之间的任何共同字段。
union SearchResult = Human | Droid | Starship
上面的 schema 定义中,任何返回一个 SearchResult 类型的地方,都可能得到一个 Human、Droid 或者 Starship类型。注意,联合类型的成员需要是具体对象类型;你不能使用接口或者其他联合类型来创造一个联合类型。
如果你需要查询一个返回 SearchResult 联合类型的字段,则需要使用内联片段,如:
{
search(text: "an") {
__typename
... on Human {
name
height
}
... on Droid {
name
primaryFunction
}
... on Starship {
name
length
}
}
}
返回
{
"data": {
"search": [
{
"__typename": "Human",
"name": "Han Solo",
"height": 1.8
},
{
"__typename": "Human",
"name": "Leia Organa",
"height": 1.5
},
{
"__typename": "Starship",
"name": "TIE Advanced x1",
"length": 9.2
}
]
}
}
前面说过,_typename 元字段解析为 String类型,可以在客户端区分不同的数据类型。
由于 Human 和 Droid 共享一个公共接口(Character),我们可以在一个地方查询它们的公共字段,而不必在多个类型中重复相同的字段:
{
search(text: "an") {
__typename
... on Character {
name
}
... on Human {
height
}
... on Droid {
primaryFunction
}
... on Starship {
name
length
}
}
}
输入类型(Input Types)
目前为止,我们只讨论过将例如枚举和字符串等标量值作为参数传递给字段,但是你也能很容易地传递复杂对象。这在变更(mutation)中特别有用,因为有时候你需要传递一整个对象作为新建对象。在 GraphQL schema language 中,输入对象看上去和常规对象一模一样,除了关键字是 input 而不是 type:
input ReviewInput {
stars: Int!
commentary: String
}
可以像下面代码这样在变更(mutation)中使用输入对象类型:
mutation CreateReviewForEpisode($ep: Episode!, $review: ReviewInput!) {
createReview(episode: $ep, review: $review) {
stars
commentary
}
}
参数为
{
"ep": "JEDI",
"review": {
"stars": 5,
"commentary": "This is a great movie!"
}
}
输入对象类型上的字段本身也可以为输入对象类型(即输入对象类型可嵌套)。
不能在 schema 中混淆输入和输出类型。输入对象类型的字段不能拥有参数。
内省(Introspection)
GraphQL 通过内省机制告诉客户端,服务端都提供哪些查询、变更或订阅,以及服务端定义的类型和字段。
如果是自己设计了类型系统,那自己当然知道哪些类型是可用的。但如果类型不是自己设计的,可以通过查询 __schema 字段来向 GraphQL 服务端询问哪些类型是可用的。一个查询的根类型总是有 __schema 这个字段。如下代码所示:
{
__schema {
types {
name
}
}
}
返回结果如下:
{
"data": {
"__schema": {
"types": [
{
"name": "Query"
},
{
"name": "Episode"
},
{
"name": "Character"
},
{
"name": "ID"
},
{
"name": "String"
},
{
"name": "Int"
},
{
"name": "FriendsConnection"
},
{
"name": "FriendsEdge"
},
{
"name": "PageInfo"
},
{
"name": "Boolean"
},
{
"name": "Review"
},
{
"name": "SearchResult"
},
{
"name": "Human"
},
{
"name": "LengthUnit"
},
{
"name": "Float"
},
{
"name": "Starship"
},
{
"name": "Droid"
},
{
"name": "Mutation"
},
{
"name": "ReviewInput"
},
{
"name": "__Schema"
},
{
"name": "__Type"
},
{
"name": "__TypeKind"
},
{
"name": "__Field"
},
{
"name": "__InputValue"
},
{
"name": "__EnumValue"
},
{
"name": "__Directive"
},
{
"name": "__DirectiveLocation"
}
]
}
}
}
- 内建类型:
Query、Mutation、Subscription是 GraphQL Schema 内建的特殊类型,其中Query必须有。 - 自定义类型:
Character,Human,Episode,Droid等 - 这些是我们在类型系统中定义的类型。 - 标量类型:
String、Int、FLoat、Boolean、ID为标量类型. - 内省系统类型:
__Schema、__Type、__TypeKind、__Field、__InputValue、__EnumValue、__Directive、__DirectiveLocation这些以两个下划线__开头的类型属于 GraphQL Schema 内省系统。
GraphQL Schema 的内省系统可通过查询操作的根级类型上的元字段__schema和__type来进行。
可以通过内省系统接触到类型系统的文档,并做出文档浏览器,或是提供丰富的 IDE 体验。
更多关于内省的说明参见GraphQL 规范-内省。
参考 & 引用
- GraphQL 文档(官方英文)
- GraphQL 规范(2019-08-07官方预发行草案)
- How do I GraphQL?(离线pdf)
- How to GraphQL
- How to build a GraphQL Server with graphql-yoga
- How to GraphQL : The fullstack GraphQL tutorial
- GraphQL boilerplates: Starter kits for GraphQL projects with Node, TypeScript, React, Vue,…
- 360linker-GraphQL 入门介绍
- 使用 GraphQL 的 5 个理由
- awesome-graphql Awesome
- GraphQL explained-How GraphQL turns a query into a response(离线pdf)