本教程基于Python 3,参考 A Byte of Python v1.92(for Python 3.0) 以及廖雪峰python教程
1第一个python程序
1.1 python的三种执行方式
1.在Python交互式命令行下,可以直接输入代码,然后执行,并立刻得到结果。交互式环境会把每一行Python代码的结果自动打印出来。
看到>>>即是在Python交互式环境下
2.用python运行Python代码
文件必须以.py结尾。此外,文件名只能是英文字母、数字和下划线的组合。
例如写一个calc.py的文件,在命令行模式下执行:
$python calc.py
3.用./直接运行py文件
方法:
在.py文件的第一行加上一个特殊的注释 #!/usr/bin/env python3
源文件的头两个字符是#! ,称之为组织行。这行告诉你的Linux/Unix 系统当你执行
你的程序的时候,它应该运行哪个解释器。env 程序用于反过来寻找运行程序的Python 解释器
#!/usr/bin/env python3
print('hello, world')
然后,通过命令给hello.py以执行权限:
$ chmod a+x hello.py
最后,在终端执行
./hello.py //输出hello, world
1.2 python的两种注释方式
#单行注释
'''
三引号多行注视
'''
1.3 python输入与输出
输出
用print()在括号中加上字符串,就可以向屏幕上输出指定的文字。
print()会依次打印每个字符串,遇到逗号“,”会输出一个空格
>>>print('1024 * 768 = ', 1024*768) //1024 * 768 = 786432
>>>number = 555
>>>print(number) //555
>>>print(type(number)) //
输入
input(),可以让用户输入字符串,并存放到一个变量里。比如输入用户的名字:
输入的值就会存放到name变量里
>>> name = input()
Michael
input()返回的数据类型是str
读取文本文件时,返回的数据类型也是str。由于str不能直接和整数比较,必须先把str转换成整数。Python提供了int()函数来将str转换成整数
s = input('birth: ')
birth = int(s) //int()函数将str转换成整数
if birth < 2000:
print('00前')
else:
print('00后')
但当输入abc时,会得到错误信息,int()函数发现一个字符串并不是合法的数字时就会报错,程序就退出了。
Python也提供了str()函数来将其他类型转换成字符串
类似还有float()等方法
eight = 8
str_eight = str(eight)
print(type(str_eight)) //
1.4 python语法
1.Python 没有强制性语句终止字符,使用4个空格的缩进来组织代码块,(每一行都是一个语句,当语句以冒号:结尾时,缩进的语句视为代码块。同一层次的语句必须有相同的缩进。
缩进的坏处是“复制-粘贴”功能失效了,当重构代码时,粘贴过去的代码必须重新检查缩进是否正确。
# print absolute value of an integer:
a = 100
if a >= 0:
print(a)
else:
print(-a)
2.Python程序是大小写敏感
2 python基础
2.1 数
在Python 中数的类型有三种——整数、浮点数和复数。
• 2 是一个整数的例子。Python可以处理任意大小的整数,1,100,-8080,0,0xff00(十六进制),0xa5b4c3d2(十六进制)
• Python的浮点数也没有大小限制,但是超出一定范围就直接表示为inf
1.23,3.14,-9.01,对于很大或很小的浮点数,就必须用科学计数法表示,把10用e替代,1.23x109就是1.23e9,或者12.3e8,0.000012可以写成1.2e-5。
• (-5+4j) 和(2.3-4.6j) 是复数的例子。
2.2 字符串
字符串是字符的序列,是以单引号'或双引号"括起来的任意文本,比如'abc',"xyz"等等。
在Python 中没有单独的char 数据类型。记住单引号和双引号是一样的。
单引号
你可以用单引号指定字符串,如’Quote me on this’。所有的空白,即空格和制表符都照原样保留。
双引号
在双引号中的字符串与单引号中的字符串的使用完全相同,例如"What’s your name?" 。
请注意,''或""本身只是一种表示方式,不是字符串的一部分。如果'本身也是一个字符,那就可以用""括起来,比如"I'm OK"包含的字符是I,',m,空格,O,K这6个字符。 还可以采用利用转义符'I\'m OK'表示
三引号
利用三引号(''' ),用来输入多行文本,也就是说在三引号之间输入的内容将被原样保留,之中的单号和双引号不用转义,其中的不可见字符比如/n和/t都会被保留,这样的好处是你可以替换一些多行的文本。
'''This is a multi-line string. This is the first line.
This is the second line.
"What's your name?," I asked.
He said "Bond, James Bond."
'''
转义序列
转义字符\可以转义很多字符,比如\n表示换行,\t表示制表符,字符\本身也要转义,所以\\表示的字符就是\。
如果字符串内部有很多换行,用\n写在一行里不好阅读,为了简化,Python允许用'''...'''的格式表示多行内容
>>> print('''line1
... line2
... line3''')
line1
line2
line3
自然字符串
通过在字符串前面附加r 或R 来指定自然字符串,省去了使用大量转义序列 \ 的麻烦。例如后向引用符可以写成’\\1’或r’\1’。在正则表达式中推荐使用r。
字符串是不可变的
这意味着一个字符串一旦创建,就不能在改变它。
字符串运算
# 字符串加法
"Hello " + "world!" # => "Hello world!"
# 字符串加法,可以不使用 '+'
"Hello " "world!" # => "Hello world!"
#一个字符串可以被认为是一个字符列表
"This is a string"[0] # => 'T'
# 可以获得字符的长度(如果有空格,字符的长度将包含空格)
len("This is a string") # => 16
len("I'm OK") # => 6, I,',m,空格,O,K这6个字符
2.3 布尔值bool
只有True、False两种值
#bool值的运算
>>>True and False #False
>>>False or True # True
#对整数的bool运算
0 and 2 # 0
-5 or 0 #-5
0 == False #True
2 == True #False
1 == True #True
#bool值的not运算
not True #False
not False #True
>>> cat = True
>>> dog = False
>>> print(type(cat))
>>> print(9!=9)
False
>>> print('abc' == 'abc')
True
>>> print(['asp', 'php'] == ['asp', 'php'])
True
bool()函数
#除了以下两种情况,所有其他值是True(即使用bool()函数返回True)
bool(0)#=> False
bool(“”)#=> False
2.4 变量
变量是你的计算机中存储信息的一部分内存。与字面意义上的常量不同,你需要能够访问这些变量的方法,因此要给变量命名。
Python中,等号=是赋值语句,可以把任意数据类型赋值给变量,同一个变量可以反复赋值,而且可以是不同类型的变量,例如:
a = 123 # a是整数
print(a)
a = 'ABC' # a变为字符串
print(a)
这种变量本身类型不固定的语言称之为动态语言,与之对应的是静态语言。静态语言在定义变量时必须指定变量类型,如果赋值的时候类型不匹配,就会报错。例如Java
标识符命名规则
1.首字符为字母或下划线,所以以数字开头无效
2.除了首字符以外的其余字符可以是字母、下划线或注释。
3.标识符名称对大小写敏感。
#变量名的书写规则 (单词之间通过下横线连接)
days = 365
days_1 = 365
days_2 = 365
number_of_days = 365
理解变量在计算机内存中的表示
a = 'ABC'时,Python解释器干了两件事情:
1.在内存中创建了一个'ABC'的字符串;
2.在内存中创建了一个名为a的变量,并把它指向'ABC'。
也可以把一个变量a赋值给另一个变量b,这个操作实际上是把变量b指向变量a所指向的数据
a = 'ABC'
b = a
a = 'XYZ'
print(b) #ABC

2.5 对象
Python 是完全面向对象的,在某种意义上,任何东西都被作为对象,包括数字、字符串和函数。
我们不会说“某某东西”,我们会说“某个对象”。
2.6 常量的习惯性写法
Python中,通常用全部大写的变量名表示常量:
PI = 3.14159265359
但事实上PI仍然是一个变量,Python根本没有任何机制保证PI不会被改变,所以,用全部大写的变量名表示常量只是一个习惯上的用法,如果你一定要改变变量PI的值,也没人能拦住你。
3 操作符和表达式

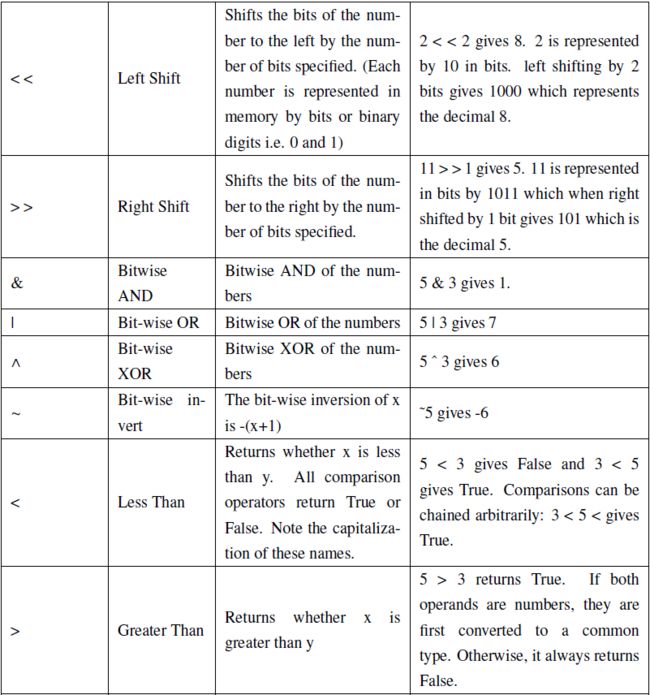


3.1 特别说明
两种除法运算
1.一种除法是/,计算结果是浮点数,即使是两个整数恰好整除,结果也是浮点数
>>> 10 / 3
3.3333333333333335
>>> 9 / 3
3.0
2.还有一种除法是//,称为地板除,计算结果是整数,即使除不尽。
>>> 10 // 3
3
因为//除法只取结果的整数部分,所以Python还提供一个余数运算,可以得到两个整数相除的余数:
>>> 10 % 3
1
指数运算
python中使用**表示指数运算
num = 10
print(num**2) //100
3.2 优先级
下面这个表给出Python 的运算符优先级,从最低的优先级到最高的优先级。这意味着在一个表达式中, Python 会首先计算表中较下面的运算符,然后在计算列在表上部的运算符,但建议使用圆括号来分组运算符和操作数。


3.3 字符串和编码
Python源代码也是一个文本文件,所以,当你的源代码中包含中文的时候,在保存源代码时需要务必指定保存为UTF-8编码(确保文本编辑器正在使用UTF-8 without BOM编码)。
当Python解释器读取源代码时,为了让它按UTF-8编码读取,我们通常在文件开头写上这两行:
#!/usr/bin/env python3 //告诉Linux/OS X系统,这是一个Python可执行程序
# -*- coding: utf-8 -*- //告诉Python解释器,按照UTF-8编码读取源代码,否则,你在源代码中写的中文输出可能会有乱码。
3.4 格式化
如何输出格式化的字符串。我们经常会输出类似'亲爱的xxx你好!你xx月的话费是xx,余额是xx'之类的字符串,而xxx的内容都是根据变量变化的。
Python中,%运算符就是用来格式化字符串的。在字符串内部,%s表示用字符串替换,%d表示用整数替换,有几个%?占位符,后面就跟几个变量或者值,顺序要对应好。如果只有一个%?,括号可以省略。
常见的占位符有:
%d 整数
%f 浮点数
%s 字符串
%x 十六进制整数
>>> 'Hello, %s' % 'world' //'Hello, world'
>>> 'Hi, %s, you have $%d.' % ('Michael', 1000000) //'Hi, Michael, you have $1000000.'
>>> '%2d-%02d' % (3, 1) //' 3-01' 指定是否补0和整数与小数的位数:
>>> '%.2f' % 3.1415926 //'3.14'指定是否补0和整数与小数的位数:
>>> 'growth rate: %d %%' % 7 // 'growth rate: 7 %' 若字符串里面的%是一个普通字符,就需要转义,用%%来表示一个%:
新的格式化方法:format方法(首选)
format 方法利用参变量的值代替格式符
age = 25
name = 'Swaroop'
print('{0} is {1} years old'.format(name, age))
print('Why is {0} playing with that python?'.format(name))
输出:
Swaroop is 25 years old
Why is Swaroop playing with that python?
运行原理:
一个字符串能使用确定的格式,随后,可以调用format 方法来代替这些格式,参数要与format 方法的参数保持一致。
观察首次使用0 的地方,这与format 方法的第一个参变量name 相一致。类似地,第二个格式1 与format 方法的第二个参变量age 相一致。
"{} is a {}".format("This", "placeholder")
"{0} can be {1}".format("strings", "formatted")
# 可以使用keywords如果不想数数字
"{name} wants to eat {food}".format(name="Bob", food="lasagna")
3.5 None(None是一个对象)
#不能使用相等的“==”符号将对象与None进行比较,而要使用is
"etc" is None # => False
None is None # => True
4 控制流
在到目前为止我们所见到的程序中,总是有一系列的语句,Python 忠实地按照它们的顺序执行它们。如果想要改变语句流的执行顺序,需要通过控制流语句实现。在Python 中有三种控制流语句——if、for 和while 。
4.1 if 语句
if 语句用来检验一个条件,如果条件为真,我们运行一块语句(称为if-块),否则我们处理另外一块语句(称为else-块)。else 子句是可选的。
if语句的完整形式
if <条件判断1>: //注意每一个语句之后的冒号:
<执行1>
elif <条件判断2>:
<执行2>
elif <条件判断3>:
<执行3>
else:
<执行4>
给C/C++ 程序员的注释:
在Python 中没有switch 语句。你可以使用if..elif..else 语句来完成同样的工作(在某些场合,使用字典会更加快捷。)
也可以使用
if <条件判断1>:
<执行1>
或者
if <条件判断1>:
<执行1>
else:
<执行4>
if可以用作表达式,相当于C的'?:'三元运算符
"yahoo!" if 3 > 2 else 2 # => "yahoo!"
"yahoo!" if 3 < 2 else 2 # => 2
if语句例子
age = 3
if age >= 18:
print('your age is', age)
print('adult')
else:
print('your age is', age)
print('teenager')
输出:
your age is 3
teenager
if语句的执行特点
if语句是从上往下判断,如果在某个判断上是True,把该判断对应的语句执行后,就忽略掉剩下的elif和else
age = 20
if age >= 6:
print('teenager') //此处判断为true,就忽略掉剩下的elif和else
elif age >= 18:
print('adult')
else:
print('kid')
if判断条件的简写
if x:
print('True')
练习
小明身高1.75,体重80.5kg。请根据BMI公式(体重除以身高的平方)帮小明计算他的BMI指数,并根据BMI指数:
低于18.5:过轻
18.5-25:正常
25-28:过重
28-32:肥胖
高于32:严重肥胖
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
weight = input('weight: ')
height = input('height: ')
weight = float(weight)
height = float(height)
BMI = weight/(height*height)
if BMI < 18.5:
print('过轻')
elif 18.5< BMI < 25:
print('正常')
elif 25< BMI < 28:
print('肥胖')
else:
print('严重肥胖')
4.2 while循环
只要在一个条件为真的情况下, 就不断循环,条件不满足时退出循环。while 语句有一个可选的else 从句。
while <条件判断1>:
<执行1>
else:
<执行2>
计算100以内所有奇数之和
sum = 0
n = 99
while n > 0:
sum = sum + n
n = n - 2
print(sum) //2500
给C/C++ 程序员的注释:
记得while 循环可以有else 语句。
4.3 for...in 循环
for..in 是另外一个循环语句,它在一序列的对象上迭代,即逐一使用序列中的每个项目。可以用于依次把list或tuple中的每个元素迭代出来。
for x in ...循环就是把每个元素代入变量x,然后执行缩进块的语句。else 部分是可选的。如果包含else ,它总是在for 循环结束后执行一次,除非遇到break 语句。
names = ['Michael', 'Bob', 'Tracy']
for name in names: //for 自定义元素别名 in 要遍历的list
print(name) //循环体中的内容,需要四个空格的缩进
输出:依次打印list names中的每一个元素
Michael
Bob
Tracy
计算1-10的整数之和
sum = 0
for x in [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]:
sum = sum + x
print(sum) //无缩进,表示不在循环体中。输出55
通过range()函数生成整数序列
for x in range(1,5):
print(x)
else:
print ( 'The for loop is over' )
输出:
1
2
3
4
The for loop is over
range(1,5) 给出序列[1, 2, 3, 4]。range 的步长默认为1。如果我们为range 提供第三个数,那么它将成为步长。例如,range(1,5,2) 给出[1,3]
>>> list(range(5)) //range(5)生成的序列是从0开始小于5的整数,通过list()函数可以转换为list
[0, 1, 2, 3, 4]
for i in range(10):
print(i) //依次打印0,1,2,3,4,5,6,7,8,9
计算1-100的整数之和
sum=0;
for x in range(101): //range(101)可以生成0-100的整数序列
sum +=x
print(sum) //5050
遍历list中的所有元素
s = [['asp', 'php'],['pp','java']]
for aa in s:
for bb in aa:
print(bb)
输出:
asp
php
pp
java
练习
请利用循环依次对list中的每个名字打印出Hello, xxx!:
L = ['Bart', 'Lisa', 'Adam']
for name in L:
print('hello,'+name+'!')
输出:
hello,Bart!
hello,Lisa!
hello,Adam!
给C/C++程序员的注释:
Python 的for 循环从根本上不同于C/C++ 的for 循环。
在C/C++ 中,如果你想要写for (int i = 0; i < 5; i++),那么用Python ,你写成for i in range(0,5)。你会注意到, Python 的for 循环更加简单、明白、不易出错。
4.4 break语句
break可用于for 或while 循环中,用于提前终止循环语句。如果你从for 或while 循环中终止,任何对应的循环else块将不执行。
n = 1
while n <= 100:
if n > 10: # 当n = 11时,条件满足,执行break语句
break # break语句会结束当前循环
print(n)
n = n + 1
print('END') //打印出1~10后,紧接着打印END
4.5 continue
continue语句,跳过当前的这次循环,直接开始下一次循环。
n = 0
while n < 10:
n = n + 1
if n % 2 == 0: # 如果n是偶数,执行continue语句
continue # continue语句会直接继续下一轮循环,后续的print()语句不会执行
print(n)
5 数据结构
在Python 中有四种内建的数据结构—— 列表、元组、字典和集合
5.1 list列表
Python内置的一种数据类型是列表:list。list是一种有序的集合,可以随时添加和删除其中的元素。
声明list类型
classmates = []
print(type(classmates)) //
创建list
>>> classmates = ['Michael', 'Bob', 'Tracy'] //创建一个list:
>>> classmates
['Michael', 'Bob', 'Tracy']
通过索引或切片获取list中的值
>>> len(classmates) //输出3 用len()函数可以获得list中元素的个数:
>>> classmates[0] //输出'Michael' 用索引(从0开始)来访问list中每一个位置的元素
//当索引超出了范围时,Python会报一个IndexError错误,所以,要确保索引不要越界,记得最后一个元素的索引是len(classmates) - 1。
>>> classmates[-1] //可以用-1做索引,直接获取最后一个元素
>>> classmates[-2] //以此类推,可以获取倒数第2个
使用切片,取头不取尾(所有对list的操作都会创建一个list的copy,对它进行操作)
>>> month = [1,2,3,4,5,6,7,8,9,10,11,12]
>>> month[2:5]
[3, 4, 5]
>>> month[2:] //取到结尾
[3, 4, 5, 6, 7, 8, 9, 10, 11, 12]
获取索引为2倍数的元素
li = [1,2,3,4,5,6,7,8,9]
li[::2] #[1, 3, 5, 7, 9]
颠倒list
li[::-1] #[9, 8, 7, 6, 5, 4, 3, 2, 1]
获取list的长度(list中元素的个数)
len(li) #9
插入&删除&替换list中的元素
>>> classmates.append('Adam') //使用append往list中追加元素到末尾
>>> classmates
['Michael', 'Bob', 'Tracy', 'Adam']
>>> classmates.insert(1, 'Jack') //用insert把元素插入到指定的位置
>>> classmates
['Michael', 'Jack', 'Bob', 'Tracy', 'Adam']
>>> classmates.pop() //用pop()方法 删除list末尾的元素
'Adam'
>>> classmates
['Michael', 'Jack', 'Bob', 'Tracy']
>>> classmates.pop(1) //用pop(i)删除指定位置的元素
'Jack'
>>> classmates
['Michael', 'Bob', 'Tracy']
>>>del classmates[0] //使用“del”删除列表中的任意元素
>>> classmates[1] = 'Sarah' //直接赋值给对应的索引位置 替换元素
>>> classmates
['Michael', 'Sarah', 'Tracy']
for循环遍历list元素&list元素排序
>>> shoplist = ['apple', 'mango', 'carrot', 'banana']
>>> for item in shoplist:
print(item,end =' ')
输出结果:
apple mango carrot banana #print函数的end关键参数来表示以空格结束输出,而不是通常的换行
>>> shoplist
['apple', 'mango', 'carrot', 'banana']
>>> shoplist.sort()
>>> shoplist
['apple', 'banana', 'carrot', 'mango']
#用sort 方法将列表进行排序。理解这一方法影响了列表本身,没有返回修改后的列表是重要的—— 这与字符串起作用的方式不同。
这就是我们所说的列表是易变的,字符串是不可变的。
list里面的元素的数据类型也可以不同
L = ['Apple', 123, True]
list中的元素也可以是另一个list,比如:
>>> s = ['python', 'java', ['asp', 'php'], 'scheme']
>>> len(s) //注意s只有4个元素,其中s[2]又是一个list
4
>>> s[2]
['asp', 'php']
>>> s[2][1] //要拿到'php'可以写s[2][1],s可以看成是一个二维数组
'php'
空的list的长度为0:
>>> L = []
>>> len(L)
0
5.2 tuple元组
另一种有序列表叫元组:tuple。tuple和list非常类似,只不过元组tuple和字符串一样是不可变的,一旦初始化就不能修改。
创建元组tuple
>>> classmates = ('Michael', 'Bob', 'Tracy') //对比创建list classmates = ['Michael', 'Bob', 'Tracy']
classmates这个tuple不能变了,它也没有append(),insert()这样的方法。其他获取元素的方法和list是一样的,你可以正常地使用classmates[0],classmates[-1],但不能赋值成另外的元素。
例子:
>>> zoo = ('python', 'elephant', 'penguin')
>>> len(zoo)
3
>>> new_zoo = ('monkey', 'camel', zoo)
>>> len(new_zoo)
3
>>> new_zoo
('monkey', 'camel', ('python', 'elephant', 'penguin'))
>>> new_zoo[2]
('python', 'elephant', 'penguin')
>>> new_zoo[2][2]
'penguin'
不可变的tuple有什么意义?
因为tuple不可变,所以代码更安全。如果可能,能用tuple代替list就尽量用tuple。
tuple的陷阱:含有1 个项目的元组
当你定义一个tuple时,在定义的时候,tuple的元素就必须被确定下来
>>> t = (1, 2)
>>> t = () //定义一个空的tuple
>>> t = (1,) //只有1个元素的tuple定义时必须加一个逗号,来消除歧义
>>> t = (1) //否则这样定义的不是tuple,是1这个数,因为括号()既可以表示tuple,又可以表示数学公式中的小括号,Python规定,这种情况按小括号进行计算
一个“可变的”tuple
>>> t = ('a', 'b', ['A', 'B'])
>>> t[2][0] = 'X'
>>> t
('a', 'b', ['X', 'B'])
tuple所谓的“不变”是说,tuple的每个元素,指向永远不变。即指向'a',就不能改成指向'b',指向一个list,就不能改成指向其他对象,但指向的这个list本身是可变的
所以,如果要创建一个内容也不变的tuple,就必须保证tuple的每一个元素本身也不能变。
5.3 dict
使用if实现的字典
animals = ['cat','dog','rabbit']
if 'cat' in animals:
print('cat found') #cat found
另一种字典方式
animals = ['cat','dog','rabbit']
cat_found = 'cat' in animals
print(cat_found) #True
Python内置了字典:dict的支持,dict全称dictionary,在其他语言中也称为map,使用键-值(key-value)存储,具有极快的查找速度。注意,键必须是唯一的,就像如果有两个人恰巧同名的话,你无法找到正确的信息。
所以只能使用不可变的对象(比如字符串)来作为字典的键,但可以把不可变或可变的对象作为字典的值。
键/值对用冒号分割,而各个对用逗号分割,所有这些都包括在花括号中。
记住字典中的键/值对是没有顺序的。如果你想要一个特定的顺序,那么你应该在使用前自己对它们排序。
通过dict实现一个“名字”-“成绩”的对照表
>>> d = {'Michael': 95, 'Bob': 75, 'Tracy': 85} //在初始化时就指定数据
>>> d['Michael']
95
>>> print(type(d))
>>> d['Adam'] = 67 //使用索引操作符来寻址一个键并为它赋值,这样就增加了一个新的键/值对
>>> d['Adam']
67
>>> d['Jack'] = 90 //一个key只能对应一个value,多次对一个key放入value,后面的值会把前面的值冲掉
>>> d['Jack']
90
>>> d['Jack'] = 88
>>> d['Jack']
88
>>> d = {'Michael': 95, 'Bob': 75, 'Tracy': 85, 'Adam': 67, 'Jack': 88}
>>> del d['Michael'] #使用del删除一个键值对
>>> d
{'Bob': 75, 'Tracy': 85, 'Adam': 67, 'Jack': 88}
使用字典的items 方法,来使用字典中的每个键/值对。
这会返回一个元组的列表,其中每个元组都包含一对项目—— 键与对应的值。我们抓取这个对,然后分别赋给for..in 循环中的变量name 和score 然后在for 块中打印这些值。
>>> d = {'Michael': 95, 'Bob': 75, 'Tracy': 85, 'Adam': 67, 'Jack': 88}
>>> for name, score in d.items():
print('{0}\'s score is {1}'.format(name, score))
输出结果:
Michael's score is 95
Bob's score is 75
Tracy's score is 85
Adam's score is 67
Jack's score is 88
检验一个键/值对是否存在的两种方法
方法一:使用in 操作符判断key是否存在
>>> 'Michael' in s
True
>>> 'lucy' in s
False
方法二:通过dict提供的get方法,如果key不存在,可以返回None,或者自己指定的value
>>> s.get('Michael' , 1) #key存在,返回对应的value
95
>>> s.get('Michaels') //返回None的时候Python的交互式命令行不显示结果。
>>> s.get('Michaels' , 1) #key不存在,返回自己指定的value
1
用pop(key)方法删除一个key
>>> s.pop('Bob') //对应的value也会从dict中删除:
75
>>> s
{'Michael': 95, 'Tracy': 85}
注意,dict内部存放的顺序和key放入的顺序是没有关系的。
重要:使用字典来统计list中相同元素出现的个数
li = ['apple','banana','orange','grape','orange','grape','orange','grape']
li_count = {}
for fruit in li:
if fruit in li_count:
li_count[fruit] = li_count[fruit] + 1
else:
li_count[fruit] = 1
print (li_count)
#{'apple': 1, 'banana': 1, 'orange': 3, 'grape': 3}
和list比较,dict有以下几个特点:
1.查找和插入的速度极快,不会随着key的增加而变慢;
2.需要占用大量的内存,内存浪费多。
而list相比dict:
1.查找和插入的时间随着元素的增加而增加;
2.占用空间小,浪费内存很少。
所以,dict是用空间来换取时间的一种方法。
dict的key必须是不可变对象
因为dict根据key来计算value的存储位置(哈希算法),如果每次计算相同的key得出的结果不同,那dict内部就完全混乱了。
要保证hash的正确性,作为key的对象就不能变。在Python中,字符串、整数等都是不可变的,因此,可以放心地作为key。而list是可变的,就不能作为key
>>> key = [1, 2, 3]
>>> d[key] = 'a list'
Traceback (most recent call last):
File "", line 1, in
TypeError: unhashable type: 'list'
5.4 序列
列表、元组和字符串都是序列,序列的主要特点是可以通过索引操作符让我们可以直接从序列中抓取一个特定项目。
既然是序列,就具有切片操作,即取出序列的薄片,例如序列的一部分。
shoplist = ['apple', 'mango', 'carrot', 'banana']
name = 'swaroop'
#使用索引取出元素
print('Item 0 is', shoplist[0]) #Item 0 is apple
print('Item -1 is', shoplist[-1]) #Item -1 is banana
print('Item -2 is', shoplist[-2]) #Item -2 is carrot
print('Character 0 is', name[0]) #Character 0 is s
#对list切片
print('Item 1 to 3 is', shoplist[1:3]) #Item 1 to 3 is ['mango', 'carrot']
print('Item 2 to end is', shoplist[2:]) #Item 2 to end is ['carrot', 'banana']
print('Item 1 to -1 is', shoplist[1:-1]) #Item 1 to -1 is ['mango', 'carrot']
print('Item start to end is', shoplist[:]) #Item start to end is ['apple', 'mango', 'carrot', 'banana']
#对string切片
print('characters 1 to 3 is', name[1:3]) #characters 1 to 3 is wa
#给切片规定第三个参数,就是切片的步长(默认步长是1)
>>> shoplist = ['apple', 'mango', 'carrot', 'banana']
>>> shoplist[::2]
['apple', 'carrot']
5.5 集合set
集合是没有顺序的简单对象的聚集。当在聚集中一个对象的存在比其顺序或者出现的次数重要时使用集合。
使用集合,可以检查是否是成员,是否是另一个集合的子集,得到两个集合的交集等等。
set和dict类似,也是一组key的集合,但不存储value。由于key不能重复,所以,在set中,没有重复的key。
要创建一个set,需要提供一个list作为输入集合:
>>> s = set([1, 2, 3])
>>> s
{1, 2, 3} //显示的顺序也不表示set是有序的,set是无序和无重复元素的集合
>>> s = set([1, 1, 2, 2, 3, 3]) //list中可以有重复元素,但重复元素在set中自动被过滤
>>> s
{1, 2, 3}
>>> s.add(4) //通过add(key)方法可以添加元素到set中
>>> s
{1, 2, 3, 4}
>>> s.add(4) //可以重复添加,但不会有效果:
>>> s
{1, 2, 3, 4}
>>> dd = s.copy() #copy方法复制集合
>>> dd
{1, 2, 3, 4}
>>> dd.issuperset(s) #检查一个集合是否是另一个集合的子集
True
>>> s.remove(4) //通过remove(key)方法可以删除元素
>>> s
{1, 2, 3}
两个set可以做数学意义上的交集、并集等操作:
>>> s1 = set([1, 2, 3])
>>> s2 = set([2, 3, 4])
>>> s1 & s2
{2, 3}
>>> s1 | s2
{1, 2, 3, 4}
set和dict的区别
set和dict的唯一区别仅在于没有存储对应的value,但是,set的原理和dict一样,所以,同样不可以放入可变对象,因为无法判断两个可变对象是否相等,也就无法保证set内部“不会有重复元素”。
5.6再议不可变对象
例如str是不变对象,而list是可变对象。
对于不变对象来说,调用对象自身的任意方法,也不会改变该对象自身的内容。相反,这些方法会创建新的对象并返回,这样,就保证了不可变对象本身永远是不可变的。
对于可变对象,比如list,对list进行操作,list内部的内容是会变化的,比如:
>>> a = ['c', 'b', 'a']
>>> a.sort()
>>> a
['a', 'b', 'c']
而对于不可变对象,比如str,对str进行操作:
>>> a = 'abc'
>>> a.replace('a', 'A')
'Abc'
>>> a
'abc'
虽然字符串有个replace()方法,也确实变出了'Abc',但变量a最后仍是'abc',应该怎么理解呢?
我们先把代码改成下面这样:
>>> a = 'abc' //注意a是变量,而'abc'才是字符串对象!
>>> b = a.replace('a', 'A') //replace方法创建了一个新字符串'Abc'并返回
>>> b //用变量b指向该新字符串变量,变量b仅仅引用那个对象,而不是表示这个对象本身
'Abc'
>>> a //变量a仍指向原有的字符串'abc'
'abc'
5.7 关于字符串的更多内容
字符串也是对象,同样具有方法。这些方法可以完成包括检验一部分字符串和去除空格在内的各种工作。
你在程序中使用的字符串都是str 类的对象。
如果要了解这些方法的完整列表,请参见help(str)。
>>> name = 'Swaroop'
>>> name.startswith('Swa') #tartwith 方法是用来测试字符串是否以给定字符串开始
True
>>> 'a' in name #in 操作符用来检验一个给定字符串是否为另一个字符串的一部分
True
>>> name.find('war') != -1 #find 方法用来找出给定字符串在另一个字符串中的位置,或者返回-1 以表示找不到子字符串
True
>>> name.find('oop')
4
>>> '-'.join(['tan','yu']) #join方法连接字符串
'tan-yu'
6 函数
函数是重用的程序段。它们允许你给一个语句块一个名称,然后你用这个名字可以在你的程序的任何地方,任意多次地运行这个语句块。这被称为调用函数。
6.1 内建函数
Python内置了很多有用的函数,我们可以直接调用。要调用一个函数,需要知道函数的名称和参数。查看所有内置函数

>>> abs(100) //abs函数获取一个参数的返回值
100
>>> abs(-20)
20
>>> abs(12.34)
12.34
>>> max(2, 3, 1, -5) //max()函数可以接收任意多个参数,返回最大的那个
3
数据类型转换
>>> int('123') //int()函数可以把其他数据类型转换为整数
123
>>> int(12.34)
12
>>> float('12.34')
12.34
>>> str(1.23)
'1.23'
>>> str(100)
'100'
>>> bool(1)
True
>>> bool('')
False
函数名其实就是指向一个函数对象的引用,完全可以把函数名赋给一个变量,相当于给这个函数起了一个“别名”:
>>> a = abs # 变量a指向abs函数
>>> a(-1) # 所以也可以通过a调用abs函数
1
6.2 定义函数
在Python中,定义一个函数要使用def语句,依次写出函数名、括号、括号中的参数和冒号:,然后,在缩进块中编写函数体,函数的返回值用return语句返回。
求绝对值函数my_abs
def my_abs(x):
if x >= 0:
return x
else:
return -x
在Python交互环境中定义函数时,注意Python会出现...的提示。函数定义结束后需要按两次回车重新回到>>>提示符下
6.3 函数的参数
函数中的参数名称为形参,而你提供给函数调用的值称为实参。
Python的函数定义非常简单,但灵活度却非常大。除了正常定义的必选参数外,还可以使用默认参数、可变参数和关键字参数,使得函数定义出来的接口,不但能处理复杂的参数,还可以简化调用者的代码。
位置参数
def power(x, n):
s = 1
while n > 0:
n = n - 1
s = s * x
return s
power(x, n)函数有两个参数:x和n,这两个参数都是位置参数,调用函数时,传入的两个值按照位置顺序依次赋给参数x和n。
默认参数
对于上述代码,由于我们经常计算x2,所以完全可以把第二个参数n的默认值设定为2
def power(x, n=2):
s = 1
while n > 0:
n = n - 1
s = s * x
return s
调用power(5)时,相当于调用power(5, 2):
>>> power(5)
25
>>> power(5, 2)
25
而对于n > 2的其他情况,就必须明确地传入n,比如power(5, 3)。
默认参数的好处
最大的好处是能降低调用函数的难度。而一旦需要更复杂的调用时,又可以传递更多的参数来实现。无论是简单调用还是复杂调用,函数只需要定义一个。
把年龄和城市设为默认参数:
def enroll(name, gender, age=6, city='Beijing'):
print('name:', name)
print('gender:', gender)
print('age:', age)
print('city:', city)
这样,大多数学生注册时不需要提供年龄和城市,只提供必须的两个参数:
>>> enroll('Sarah', 'F')
name: Sarah
gender: F
age: 6
city: Beijing
只有与默认参数不符的学生才需要提供额外的信息:
enroll('Bob', 'M', 7)
enroll('Adam', 'M', city='Tianjin')
注意:默认参数必须指向不变对象!
可变参数
可变参数就是传入的参数个数是可变的,可以是1个、2个到任意个,还可以是0个。
给定一组数字a,b,c……,计算a2 + b2 + c2 + …
由于参数个数不确定,我们首先想到可以把a,b,c……作为一个list或tuple传进来
def calc(numbers):
sum = 0
for n in numbers:
sum = sum + n * n
return sum
但是调用的时候,需要先组装出一个list或tuple:
>>> calc([1, 2, 3])
14
>>> calc((1, 3, 5, 7))
84
如果利用可变参数,把函数的参数改为可变参数:
def calc(*numbers): //在函数内部,参数numbers接收到的是一个tuple
sum = 0
for n in numbers:
sum = sum + n * n
return sum
利用可变参数,调用函数的方式也可以简化:
>>> calc(1, 2, 3)
14
>>> calc(1, 3, 5, 7)
84
如果已经有一个list或者tuple,要调用一个可变参数怎么办?
Python允许你在list或tuple前面加一个*号,把list或tuple的元素变成可变参数传进去:
>>> nums = [1, 2, 3]
>>> calc(*nums) //*nums表示把nums这个list的所有元素作为可变参数传进去
14
关键字参数
可变参数允许你传入0个或任意个参数,这些可变参数在函数调用时自动组装为一个tuple。而关键字参数允许你传入0个或任意个含参数名的参数,这些关键字参数在函数内部自动组装为一个dict。
def person(name, age, **kw): //函数person除了必选参数name和age外,还接受关键字参数kw
print('name:', name, 'age:', age, 'other:', kw)
调用函数
>>> person('Michael', 30) //可以只传入必选参数
name: Michael age: 30 other: {}
>>> person('Bob', 35, city='Beijing') //也可以传入任意个数的关键字参数
name: Bob age: 35 other: {'city': 'Beijing'}
>>> person('Adam', 45, gender='M', job='Engineer')
name: Adam age: 45 other: {'gender': 'M', 'job': 'Engineer'}
和可变参数类似,也可以先组装出一个dict,然后,把该dict转换为关键字参数传进去:
>>> extra = {'city': 'Beijing', 'job': 'Engineer'}
>>> person('Jack', 24, **extra)//**extra表示把extra这个dict的所有key-value用关键字参数传入到函数的**kw参数
name: Jack age: 24 other: {'city': 'Beijing', 'job': 'Engineer'}
命名关键字参数(限制关键字参数的名字)
对于关键字参数,函数的调用者可以传入任意不受限制的关键字参数。至于到底传入了哪些,就需要在函数内部通过kw检查。
以person()函数为例,我们希望检查是否有city和job参数:
def person(name, age, **kw):
if 'city' in kw:
# 有city参数
pass
if 'job' in kw:
# 有job参数
print('job_parameter')
print('name:', name, 'age:', age, 'other:', kw)
person('Michael', 30, lucy=20, ass=100, job='teacher')
输出:
job_parameter
name: Michael age: 30 other: {'lucy': 20, 'ass': 100, 'job': 'teacher'}
如果要限制关键字参数的名字,就可以用命名关键字参数,例如,只接收city和job作为关键字参数。这种方式定义的函数如下:
def person(name, age, *, city, job): //需要一个特殊分隔符*,*后面的参数被视为命名关键字参数。
//注意:如果缺少*,Python解释器将无法识别位置参数和命名关键字参数:
print(name, age, city, job)
调用方式如下:
>>> person('Jack', 24, city='Beijing', job='Engineer')
Jack 24 Beijing Engineer
如果函数定义中已经有了一个可变参数,后面跟着的命名关键字参数就不再需要一个特殊分隔符*了
def person(name, age, *args, city, job):
print(name, age, args, city, job)
调用方式如下
>>> person('Jack', 24,'wwww', city='Beijing', job='Engineer') //命名关键字参数必须传入参数名,这和位置参数不同
Jack 24 ('wwww',) Beijing Engineer
命名关键字参数可以有缺省值,从而简化调用:
def person(name, age, *, city='Beijing', job):
print(name, age, city, job)
由于命名关键字参数city具有默认值,调用时,可不传入city参数
>>> person('Jack', 24, job='Engineer')
Jack 24 Beijing Engineer
参数组合
在采用不同参数的情况下,不同参数定义的顺序必须是:必选参数、默认参数、可变参数、命名关键字参数、关键字参数。
比如定义一个函数,包含上述若干种参数:
def f1(a, b, c=0, *args, **kw): //必选参数、默认参数、可变参数、关键字参数
print('a =', a, 'b =', b, 'c =', c, 'args =', args, 'kw =', kw)
def f2(a, b, c=0, *, d, **kw)://必选参数、默认参数、命名关键字参数、关键字参数
print('a =', a, 'b =', b, 'c =', c, 'd =', d, 'kw =', kw)
在函数调用的时候,Python解释器自动按照参数位置和参数名把对应的参数传进去。
通过一个tuple和dict,你也可以调用上述函数:
>>> args = (1, 2, 3, 4)
>>> kw = {'d': 99, 'x': '#'}
>>> f1(*args, **kw)
a = 1 b = 2 c = 3 args = (4,) kw = {'d': 99, 'x': '#'}
>>> args = (1, 2, 3)
>>> kw = {'d': 88, 'x': '#'}
>>> f2(*args, **kw)
a = 1 b = 2 c = 3 d = 88 kw = {'x': '#'}
所以,对于任意函数,都可以通过类似func(*args, **kw)的形式调用它,无论它的参数是如何定义的。
python参数小结
- 默认参数一定要用不可变对象,如果是可变对象,程序运行时会有逻辑错误!
- 要注意定义可变参数和关键字参数的语法:
- *args是可变参数,args接收的是一个tuple;
- **kw是关键字参数,kw接收的是一个dict。
- 以及注意调用函数时如何传入可变参数和关键字参数的语法:
- 可变参数既可以直接传入:func(1, 2, 3),又可以先组装list或tuple,再通过
*args传入:func(*(1, 2, 3)); - 关键字参数既可以直接传入:func(a=1, b=2),又可以先组装dict,再通过
**kw传入:func(**{'a': 1, 'b': 2})。
- 可变参数既可以直接传入:func(1, 2, 3),又可以先组装list或tuple,再通过
- 使用
*args和**kw是Python的习惯写法,当然也可以用其他参数名,但最好使用习惯用法。 - 命名的关键字参数是为了限制调用者可以传入的参数名,同时可以提供默认值。
- 定义命名的关键字参数在没有可变参数的情况下不要忘了写分隔符*,否则定义的将是位置参数。
6.4 return 语句
return 语句用来从一个函数返回即跳出函数。我们也可选是否从函数返回一个
值。
#!/usr/bin/python
def max1(a,b):
if a > b:
return a
else:
return b
print(max1(5,3))
输出:5
注意,没有返回值的 return 语句等价于 return None 。 None 是 Python 中表示没有任何东西的特殊类型。例如,如果一个变量的值为 None ,可以表示它没有值。除非你提供你自己的 return 语句,每个函数都在结尾暗含有 return None 语句。例如:
def someFunction():
pass #pass 语句在 Python 中表示一个空的语句块。
7 文件处理
7.1读取文件
f = open('test.txt', 'r') #使用Python内置的open()函数,传入文件名和标示符,标示符'r'表示读
g = f.read() #调用read()方法可以一次读取文件的全部内容
print(g) #read me
f.close() #调用close()方法关闭文件。文件使用完毕后必须关闭,因为文件对象会占用操作系统的资源
如果文件不存在,open()函数就会抛出一个IOError的错误,一旦出错,后面的f.close()就不会调用。为了保证无论是否出错都能正确地关闭文件,with语句来自动帮我们调用close()方法,代码更佳简洁,并且不必自己再调用f.close()方法。
with open('test.txt', 'r') as f:
print(f.read())
调用read()会一次性读取文件的全部内容,如果文件有10G,内存就爆了,所以,要保险起见,可以反复调用read(size)方法,每次最多读取size个字节的内容。另外,调用readline()可以每次读取一行内容,调用readlines()一次读取所有内容并按行返回list。
for line in f.readlines():
print(line.strip()) # 把末尾的'\n'删掉
strip() 方法用于移除字符串头尾指定的字符(默认为空格)
str = "0000000this is string example....wow!!!0000000";
print str.strip( '0' ); #this is string example....wow!!!
7.2写入文件
写文件和读文件是一样的,唯一区别是调用open()函数时,传入标识符'w'或者'wb'表示写文本文件或写二进制文件:
f = open('test2.txt', 'w')
f.write('Hello, world!')
f.write('\n')
f.write('123456')
f.close() #可以反复调用write()来写入文件,但是务必要调用f.close()来关闭文件
#Hello, world!
#123456
忘记调用close()的后果是数据可能只写了一部分到磁盘,剩下的丢失了。所以,还是用with语句来得保险:
with open('test2.txt', 'w') as f:
f.write('Hello, world!')
模式可以为读模式(’r’)、写模式(’w’)或追加模式(’a’)。事实上还有多得多的模式可以使用,你可以使用 help(file) 来了解它们的详情。
若想要写入文件的内容是追加在原文件内容之后,而不是覆盖,应该使用追加模式(’a’)。
with open('test2.txt', 'a') as f:
f.write('Hello, world!')
split()方法
split()通过指定分隔符对字符串进行切片,如果参数num 有指定值,则仅分隔 num 个子字符串。
str.split(str="", num=string.count(str))
str -- 分隔符,默认为所有的空字符,包括空格、换行(\n)、制表符(\t)等。
num -- 分割次数。
str = "Line1-abcdef \nLine2-abc \nLine4-abcd";
print str.split( );
print str.split(' ', 1 );
#输出结果如下:
['Line1-abcdef', 'Line2-abc', 'Line4-abcd']
['Line1-abcdef', '\nLine2-abc \nLine4-abcd']
读取csv文件
weather_data = []
f = open('weather.csv', 'r')
data = f.read()
rows = data.split('\n')
for row in rows:
split_row = row.split(',')
weather_data.append(split_row)
print(weather_data)
#输出结果
[['1', 'sunny'], ['2', 'sunny'], ['3', 'sunny'], ['4', 'sunny'], ['5', 'rain'], ['6', 'fog'], ['7', 'rain'], ['8', 'fog'], ['9', 'rain'], ['10', 'sunny']]
当只想要取出第二列的weather
weather_data = []
f = open('weather.csv', 'r')
data = f.read()
rows = data.split('\n')
for row in rows:
split_row = row.split(',')
weather_data.append(split_row)
weather = []
for row in weather_data:
weather.append(row[1])
print(weather)
f.close()
#输出结果
['sunny', 'sunny', 'sunny', 'sunny', 'rain', 'fog', 'rain', 'fog', 'rain', 'sunny']