最近在做Redis方面的一些工作,其中Redis3.0以前的版本,服务器端没有提供集群的方式。需要在客户端做sharding。redis客户端做sharding的话,需要用到一致性Hash算法。
假设我们有3台redis服务器。

一、普通Hash算法
1、首先对3台redis服务器的ip地址,进行hash运算。得到一个int类型的值。hash算法如下:
private static int getHash(String str) {
final int p = 16777619;
int hash = (int) 2166136261L;
for (int i = 0; i < str.length(); i++)
hash = (hash ^ str.charAt(i)) * p;
hash += hash << 13;
hash ^= hash >> 7;
hash += hash << 3;
hash ^= hash >> 17;
hash += hash << 5;
// 如果算出来的值为负数则取其绝对值
if (hash < 0)
hash = Math.abs(hash);
return hash;
}
2、利用得到的hash值对3进行取模
getHash(192.168.7.1)=196713682%3=1
getHash(192.168.7.2)=467665103%3=2
getHash(192.168.7.3)=542751888%3=0
3、假如我们想要把键值对name=linlin。存入到redis中,因为有3台redis存在,所以必须要决定将键值对存入到哪一台中。对key值name进行hash,然后对3进行取模。
getHash("name")=117328155%3=0
所以键值对name=linlin会被路由到192.168.7.3这台服务器中。
4、使用Java来实现
- 创建RedisNode类
package com.lin.hash.redis;
import java.util.HashMap;
import java.util.Map;
public class RedisNode {
private String ip;
private Map data;
public RedisNode(String ip) {
this.ip = ip;
data = new HashMap<>();
}
public String getIp() {
return ip;
}
public void setIp(String ip) {
this.ip = ip;
}
public Map getData() {
return data;
}
public void setData(Map data) {
this.data = data;
}
public Object getNodeValue(String key){
return data.get(key);
}
}
2.创建抽象类
package com.lin.hash.redis;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
public abstract class RedisCluster {
protected List redisNodes;
public RedisCluster() {
redisNodes = new ArrayList<>();
}
public List getRedisNodes() {
return redisNodes;
}
public void setRedisNodes(List redisNodes) {
this.redisNodes = redisNodes;
}
public abstract void addRedisNode(RedisNode redisNode);
public abstract RedisNode getRedisNode(String key);
public abstract void removeRedisNode(RedisNode redisNode);
}
3.创建NormalRedisCluster类
package com.lin.hash.redis;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
public class NormalRedisCluster extends RedisCluster {
private List redisNodes;
public NormalRedisCluster() {
redisNodes = new ArrayList<>();
}
public List getRedisNodes() {
return redisNodes;
}
public void setRedisNodes(List redisNodes) {
this.redisNodes = redisNodes;
}
public void addRedisNode(RedisNode redisNode){
redisNodes.add(redisNode);
}
public RedisNode getRedisNode(String key){
int hash = HashUtils.getHash(key);
/**使用key的hash值对key进行取模*/
RedisNode redisNode = redisNodes.get(hash % redisNodes.size());
return redisNode;
}
public void removeRedisNode(RedisNode redisNode){
Iterator iterator = redisNodes.iterator();
while (iterator.hasNext()){
RedisNode next = iterator.next();
if (next.getIp().equals(redisNode.getIp())){
iterator.remove();
}
}
}
}
4.创建HashUtils
package com.lin.hash.redis;
public class HashUtils {
/**
* 使用FNV1_32_HASH算法计算服务器的Hash值,这里不使用重写hashCode的方法,最终效果没区别
*/
public static int getHash(String str) {
final int p = 16777619;
int hash = (int) 2166136261L;
for (int i = 0; i < str.length(); i++)
hash = (hash ^ str.charAt(i)) * p;
hash += hash << 13;
hash ^= hash >> 7;
hash += hash << 3;
hash ^= hash >> 17;
hash += hash << 5;
// 如果算出来的值为负数则取其绝对值
if (hash < 0)
hash = Math.abs(hash);
return hash;
}
}
5.创建RedisHashTest类
package com.lin.hash.redis;
import com.alibaba.fastjson.JSONObject;
import java.util.List;
import java.util.Map;
public class RedisHashTest {
public static void main(String[] args) {
String[] servers = {"192.168.7.1","192.168.7.2","192.168.7.3"};
/**
* 添加redis节点
*/
RedisCluster redisCluster = new NormalRedisCluster();
for (String server:servers){
redisCluster.addRedisNode(new RedisNode(server));
}
/**
* 往redis集群中加入100条数据
* */
int dataCount = 100;
for (int i=0;i data = redisNode.getData();
data.put(key,value);
}
/**获取redis节点中的数据分布*/
List redisNodes = redisCluster.getRedisNodes();
for (RedisNode redisNode:redisNodes){
System.out.println(JSONObject.toJSONString(redisNode.getData()));
}
/**查看节点不变的情况下,redis数据的命中率*/
int hitCount = 0;
for (int i=0;i 5.我们可以看到在节点保持不变的情况下,数据的命中率为1.0。
新增一个节点的命中率为:0.27
删除一个节点的命中率为:0.4
但是无论是新增一个节点或者删除一个节点。数据的命中率都会显著降低。
一致性Hash算法
关于一致性Hash算法的原理,网络上已经有很多非常棒的文章,我在这里就不解释了,为了文章的完整性,在这里将原理贴出来:
先构造一个长度为232的整数环(这个环被称为一致性Hash环),根据节点名称的Hash值(其分布为[0, 232-1])将服务器节点放置在这个Hash环上,然后根据数据的Key值计算得到其Hash值(其分布也为[0, 232-1]),接着在Hash环上顺时针查找距离这个Key值的Hash值最近的服务器节点,完成Key到服务器的映射查找。
一直性Hash算法会导致数据分布不均匀的情况产生。如下图所示
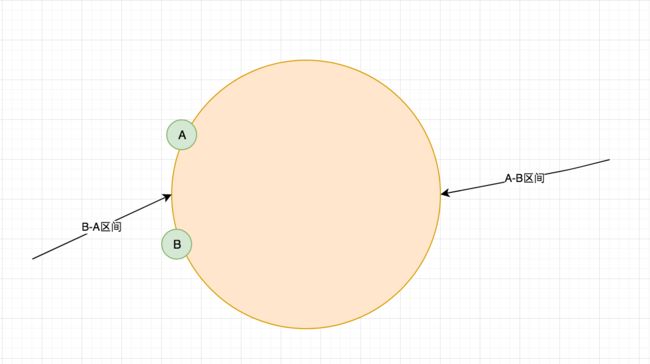
按照一致性Hash的原理,因为A-B区间占了圆环的绝大部分,所以大部分的数据都会落入到B节点上,这样就会导致数据不会均匀的分不到A-B两个节点中。从而导致负载不均衡。可以通过引入虚拟节点来解决这个问题。
不带虚拟节点的一致性Hash算法
下面是不带虚拟节点的ConsistentWithoutVirtualNodeRedisCluster
package com.lin.hash.redis;
import java.util.ArrayList;
import java.util.Collections;
import java.util.HashMap;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
import java.util.SortedMap;
import java.util.TreeMap;
public class ConsistentWithoutVirtualNodeRedisCluster extends RedisCluster{
private List redisNodes;
private SortedMap hashNodeMap = new TreeMap<>();
public ConsistentWithoutVirtualNodeRedisCluster() {
redisNodes = new ArrayList<>();
}
public List getRedisNodes() {
return redisNodes;
}
public void setRedisNodes(List redisNodes) {
this.redisNodes = redisNodes;
}
public void addRedisNode(RedisNode redisNode){
redisNodes.add(redisNode);
int hash = HashUtils.getHash(redisNode.getIp());
hashNodeMap.put(hash,redisNode);
}
public RedisNode getRedisNode(String key){
int hash = HashUtils.getHash(key);
SortedMap subMap = hashNodeMap.tailMap(hash);
int i = 0;
if (subMap.size()==0){
i = hashNodeMap.firstKey();
return hashNodeMap.get(i);
}else {
i = subMap.firstKey();
return subMap.get(i);
}
}
public void removeRedisNode(RedisNode redisNode){
Iterator iterator = redisNodes.iterator();
while (iterator.hasNext()){
RedisNode next = iterator.next();
if (next.getIp().equals(redisNode.getIp())){
iterator.remove();
}
}
}
}
如果要测试不带虚拟节点的一直性Hash算法的命中率,将
RedisCluster redisCluster = new NormalRedisCluster();
替换成
RedisCluster redisCluster = new ConsistentWithoutVirtualNodeRedisCluster();
就可以进行测试了
带虚拟节点的一致性Hash算法
假设我们将一个真实节点映射成10个虚拟节点。例如真正节点的ip是192.168.7.1。那么对应的十个虚拟ip分别是
真实:192.168.7.1
虚拟:
192.168.7.1&&VN1
192.168.7.1&&VN2
192.168.7.1&&VN3
192.168.7.1&&VN4
192.168.7.1&&VN5
192.168.7.1&&VN6
192.168.7.1&&VN7
192.168.7.1&&VN8
192.168.7.1&&VN9
192.168.7.1&&VN10
当真正进行数据存储的时候,我们根据虚拟节点的ip信息, 取出真正的ip,然后进行存储。
算法如下:
package com.lin.hash.redis;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
import java.util.SortedMap;
import java.util.TreeMap;
public class ConsistentWithVirtualNodeRedisCluster extends RedisCluster{
private List redisNodes;
//定义每个真实节点对应10个虚拟节点
private Integer virtualCount = 10;
private SortedMap virtualHashNodeMap = new TreeMap<>();
public ConsistentWithVirtualNodeRedisCluster() {
redisNodes = new ArrayList<>();
}
public List getRedisNodes() {
return redisNodes;
}
public void setRedisNodes(List redisNodes) {
this.redisNodes = redisNodes;
}
public void addRedisNode(RedisNode redisNode){
redisNodes.add(redisNode);
for (int i=0;i<10;i++){
int hash = HashUtils.getHash(redisNode.getIp()+"&&VN"+(i+1));
virtualHashNodeMap.put(hash,redisNode);
}
}
public RedisNode getRedisNode(String key){
int hash = HashUtils.getHash(key);
SortedMap subMap = virtualHashNodeMap.tailMap(hash);
int i = 0;
if (subMap.size()==0){
i = virtualHashNodeMap.firstKey();
return virtualHashNodeMap.get(i);
}else {
i = subMap.firstKey();
return subMap.get(i);
}
}
public void removeRedisNode(RedisNode redisNode){
Iterator iterator = redisNodes.iterator();
while (iterator.hasNext()){
RedisNode next = iterator.next();
if (next.getIp().equals(redisNode.getIp())){
iterator.remove();
}
}
}
}
如果要测试带虚拟节点的一直性Hash算法的命中率,将
RedisCluster redisCluster = new NormalRedisCluster();
替换成
RedisCluster redisCluster = new ConsistentWithVirtualNodeRedisCluster();
就可以进行测试了
从测试结果中可以看到,无论是新增节点还是删除节点,带虚拟节点的一致性Hash算法的命中率都大大的提高了。