1.注册中国大学MOOC

2.选择北京理工大学嵩天老师的《Python网络爬虫与信息提取》MOOC课程
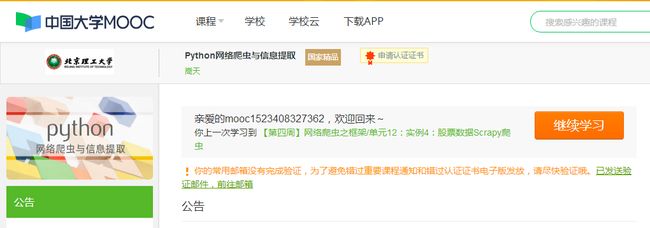
3.学习完成第0周至第4周的课程内容,并完成各周作业
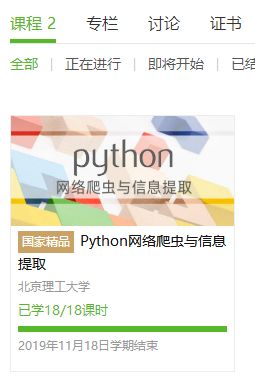
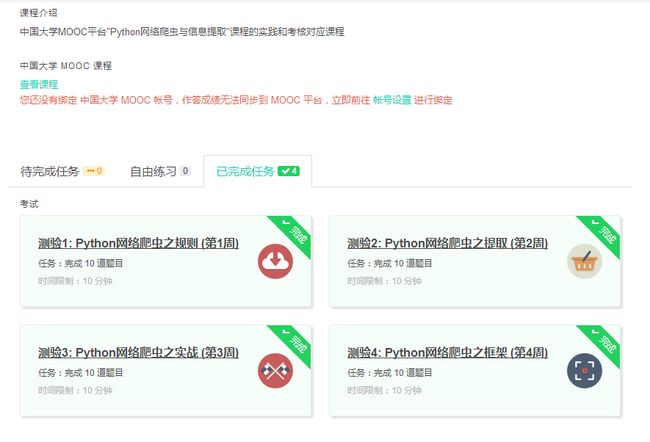
4.提供图片或网站显示的学习进度,证明学习的过程。
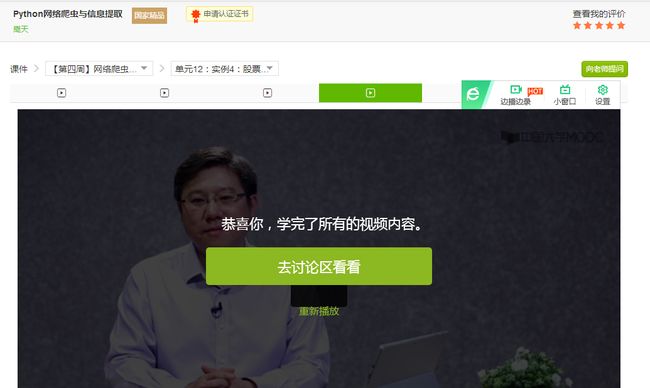
5.写一篇不少于1000字的学习笔记,谈一下学习的体会和收获。
学习心得:
经过这段时间学习嵩天老师的《Python网络爬虫与信息提取》MOOC课程,我感觉有了不少收获,增长了自己对爬虫的了解。
接下来说说自己的总结与心得。
第一周学习的是Requests,使用命令管理器安装,使用IDLE检测是否安装成功,状态码为200,便是安装成功。老师讲了Requests的七个主要方法,分别是:requests.requests()、requests.get() 、requests.head()、requests.post()、requests.put()、requests.patch()、requests.delete()。老师还讲述了两个重要对象:Response和Request。
Requests能够自动爬取html页面,自动网络请求提交。我们在使用爬虫时虽然能爬取到自己需要的数据,但是网络爬虫还是有可能引起性能骚扰、法律风险、隐私泄露等问题。
第二周我学习的是beautiful Soup,可以分析HTML页面。Beautiful Soup库是解析、遍历、维护“标签树”的功能库。Beautiful Soup库,也叫beautifulsoup4 或 bs4 约定引用方式如下,即主要是用BeautifulSoup 类。它提供了五种基本元素和三种遍历方法。
五种元素分别是:
1. Tag 标签,最基本的信息组织单元,分别用<> 和标明开头和结尾
2. Name 标签的名字,
…
的名字是'p',格式:3. Attributes 标签的属性,字典形式组织,格式:.attrs
4. NavigableString 标签内非属性字符串,<>…中字符串,格式:
5. Comment 标签内字符串的注释部分,一种特殊的Comment类型
三种遍历方法分别为:
- 上行遍历
- 下行遍历
- 平行遍历
课程里还告诉我们了信息标记的三种形式分别是:
- XML 最早的通用信息标记语言,可扩展性好,但繁琐。Internet上的信息交互与传递
- JSON 信息有类型,适合程序处理(js),较XML简洁。移动应用云端和节点的信息通信,无注释
- YAML 信息无类型,文本信息比例最高,可读性好。各类系统的配置文件,有注释易读
还有信息提取的三种方法:
- 完整解析信息的标记形式,再提取关键信息。需要标记解析器,例如:bs4库的标签树遍历。
- 无视标记形式,直接搜索关键信息。对信息的文本查找函数即可。
- 融合方法:结合形式解析与搜索方法,提取关键信息。需要标记解析器及文本查找函数
课程中还用了中国大学排名的实例,采用requests‐bs4路线实现了中国大学排名定向爬虫 对中英文混排输出问题进行优化。从而让我们更好的学习python。
第三周学习的是Re正则表达式。
正则表达式是用来简洁表达一组字符串的表达式,它的优势是简洁。它经常用于表达文本类型的特征(病毒、入侵等)、同时查找或替换一组字符串、匹配字符串的全部或部分。最主要应用在字符串匹配中。
我们还学到了Re库六个主要功能函数:
1. re.search() 在一个字符串中搜索匹配正则表达式的第一个位置,返回match对象
2. re.match() 从一个字符串的开始位置起匹配正则表达式,返回match对象
3. re.findall() 搜索字符串,以列表类型返回全部能匹配的子串
4. re.split() 将一个字符串按照正则表达式匹配结果进行分割,返回列表类型
5. re.finditer() 搜索字符串,返回一个匹配结果的迭代类型,每个迭代元素是match对象
6. re.sub() 在一个字符串中替换所有匹配正则表达式的子串,返回替换后的字符串
我们还学习了Match对象,它是一次匹配的结果,包含匹配的很多信息。
这次我们用的实例是淘宝商品信息,让我们熟练掌握正则表达式在信息提取方面的应用。还有一个股票数据的实例,采用requests‐bs4‐re路线实现了股票信息爬取和存储,实现了展示爬取进程的动态滚动条。
第四周我们学习网络爬虫的框架。我们学习的是Scrapy的安装及框架结构,爬虫框架是实现爬虫功能的一个软件结构和功能组件的集合,能够帮助用户实现专业的网络爬虫。
在学习完四周课程后,我学到了更多关于python的知识,我也知道了仅仅学到理论知识是不够的,实战会让自己遇到问题、发现问题、解决问题,这才是真正的成长。