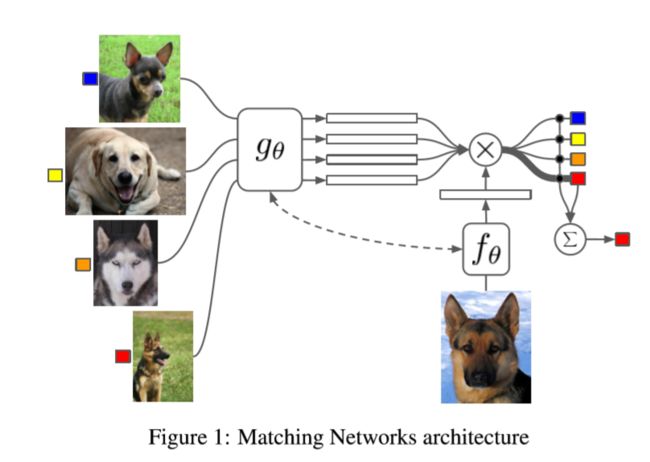
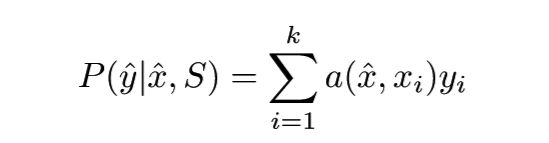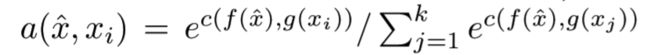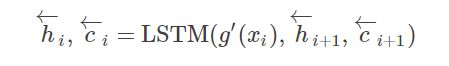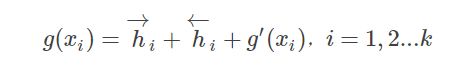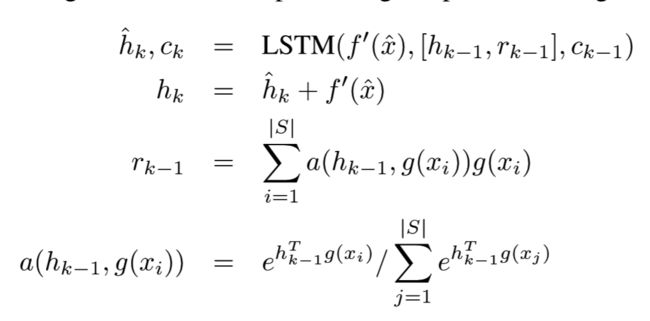- 机器学习与深度学习间关系与区别
ℒℴѵℯ心·动ꦿ໊ོ꫞
人工智能学习深度学习python
一、机器学习概述定义机器学习(MachineLearning,ML)是一种通过数据驱动的方法,利用统计学和计算算法来训练模型,使计算机能够从数据中学习并自动进行预测或决策。机器学习通过分析大量数据样本,识别其中的模式和规律,从而对新的数据进行判断。其核心在于通过训练过程,让模型不断优化和提升其预测准确性。主要类型1.监督学习(SupervisedLearning)监督学习是指在训练数据集中包含输入
- git常用命令笔记
咩酱-小羊
git笔记
###用习惯了idea总是不记得git的一些常见命令,需要用到的时候总是担心旁边站了人~~~记个笔记@_@,告诉自己看笔记不丢人初始化初始化一个新的Git仓库gitinit配置配置用户信息gitconfig--globaluser.name"YourName"gitconfig--globaluser.email"
[email protected]"基本操作克隆远程仓库gitclone查看
- python os.environ_python os.environ 读取和设置环境变量
weixin_39605414
pythonos.environ
>>>importos>>>os.environ.keys()['LC_NUMERIC','GOPATH','GOROOT','GOBIN','LESSOPEN','SSH_CLIENT','LOGNAME','USER','HOME','LC_PAPER','PATH','DISPLAY','LANG','TERM','SHELL','J2REDIR','LC_MONETARY','QT_QPA
- Git常用命令-修改远程仓库地址
猿大师
LinuxJavagitjava
查看远程仓库地址gitremote-v返回结果originhttps://git.coding.net/*****.git(fetch)originhttps://git.coding.net/*****.git(push)修改远程仓库地址gitremoteset-urloriginhttps://git.coding.net/*****.git先删除后增加远程仓库地址gitremotermori
- libyuv之linux编译
jaronho
Linuxlinux运维服务器
文章目录一、下载源码二、编译源码三、注意事项1、银河麒麟系统(aarch64)(1)解决armv8-a+dotprod+i8mm指令集支持问题(2)解决armv9-a+sve2指令集支持问题一、下载源码到GitHub网站下载https://github.com/lemenkov/libyuv源码,或者用直接用git克隆到本地,如:gitclonehttps://github.com/lemenko
- 【无标题】达瓦达瓦
JhonKI
考研
博客主页:https://blog.csdn.net/2301_779549673欢迎点赞收藏⭐留言如有错误敬请指正!本文由JohnKi原创,首发于CSDN未来很长,值得我们全力奔赴更美好的生活✨文章目录前言111️111❤️111111111111111总结111前言111骗骗流量券,嘿嘿111111111111111111111111111️111❤️111111111111111总结11
- 上图为是否色发
JhonKI
考研
博客主页:https://blog.csdn.net/2301_779549673欢迎点赞收藏⭐留言如有错误敬请指正!本文由JohnKi原创,首发于CSDN未来很长,值得我们全力奔赴更美好的生活✨文章目录前言111️111❤️111111111111111总结111前言111骗骗流量券,嘿嘿111111111111111111111111111️111❤️111111111111111总结11
- 143234234123432
JhonKI
考研
博客主页:https://blog.csdn.net/2301_779549673欢迎点赞收藏⭐留言如有错误敬请指正!本文由JohnKi原创,首发于CSDN未来很长,值得我们全力奔赴更美好的生活✨文章目录前言111️111❤️111111111111111总结111前言111骗骗流量券,嘿嘿111111111111111111111111111️111❤️111111111111111总结11
- 在Ubuntu中编译含有JSON的文件出现报错
芝麻糊76
Linuxkill_buglinuxubuntujson
在ubuntu中进行JSON相关学习的时候,我发现了一些小问题,决定与大家进行分享,减少踩坑时候出现不必要的时间耗费截取部分含有JSON部分的代码进行展示char*str="{\"title\":\"JSONExample\",\"author\":{\"name\":\"JohnDoe\",\"age\":35,\"isVerified\":true},\"tags\":[\"json\",\"
- Python中深拷贝与浅拷贝的区别
yuxiaoyu.
转自:http://blog.csdn.net/u014745194/article/details/70271868定义:在Python中对象的赋值其实就是对象的引用。当创建一个对象,把它赋值给另一个变量的时候,python并没有拷贝这个对象,只是拷贝了这个对象的引用而已。浅拷贝:拷贝了最外围的对象本身,内部的元素都只是拷贝了一个引用而已。也就是,把对象复制一遍,但是该对象中引用的其他对象我不复
- 女儿考研完报考雅思
捡拾流年
是否我过于焦虑?会不会无形间让女儿觉得压力太大了啊。2022年对于我们家来说是不平常的一年。女儿今年大四,为了准备考研,暑假也没回家,年初去了学校到了年末才回家。女儿自己一个人面对考研,没有参加培训,大四学校作业论文等课业也多,她同时也是很努力复习考研的。在疫情开放很多羊的时期,女儿终于顺顺利利参加12月24、25号的考研,我们和家人都觉得女儿回家来要好好休息调养。可女儿回到家,我再查阅考研信息,
- 你可能遗漏的一些C#/.NET/.NET Core知识点
追逐时光者
C#.NETDotNetGuide编程指南c#.net.netcoremicrosoft
前言在这个快速发展的技术世界中,时常会有一些重要的知识点、信息或细节被忽略或遗漏。《C#/.NET/.NETCore拾遗补漏》专栏我们将探讨一些可能被忽略或遗漏的重要知识点、信息或细节,以帮助大家更全面地了解这些技术栈的特性和发展方向。拾遗补漏GitHub开源地址https://github.com/YSGStudyHards/DotNetGuide/blob/main/docs/DotNet/D
- Some jenkins settings
SnC_
Jenkins连接到特定gitlabproject的特定branch我采用的方法是在pipeline的script中使用git命令来指定branch。如下:stage('Clonerepository'){steps{gitbranch:'develop',credentialsId:'gitlab-credential-id',url:'http://gitlab.com/repo.git'}}
- 第1步win10宿主机与虚拟机通过NAT共享上网互通
学习3人组
大数据大数据
VM的CentOS采用NAT共用宿主机网卡宿主机器无法连接到虚拟CentOS要实现宿主机与虚拟机通信,原理就是给宿主机的网卡配置一个与虚拟机网关相同网段的IP地址,实现可以互通。1、查看虚拟机的IP地址2、编辑虚拟机的虚拟网络的NAT和DHCP的配置,设置虚拟机的网卡选择NAT共享模式3、宿主机的IP配置,确保vnet8的IPV4属性与虚拟机在同一网段4、ping测试连通性[root@localh
- mac 备份android 手机通讯录导入iphone,iphone如何导出通讯录(轻松教你iPhone备份通讯录的方法)...
weixin_39762838
mac备份android手机通讯录导入iphone
在日新月异的手机更替中,换手机已经成为一个非常稀松平常的事情,但将旧手机上面的通讯录导入到新手机还是让不少小伙伴为难,本篇将给大家详细讲解这方面的知识:“苹果手机通讯录怎么导入到新手机”及“安卓手机通讯录导入到新手机”的方法。一、苹果手机通讯录导入到新手机常用方法(SIM卡导入)在苹果手机主频幕上找到“设置”,单击进入设置菜单,下拉菜单列表,点击“邮件、通讯录、日历”,然后找到“导入SIM卡通讯录
- SpringCloudAlibaba—Sentinel(限流)
菜鸟爪哇
前言:自己在学习过程的记录,借鉴别人文章,记录自己实现的步骤。借鉴文章:https://blog.csdn.net/u014494148/article/details/105484410Sentinel介绍Sentinel诞生于阿里巴巴,其主要目标是流量控制和服务熔断。Sentinel是通过限制并发线程的数量(即信号隔离)来减少不稳定资源的影响,而不是使用线程池,省去了线程切换的性能开销。当资源
- 光盘文件系统 (iso9660) 格式解析
穷人小水滴
光盘文件系统iso9660denoGNU/Linuxjavascript
越简单的系统,越可靠,越不容易出问题.光盘文件系统(iso9660)十分简单,只需不到200行代码,即可实现定位读取其中的文件.参考资料:https://wiki.osdev.org/ISO_9660相关文章:《光盘防水嘛?DVD+R刻录光盘泡水实验》https://blog.csdn.net/secext2022/article/details/140583910《光驱的内部结构及日常使用》ht
- 科幻游戏 《外卖员模拟器》 主要地理环境设定 (1)
穷人小水滴
游戏科幻设计
游戏名称:《外卖员模拟器》(英文名称:waimai_se)作者:穷人小水滴本故事纯属虚构,如有雷同实属巧合.故事发生在一个(架空)平行宇宙的地球,21世纪(超低空科幻流派).相关文章:https://blog.csdn.net/secext2022/article/details/141790630目录1星球整体地理设定2巨蛇国主要设定3海蛇市主要设定3.1主要地标建筑3.2交通3.3能源(电力)
- react-intl——react国际化使用方案
苹果酱0567
面试题汇总与解析java开发语言中间件springboot后端
国际化介绍i18n:internationalization国家化简称,首字母+首尾字母间隔的字母个数+尾字母,类似的还有k8s(Kubernetes)React-intl是React中最受欢迎的库。使用步骤安装#usenpmnpminstallreact-intl-D#useyarn项目入口文件配置//index.tsximportReactfrom"react";importReactDOMf
- Mongodb Error: queryTxt ETIMEOUT xxxx.wwwdz.mongodb.net
佛一脚
errorreactmongodb数据库
背景每天都能遇到奇怪的问题,做个记录,以便有缘人能得到帮助!换了一台电脑开发nextjs程序。需要连接mongodb数据,对数据进行增删改查。上一台电脑好好的程序,新电脑死活连不上mongodb数据库。同一套代码,没任何修改,搞得我怀疑人生了,打开浏览器进入mongodb官网毫无问题,也能进入线上系统查看数据,网络应该是没问题。于是我尝试了一下手机热点,这次代码能正常跑起来,连接数据库了!!!是不
- C++ lambda闭包消除类成员变量
barbyQAQ
c++c++java算法
原文链接:https://blog.csdn.net/qq_51470638/article/details/142151502一、背景在面向对象编程时,常常要添加类成员变量。然而类成员一旦多了之后,也会带来干扰。拿到一个类,一看成员变量好几十个,就问你怕不怕?二、解决思路可以借助函数式编程思想,来消除一些不必要的类成员变量。三、实例举个例子:classClassA{public:...intfu
- tiff批量转png
诺有缸的高飞鸟
opencv图像处理pythonopencv图像处理
目录写在前面代码完写在前面1、本文内容tiff批量转png2、平台/环境opencv,python3、转载请注明出处:https://blog.csdn.net/qq_41102371/article/details/132975023代码importnumpyasnpimportcv2importosdeffindAllFile(base):file_list=[]forroot,ds,fsin
- 笋丁网页自动回复机器人V3.0.0免授权版源码
希希分享
软希网58soho_cn源码资源笋丁网页自动回复机器人
笋丁网页机器人一款可设置自动回复,默认消息,调用自定义api接口的网页机器人。此程序后端语言使用Golang,内存占用最高不超过30MB,1H1G服务器流畅运行。仅支持Linux服务器部署,不支持虚拟主机,请悉知!使用自定义api功能需要有一定的建站基础。源码下载:https://download.csdn.net/download/m0_66047725/89754250更多资源下载:关注我。安
- iPhone怎么删除重复照片,可以尝试这几种方法
2401_85240355
iphoneios
在数字化时代,智能手机尤其是iPhone成为我们日常生活中不可或缺的一部分。随着我们不断使用iPhone拍照,重复照片的积累逐渐成为一个普遍问题。这不仅占用了大量的存储空间,也使得照片库变得杂乱无章。本文将介绍几种有效的iPhone怎么删除重复照片方法,并介绍如何利用CleanMyPhone来简化这一过程。iPhone怎么删除重复照片方法一:人工筛查人工筛查是最直接的方法,尽管它可能比较耗时。这种
- 【树一线性代数】005入门
Owlet_woodBird
算法
Index本文稍后补全,推荐阅读:https://blog.csdn.net/weixin_60702024/article/details/141874376分析实现总结本文稍后补全,推荐阅读:https://blog.csdn.net/weixin_60702024/article/details/141874376已知非空二叉树T的结点值均为正整数,采用顺序存储方式保存,数据结构定义如下:t
- 绝招曝光!3小时高效利用ChatGPT写出精彩论文
kkai人工智能
chatgpt人工智能ai学习媒体
在这份指南中,我将深入解析如何利用ChatGPT4.0的高级功能,指导整个学术研究和写作过程。从初步探索研究主题,到撰写结构严谨的学术论文,我将一步步展示如何在每个环节中有效运用ChatGPT。如果您还未使用PLUS版本,可以参考相关教程。**初步探索与主题的确定**起初,我处于庞大的知识领域中,寻找一个可深入研究的领域。ChatGPT如同灯塔,通过深入分析最新研究趋势和领域热点,帮助我在广阔的学
- 自动写论文的网站推荐这5款实用类工具
小猪包333
写论文人工智能深度学习计算机视觉AI写作
在当今学术研究和写作领域,AI论文写作工具的出现极大地提高了写作效率和质量。这些工具不仅能够帮助研究人员快速生成论文草稿,还能进行内容优化、查重和排版等操作。以下是五款实用类工具推荐,特别是千笔-AIPassPaper。1.千笔-AIPassPaper千笔-AIPassPaper是一款功能强大且全面的AI论文写作助手,用户只需输入基本的研究需求和关键词,便能迅速生成一篇完整的论文。该工具利用先进的
- 推荐3家毕业AI论文可五分钟一键生成!文末附免费教程!
小猪包333
写论文人工智能AI写作深度学习计算机视觉
在当前的学术研究和写作领域,AI论文生成器已经成为许多研究人员和学生的重要工具。这些工具不仅能够帮助用户快速生成高质量的论文内容,还能进行内容优化、查重和排版等操作。以下是三款值得推荐的AI论文生成器:千笔-AIPassPaper、懒人论文以及AIPaperPass。千笔-AIPassPaper千笔-AIPassPaper是一款基于深度学习和自然语言处理技术的AI写作助手,旨在帮助用户快速生成高质
- 4款毕业论文参考文献格式生成器(附加详细步骤)
小猪包333
写论文人工智能深度学习计算机视觉AI写作
在撰写毕业论文时,参考文献的格式规范是至关重要的。为了帮助学生和学者们更高效地生成符合要求的参考文献格式,本文将详细介绍四款推荐的参考文献格式生成器,并提供详细的使用步骤。1.千笔-AIPassPaper千笔-AIPassPaper是一款先进的AI辅助论文写作工具,不仅能够自动生成大纲、开题报告,还能一键生成参考文献。AI论文,免费大纲,10分钟3万字https://www.aipaperpass
- AI论文写作推荐哪个好?分享5款AI论文写作带数据图表网站
小猪包333
写论文人工智能深度学习计算机视觉
在当今学术研究和写作领域,AI论文写作工具的出现极大地提高了写作效率和质量。这些工具不仅能够帮助研究人员快速生成论文草稿,还能进行内容优化、查重和排版等操作。以下是五款推荐的AI论文写作工具,包括千笔-AIPassPaper。千笔-AIPassPaper千笔-AIPassPaper是一款功能强大的AI论文写作助手,旨在帮助用户快速生成高质量的论文内容。AI论文,免费大纲,10分钟3万字https:
- java线程的无限循环和退出
3213213333332132
java
最近想写一个游戏,然后碰到有关线程的问题,网上查了好多资料都没满足。
突然想起了前段时间看的有关线程的视频,于是信手拈来写了一个线程的代码片段。
希望帮助刚学java线程的童鞋
package thread;
import java.text.SimpleDateFormat;
import java.util.Calendar;
import java.util.Date
- tomcat 容器
BlueSkator
tomcatWebservlet
Tomcat的组成部分 1、server
A Server element represents the entire Catalina servlet container. (Singleton) 2、service
service包括多个connector以及一个engine,其职责为处理由connector获得的客户请求。
3、connector
一个connector
- php递归,静态变量,匿名函数使用
dcj3sjt126com
PHP递归函数匿名函数静态变量引用传参
<!doctype html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>Current To-Do List</title>
</head>
<body>
- 属性颜色字体变化
周华华
JavaScript
function changSize(className){
var diva=byId("fot")
diva.className=className;
}
</script>
<style type="text/css">
.max{
background: #900;
color:#039;
- 将properties内容放置到map中
g21121
properties
代码比较简单:
private static Map<Object, Object> map;
private static Properties p;
static {
//读取properties文件
InputStream is = XXX.class.getClassLoader().getResourceAsStream("xxx.properti
- [简单]拼接字符串
53873039oycg
字符串
工作中遇到需要从Map里面取值拼接字符串的情况,自己写了个,不是很好,欢迎提出更优雅的写法,代码如下:
import java.util.HashMap;
import java.uti
- Struts2学习
云端月影
最近开始关注struts2的新特性,从这个版本开始,Struts开始使用convention-plugin代替codebehind-plugin来实现struts的零配置。
配置文件精简了,的确是简便了开发过程,但是,我们熟悉的配置突然disappear了,真是一下很不适应。跟着潮流走吧,看看该怎样来搞定convention-plugin。
使用Convention插件,你需要将其JAR文件放
- Java新手入门的30个基本概念二
aijuans
java新手java 入门
基本概念: 1.OOP中唯一关系的是对象的接口是什么,就像计算机的销售商她不管电源内部结构是怎样的,他只关系能否给你提供电就行了,也就是只要知道can or not而不是how and why.所有的程序是由一定的属性和行为对象组成的,不同的对象的访问通过函数调用来完成,对象间所有的交流都是通过方法调用,通过对封装对象数据,很大限度上提高复用率。 2.OOP中最重要的思想是类,类是模板是蓝图,
- jedis 简单使用
antlove
javarediscachecommandjedis
jedis.RedisOperationCollection.java
package jedis;
import org.apache.log4j.Logger;
import redis.clients.jedis.Jedis;
import java.util.List;
import java.util.Map;
import java.util.Set;
pub
- PL/SQL的函数和包体的基础
百合不是茶
PL/SQL编程函数包体显示包的具体数据包
由于明天举要上课,所以刚刚将代码敲了一遍PL/SQL的函数和包体的实现(单例模式过几天好好的总结下再发出来);以便明天能更好的学习PL/SQL的循环,今天太累了,所以早点睡觉,明天继续PL/SQL总有一天我会将你永远的记载在心里,,,
函数;
函数:PL/SQL中的函数相当于java中的方法;函数有返回值
定义函数的
--输入姓名找到该姓名的年薪
create or re
- Mockito(二)--实例篇
bijian1013
持续集成mockito单元测试
学习了基本知识后,就可以实战了,Mockito的实际使用还是比较麻烦的。因为在实际使用中,最常遇到的就是需要模拟第三方类库的行为。
比如现在有一个类FTPFileTransfer,实现了向FTP传输文件的功能。这个类中使用了a
- 精通Oracle10编程SQL(7)编写控制结构
bijian1013
oracle数据库plsql
/*
*编写控制结构
*/
--条件分支语句
--简单条件判断
DECLARE
v_sal NUMBER(6,2);
BEGIN
select sal into v_sal from emp
where lower(ename)=lower('&name');
if v_sal<2000 then
update emp set
- 【Log4j二】Log4j属性文件配置详解
bit1129
log4j
如下是一个log4j.properties的配置
log4j.rootCategory=INFO, stdout , R
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appe
- java集合排序笔记
白糖_
java
public class CollectionDemo implements Serializable,Comparable<CollectionDemo>{
private static final long serialVersionUID = -2958090810811192128L;
private int id;
private String nam
- java导致linux负载过高的定位方法
ronin47
定位java进程ID
可以使用top或ps -ef |grep java
![图片描述][1]
根据进程ID找到最消耗资源的java pid
比如第一步找到的进程ID为5431
执行
top -p 5431 -H
![图片描述][2]
打印java栈信息
$ jstack -l 5431 > 5431.log
在栈信息中定位具体问题
将消耗资源的Java PID转
- 给定能随机生成整数1到5的函数,写出能随机生成整数1到7的函数
bylijinnan
函数
import java.util.ArrayList;
import java.util.List;
import java.util.Random;
public class RandNFromRand5 {
/**
题目:给定能随机生成整数1到5的函数,写出能随机生成整数1到7的函数。
解法1:
f(k) = (x0-1)*5^0+(x1-
- PL/SQL Developer保存布局
Kai_Ge
近日由于项目需要,数据库从DB2迁移到ORCAL,因此数据库连接客户端选择了PL/SQL Developer。由于软件运用不熟悉,造成了很多麻烦,最主要的就是进入后,左边列表有很多选项,自己删除了一些选项卡,布局很满意了,下次进入后又恢复了以前的布局,很是苦恼。在众多PL/SQL Developer使用技巧中找到如下这段:
&n
- [未来战士计划]超能查派[剧透,慎入]
comsci
计划
非常好看,超能查派,这部电影......为我们这些热爱人工智能的工程技术人员提供一些参考意见和思想........
虽然电影里面的人物形象不是非常的可爱....但是非常的贴近现实生活....
&nbs
- Google Map API V2
dai_lm
google map
以后如果要开发包含google map的程序就更麻烦咯
http://www.cnblogs.com/mengdd/archive/2013/01/01/2841390.html
找到篇不错的文章,大家可以参考一下
http://blog.sina.com.cn/s/blog_c2839d410101jahv.html
1. 创建Android工程
由于v2的key需要G
- java数据计算层的几种解决方法2
datamachine
javasql集算器
2、SQL
SQL/SP/JDBC在这里属于一类,这是老牌的数据计算层,性能和灵活性是它的优势。但随着新情况的不断出现,单纯用SQL已经难以满足需求,比如: JAVA开发规模的扩大,数据量的剧增,复杂计算问题的涌现。虽然SQL得高分的指标不多,但都是权重最高的。
成熟度:5星。最成熟的。
- Linux下Telnet的安装与运行
dcj3sjt126com
linuxtelnet
Linux下Telnet的安装与运行 linux默认是使用SSH服务的 而不安装telnet服务 如果要使用telnet 就必须先安装相应的软件包 即使安装了软件包 默认的设置telnet 服务也是不运行的 需要手工进行设置 如果是redhat9,则在第三张光盘中找到 telnet-server-0.17-25.i386.rpm
- PHP中钩子函数的实现与认识
dcj3sjt126com
PHP
假如有这么一段程序:
function fun(){
fun1();
fun2();
}
首先程序执行完fun1()之后执行fun2()然后fun()结束。
但是,假如我们想对函数做一些变化。比如说,fun是一个解析函数,我们希望后期可以提供丰富的解析函数,而究竟用哪个函数解析,我们希望在配置文件中配置。这个时候就可以发挥钩子的力量了。
我们可以在fu
- EOS中的WorkSpace密码修改
蕃薯耀
修改WorkSpace密码
EOS中BPS的WorkSpace密码修改
>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
蕃薯耀 201
- SpringMVC4零配置--SpringSecurity相关配置【SpringSecurityConfig】
hanqunfeng
SpringSecurity
SpringSecurity的配置相对来说有些复杂,如果是完整的bean配置,则需要配置大量的bean,所以xml配置时使用了命名空间来简化配置,同样,spring为我们提供了一个抽象类WebSecurityConfigurerAdapter和一个注解@EnableWebMvcSecurity,达到同样减少bean配置的目的,如下:
applicationContex
- ie 9 kendo ui中ajax跨域的问题
jackyrong
AJAX跨域
这两天遇到个问题,kendo ui的datagrid,根据json去读取数据,然后前端通过kendo ui的datagrid去渲染,但很奇怪的是,在ie 10,ie 11,chrome,firefox等浏览器中,同样的程序,
浏览起来是没问题的,但把应用放到公网上的一台服务器,
却发现如下情况:
1) ie 9下,不能出现任何数据,但用IE 9浏览器浏览本机的应用,却没任何问题
- 不要让别人笑你不能成为程序员
lampcy
编程程序员
在经历六个月的编程集训之后,我刚刚完成了我的第一次一对一的编码评估。但是事情并没有如我所想的那般顺利。
说实话,我感觉我的脑细胞像被轰炸过一样。
手慢慢地离开键盘,心里很压抑。不禁默默祈祷:一切都会进展顺利的,对吧?至少有些地方我的回答应该是没有遗漏的,是不是?
难道我选择编程真的是一个巨大的错误吗——我真的永远也成不了程序员吗?
我需要一点点安慰。在自我怀疑,不安全感和脆弱等等像龙卷风一
- 马皇后的贤德
nannan408
马皇后不怕朱元璋的坏脾气,并敢理直气壮地吹耳边风。众所周知,朱元璋不喜欢女人干政,他认为“后妃虽母仪天下,然不可使干政事”,因为“宠之太过,则骄恣犯分,上下失序”,因此还特地命人纂述《女诫》,以示警诫。但马皇后是个例外。
有一次,马皇后问朱元璋道:“如今天下老百姓安居乐业了吗?”朱元璋不高兴地回答:“这不是你应该问的。”马皇后振振有词地回敬道:“陛下是天下之父,
- 选择某个属性值最大的那条记录(不仅仅包含指定属性,而是想要什么属性都可以)
Rainbow702
sqlgroup by最大值max最大的那条记录
好久好久不写SQL了,技能退化严重啊!!!
直入主题:
比如我有一张表,file_info,
它有两个属性(但实际不只,我这里只是作说明用):
file_code, file_version
同一个code可能对应多个version
现在,我想针对每一个code,取得它相关的记录中,version 值 最大的那条记录,
SQL如下:
select
*
- VBScript脚本语言
tntxia
VBScript
VBScript 是基于VB的脚本语言。主要用于Asp和Excel的编程。
VB家族语言简介
Visual Basic 6.0
源于BASIC语言。
由微软公司开发的包含协助开发环境的事
- java中枚举类型的使用
xiao1zhao2
javaenum枚举1.5新特性
枚举类型是j2se在1.5引入的新的类型,通过关键字enum来定义,常用来存储一些常量.
1.定义一个简单的枚举类型
public enum Sex {
MAN,
WOMAN
}
枚举类型本质是类,编译此段代码会生成.class文件.通过Sex.MAN来访问Sex中的成员,其返回值是Sex类型.
2.常用方法
静态的values()方