1.注册中国大学MOOC

2.选择北京理工大学嵩天老师的《Python网络爬虫与信息提取》MOOC课程
3.学习完成第0周至第4周的课程内容,并完成各周作业
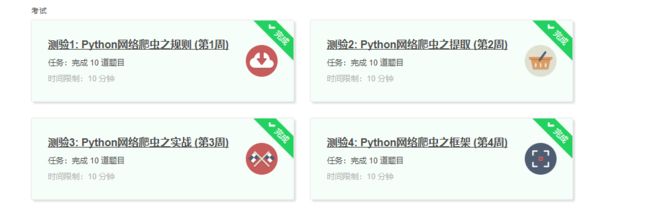
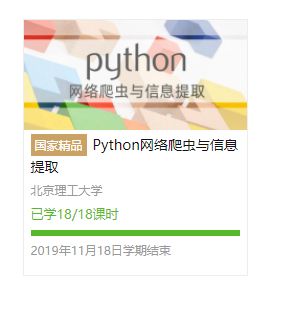
4.提供图片或网站显示的学习进度,证明学习的过程。
5.写一篇不少于1000字的学习笔记,谈一下学习的体会和收获。
这门课程介绍Python计算生态中最优秀的网络数据爬取和解析技术,具体讲授构建网络爬虫功能的两条重要技术路线:requests-bs4-re和Scrapy,课程内容是进入大数据处理、数据挖掘、以数据为中心人工智能领域的必备实践基础。教学内容包括:Python第三方库Requests,讲解通过HTTP/HTTPS协议自动从互联网获取数据并向其提交请求的方法;Python第三方库Beautiful Soup,讲解从所爬取HTML页面中解析完整Web信息的方法;Python标准库Re,讲解从所爬取HTML页面中提取关键信息的方法;python第三方库Scrapy,介绍通过网络爬虫框架构造专业网络爬虫的基本方法。
嵩天老师在第0周的课程中,向我们介绍了python的许多优秀的第三方库和框架,也让我们自行选择一个适合自己的python编译器,我安装使用了pycharm,以便进行接下来的课程学习。
在第一周的学习过程中,首先我们学习了Requests库的安装、它的七个主要方法、HTTP协议对资源的操作、Response对象属性、Requests库的六种异常、学习操作了五个实例练习和了解了网络爬虫的尺寸,避免踩雷。在Response对象属性理解中,要注意区分:
request:爬虫请求request对象 response:爬虫返回的内容 r.encoding 从http header中猜测的响应内容的编码方式 。如果header中不存在charset,则认为编码为ISO-8859-1,这个编码不能解析中文 r.apparent_encoding 从内容中分析出的响应内容编码方式(备选编码方式)。 从网页内容中推断编码方式,更加准确一些,当encoding不能解析正确编码方式时,采用这个。
在第2周的时候嵩天老师介绍的是Beautiful Soup库,Beautiful Soup库是解析、遍历、维护“标签树的功能。它也叫beautifulsoup4 或bs4,它有四种解析器:bs4的HTML解析器、lxml的HTML解析器、lxml的XML解析器、html5lib的解析器。Beautiful Soup库还有3种遍历方式分别是:上行遍历,下行遍历和平行遍历,通过这三种遍历的方式我们可以来获取各个节点的信息。信息提取的一般方法:一、完整解析信息的标记形式,再提取关键信息;二、无视标记形式,直接搜索关键信息;三、融合方法,结合形式解析与搜索方法,提取关键信息。嵩天老师实例中采用requests-bs4路线实现中国大学排名定向爬虫,让我们更加了解和会使用python。
在第三周的课件“网络爬虫之实战”中,首先对正则表达式进行了详解,在之前的学习中,我一直对正则表达式这一知识点很困惑,通过这次的学习,让我对这个知识点理解的更透彻。在老师讲解的课程中,让我对正则表达式也有了新的认识,利用正则表达式和re库的结合提取页面的关键信息,并把此应用到淘宝商品的实例中。在股票数据定向爬虫中,采用requests-bs4-re路线实现了股票信息爬取和存储,实现了展示爬取进程的动态滚动条。
在第四周中,学习了Scrapy的安装及Scrapy爬虫框架的介绍和解析,“5+2”结构的目的和功能,及requests库和Scrapy爬虫的比较和Scrapy爬虫的常用命令。Scrapy命令行的格式和逻辑。老师还介绍了Scrapy爬虫的第一个实例,yield关键字的使用和Scrapy爬虫的基本使用:使用步骤,数据类型,提取信息的方法,CSS Selector的基本使用。老师还详细讲解了实例:股票数据Scrapy爬虫,功能、框架、实例的编写步骤、执行和优化。