python主要使用pandas进行分析,
数据是CDNow网站的用户购买明细。一共有用户ID,购买日期,购买数量,购买金额四个字段。我们通过案例数据完成一份基础的数据分析报告
数据获取可以可以通过百度网盘,
https://pan.baidu.com/s/1o794j3s 提取码2hge。
使用pylab 模式进入ipython,这个模式会自动的加载matplotlib;
在控制在键入ipython --pylab ,回车;
导入数据,
import pandas as pd
columns = ['user_id','order_dt','order_products','order_amount']
df = pd.read_csv('CDNOW_master.txt',names=columns,sep='\s+') # 分隔符用\s+表示匹配任意空白符。
查看数据的一般统计描述,
df.describe()

用户平均每笔订单购买2.4个商品,平均花费35.8;标准差为2.3,说明数据有较大波动;75分位数为3,有较多的订单购买数量都不超过3个;最大的订单购买了99个商品,消费金额陡增;这符合消费类商品的28分布,大部分用户都是小额,然而小部分用户贡献了收入的大头,俗称二八。
df.info()

数据中没有null值,说明数据很干净,不用清洗;
进行时间的数据类型转换,
df['order_date'] = pd.to_datetime(df.order_dt,format='%Y%m%d') # 提取出时间信息
df['month'] = df.order_date.values.astype('datetime64[M]') # 将日期转换为月份.
将月份作为消费行为的主要事件窗口,选择哪种时间窗口取决于消费频率。
进行分组聚合操作,
df.groupby('user_id').sum().describe()

从每个用户的角度来看,平均每人购买7件商品,有人会问为什么比前面的平均值多,因为有的用户是在不同的时间购买;标准差很大,波动很大,大部分用户在7件之下;
按月进行分析,
df.groupby('month').order_products.sum().plot()

在4月以后销量明显下滑,到了第二年的4月也不见回升!
df.groupby('month').order_amount.sum().plot()

销售数据与销量数据走势几乎一样;
绘制每笔订单的散点图,
df.plot.scatter(x='order_amount',y='order_products')

订单消费金额和订单商品量呈规律性,每个商品十元左右。订单的极值较少,超出1000的就几个。显然不是异常波动的罪魁祸首。
每个用户的散点图,
df.groupby('user_id').sum().plot.scatter(x='order_amount',y='order_products')

用户也比较健康,而且规律性比订单更强。因为这是CD网站的销售数据,商品比较单一,金额和商品量的关系也因此呈线性,没几个离群点.
分析每个用户的消费能力,
df.groupby('user_id').sum().order_amount.plot(kind='hist',bins=1000,xlim=(0,1000))

从直方图看,大部分用户的消费能力确实不高,几乎都在200元以下,高消费用户在图上几乎看不到。这也确实符合消费行为的行业规律。
用groupby函数将用户分组,并且求月份的最小值,最小值即用户消费行为中的第一次消费时间。 最大值为最后一次消费时间。
df.groupby('user_id').month.min().value_counts()
df.groupby('user_id').month.max().value_counts()

OK,绝大部分用户都集中在前三个月消费。后续的时间段内,依然有用户在消费,但是缓慢减少。异常趋势的原因获得了解释,现在针对消费数据进一步细分。我们要明确,这只是部分用户的订单数据,所以有一定局限性。在这里,我们统一将数据上消费的用户定义为新客。
分析消费中的复购率和回购率
pivoted_counts = df.pivot_table(index='user_id',columns='month',values='order_dt',aggfunc='count').fillna(0)
首先求复购率,复购率的定义是在某时间窗口内消费两次及以上的用户在总消费用户中占比。这里的时间窗口是月,如果一个用户在同一天下了两笔订单,这里也将他算作复购用户。
将数据转换一下,消费两次及以上记为1,消费一次记为0,没有消费记为NaN。
pivoted_counts_tran = pivoted_counts.applymap(lambda x: 1 if x > 1 else np.NaN if x == 0 else 0)
如果有复购值就会是1,所以sum除count就是我们要求的复购率,而NaN值并不会被计算,
(pivoted_counts_tran.sum()/pivoted_counts_tran.count()).plot()

图上可以看出复购率在早期,因为大量新用户加入的关系,新客的复购率并不高,譬如1月新客们的复购率只有6%左右。而在后期,这时的用户都是大浪淘沙剩下的老客,复购率比较稳定,在20%左右。
单看新客和老客,复购率有三倍左右的差距。
回购率是某一个时间窗口内消费的用户,在下一个时间窗口仍旧消费的占比。比如1月消费用户1000,他们中有300个2月依然消费,回购率是30%。
# 使用一个函数来判断是否有回购情况
def purchase_return(user):
status = []
for i in range(17):
if user[i] >= 1:
if user[i + 1] >= 1:
status.append(1)
else:
status.append(0)
else:
status.append(np.NaN)
status.append(np.NaN)
return status
pivoted_purchase_return = pivoted_counts.apply(purchase_return,axis=1) # 用apply函数应用在所有行上,就是每一个用户上
(pivoted_purchase_return.sum()/pivoted_purchase_return.count()).plot()
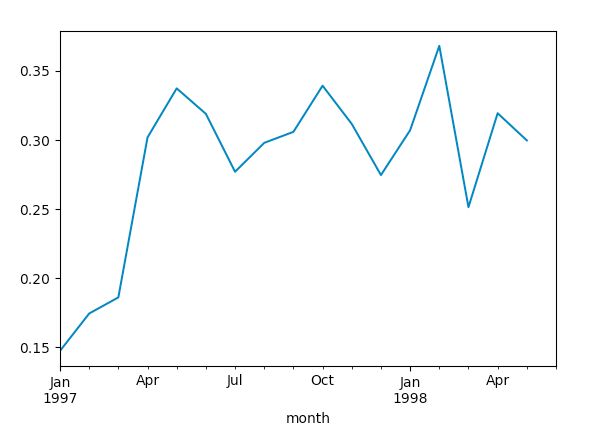
从图中可以看出,用户的回购率高于复购,约在30%左右,波动性也较强。新用户的回购率在15%左右,和老客差异不大。
将回购率和复购率综合分析,可以得出,新客的整体质量低于老客,老客的忠诚度(回购率)表现较好,消费频次稍次,这是CDNow网站的用户消费特征。
接下来进行用户分层,我们按照用户的消费行为,简单划分成几个维度:新用户、活跃用户、不活跃用户、回流用户。
新用户的定义是第一次消费。活跃用户即老客,在某一个时间窗口内有过消费。不活跃用户则是时间窗口内没有消费过的老客。回流用户是在上一个窗口中没有消费,而在当前时间窗口内有过消费。以上的时间窗口都是按月统计。
比如某用户在1月第一次消费,那么他在1月的分层就是新用户;他在2月消费国,则是活跃用户;3月没有消费,此时是不活跃用户;4月再次消费,此时是回流用户,5月还是消费,是活跃用户。
分层会涉及到比较复杂的逻辑判断。
def active_status(user):
status = []
for i in range(17):
if user[i] == 0:
if len(status) > 0:
if status[i-1] == 'regis': #未注册
status.append('regis')
else:
status.append('unactive')
else:
status.append('regis')
else:
if len(status) == 0:
status.append('new')
else:
if status[i-1] == 'regis':
status.append('new')
elif status[i-1] == 'unactive':
status.append('return')
else:
status.append('active')
return status
pivoted_status = pivoted_counts.apply(active_status,axis=1)
status_counts =pivoted_status.replace('regis',np.NaN).apply(lambda x:pd.value_counts(x)) #统计计数 regis状态排除掉,它是「未来」才作为新客,这么能计数呢.
status_counts.fillna(0).T.plot(kind='area')

因为它只是某时间段消费过的用户的后续行为,红色和橙色区域都可以不看。只看绿色回流和蓝色活跃这两个分层,用户数比较稳定。这两个分层相加,就是消费用户占比(后期没新客)
rate =status_counts.apply(lambda x:x/x.sum(),axis=1)
rate.loc['return'].plot()
rate.loc['active'].plot()
查看用户回流率,活跃度,图这里就不贴了
回流占比,就是回流用户在总用户中的占比。另外一种指标叫回流率,指上个月多少不活跃/消费用户在本月活跃/消费。因为不活跃的用户总量近似不变,所以这里的回流率也近似回流占比。
结合回流用户和活跃用户看,在后期的消费用户中,60%是回流用户,40%是活跃用户/连续消费用户,整体质量还好,但是针对这两个分层依旧有改进的空间,可以继续细化数据。
用户消费数据的概率分布,
ser_amount = df.groupby('user_id').order_amount.sum().sort_values().reset_index() # 排序
user_amount['amount_cumsum'] = user_amount.order_amount.cumsum() # 累加
user_amount['prop'] = user_amount.apply(lambda x:x.amount_cumsum/user_amount.amount_cumsum.max(),axis=1) # 求概率分布
user_amount.prop.plot()
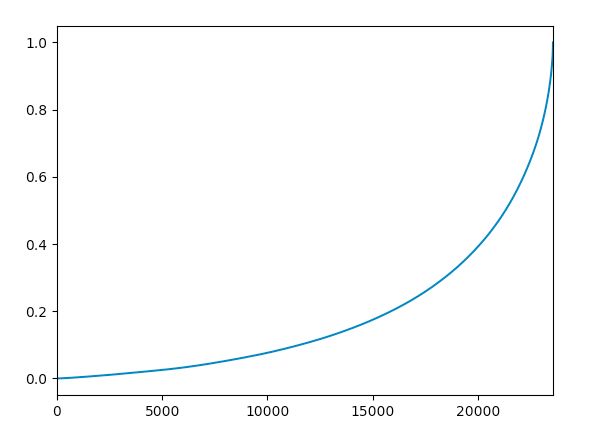
统计一下销量,前两万个用户贡献了45%的销量,高消费用户贡献了55%的销量。在消费领域中,狠抓高质量用户是万古不变的道理。
计算用户生命周期,这里定义第一次消费至最后一次消费为整个用户生命。
(df.groupby('user_id').order_date.max() - df.groupby('user_id').order_date.min()).describe()
所有用户的平均生命周期是134天,但一多半用户都是0;
看一下分布图,
((df.groupby('user_id').order_date.max() - df.groupby('user_id').order_date.min())/np.timedelta64(1,'D')).hist(bins=100) # 换算的方式直接除timedelta函数即可,这里的np.timedelta64(1, 'D'),D表示天,1表示1天,作为单位使用的
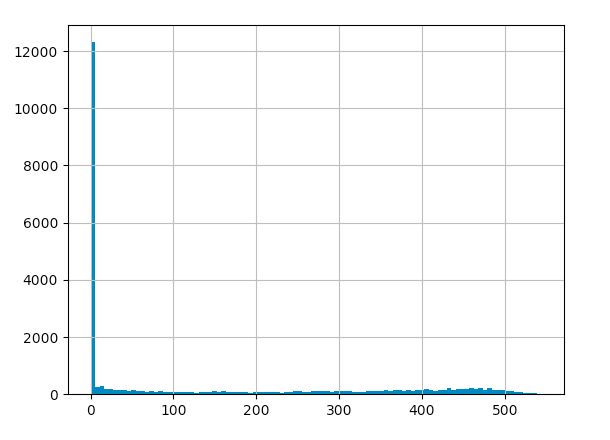
大部分用户只消费了一次,所有生命周期的大头都集中在了0天。但这不是我们想要的答案,不妨将只消费了一次的新客排除,来计算所有消费过两次以上的老客的生命周期。
life_time =(df.groupby('user_id').order_date.max() - df.groupby('user_id').order_date.min())/np.timedelta64(1,'D')
life_time[life_time > 0].hist(bins=200) # 也可以再给life_time加一个column让他讲他转为Dataframe

这个图比上面的靠谱多了,虽然仍旧有不少用户生命周期靠拢在0天。这是双峰趋势图。部分质量差的用户,虽然消费了两次,但是仍旧无法持续,在用户首次消费30天内应该尽量引导。少部分用户集中在50天~300天,属于普通型的生命周期,高质量用户的生命周期,集中在400天以后,这已经属于忠诚用户了,大家有兴趣可以跑一下400天+的用户占老客比多少,占总量多少。
再来计算留存率,留存率也是消费分析领域的经典应用。它指用户在第一次消费后,有多少比率进行第二次消费。和回流率的区别是留存倾向于计算第一次消费,并且有多个时间窗口。
user_purchase = df[['user_id','order_products','order_amount','order_date']]
user_retention = pd.merge(left=user_purchase,right=df.groupby('user_id').order_date.min().reset_index(),how='inner',on='user_id',suffixes=('_max','_min'))
这里用到merge函数,它和SQL中的join差不多,用来将两个DataFrame进行合并。我们选择了inner 的方式,对标inner join。即只合并能对应得上的数据。这里以on=user_id为对应标准。这里merge的目的是将用户消费行为和第一次消费时间对应上,形成一个新的DataFrame。suffxes参数是如果合并的内容中有重名column,加上后缀。
user_retention['diff'] = (user_retention['order_date'] - user_retention['order_date_min']).apply(lambda x:x/np.timedelta64(1,'D'))
获得用户每一次消费距第一次消费的时间差值,
将时间差值分桶。我这里分成0~3天内,3~7天内,7~15天等,代表用户当前消费时间距第一次消费属于哪个时间段呢。这里date_diff=0并没有被划分入0~3天,因为计算的是留存率,如果用户仅消费了一次,留存率应该是0。另外一方面,如果用户第一天内消费了多次,但是往后没有消费,也算作留存率0。
user_retention['diff_bin']= pd.cut(user_retention['diff'],bins=[0,3,7,15,60,90,180,365])
user_retention.describe()

虽然后面时间段的金额高,但是它的时间范围也宽广。从平均效果看,用户第一次消费后的0~3天内,更可能消费更多。
但消费更多是一个相对的概念,我们还要看整体中有多少用户在0~3天消费。
用pivot_table数据透视,获得用户在第一次消费之后,在后续各时间段内的消费总额。
pivoted = user_retention.pivot_table(index='user_id',columns='diff_bin',values='order_amount',aggfunc=sum)
pivoted_trans = pivoted.fillna(0).applymap(lamda x:1 if x>0 else 0)
(pivoted_trans.sum()/pivoted_trans.count()).plot(kind='bar')

只有2.5%的用户在第一次消费的次日至3天内有过消费,3%的用户在3~7天内有过消费。数字并不好看,CD购买确实不是高频消费行为。时间范围放宽后数字好看了不少,有20%的用户在第一次消费后的三个月到半年之间有过购买,27%的用户在半年后至1年内有过购买。从运营角度看,CD机营销在教育新用户的同时,应该注重用户忠诚度的培养,放长线掉大鱼,在一定时间内召回用户购买。
求出用户的消费间隔,
def diff(group):
d = group.diff - group.diff.shift(-1)
return d
last_diff = user_retention.groupby('user_id').apply(diff)
last_diff.mean()
然后就简单了,用mean函数即可求出用户的平均消费间隔时间是68天。想要召回用户,在60天左右的消费间隔是比较好的。
也可以画一个柱状图,
last_dfff.hist(bins=20)
假若大家有兴趣,不妨多做几个分析假设,看能不能用Python挖掘出更有意思的数据,1月、2月、3月的新用户在留存率有没有差异?不同生命周期的用户,他们的消费累加图是什么样的?消费留存,划分其他时间段怎么样?
这里的数据只是用户ID,消费时间,购买量和消费金额。如果换成用户ID,浏览时间,浏览量,能不能直接套用?浏览变成评论、点赞又行不行?消费行为变成用户其他行为呢?我可以明确地告诉你,大部分代码只要替换部分就能直接用了。