高可用是很多分布式系统中必备的特征之一,Kafka 日志的高可用是通过基于 leader-follower 的多副本同步实现的,每个分区下有多个副本,其中只有一个是 leader 副本,提供发送和消费消息,其余都是 follower 副本,不断地发送 fetch 请求给 leader 副本以同步消息,如果 leader 在整个集群运行过程中不发生故障,follower 副本不会起到任何作用,问题就在于任何系统都不能保证其稳定运行,当 leader 副本所在的 broker 崩溃之后,其中一个 follower 副本就会成为该分区下新的 leader 副本,那么问题来了,在选为新的 leader 副本时,会导致消息丢失或者离散吗?Kafka 是如何解决 leader 副本变更时消息不会出错?以及 leader 与 follower 副本之间的数据同步是如何进行的?带着这几个问题,我们接着往下看,一起揭开 Kafka 水印备份的神秘面纱。
水印相关概念
在讲解水印备份之前,我们必须要先搞清楚几个关键的术语以及它们的含义,下面我用一张图来示意 Kafka 分区副本的位移信息:
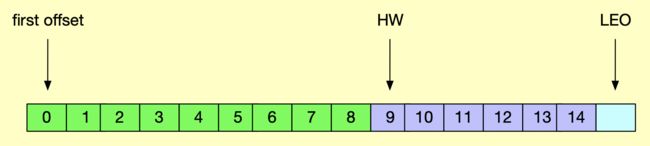
如上图所示,绿色部分表示已完全备份的消息,对消费者可见,紫色部分表示未完全备份的消息,对消费者不可见。
LEO(last end offset):日志末端位移,记录了该副本对象底层日志文件中下一条消息的位移值,副本写入消息的时候,会自动更新 LEO 值。
HW(high watermark):从名字可以知道,该值叫高水印值,HW 一定不会大于 LEO 值,小于 HW 值的消息被认为是“已提交”或“已备份”的消息,并对消费者可见。
leader 会保存两个类型的 LEO 值,一个是自己的 LEO,另一个是 remote LEO 值,remote LEO 值就是 follower 副本的 LEO 值,意味着 follower 副本的 LEO 值会保存两份,一份保存到 leader 副本中,一份保存到自己这里。
remote LEO 值有什么用呢?
它是决定 HW 值大小的关键,当 HW 要更新时,就会对比 LEO 值(也包括 leader LEO),取最小的那个做最新的 HW 值。
以下介绍 LEO 和 HW 值的更新机制:
LEO 更新机制:
- leader 副本自身的 LEO 值更新:在 Producer 消息发送过来时,即 leader 副本当前最新存储的消息位移位置 +1;
- follower 副本自身的 LEO 值更新:从 leader 副本中 fetch 到消息并写到本地日志文件时,即 follower 副本当前同步 leader 副本最新的消息位移位置 +1;
- leader 副本中的 remote LEO 值更新:每次 follower 副本发送 fetch 请求都会包含 follower 当前 LEO 值,leader 拿到该值就会尝试更新 remote LEO 值。
leader HW 更新机制:
leader HW 更新分为故障时更新与正常时更新:
故障时更新:
- 副本被选为 leader 副本时:当某个 follower 副本被选为分区的 leader 副本时,kafka 就会尝试更新 HW 值;
- 副本被踢出 ISR 时:如果某个副本追不上 leader 副本进度,或者所在 broker 崩溃了,导致被踢出 ISR,leader 也会检查 HW 值是否需要更新,毕竟 HW 值更新只跟处于 ISR 的副本 LEO 有关系。
正常时更新:
- producer 向 leader 副本写入消息时:在消息写入时会更新 leader LEO 值,因此需要再检查是否需要更新 HW 值;
- leader 处理 follower FETCH 请求时:follower 的 fetch 请求会携带 LEO 值,leader 会根据这个值更新对应的 remote LEO 值,同时也需要检查是否需要更新 HW 值。
follower HW 更新机制:
- follower 更新 HW 发生在其更新 LEO 之后,每次 follower Fetch 响应体都会包含 leader 的 HW 值,然后比较当前 LEO 值,取最小的作为新的 HW 值。
图解水印备份过程
在了解了 Kafka 水印备份机制的相关概念之后,下面我用图来帮大家更好地理解 Kafka 的水印备份过程,假设某个分区有两个副本,min.insync.replica=1:

Step 1:leader 和 follower 副本处于初始化值,follower 副本发送 fetch 请求,由于 leader 副本没有数据,因此不会进行同步操作;
Step 2:生产者发送了消息 m1 到分区 leader 副本,写入该条消息后 leader 更新 LEO = 1;
Step 3:follower 发送 fetch 请求,携带当前最新的 offset = 0,leader 处理 fetch 请求时,更新 remote LEO = 0,对比 LEO 值最小为 0,所以 HW = 0,leader 副本响应消息数据及 leader HW = 0 给 follower,follower 写入消息后,更新 LEO 值,同时对比 leader HW 值,取最小的作为新的 HW 值,此时 follower HW = 0,这也意味着,follower HW 是不会超过 leader HW 值的。
Step 4:follower 发送第二轮 fetch 请求,携带当前最新的 offset = 1,leader 处理 fetch 请求时,更新 remote LEO = 1,对比 LEO 值最小为 1,所以 HW = 1,此时 leader 没有新的消息数据,所以直接返回 leader HW = 1 给 follower,follower 对比当前最新的 LEO 值 与 leader HW 值,取最小的作为新的 HW 值,此时 follower HW = 1。
基于水印备份机制的一些缺陷
从以上步骤可看出,leader 中保存的 remote LEO 值的更新总是需要额外一轮 fetch RPC 请求才能完成,这意味着在 leader 切换过程中,会存在数据丢失以及数据不一致的问题,下面我用图来说明存在的问题:
- 数据丢失

前面也说过,leader 中的 HW 值是在 follower 下一轮 fetch RPC 请求中完成更新的,如上图所示,有副本 A 和 B,其中 B 为 leader 副本,A 为 follower 副本,在 A 进行第二段 fetch 请求,并接收到响应之后,此时 B 已经将 HW 更新为 2,如果这是 A 还没处理完响应就崩溃了,即 follower 没有及时更新 HW 值,A 重启时,会自动将 LEO 值调整到之前的 HW 值,即会进行日志截断,接着会向 B 发送 fetch 请求,但很不幸的是此时 B 也发生宕机了,Kafka 会将 A 选举为新的分区 Leader。当 B 重启后,会从 向 A 发送 fetch 请求,收到 fetch 响应后,拿到 HW 值,并更新本地 HW 值,此时 HW 被调整为 1(之前是 2),这时 B 会做日志截断,因此,offsets = 1 的消息被永久地删除了。
可能你会问,follower 副本为什么要进行日志截断?
这是由于消息会先记录到 leader,follower 再从 leader 中拉取消息进行同步,这就导致 leader LEO 会比 follower 的要大(ollower之间的offset也不尽相同,虽然最终会一致,但过程中会有差异),假设此时出现 leader 切换,有可能选举了一个 LEO 较小的 follower 成为新的 leader,这时该副本的 LEO 就会成为新的标准,这就会导致 follower LEO 值有可能会比 leader LEO 值要大的情况,因此 follower 在进行同步之前,需要从 leader 获取 LastOffset 的值(该值后面会有解释),如果 LastOffset 小于 当前 LEO,则需要进行日志截断,然后再从 leader 拉取数据实现同步。
可能你还会问,日志截断会不会造成数据丢失?
前面也说过,HW 值以上的消息是没有“已提交”或“已备份”的,因此消息也是对消费者不可见,即这些消息不对用户作承诺,也即是说从 HW 值截断日志,并不会导致数据丢失(承诺用户范围内)。
- 数据不一致/离散
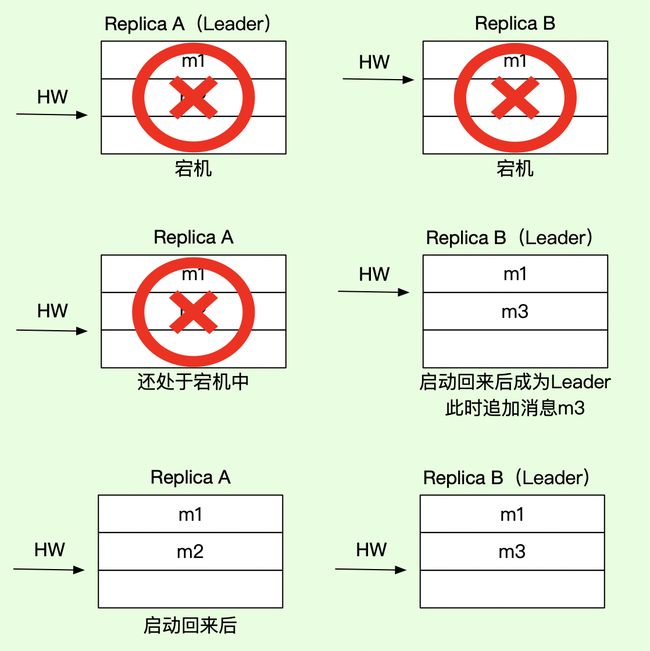
以上情况,需要满足以下其中一个条件才会发生:
- 宕机之前,B 已不在 ISR 列表中,unclean.leader.election.enable=true,即允许非 ISR 中副本成为 leader;
- B 消息写入到 pagecache,但尚未 flush 到磁盘。
分区有两个副本,其中 A 为 Leader 副本,B 为 follower 副本,A 已经写入两条消息,且 HW 更新到 2,B 只写了 1条消息,HW 为 1,此时 A 和 B 同时宕机,B 先重启,B 成为了 leader 副本,这时生产者发送了一条消息,保存到 B 中,由于此时分区只有 B,B 在写入消息时把 HW 更新到 2,就在这时候 A 重新启动,发现 leader HW 为 2,跟自己的 HW 一样,因此没有执行日志截断,这就造成了 A 的 offset=1 的日志与 B 的 offset=1 的日志不一样的现象。
leader epoch
为了解决 HW 更新时机是异步延迟的,而 HW 又是决定日志是否备份成功的标志,从而造成数据丢失和数据不一致的现象,Kafka 引入了 leader epoch 机制,在每个副本日志目录下都创建一个 leader-epoch-checkpoint 文件,用于保存 leader 的 epoch 信息,如下,leader epoch 长这样:

它的格式为 (epoch offset),epoch指的是 leader 版本,它是一个单调递增的一个正整数值,每次 leader 变更,epoch 版本都会 +1,offset 是每一代 leader 写入的第一条消息的位移值,比如:
(0, 0)
(1, 300)以上第二个版本是从位移300开始写入消息,意味着第一个版本写入了 0-299 的消息。
leader epoch 具体的工作机制如下:
1)当副本成为 leader 时:
这时,如果此时生产者有新消息发送过来,会首先新的 leader epoch 以及 LEO 添加到 leader-epoch-checkpoint 文件中。
2)当副本变成 follower 时:
- 发送 LeaderEpochRequest 请求给 leader 副本,该请求包括了 follower 中最新的 epoch 版本;
- leader 返回给 follower 的相应中包含了一个 LastOffset,如果 follower last epoch = leader last epoch,则 LastOffset = leader LEO,否则取大于 follower last epoch 中最小的 leader epoch 的 start offset 值,举个例子:假设 follower last epoch = 1,此时 leader 有 (1, 20) (2, 80) (3, 120),则 LastOffset = 80;
- follower 拿到 LastOffset 之后,会对比当前 LEO 值是否大于 LastOffset,如果当前 LEO 大于 LastOffset,则从 LastOffset 截断日志;
- follower 开始发送 fetch 请求给 leader 保持消息同步。
基于 leader epoch 的工作机制,我们接下来看看它是如何解决水印备份缺陷的:
(1)解决数据丢失:

如上图所示,A 重启之后,发送 LeaderEpochRequest 请求给 B,由于 B 还没追加消息,此时 epoch = request epoch = 0,因此返回 LastOffset = leader LEO = 2 给 A,A 拿到 LastOffset 之后,发现等于当前 LEO 值,故不用进行日志截断。就在这时 B 宕机了,A 成为 leader,在 B 启动回来后,会重复 A 的动作,同样不需要进行日志截断,数据没有丢失。
(2)解决数据不一致/离散
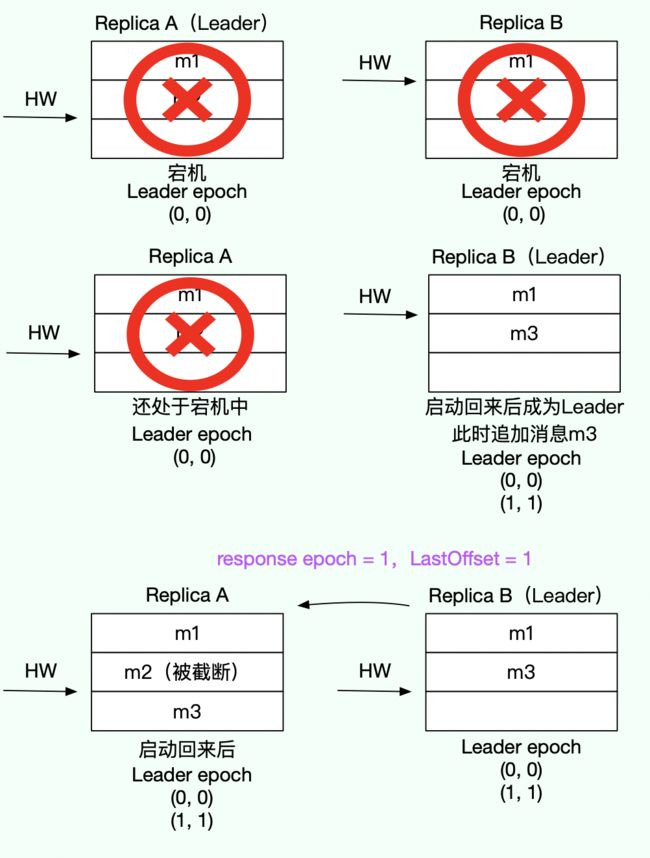
如上图所示,A 和 B 同时宕机后,B 先重启回来成为分区 leader,这时候生产者发送了一条消息过来,leader epoch 更新到 1,此时 A 启动回来后,发送 LeaderEpochRequest(follower epoch = 0) 给 B,B 判断 follower epoch 不等于 最新的 epoch,于是找到大于 follower epoch 最小的 epoch = 1,即 LastOffset = epoch start offset = 1,A 拿到 LastOffset 后,判断小于当前 LEO 值,于是从 LastOffset 位置进行日志截断,接着开始发送 fetch 请求给 B 开始同步消息,避免了消息不一致/离散的问题。
更多精彩文章请关注作者维护的公众号「后端进阶」,这是一个专注后端相关技术的公众号。
关注公众号并回复「后端」免费领取后端相关电子书籍。
欢迎分享,转载请保留出处。
