数据来自于一个不完全清楚的过程。以投掷硬币为例,严格意义上讲,我们无法预测任意一次投硬币的结果是正面还是反面,只能谈论正面或反面出现的概率。在投掷过程中有大量会影响结果的不可观测的变量,比如投掷的姿势、力度、方向,甚至风速和地面的材质都会影响结果。也许这些变量实际上是可以观测的,但我们对这些变量对结果的影响缺乏必要的认知,所以退而求其次,把投掷硬币作为一个随机过程来建模,并用概率理论对其进行分析。
概率有时也被解释为频率或可信度,但是在日常生活中,人们讨论的概率经常包含着主观的因素,并不总是能等同于频率或可信度。比如有人分析中国足球队打进下次世界杯的概率是10%,并不是说出现的频率是10%,因为下次比赛还没有开始。我们实际上是说这个结果出现的可能性,由于是主观的,因此不同的人将给出不同的概率。
在数学上,概率研究的是随机现象背后的客观规律。我们对随机没有兴趣,感兴趣的是通过大量随机试验总结出的数学模型。当某个试验可以在完全相同的条件下不断重复时,对于任意事件E(试验的可能结果的集合,事件是集合,不是动作),结果在出现在E中的次数占比趋近于某个常量,这个常数极限是事件E的概率,用P(E)表示。
我们需要对现实世界建模,将现实世界的动作映射为函数,动作结果映射为数。比如把投硬币看作f(z),z是影响结果的一系列不可观测的变量,x 表示投硬币的结果,x = f(z)。f是一个确定的函数,如果能够得到该函数的形态,我们就能对结果进行精确预测,但由于我们对x和z之间的映射关系缺少了解,所以无法对f建模,只能定义X来描述该过程是由概率分布P(X=x)抽取的随机变量。
在讨论贝叶斯决策之前先来复习一下概率的基础知识。
随机变量和概率分布
随机变量通常用实数表示概率事件,它具有随机性,会随环境而改变,对于随机变量的每一个取值,都有一个与之唯一对应的概率。通常用大X表示随机变量,比如X={投掷硬币的结果},X={公司第一季度的销售额}。
离散型变量和概率质量函数
离散型变量的概率分布可以用概率质量函数(probability mass function,PMF)来描述。通常用大写的P来表示概率质量函数。概率质量函数把随机变量能够取得的每个值都映射到该值对应的概率,比如P(X=x)表示随机变量等于x的概率,这里X表示随机变量本身,x表示某一个固定的取值。
离散型随机变量是的取值是有限的,比如投骰子的结果,X=每次投骰子的结果。每个随机变量都有一个与之对应的概率,比如投骰子时P(X=1)=1/6,P(X=3)=1/6;再比如P(X=1)=1/4,1表示“今年会发年终奖”。
对于任意实数a,离散型随机变量X的概率分布函数是:
![]()
其中P是概率质量函数,P(a) = P(X=a),可以简单地把概率分布理解为概率的累加。
随机变量可能不止一个,比如{X=汽车发动机功率,Y=汽车价格}。我们对多个随机变量以及它们之间的关系同样感兴趣,它们的联合分布是:
![]()
假设有两个离散型随机变量X和Y,并且已知P(X,Y),可以用下式定义X=x的边缘概率:
![]()
连续型变量和概率密度函数
连续型随机变量的取值是连续的,比如水杯中水的真实体积,它的值可能是从0~1000ml中的任意取值(包括小数)。我们用概率密度函数(probability density function,PDF)而不是质量函数来描述它的概率分布。通常用小写字母p表示概率密度函数,p的定义域是所有随机变量的可能的取值,一个常见的密度函数是正态分布函数。
对于单变量连续型概率分布来说:
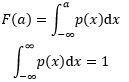
p和表示概率的质量函数P不同,p不是概率,p(x)dx才是概率。
对于二维随机变量来说,p(x,y)是密度函数,联合概率分布是:
![]()
边缘密度自然是固定一个变量,对另一个做积分:
![]()
实际上这与离散型类似,只不过用积分代替了求和。边缘密度也不是概率,px(a)dx才是概率。
期望
随机变量X的期望是指大量试验中X的加权平均值,用E[X]表示:
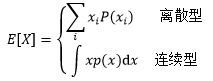
伯努利分布
如果随机试验仅有两个可能的结果,那么这两个结果可以用0和1表示,此时随机变量X将是一个0/1的变量,其分布是单个二值随机变量的分布,称为伯努利分布。注意伯努利分布关注的是结果只有0和1,而不管观测条件是什么。
设p是随机变量等于1的概率,伯努利分布有一些特殊的性质:
![]()
将上面的两个式子合并:
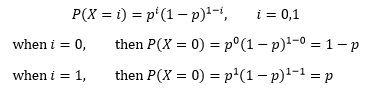
伯努利变量是离散型,并且是一个0/1变量,它的数学期望是:
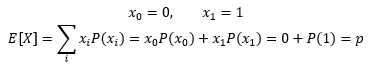
方差是:
![]()
条件概率
很多时候,我们感兴趣的是某个事件在给定其它事件时出现的概率,这种概率称为条件概率。给定X=x,Y=y,在x条件下下发生y的概率是P(y|x):
![]()
这实际上是由下式推导来的:
![]()
x和y同时发生的概率等于x条件下发生y的概率(这里x和y都是给定的值,x条件下还可以发生其他事件)乘以x发生的概率。这里并未强调X和Y是独立的,所以P(x|y)≠P(y|x),只有当二者互相独立时,P(y|x)=p(xy)=P(x|y)。
贝叶斯规则
贝叶斯公式常见的一个版本:
![]()
很多时候,求P(A|B)很困难,但求P(B|A)却很容易。上面的公式实际上是条件概率公式简单的推导:
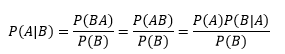
当两个变量联合分布时:
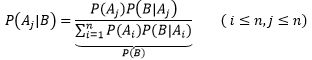
分母实际上是随机变量Y=B时的边缘概率:
![]()
先验与后验
人们一直通过寻找证据的方式来排除陌生领域的不确定性,并在不确定的条件下进行决策,而概率正是根据有意义的证据进行推理的一种方式。
假设我们有一个关于小汽车的样本集,其中包含m个样本,每个样本都有发动机功率和价格两个特征,这些汽车可分为两类,跑车和普通家用车。在这个集合中,汽车的类型可以用伯努利随机变量C表示,C=1表示家用车,C=0表示豪华车。发动机功率和价格作为可观测的条件,是一个二维随机变量,X=(x1; x2)。如果我们能够知道质量函数,当面对一组观测条件的向量x=(x1; x2)时,就可以做出类似下面的预判:
![]()
在x条件下,当汽车是家用车的概率大于50%时,判断该汽车是家用车,否则判断为豪华车。
现在的问题是如何求得P(C|x)的分布模型。根据贝叶斯规则:
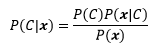
P(C|x)是后验概率,意思是根据观测条件判断C取值类型的概率,是我们的目标。
P(C)是预先知道的,它是根据数据集中m个样本的标签统计而来的,与x无关。这里“无关”的意思是说,我们只通过标签就可以计算出P(C),而不是说特征真的和标签无关——要是真的无关也就没必要建立模型了。由于我们在看到x前就已经知道了P(C),因此称P(C)为先验概率,并且有P(C = 0) + P(C = 1) = 1。
P(x|C)是似然,P(x|C=1)表示在家用车的前提下,发动机功率和价格有多大可能性是x。P(x|C)也可以通过训练数据得到(具体方法将在后续文章详细讲述)。值得注意的是,在实际应用中,x通常是更多维的,且每一维度都有很多取值,因此随机变量的取值空间远远大于训练集的样本数,这就导致观测条件的许多取值没有出现在训练样本中,而“没有出现”和“出现的概率是0”并不是一回事,这意味着P(x|C)实际上也无法通过已知的数据求得(变通方法将在后续文章详细讲述)。
P(x)是证据,是可观测条件X=x的边缘概率:
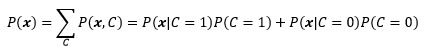
可以看到,P(x)实际上就是x出现在数据集中的概率,与C有多少个取值无关。证据的一个作用是使后验概率规范化,使得:
![]()
也许代入具体的公式会更清晰:
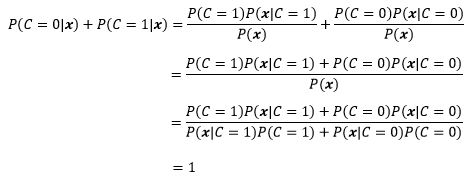
贝叶斯规则告诉我们:
只要知道了后验概率,就可以根据观测条件做出决策。
决策、损失与风险
以手写数字识别为例,随机变量X是手写输入的图像,Ci(i=1,2,…,10)表示被识别出数字的分类,C1~C9表示1~9,C10表示数字0,共10个分类,K = 10。数据集中已经有了大量的图像和对应的分类:

多分类的决策
对于先验概率P(Ci)来说:
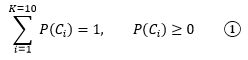
假设先验和似然是已知的,对于任意一个输入x,被识别为Ci类的概率是:
![]()
对于每个输入,都能得到K=10个后验概率。现在有一个潦草的输入:

暂且认为是地球文字,并且![]() 中第一个字符的真实含义是7,对于该字符的识别将产生10个后验概率:
中第一个字符的真实含义是7,对于该字符的识别将产生10个后验概率:
![]()
其中最大的一个值是P(C2|x),因此选择C2作为最终决策:
![]()
损失与风险
在这个例子中,由于字迹潦草,识别系统对x做出了错误的决策。对于医疗诊断来说,决策是至关重要的,也许把每7天检查一次看成2天检查一次没什么大不了,但是反过来就可能耽误患者的治疗,这意味着每个决策对应的风险是不同的。
为了判断风险的大小,需要将其数字化。我们定义R(Ci|x)是把输入x指派到Ci类的决策所带来的风险。λik是x实际上属于Ck时把x指派到Ci的损失,比如本例中字符的真实含义是7(x属于C7),但识别系统将x指派到了C2,此时的损失是λ27。结合期望的概念,期望风险(expected risk)R(Ci|x)是:

期望风险的另一个名称是期望损失(expected loss),在决策论中通常用“期望风险”一词。λik是根据领域知识定义的,抢银行失败的风险和考试失败的风险当然不同。
我们选择期望风险最小的决策作为最终决策:
![]()
正确的决策没有损失,即λii=0,但错误的损失各不相同,把2天服药一次看作3天服药一次也许损失不大,但是看作7天服药一次可就要命了。
一种最简单的损失函数是0-1损失函数:
![]()
在0-1损失函数下,结合①,把输入x指派到Ci的决策带来的期望风险是:
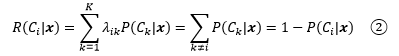
“正确的决策没有损失”这句话并不完全正确,因为存在例外,比如在“老妈和女朋友同时掉进水中先救谁”这种送命题中,无论怎么选会有损失,此时你可以让“最佳决策”有一个相对较小的损失。鉴于送命题的答案是一个玄学问题,我们姑且认为在绝大多数情况下,正确的决策没有损失。
疑惑动作
P(C2|x)=0.54是所有P(Ci|x)中最大的一个,表示x有比一半多一点的概率是C2,近似于瞎蒙,这意味着这是一个确定性很低(或错误率很高)的决策。在医疗诊断中,错误的决策往往意味着极高的代价,因此对这些确定性很低的决策可能需要更高级别的处理,比如人工干预。这就需要定义一个拒绝(reject)或疑惑(doubt)动作d,此时带有疑惑动作的0-1损失函数是:
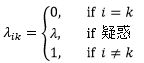
λ是疑惑动作的损失(注意λ和λik不是一回事)。疑惑的风险是:
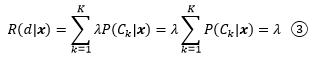
值得注意的是,我们处理的仍然是K分类,疑惑动作和其他的普通决策虽然站在一起,但并不等价。之所以定义d,是由于对所有P(Ci|x),1 ≤ i ≤ K来说,即使最大的一个P(Ci|x)仍然可能只有很低的置信度,①仍然成立,把x划分到Ci的风险仍然是②。
对于带有疑惑的决策来说:
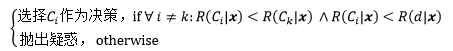
把②和③代入的第一个分式:
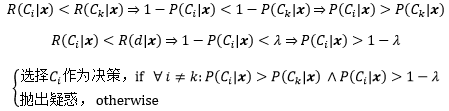
λ的取值应该在(0, 1)之间,如果λ ≤ 0,那么对于第一个分式来说,P(Ci|x) > 1 – λ 永远不会成立,这意味着识别系统总是对输入产生疑惑;如果λ ≥ 1,则永远不会拒绝,加入疑惑动作就没有意义了。
出处:微信公众号 "我是8位的"
本文以学习、研究和分享为主,如需转载,请联系本人,标明作者和出处,非商业用途!
扫描二维码关注作者公众号“我是8位的”
