可能很多安卓手机都会自带拼接长截图的功能,可是对于iOS只能通过第三方的app拼接了。于是我想将拼接的功能做成微信小程序,这样会比较方便,无奈实现过程中发现用JavaScript实现性能存在很大问题,识别率也很低,于是打算先用python实现,以测试算法的正确性。
拼接效果在最后
我写得可能不是很好,欢迎指正!
要实现长截图,可能的情况很多,先介绍一下最简单的情况
长截图算法
获取截图
我们按照手工拼接的想法来考虑这个问题
首先得到两张截图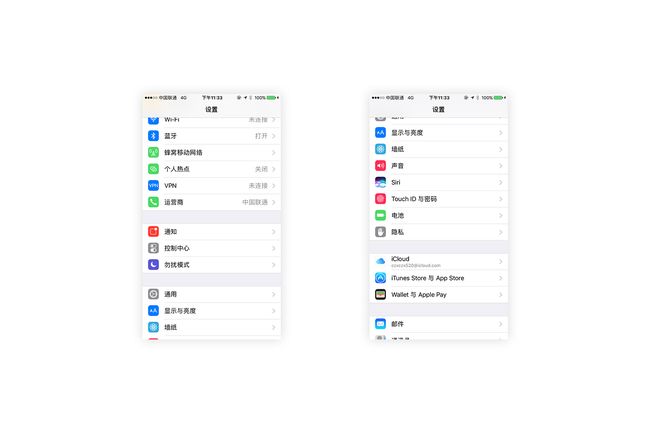
寻找相同部分
然后我们首先要考虑两张图相同的部分,也就是找到相同的头部
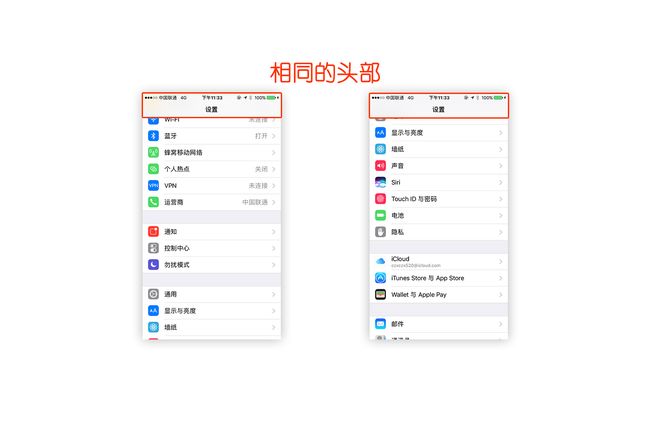
删除相同头部
接着把第二张图中与图1重复的头部删掉
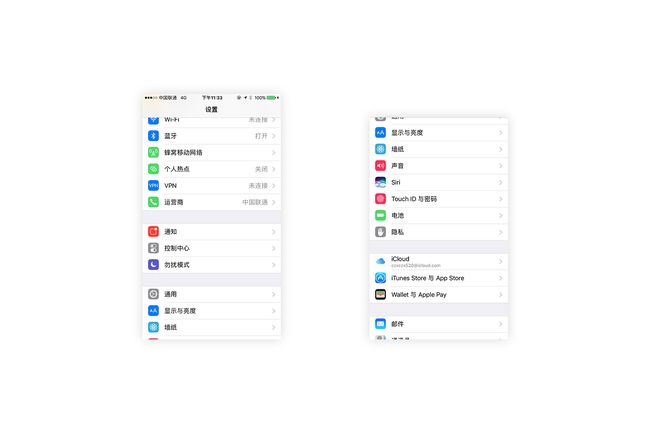
移动并拼接
然后第二张图从底至顶移动,找到重合的地方,拼接
这就是我们正常的手工拼接流程。因此可以把算法总结一下:
- step 1: 获取两张截图
- step 2: 寻找相同的头部
- step 3: 删除第二张中相同的头部
- step 4: 从第一张的底部至顶部比较,找到重合的地方,拼接
实现前要知道
- 通常的图片为RGB模式,即图片的每个像素由红(red)、绿(green)、蓝(blue)三个颜色组成,它们的取值范围是[0,255],即(0,0,0)表示黑色,(255,255,255)表示白色。
- 在处理图片时,我们可以对图片中的每个像素操作,获取到图片的每个像素的RGB值,对于一张2*3的纯白图片,我们可以得到它的像素内容:
[
[ (255,255,255) , (255,255,255) ],
[ (255,255,255) , (255,255,255) ],
[ (255,255,255) , (255,255,255) ]
]
共6个像素点,每个tuple包含了一个像素点的RGB内容
因此,我们在 寻找相同的头部 的时候,可以从头开始比较其中每个像素的信息。
拼接图片 ,也就是将这些图片的像素信息重新拼接起来,再显示即可。
用Python实现
在python中我们可以用PIL的getdata()方法获得图片的像素内容,用putdata()将像素内容转变成图片。
打开图片
通过img = Image.open(path)我们可以打开一张图片
再通过img.getdata()可以得到像素信息
from PIL import Image #引入PIL
from datetime import datetime #后续用于测试运行时间
class sewImage(object): #拼接图片的类
def __init__(self,imagePath=[]):
self.imgPath = imagePath #imgPath是储存图片路径的数组
self.imgdatas = [] #imgdatas是储存每张图片的像素信息的数组
self.width = -1 #截图宽度
self.height = -1 #截图高度
self.curr = 0 #当前图片的位置
#打开图片
def openImages(self):
if(len(self.imgPath)<2):
raise ValueError("图片数量小于2张")
for path in self.imgPath:
img = Image.open(path) #打开图片
img_RGB = img.convert("RGB") #转换成RGB模式
imgdata = img_RGB.getdata() #获取图片的像素信息
#判断尺寸是否一致,要求每张图片的宽高一致(高度其实可以不一致,不过稍微麻烦点)
if(self.width==-1):
self.width,self.height = img_RGB.size
else:
w,h = img_RGB.size
if(w!=self.width or h != self.height):
raise ValueError("图片尺寸不一致")
self.imgdatas.append(imgdata) #将获取的像素信息加入imgdatas数组
寻找相同的头部
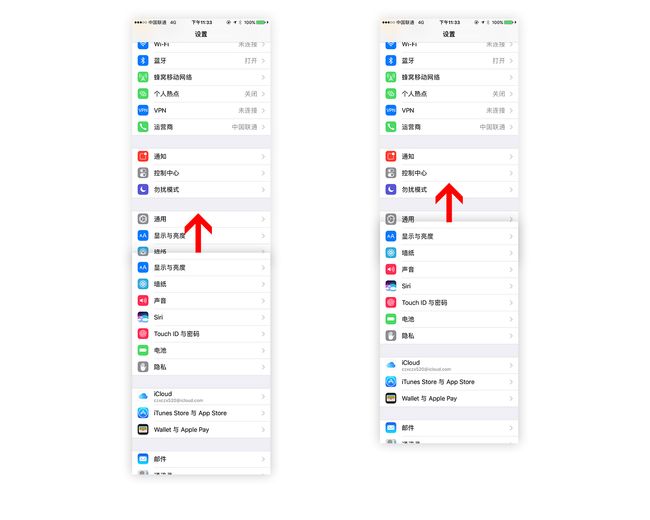
在iOS中的导航栏通常是磨砂半透明的,所以实际上无论微信还是其他app的导航栏,两张截图的颜色通常是有差别的,如图所示,因此我们再比较是否两个像素是否相同的时候,应该允许一定的误差范围,我试验后发现RGB分别相差在25以内可以认为是“相同的”。(这个可根据需求自行调整)同时,截图时状态栏的图标可能也会发生细微变化,比如信号强度不同,因此我们也得设置一定的误差允许范围,在此我设置了一行中超过90%的像素是“相同的”,即认为该行相同。

代码如下
#寻找相同的头部
def findHead(self,hitRate=0.9): #hitRate:一行中超过hitRate*width个相同的像素即认为该行相同
imgdatas = self.imgdatas
curr = self.curr
width = self.width
if(curr>=len(imgdatas)-1):
return
equalPixel = 0
head=self.height #相同头的位置,默认为height
imgdata1=imgdatas[curr]
imgdata2=imgdatas[curr+1]
for h in range(head):
for w in range(width):#比对一行
r1,g1,b1 = imgdata1[width*h+w]
r2,g2,b2 = imgdata2[width*h+w]
if(abs(r1-r2)<25 and abs(g1-g2)<25 and abs(b1-b2)<25):
equalPixel +=1
if(equalPixel拼接图片
拼接部分是按这样的顺序,两张两张拼接:
-> [ 图1 ] [ 图2 ] [ 图3 ] [ 图4 ]
-> [ 图1 图2 ] [ 图3 ] [ 图4 ]
-> [ 图1 图2 图3 ] [ 图4 ]
-> [ 图1 图2 图3 图4 ]
先调用上面的函数寻找图1和图2的相同的头部,将图2的头部的那一行与图1从底至顶依次比较每一行,为了提高准确率,我再同时比较图2头部的后15行,与图1的对应位置的行。
#拼接两张图
def getNewImgData(self):
newHeight = self.height
newImgData = list(self.imgdatas[0])
width = self.width
height = self.height
for i in range(len(self.imgdatas)-1):
equalPixel=0
tail = newHeight
imgdata2 = list(self.imgdatas[i+1])
head = self.findHead()
offsetLine = 15 #同时检查offsetLine行是否一致
for h in range(newHeight-offsetLine)[::-1]:
for w in range(width):
r1,g1,b1 = imgdata2[w+width*head]
r2,g2,b2 = newImgData[w+width*h]
r3,g3,b3 = imgdata2[w+width*(head+offsetLine)]
r4,g4,b4 = newImgData[w+width*(h+offsetLine)]
if(r1==r2 and g1==g2 and b1==b2 and r3==r4 and g3==g4 and b3==b4):
equalPixel+=1
if(h < newHeight-height): #没有找到相同行
break
if(equalPixel==width):
tail = h
break
equalPixel=0
newImgData = newImgData[:width*tail]
newImgData.extend(imgdata2[width*head:])
newHeight = tail + (height - head)
return (newImgData,newHeight)
完成拼图
最后再定义一个sew函数组织起来前面的函数,拼图并保存
def sew(self,imagePath=[]):
if(imagePath!=[]):
self.imgPath = imagePath
self.curr = 0
self.openImages() #加载图片
newImgData,newHeight = self.getNewImgData()
newImg = Image.new('RGB',(self.width,newHeight))
newImg.putdata(newImgData)
newImg.save('new.png')
print('拼图完成!')
测试的时候只需要这样即可
sewImg = sewImage(["pic1.png","pic2.png","pic3.png"])
begin = datetime.now()
sewImg.sew()
end = datetime.now()
total = end.timestamp() - begin.timestamp()
print("共耗时:%sms" %(total*1000))
源代码放在了GitHub上:https://github.com/ZitionChan/sewImage
优化
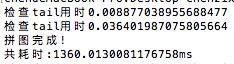
显然,逐个像素比较还是比较慢的,可以看到拼接上面的三张图,需要1.8秒
因此我们需要寻找更好的方法来优化一下
识别拼接尾部的优化
在拼接尾部的时候我们遍历了每个像素,实际上我们只是需要判断两行是否完全一致,因此我们可以切片出每行的内容,直接判断即可,这样则可以去掉一个for循环,效率会提高不少。
我们可以将原来的修改成下面这样
#拼接两张图
def __getNewImgData(self):
newHeight = self.__height
newImgData = list(self.__imgdatas[0])
width = self.__width
height = self.__height
for i in range(len(self.__imgdatas)-1):
tail = newHeight
imgdata2 = list(self.__imgdatas[i+1])
head = self.__findHead()
offsetLine = 15 #同时检查offsetLine行是否一致
#####改动部分#####
for h in range(newHeight-offsetLine)[::-1]:
line1 = imgdata2[width*head:width*(head+1)]
line2 = newImgData[width*h:width*(h+1)]
line3 = imgdata2[width*(head+offsetLine):width*(head+offsetLine+1)]
line4 = newImgData[width*(h+offsetLine):width*(h+offsetLine+1)]
if(h < newHeight-height): #没有找到相同行
break
if(line1==line2 and line3 == line4):
tail = h
break
####改动部分结束####
newImgData = newImgData[:width*tail]
newImgData.extend(imgdata2[width*head:])
newHeight = tail + (height - head)
return (newImgData,newHeight)
改动后拼接3张图快了有半秒
效果
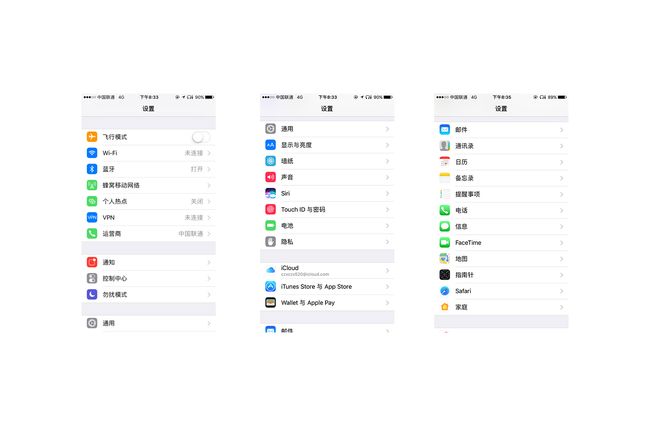
变成这个